Plotting Images from Kepler Target Pixel Files¶
This notebook tutorial demonstrates the loading and extracting of information from Kepler Target Pixel Files to plot images that show the pixels used to create data found in Kepler light curve files.
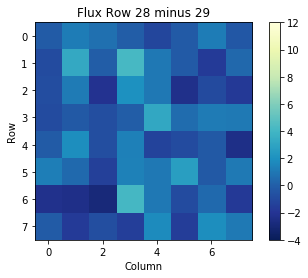
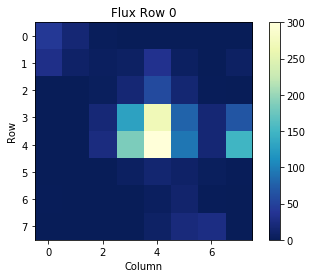
Table of Contents¶
[Introduction](#intro_ID)
[Imports](#imports_ID)
[Getting the Data](#data_ID)
[Reading FITS Extensions](#extension_ID)
[Plotting the Images](#images_ID)
[The Aperture Extension](#aperture_ID)
[Additional Resources](#resources_ID)
[About this Notebook](#about_ID)
Introduction¶
Target Pixel File background: The pixels used to create data in the light curve files are contained within a predefined mask. Each target pixel file packages these pixels as a time series of images in a binary FITS table. These files can then be used to perform photometry on. The binary table in a Target Pixel File (TPF) holds columns of data that contain an array in each cell.
Some notes about the file: kplr008957091-2012277125453_lpd-targ.fits.gz
The filename contains phrases for identification, where
- kplr = Kepler
- 008957091 = Kepler ID number
- 2012277125453 = year 2012, day 277, time 12:54:53
- lpd-targ = long cadence target pixel file
Defining some terms:
- Cadence: the frequency with which summed data are read out. Files are either short cadence (a 1 minute sum) or long cadence (a 30 minute sum). The data we are using here is a long cadence file.
- HDU: Header Data Unit; a FITS file is made up of Header or Data units that contain information, data, and metadata relating to the file. The first HDU is called the primary, and anything that follows is considered an extension.
For more information about the Kepler mission and collected data, visit the Kepler archive page. To read more details about Target Pixel Files and relevant data terms, look in the Kepler archive manual.
Imports¶
Let's start by importing some libraries to the environment:
- numpy to handle array functions
- astropy.io fits for accessing FITS files
- astropy.table Table for creating tidy tables of the data
- matplotlib.pyplot for plotting data
%matplotlib inline
import numpy as np
from astropy.io import fits
from astropy.table import Table
import matplotlib.pyplot as plt
Getting the Data¶
Start by importing libraries from Astroquery. For a longer, more detailed description using of Astroquery, please visit this tutorial or read the Astroquery documentation.
from astroquery.mast import Mast
from astroquery.mast import Observations
Next, we need to find the data file. This is similar to searching for the data using the MAST Portal in that we will be using certain keywords to find the file. The object we are looking for is kplr008957091, collected by the Kepler spacecraft. We are also looking for a long cadence timeseries file.
keplerObs = Observations.query_criteria(target_name='kplr008957091', obs_collection='Kepler')
keplerProds = Observations.get_product_list(keplerObs[0])
yourProd = Observations.filter_products(keplerProds,extension='kplr008957091-2012277125453_lpd-targ.fits.gz',
mrp_only=False)
yourProd
Now that we've found the data file, we can download it using the reults shown in the table above:
Observations.download_products(yourProd, mrp_only=False, cache=False)
Reading FITS Extensions¶
Now that we have the file, we can start working with the data. We will begin by assigning a shorter name to the file to make it easier to use. Then, using the info function from astropy.io.fits, we can see some information about the FITS Header Data Units:
filename = "./mastDownload/Kepler/kplr008957091_lc_Q000000000011111111/kplr008957091-2012277125453_lpd-targ.fits.gz"
fits.info(filename)
- No. 0 (Primary):
This HDU contains meta-data related to the entire file. - No. 1 (Targettables):
This HDU contains a binary table that has 13 columns containing a series of either scalar values or images. We will be taking some of the images from the table and plotting them in this tutorial. - No. 2 (Aperture):
This HDU contains the image extension with data collected from the aperture. We will also use this to display a bitmask plot that visually represents the optimal aperture used to create the SAP_FLUX column in the light curve data.
For more detailed information about header extensions, look here.
Let's say we wanted to see more information about the extensions than what the fits.info command gave us. For example, we can access information stored in the header of the Binary Table extension (No.1, TARGETTABLES). The following line opens the FITS file, writes the first HDU extension into header1, and then closes the file. Only 24 columns are displayed here but you can view them all by adjusting the range:
with fits.open(filename) as hdulist:
header1 = hdulist[1].header
print(repr(header1[1:25])) #repr() prints the info into neat columns
We can also view a table of the data from the Binary Table extension. This is where we can find the flux and time columns to be plotted later. Here only the first four rows of the table are displayed:
with fits.open(filename) as hdulist:
binaryext = hdulist[1].data
binarytab = Table(binaryext)
binarytab[0:4]
Some of the columns (RAW_CNTS through COSMIC_RAYS) are 8x8 arrays. These are the pixels used for light curve data packaged as images into the Binary Table. Each of these arrays is an image taken at a certain time as seen in the TIME column. To find out how many times there are, we can run the following code to get the vertical length of the entire table:
print(len(binarytab['TIME']))
Plotting the Images¶
To better understand the arrays in the table, we can single out one cell and display its data. For example, let's read the cell in Row 0, column FLUX. This is the flux data collected at time 1274.1395732864694.
binarytab['FLUX'][0]
We can then plot this array as an image, where each pixel is shown as a color value from the above array:
plt.title('Flux Row 0')
plt.xlabel('Column')
plt.ylabel('Row')
plt.imshow(binarytab['FLUX'][0], cmap=plt.cm.YlGnBu_r)
plt.colorbar()
plt.clim(0,300)

This plot can be made for any of the arrays in the table. To read in and plot a different cell, change the row number from [0] to another number.
Some arrays contain no numbers, only NaN values. This results in completely blank image frames:
binarytab['FLUX'][34]
plt.title('Flux Row 34')
plt.xlabel('column')
plt.ylabel('row')
plt.imshow(binarytab['FLUX'][34], cmap=plt.cm.YlGnBu_r)
plt.colorbar()
plt.clim(0,300)

We can also view the difference between one frame and another. For example, if we want to see the change from the flux at time in row 20 subtracted from the flux at time in row 19, we can write the following:
arr = np.subtract(binarytab['FLUX'][28], binarytab['FLUX'][29])
print(arr)
We can then plot this array as well:
plt.title('Flux Row 28 minus 29')
plt.xlabel('Column')
plt.ylabel('Row')
plt.imshow(arr, cmap=plt.cm.YlGnBu_r)
plt.colorbar()
plt.clim(-4, 12)

The Aperture Extension¶
We can also make a plot of the third header extension; the image extension. This data is stored as an array of integers that encodes which pixels were collected from the spacecraft and which were used in the optimal aperture (look here for more information on the aperture extension).
First, we need to re-open the FITS file and access the header. Next, we read the the image extension (No. 2, APERTURE) and print it as an array:
with fits.open(filename) as hdulist:
imgdata = hdulist[2].data
print(imgdata)
We can then plot the above array, which will show the pixels used in the optimal aperture for photometry:
plt.figure()
plt.title('TPF APERTURE')
plt.xlabel('Column')
plt.ylabel('Row')
plt.imshow(imgdata, cmap=plt.cm.YlGnBu_r)

Aditional Resources¶
For more information about the MAST archive and details about mission data:
MAST API
Kepler Archive Page (MAST)
Kepler Archive Manual
Exo.MAST website
