
NIRISS AMI Pipeline Notebook#
Authors: R. Cooper
Last Updated: April 17, 2026
Pipeline Version: 2.0.0 (Build 12.3)
Purpose:
This notebook provides a framework for processing Near-Infrared
Imager and Slitless Spectrograph (NIRISS) Aperture Masking Interferometry (AMI) data through all
three James Webb Space Telescope (JWST) pipeline stages. Data is assumed
to be located in one observation folder according to paths set up below.
It should not be necessary to edit any cells other than in the
Configuration section unless modifying the standard
pipeline processing options.
Data: This notebook uses an example dataset from Program ID 1093 (PI: Thatte) which is the AMI commissioning program. For illustrative purposes, we will use a single target and reference star pair. Each exposure was taken in the F480W filter filter with the non-redundant mask (NRM) that enables AMI in the pupil. The observations used are observation 12 for the target and observation 15 for the reference star.
Example input data to use will be downloaded automatically unless disabled (i.e., to use local files instead).
JWST pipeline version and CRDS context:
This notebook was written for the above-specified pipeline version and associated
build context for this version of the JWST Calibration Pipeline. Information about
this and other contexts can be found in the JWST Calibration Reference Data System
(CRDS server). If you use different pipeline versions,
please refer to the table here
to determine what context to use. To learn more about the differences for the pipeline,
read the relevant
documentation.
Please note that pipeline software development is a continuous process, so results
in some cases may be slightly different if a subsequent version is used. For optimal
results, users are strongly encouraged to reprocess their data using the most recent
pipeline version and
associated CRDS context,
taking advantage of bug fixes and algorithm improvements.
Any known issues for this build are noted in the notebook.
Updates:
This notebook is regularly updated as improvements are made to the
pipeline. Find the most up to date version of this notebook at:
https://github.com/spacetelescope/jwst-pipeline-notebooks/
Recent Changes:
March 31, 2025: original notebook released
July 16, 2025: Updated to jwst 1.19.1 (no significant changes)
December 10, 2025: Updated to jwst 1.20.2 (no significant changes)
April 17, 2026: Updated to jwst 2.0.0 (no significant changes)
Table of Contents#
1. Configuration#
Install dependencies and parameters#
To make sure that the pipeline version is compatabile with the steps
discussed below and the required dependencies and packages are installed,
you can create a fresh conda environment and install the provided
requirements.txt file:
conda create -n niriss_ami_pipeline python=3.13
conda activate niriss_ami_pipeline
pip install -r requirements.txt
Set the basic parameters to use with this notebook. These will affect what data is used, where data is located (if already in disk), and pipeline modules run in this data. The list of parameters are:
demo_mode
directories with data
pipeline modules
# Basic import necessary for configuration
import os
demo_mode must be set appropriately below.
Set demo_mode = True to run in demonstration mode. In this
mode this notebook will download example data from the Barbara A.
Mikulski Archive for Space Telescopes (MAST)
and process it through the
pipeline. This will all happen in a local directory unless modified
in Section 3
below.
Set demo_mode = False if you want to process your own data
that has already been downloaded and provide the location of the data.
# Set parameters for demo_mode, channel, band, data mode directories, and
# processing steps.
# -----------------------------Demo Mode---------------------------------
demo_mode = True
if demo_mode:
print('Running in demonstration mode using online example data!')
# --------------------------User Mode Directories------------------------
# If demo_mode = False, look for user data in these paths
if not demo_mode:
# Set directory paths for processing specific data; these will need
# to be changed to your local directory setup (below are given as
# examples)
basedir = os.path.join(os.getcwd(), '')
# Point to location of science observation data.
# Assumes both science and PSF reference data are in the same directory
# with uncalibrated data in sci_dir/uncal/ and results in stage1,
# stage2, stage3 directories
sci_dir = os.path.join(basedir, 'JWSTData/PID_1093/')
# Set which filter to process (empty will process all)
use_filter = '' # E.g., F480M
# --------------------------Set Processing Steps--------------------------
# Individual pipeline stages can be turned on/off here. Note that a later
# stage won't be able to run unless data products have already been
# produced from the prior stage.
# Science processing
dodet1 = True # calwebb_detector1
doimage2 = True # calwebb_image2
doami3 = True # calwebb_ami3
doviz = True # Visualize calwebb_ami3 output
Running in demonstration mode using online example data!
Set CRDS context and server#
Before importing CRDS and JWST modules, we need
to configure our environment. This includes defining a CRDS cache
directory in which to keep the reference files that will be used by the
calibration pipeline.
If the root directory for the local CRDS cache directory has not been set already, it will be set to create one in the home directory.
# ------------------------Set CRDS context and paths----------------------
# Each version of the calibration pipeline is associated with a specific CRDS
# context file. The pipeline will select the appropriate context file behind
# the scenes while running. However, if you wish to override the default context
# file and run the pipeline with a different context, you can set that using
# the CRDS_CONTEXT environment variable. Here we show how this is done,
# although we leave the line commented out in order to use the default context.
# If you wish to specify a different context, uncomment the line below.
#os.environ['CRDS_CONTEXT'] = 'jwst_1322.pmap' # CRDS context for 1.16.0
# Check whether the local CRDS cache directory has been set.
# If not, set it to the user home directory
if (os.getenv('CRDS_PATH') is None):
os.environ['CRDS_PATH'] = os.path.join(os.path.expanduser('~'), 'crds')
# Check whether the CRDS server URL has been set. If not, set it.
if (os.getenv('CRDS_SERVER_URL') is None):
os.environ['CRDS_SERVER_URL'] = 'https://jwst-crds.stsci.edu'
# Echo CRDS path in use
print(f"CRDS local filepath: {os.environ['CRDS_PATH']}")
print(f"CRDS file server: {os.environ['CRDS_SERVER_URL']}")
CRDS local filepath: /home/runner/crds
CRDS file server: https://jwst-crds.stsci.edu
2. Package Imports#
# Use the entire available screen width for this notebook
from IPython.display import display, HTML
display(HTML("<style>.container { width:95% !important; }</style>"))
# Basic system utilities for interacting with files
# ----------------------General Imports------------------------------------
import glob
import time
import json
from pathlib import Path
from collections import defaultdict
# Numpy for doing calculations
import numpy as np
# -----------------------Astroquery Imports--------------------------------
# ASCII files, and downloading demo files
from astroquery.mast import Observations
# For visualizing data
import matplotlib.pyplot as plt
from astropy.visualization import (MinMaxInterval, SqrtStretch,
ImageNormalize)
# For file manipulation
from astropy.io import fits
import asdf
# for JWST calibration pipeline
import jwst
import crds
from jwst.pipeline import Detector1Pipeline
from jwst.pipeline import Image2Pipeline
from jwst.pipeline import Ami3Pipeline
# JWST pipeline utilities
from jwst import datamodels
from jwst.associations import asn_from_list # Tools for creating association files
from jwst.associations.lib.rules_level3_base import DMS_Level3_Base # Definition of a Lvl3 association file
# Echo pipeline version and CRDS context in use
print(f"JWST Calibration Pipeline Version: {jwst.__version__}")
print(f"Using CRDS Context: {crds.get_context_name('jwst')}")
JWST Calibration Pipeline Version: 2.0.0
CRDS - INFO - Calibration SW Found: jwst 2.0.0 (/home/runner/micromamba/envs/ci-env/lib/python3.13/site-packages/jwst-2.0.0.dist-info)
Using CRDS Context: jwst_1535.pmap
Define convenience functions#
# Define a convenience function to select only files of a given filter from an input set
def select_filter_files(files, use_filter):
files_culled = []
if (use_filter != ''):
for file in files:
model = datamodels.open(file)
filt = model.meta.instrument.filter
if (filt == use_filter):
files_culled.append(file)
model.close()
else:
files_culled = files
return files_culled
# Define a convenience function to separate a list of input files into science and PSF reference exposures
def split_scipsf_files(files):
psffiles = []
scifiles = []
for file in files:
model = datamodels.open(file)
if model.meta.exposure.psf_reference is True:
psffiles.append(file)
else:
scifiles.append(file)
model.close()
return scifiles, psffiles
# Start a timer to keep track of runtime
time0 = time.perf_counter()
3. Demo Mode Setup (ignore if not using demo data)#
If running in demonstration mode, set up the program information to
retrieve the uncalibrated data automatically from MAST using
astroquery.
MAST has a dedicated service for JWST data retrieval, so the archive can
be searched by instrument keywords rather than just filenames or proposal IDs.
The list of searchable keywords for filtered JWST MAST queries
is here.
For illustrative purposes, we will use a single target and reference star pair. Each exposure was taken in the F480W filter filter with the non-redundant mask (NRM) that enables AMI in the pupil.
We will start with uncalibrated data products. The files are named
jw010930nn001_03102_00001_nis_uncal.fits, where nn refers to the
observation number: in this case, observation 12 for the target and
observation 15 for the reference star.
More information about the JWST file naming conventions can be found at: https://jwst-pipeline.readthedocs.io/en/latest/jwst/data_products/file_naming.html
# Set up the program information and paths for demo program
if demo_mode:
print('Running in demonstration mode and will download example data from MAST!')
# --------------Program and observation information--------------
program = '01093'
sci_observtn = ['012', '015'] # Obs 12 is the target, Obs 15 is the reference star
visit = '001'
visitgroup = '03'
seq_id = "1"
act_id = '02'
expnum = '00001'
# --------------Program and observation directories--------------
data_dir = os.path.join('.', 'nis_ami_demo_data')
sci_dir = os.path.join(data_dir, 'PID_1093')
uncal_dir = os.path.join(sci_dir, 'uncal') # Uncalibrated pipeline inputs should be here
if not os.path.exists(uncal_dir):
os.makedirs(uncal_dir)
# Create directory if it does not exist
if not os.path.isdir(data_dir):
os.mkdir(data_dir)
Running in demonstration mode and will download example data from MAST!
Identify list of science (SCI) uncalibrated files associated with visits.
# Obtain a list of observation IDs for the specified demo program
if demo_mode:
# Science data
sci_obs_id_table = Observations.query_criteria(instrument_name=["NIRISS/AMI"],
proposal_id=[program],
filters=['F480M;NRM'], # Data for Specific Filter
obs_id=['jw' + program + '*'])
# Turn the list of visits into a list of uncalibrated data files
if demo_mode:
# Define types of files to select
file_dict = {'uncal': {'product_type': 'SCIENCE',
'productSubGroupDescription': 'UNCAL',
'calib_level': [1]}}
# Science files
sci_files = []
# Loop over visits identifying uncalibrated files that are associated
# with them
for exposure in (sci_obs_id_table):
products = Observations.get_product_list(exposure)
for filetype, query_dict in file_dict.items():
filtered_products = Observations.filter_products(products, productType=query_dict['product_type'],
productSubGroupDescription=query_dict['productSubGroupDescription'],
calib_level=query_dict['calib_level'])
sci_files.extend(filtered_products['dataURI'])
# Select only the exposures we want to use based on filename
# Construct the filenames and select files based on them
filestrings = ['jw' + program + sciobs + visit + '_' + visitgroup + seq_id + act_id + '_' + expnum for sciobs in sci_observtn]
sci_files_to_download = [scifile for scifile in sci_files if any(filestr in scifile for filestr in filestrings)]
sci_files_to_download = sorted(set(sci_files_to_download))
print(f"Science files selected for downloading: {len(sci_files_to_download)}")
Science files selected for downloading: 2
Download all the uncal files and place them into the appropriate directories.
if demo_mode:
for filename in sci_files_to_download:
sci_manifest = Observations.download_file(filename,
local_path=os.path.join(uncal_dir, Path(filename).name))
Downloading URL https://mast.stsci.edu/api/v0.1/Download/file?uri=mast:JWST/product/jw01093012001_03102_00001_nis_uncal.fits to ./nis_ami_demo_data/PID_1093/uncal/jw01093012001_03102_00001_nis_uncal.fits ...
[Done]
Downloading URL https://mast.stsci.edu/api/v0.1/Download/file?uri=mast:JWST/product/jw01093015001_03102_00001_nis_uncal.fits to ./nis_ami_demo_data/PID_1093/uncal/jw01093015001_03102_00001_nis_uncal.fits ...
[Done]
4. Directory Setup#
Set up detailed paths to input/output stages here.
# Define output subdirectories to keep science data products organized
# -----------------------------Science Directories------------------------------
uncal_dir = os.path.join(sci_dir, 'uncal') # Uncalibrated pipeline inputs should be here
det1_dir = os.path.join(sci_dir, 'stage1') # calwebb_detector1 pipeline outputs will go here
image2_dir = os.path.join(sci_dir, 'stage2') # calwebb_image2 pipeline outputs will go here
ami3_dir = os.path.join(sci_dir, 'stage3') # calwebb_ami3 pipeline outputs will go here
# We need to check that the desired output directories exist, and if not create them
# Ensure filepaths for input data exist
if not os.path.exists(uncal_dir):
os.makedirs(uncal_dir)
if not os.path.exists(det1_dir):
os.makedirs(det1_dir)
if not os.path.exists(image2_dir):
os.makedirs(image2_dir)
if not os.path.exists(ami3_dir):
os.makedirs(ami3_dir)
Print the exposure parameters of all potential input files:
uncal_files = sorted(glob.glob(os.path.join(uncal_dir, '*_uncal.fits')))
# Restrict to selected filter if applicable
uncal_files = select_filter_files(uncal_files, use_filter)
for file in uncal_files:
model = datamodels.open(file)
# print file name
print(model.meta.filename)
# Print out exposure info
print(f"Instrument: {model.meta.instrument.name}")
print(f"Filter: {model.meta.instrument.filter}")
print(f"Pupil: {model.meta.instrument.pupil}")
print(f"Number of integrations: {model.meta.exposure.nints}")
print(f"Number of groups: {model.meta.exposure.ngroups}")
print(f"Readout pattern: {model.meta.exposure.readpatt}")
print(f"Dither position number: {model.meta.dither.position_number}")
print("\n")
model.close()
jw01093012001_03102_00001_nis_uncal.fits
Instrument: NIRISS
Filter: F480M
Pupil: NRM
Number of integrations: 69
Number of groups: 5
Readout pattern: NISRAPID
Dither position number: 1
jw01093015001_03102_00001_nis_uncal.fits
Instrument: NIRISS
Filter: F480M
Pupil: NRM
Number of integrations: 61
Number of groups: 12
Readout pattern: NISRAPID
Dither position number: 1
For the demo data, files should be for the NIRISS instrument
using the F480M filter in the Filter Wheel
and the NRM in the Pupil Wheel.
Likewise, both demo exposures use the NISRAPID readout pattern. The target has 5 groups per integration, and 69 integrations per exposure. The reference star has 12 groups per integration, and 61 integrations per exposure. They were taken at the same dither position; primary dither pattern position 1.
For more information about how JWST exposures are defined by up-the-ramp sampling, see the Understanding Exposure Times JDox article.
# Print out the time benchmark
time1 = time.perf_counter()
print(f"Runtime so far: {time1 - time0:0.0f} seconds")
Runtime so far: 38 seconds
5. Detector1 Pipeline#
Run the datasets through the
Detector1
stage of the pipeline to apply detector level calibrations and create a
countrate data product where slopes are fitted to the integration ramps.
These *_rateints.fits products are 3D (nintegrations x nrows x ncols)
and contain the fitted ramp slopes for each integration.
2D countrate data products (*_rate.fits) are also
created (nrows x ncols) which have been averaged over all
integrations.
By default, all steps in the Detector1 stage of the pipeline are run for
NIRISS except: the ipc correction step and the gain_scale step. Note
that while the persistence step
is set to run by default, this step does not automatically correct the
science data for persistence. The persistence step creates a
*_trapsfilled.fits file which is a model that records the number
of traps filled at each pixel at the end of an exposure. This file would be
used as an input to the persistence step, via the input_trapsfilled
argument, to correct a science exposure for persistence. Since persistence
is not well calibrated for NIRISS, we do not perform a persistence
correction and thus turn off this step to speed up calibration and to not
create files that will not be used in the subsequent analysis. This step
can be turned off when running the pipeline in Python by doing:
rate_result = Detector1Pipeline.call(uncal,steps={'persistence': {'skip': True}})
or as indicated in the cell bellow using a dictionary.
The charge_migration step
is particularly important for NIRISS images to mitigate apparent flux loss
in resampled images due to the spilling of charge from a central pixel into
its neighboring pixels (see Goudfrooij et al. 2023
for details). Charge migration occurs when the accumulated charge in a
central pixel exceeds a certain signal limit, which is ~25,000 ADU. This
step is turned on by default for NIRISS imaging mode when using CRDS
contexts of jwst_1159.pmap or later. Different signal limits for each filter are provided by the
pars-chargemigrationstep parameter files.
Users can specify a different signal limit by running this step with the
signal_threshold flag and entering another signal limit in units of ADU.
The effect is stronger when there is high contrast between a bright pixel and neighboring faint pixel,
as is the case for the strongly peaked AMI PSF.
For AMI mode, preliminary investigation shows that dark subtraction does not improve calibration, and may in fact have a detrimental effect, so we turn it off here.
# Set up a dictionary to define how the Detector1 pipeline should be configured
# Boilerplate dictionary setup
det1dict = defaultdict(dict)
# Step names are copied here for reference
det1_steps = ['group_scale', 'dq_init', 'saturation', 'ipc', 'superbias', 'refpix',
'linearity', 'persistence', 'dark_current', 'charge_migration',
'jump', 'ramp_fit', 'gain_scale']
# Overrides for whether or not certain steps should be skipped
# skipping the ipc, persistence, and dark steps
det1dict['ipc']['skip'] = True
det1dict['persistence']['skip'] = True
det1dict['dark_current']['skip'] = True
# Overrides for various reference files
# Files should be in the base local directory or provide full path
#det1dict['dq_init']['override_mask'] = 'myfile.fits' # Bad pixel mask
#det1dict['saturation']['override_saturation'] = 'myfile.fits' # Saturation
#det1dict['linearity']['override_linearity'] = 'myfile.fits' # Linearity
#det1dict['dark_current']['override_dark'] = 'myfile.fits' # Dark current subtraction
#det1dict['jump']['override_gain'] = 'myfile.fits' # Gain used by jump step
#det1dict['ramp_fit']['override_gain'] = 'myfile.fits' # Gain used by ramp fitting step
#det1dict['jump']['override_readnoise'] = 'myfile.fits' # Read noise used by jump step
#det1dict['ramp_fit']['override_readnoise'] = 'myfile.fits' # Read noise used by ramp fitting step
# Turn on multi-core processing (off by default). Choose what fraction of cores to use (quarter, half, or all)
det1dict['jump']['maximum_cores'] = 'half'
# Alter parameters of certain steps (example)
#det1dict['charge_migration']['signal_threshold'] = X
The clean_flicker_noise step removes 1/f noise from calibrated ramp images, after the jump step and prior to performing the ramp_fitting step. By default, this step is skipped in the calwebb_detector1 pipeline for all instruments and modes. Although available, this step has not been extensively tested for the NIRISS AMI subarray and is thus not recommended at the present time.
Run Detector1 stage of pipeline
# Run Detector1 stage of pipeline, specifying:
# output directory to save *_rateints.fits files
# save_results flag set to True so the *rateints.fits files are saved
# save_calibrated_ramp set to True so *ramp.fits files are saved
if dodet1:
for uncal in uncal_files:
rate_result = Detector1Pipeline.call(uncal,
output_dir=det1_dir,
steps=det1dict,
save_results=True,
save_calibrated_ramp=True)
else:
print('Skipping Detector1 processing')
2026-04-15 20:14:06,615 - CRDS - INFO - Fetching /home/runner/crds/mappings/jwst/jwst_system_datalvl_0002.rmap 694 bytes (1 / 224 files) (0 / 796.2 K bytes)
2026-04-15 20:14:06,729 - CRDS - INFO - Fetching /home/runner/crds/mappings/jwst/jwst_system_calver_0069.rmap 5.8 K bytes (2 / 224 files) (694 / 796.2 K bytes)
2026-04-15 20:14:06,871 - CRDS - INFO - Fetching /home/runner/crds/mappings/jwst/jwst_system_0064.imap 385 bytes (3 / 224 files) (6.5 K / 796.2 K bytes)
2026-04-15 20:14:06,950 - CRDS - INFO - Fetching /home/runner/crds/mappings/jwst/jwst_nirspec_wavelengthrange_0024.rmap 1.4 K bytes (4 / 224 files) (6.9 K / 796.2 K bytes)
2026-04-15 20:14:07,034 - CRDS - INFO - Fetching /home/runner/crds/mappings/jwst/jwst_nirspec_wavecorr_0005.rmap 884 bytes (5 / 224 files) (8.3 K / 796.2 K bytes)
2026-04-15 20:14:07,119 - CRDS - INFO - Fetching /home/runner/crds/mappings/jwst/jwst_nirspec_superbias_0089.rmap 39.4 K bytes (6 / 224 files) (9.1 K / 796.2 K bytes)
2026-04-15 20:14:07,233 - CRDS - INFO - Fetching /home/runner/crds/mappings/jwst/jwst_nirspec_sirskernel_0002.rmap 704 bytes (7 / 224 files) (48.5 K / 796.2 K bytes)
2026-04-15 20:14:07,330 - CRDS - INFO - Fetching /home/runner/crds/mappings/jwst/jwst_nirspec_sflat_0027.rmap 20.6 K bytes (8 / 224 files) (49.2 K / 796.2 K bytes)
2026-04-15 20:14:07,535 - CRDS - INFO - Fetching /home/runner/crds/mappings/jwst/jwst_nirspec_saturation_0018.rmap 2.0 K bytes (9 / 224 files) (69.8 K / 796.2 K bytes)
2026-04-15 20:14:07,618 - CRDS - INFO - Fetching /home/runner/crds/mappings/jwst/jwst_nirspec_refpix_0015.rmap 1.6 K bytes (10 / 224 files) (71.9 K / 796.2 K bytes)
2026-04-15 20:14:07,697 - CRDS - INFO - Fetching /home/runner/crds/mappings/jwst/jwst_nirspec_readnoise_0025.rmap 2.6 K bytes (11 / 224 files) (73.4 K / 796.2 K bytes)
2026-04-15 20:14:07,819 - CRDS - INFO - Fetching /home/runner/crds/mappings/jwst/jwst_nirspec_psf_0002.rmap 687 bytes (12 / 224 files) (76.0 K / 796.2 K bytes)
2026-04-15 20:14:07,903 - CRDS - INFO - Fetching /home/runner/crds/mappings/jwst/jwst_nirspec_pictureframe_0002.rmap 886 bytes (13 / 224 files) (76.7 K / 796.2 K bytes)
2026-04-15 20:14:07,991 - CRDS - INFO - Fetching /home/runner/crds/mappings/jwst/jwst_nirspec_photom_0013.rmap 958 bytes (14 / 224 files) (77.6 K / 796.2 K bytes)
2026-04-15 20:14:08,081 - CRDS - INFO - Fetching /home/runner/crds/mappings/jwst/jwst_nirspec_pathloss_0011.rmap 1.2 K bytes (15 / 224 files) (78.5 K / 796.2 K bytes)
2026-04-15 20:14:08,167 - CRDS - INFO - Fetching /home/runner/crds/mappings/jwst/jwst_nirspec_pars-whitelightstep_0001.rmap 777 bytes (16 / 224 files) (79.7 K / 796.2 K bytes)
2026-04-15 20:14:08,250 - CRDS - INFO - Fetching /home/runner/crds/mappings/jwst/jwst_nirspec_pars-tso3pipeline_0001.rmap 786 bytes (17 / 224 files) (80.5 K / 796.2 K bytes)
2026-04-15 20:14:08,331 - CRDS - INFO - Fetching /home/runner/crds/mappings/jwst/jwst_nirspec_pars-spec2pipeline_0013.rmap 2.1 K bytes (18 / 224 files) (81.3 K / 796.2 K bytes)
2026-04-15 20:14:08,416 - CRDS - INFO - Fetching /home/runner/crds/mappings/jwst/jwst_nirspec_pars-resamplespecstep_0002.rmap 709 bytes (19 / 224 files) (83.4 K / 796.2 K bytes)
2026-04-15 20:14:08,500 - CRDS - INFO - Fetching /home/runner/crds/mappings/jwst/jwst_nirspec_pars-refpixstep_0003.rmap 910 bytes (20 / 224 files) (84.1 K / 796.2 K bytes)
2026-04-15 20:14:08,581 - CRDS - INFO - Fetching /home/runner/crds/mappings/jwst/jwst_nirspec_pars-pixelreplacestep_0001.rmap 818 bytes (21 / 224 files) (85.0 K / 796.2 K bytes)
2026-04-15 20:14:08,665 - CRDS - INFO - Fetching /home/runner/crds/mappings/jwst/jwst_nirspec_pars-pictureframestep_0001.rmap 818 bytes (22 / 224 files) (85.8 K / 796.2 K bytes)
2026-04-15 20:14:08,751 - CRDS - INFO - Fetching /home/runner/crds/mappings/jwst/jwst_nirspec_pars-outlierdetectionstep_0005.rmap 1.1 K bytes (23 / 224 files) (86.7 K / 796.2 K bytes)
2026-04-15 20:14:08,833 - CRDS - INFO - Fetching /home/runner/crds/mappings/jwst/jwst_nirspec_pars-jumpstep_0006.rmap 810 bytes (24 / 224 files) (87.8 K / 796.2 K bytes)
2026-04-15 20:14:08,918 - CRDS - INFO - Fetching /home/runner/crds/mappings/jwst/jwst_nirspec_pars-image2pipeline_0008.rmap 1.0 K bytes (25 / 224 files) (88.6 K / 796.2 K bytes)
2026-04-15 20:14:09,001 - CRDS - INFO - Fetching /home/runner/crds/mappings/jwst/jwst_nirspec_pars-extract1dstep_0001.rmap 794 bytes (26 / 224 files) (89.6 K / 796.2 K bytes)
2026-04-15 20:14:09,123 - CRDS - INFO - Fetching /home/runner/crds/mappings/jwst/jwst_nirspec_pars-detector1pipeline_0004.rmap 1.1 K bytes (27 / 224 files) (90.4 K / 796.2 K bytes)
2026-04-15 20:14:09,207 - CRDS - INFO - Fetching /home/runner/crds/mappings/jwst/jwst_nirspec_pars-darkpipeline_0003.rmap 872 bytes (28 / 224 files) (91.5 K / 796.2 K bytes)
2026-04-15 20:14:09,378 - CRDS - INFO - Fetching /home/runner/crds/mappings/jwst/jwst_nirspec_pars-darkcurrentstep_0003.rmap 1.8 K bytes (29 / 224 files) (92.4 K / 796.2 K bytes)
2026-04-15 20:14:09,498 - CRDS - INFO - Fetching /home/runner/crds/mappings/jwst/jwst_nirspec_pars-cubebuildstep_0001.rmap 862 bytes (30 / 224 files) (94.2 K / 796.2 K bytes)
2026-04-15 20:14:09,578 - CRDS - INFO - Fetching /home/runner/crds/mappings/jwst/jwst_nirspec_pars-cleanflickernoisestep_0002.rmap 983 bytes (31 / 224 files) (95.1 K / 796.2 K bytes)
2026-04-15 20:14:09,668 - CRDS - INFO - Fetching /home/runner/crds/mappings/jwst/jwst_nirspec_pars-adaptivetracemodelstep_0002.rmap 997 bytes (32 / 224 files) (96.1 K / 796.2 K bytes)
2026-04-15 20:14:09,743 - CRDS - INFO - Fetching /home/runner/crds/mappings/jwst/jwst_nirspec_ote_0030.rmap 1.3 K bytes (33 / 224 files) (97.1 K / 796.2 K bytes)
2026-04-15 20:14:09,829 - CRDS - INFO - Fetching /home/runner/crds/mappings/jwst/jwst_nirspec_msaoper_0018.rmap 1.6 K bytes (34 / 224 files) (98.3 K / 796.2 K bytes)
2026-04-15 20:14:09,915 - CRDS - INFO - Fetching /home/runner/crds/mappings/jwst/jwst_nirspec_msa_0027.rmap 1.3 K bytes (35 / 224 files) (100.0 K / 796.2 K bytes)
2026-04-15 20:14:10,004 - CRDS - INFO - Fetching /home/runner/crds/mappings/jwst/jwst_nirspec_mask_0045.rmap 4.9 K bytes (36 / 224 files) (101.2 K / 796.2 K bytes)
2026-04-15 20:14:10,108 - CRDS - INFO - Fetching /home/runner/crds/mappings/jwst/jwst_nirspec_linearity_0017.rmap 1.6 K bytes (37 / 224 files) (106.2 K / 796.2 K bytes)
2026-04-15 20:14:10,198 - CRDS - INFO - Fetching /home/runner/crds/mappings/jwst/jwst_nirspec_ipc_0006.rmap 876 bytes (38 / 224 files) (107.7 K / 796.2 K bytes)
2026-04-15 20:14:10,279 - CRDS - INFO - Fetching /home/runner/crds/mappings/jwst/jwst_nirspec_ifuslicer_0018.rmap 1.5 K bytes (39 / 224 files) (108.6 K / 796.2 K bytes)
2026-04-15 20:14:10,359 - CRDS - INFO - Fetching /home/runner/crds/mappings/jwst/jwst_nirspec_ifupost_0020.rmap 1.5 K bytes (40 / 224 files) (110.1 K / 796.2 K bytes)
2026-04-15 20:14:10,437 - CRDS - INFO - Fetching /home/runner/crds/mappings/jwst/jwst_nirspec_ifufore_0017.rmap 1.5 K bytes (41 / 224 files) (111.6 K / 796.2 K bytes)
2026-04-15 20:14:10,523 - CRDS - INFO - Fetching /home/runner/crds/mappings/jwst/jwst_nirspec_gain_0023.rmap 1.8 K bytes (42 / 224 files) (113.1 K / 796.2 K bytes)
2026-04-15 20:14:10,607 - CRDS - INFO - Fetching /home/runner/crds/mappings/jwst/jwst_nirspec_fpa_0028.rmap 1.3 K bytes (43 / 224 files) (114.9 K / 796.2 K bytes)
2026-04-15 20:14:10,689 - CRDS - INFO - Fetching /home/runner/crds/mappings/jwst/jwst_nirspec_fore_0026.rmap 5.0 K bytes (44 / 224 files) (116.2 K / 796.2 K bytes)
2026-04-15 20:14:10,778 - CRDS - INFO - Fetching /home/runner/crds/mappings/jwst/jwst_nirspec_flat_0015.rmap 3.8 K bytes (45 / 224 files) (121.1 K / 796.2 K bytes)
2026-04-15 20:14:10,863 - CRDS - INFO - Fetching /home/runner/crds/mappings/jwst/jwst_nirspec_fflat_0030.rmap 7.2 K bytes (46 / 224 files) (124.9 K / 796.2 K bytes)
2026-04-15 20:14:10,951 - CRDS - INFO - Fetching /home/runner/crds/mappings/jwst/jwst_nirspec_extract1d_0018.rmap 2.3 K bytes (47 / 224 files) (132.1 K / 796.2 K bytes)
2026-04-15 20:14:11,095 - CRDS - INFO - Fetching /home/runner/crds/mappings/jwst/jwst_nirspec_disperser_0028.rmap 5.7 K bytes (48 / 224 files) (134.4 K / 796.2 K bytes)
2026-04-15 20:14:11,194 - CRDS - INFO - Fetching /home/runner/crds/mappings/jwst/jwst_nirspec_dflat_0007.rmap 1.1 K bytes (49 / 224 files) (140.1 K / 796.2 K bytes)
2026-04-15 20:14:11,288 - CRDS - INFO - Fetching /home/runner/crds/mappings/jwst/jwst_nirspec_dark_0085.rmap 37.4 K bytes (50 / 224 files) (141.3 K / 796.2 K bytes)
2026-04-15 20:14:11,391 - CRDS - INFO - Fetching /home/runner/crds/mappings/jwst/jwst_nirspec_cubepar_0015.rmap 966 bytes (51 / 224 files) (178.7 K / 796.2 K bytes)
2026-04-15 20:14:11,481 - CRDS - INFO - Fetching /home/runner/crds/mappings/jwst/jwst_nirspec_collimator_0026.rmap 1.3 K bytes (52 / 224 files) (179.6 K / 796.2 K bytes)
2026-04-15 20:14:11,563 - CRDS - INFO - Fetching /home/runner/crds/mappings/jwst/jwst_nirspec_camera_0026.rmap 1.3 K bytes (53 / 224 files) (181.0 K / 796.2 K bytes)
2026-04-15 20:14:11,645 - CRDS - INFO - Fetching /home/runner/crds/mappings/jwst/jwst_nirspec_barshadow_0007.rmap 1.8 K bytes (54 / 224 files) (182.3 K / 796.2 K bytes)
2026-04-15 20:14:11,729 - CRDS - INFO - Fetching /home/runner/crds/mappings/jwst/jwst_nirspec_area_0019.rmap 6.8 K bytes (55 / 224 files) (184.1 K / 796.2 K bytes)
2026-04-15 20:14:11,818 - CRDS - INFO - Fetching /home/runner/crds/mappings/jwst/jwst_nirspec_apcorr_0009.rmap 5.6 K bytes (56 / 224 files) (190.9 K / 796.2 K bytes)
2026-04-15 20:14:11,898 - CRDS - INFO - Fetching /home/runner/crds/mappings/jwst/jwst_nirspec_0432.imap 6.2 K bytes (57 / 224 files) (196.5 K / 796.2 K bytes)
2026-04-15 20:14:11,973 - CRDS - INFO - Fetching /home/runner/crds/mappings/jwst/jwst_niriss_wavelengthrange_0008.rmap 897 bytes (58 / 224 files) (202.6 K / 796.2 K bytes)
2026-04-15 20:14:12,056 - CRDS - INFO - Fetching /home/runner/crds/mappings/jwst/jwst_niriss_trappars_0004.rmap 753 bytes (59 / 224 files) (203.5 K / 796.2 K bytes)
2026-04-15 20:14:12,141 - CRDS - INFO - Fetching /home/runner/crds/mappings/jwst/jwst_niriss_trapdensity_0005.rmap 705 bytes (60 / 224 files) (204.3 K / 796.2 K bytes)
2026-04-15 20:14:12,217 - CRDS - INFO - Fetching /home/runner/crds/mappings/jwst/jwst_niriss_throughput_0005.rmap 1.3 K bytes (61 / 224 files) (205.0 K / 796.2 K bytes)
2026-04-15 20:14:12,325 - CRDS - INFO - Fetching /home/runner/crds/mappings/jwst/jwst_niriss_superbias_0035.rmap 8.3 K bytes (62 / 224 files) (206.2 K / 796.2 K bytes)
2026-04-15 20:14:12,403 - CRDS - INFO - Fetching /home/runner/crds/mappings/jwst/jwst_niriss_specwcs_0017.rmap 3.1 K bytes (63 / 224 files) (214.5 K / 796.2 K bytes)
2026-04-15 20:14:12,494 - CRDS - INFO - Fetching /home/runner/crds/mappings/jwst/jwst_niriss_specprofile_0010.rmap 2.5 K bytes (64 / 224 files) (217.7 K / 796.2 K bytes)
2026-04-15 20:14:12,575 - CRDS - INFO - Fetching /home/runner/crds/mappings/jwst/jwst_niriss_speckernel_0006.rmap 1.0 K bytes (65 / 224 files) (220.2 K / 796.2 K bytes)
2026-04-15 20:14:12,663 - CRDS - INFO - Fetching /home/runner/crds/mappings/jwst/jwst_niriss_sirskernel_0002.rmap 700 bytes (66 / 224 files) (221.2 K / 796.2 K bytes)
2026-04-15 20:14:13,745 - CRDS - INFO - Fetching /home/runner/crds/mappings/jwst/jwst_niriss_saturation_0015.rmap 829 bytes (67 / 224 files) (221.9 K / 796.2 K bytes)
2026-04-15 20:14:13,829 - CRDS - INFO - Fetching /home/runner/crds/mappings/jwst/jwst_niriss_readnoise_0011.rmap 987 bytes (68 / 224 files) (222.7 K / 796.2 K bytes)
2026-04-15 20:14:13,909 - CRDS - INFO - Fetching /home/runner/crds/mappings/jwst/jwst_niriss_photom_0041.rmap 1.3 K bytes (69 / 224 files) (223.7 K / 796.2 K bytes)
2026-04-15 20:14:13,992 - CRDS - INFO - Fetching /home/runner/crds/mappings/jwst/jwst_niriss_persat_0007.rmap 674 bytes (70 / 224 files) (225.0 K / 796.2 K bytes)
2026-04-15 20:14:14,085 - CRDS - INFO - Fetching /home/runner/crds/mappings/jwst/jwst_niriss_pathloss_0003.rmap 758 bytes (71 / 224 files) (225.6 K / 796.2 K bytes)
2026-04-15 20:14:14,168 - CRDS - INFO - Fetching /home/runner/crds/mappings/jwst/jwst_niriss_pastasoss_0006.rmap 818 bytes (72 / 224 files) (226.4 K / 796.2 K bytes)
2026-04-15 20:14:14,254 - CRDS - INFO - Fetching /home/runner/crds/mappings/jwst/jwst_niriss_pars-wfsscontamstep_0001.rmap 797 bytes (73 / 224 files) (227.2 K / 796.2 K bytes)
2026-04-15 20:14:14,338 - CRDS - INFO - Fetching /home/runner/crds/mappings/jwst/jwst_niriss_pars-undersamplecorrectionstep_0001.rmap 904 bytes (74 / 224 files) (228.0 K / 796.2 K bytes)
2026-04-15 20:14:14,419 - CRDS - INFO - Fetching /home/runner/crds/mappings/jwst/jwst_niriss_pars-tweakregstep_0012.rmap 3.1 K bytes (75 / 224 files) (228.9 K / 796.2 K bytes)
2026-04-15 20:14:14,503 - CRDS - INFO - Fetching /home/runner/crds/mappings/jwst/jwst_niriss_pars-spec2pipeline_0009.rmap 1.2 K bytes (76 / 224 files) (232.0 K / 796.2 K bytes)
2026-04-15 20:14:14,601 - CRDS - INFO - Fetching /home/runner/crds/mappings/jwst/jwst_niriss_pars-sourcecatalogstep_0002.rmap 2.3 K bytes (77 / 224 files) (233.3 K / 796.2 K bytes)
2026-04-15 20:14:14,682 - CRDS - INFO - Fetching /home/runner/crds/mappings/jwst/jwst_niriss_pars-resamplestep_0002.rmap 687 bytes (78 / 224 files) (235.6 K / 796.2 K bytes)
2026-04-15 20:14:14,764 - CRDS - INFO - Fetching /home/runner/crds/mappings/jwst/jwst_niriss_pars-outlierdetectionstep_0004.rmap 2.7 K bytes (79 / 224 files) (236.3 K / 796.2 K bytes)
2026-04-15 20:14:14,847 - CRDS - INFO - Fetching /home/runner/crds/mappings/jwst/jwst_niriss_pars-jumpstep_0007.rmap 6.4 K bytes (80 / 224 files) (239.0 K / 796.2 K bytes)
2026-04-15 20:14:14,933 - CRDS - INFO - Fetching /home/runner/crds/mappings/jwst/jwst_niriss_pars-image2pipeline_0005.rmap 1.0 K bytes (81 / 224 files) (245.3 K / 796.2 K bytes)
2026-04-15 20:14:15,012 - CRDS - INFO - Fetching /home/runner/crds/mappings/jwst/jwst_niriss_pars-detector1pipeline_0005.rmap 1.5 K bytes (82 / 224 files) (246.3 K / 796.2 K bytes)
2026-04-15 20:14:15,101 - CRDS - INFO - Fetching /home/runner/crds/mappings/jwst/jwst_niriss_pars-darkpipeline_0002.rmap 868 bytes (83 / 224 files) (247.9 K / 796.2 K bytes)
2026-04-15 20:14:15,180 - CRDS - INFO - Fetching /home/runner/crds/mappings/jwst/jwst_niriss_pars-darkcurrentstep_0001.rmap 591 bytes (84 / 224 files) (248.8 K / 796.2 K bytes)
2026-04-15 20:14:15,263 - CRDS - INFO - Fetching /home/runner/crds/mappings/jwst/jwst_niriss_pars-cleanflickernoisestep_0003.rmap 1.2 K bytes (85 / 224 files) (249.3 K / 796.2 K bytes)
2026-04-15 20:14:15,343 - CRDS - INFO - Fetching /home/runner/crds/mappings/jwst/jwst_niriss_pars-chargemigrationstep_0005.rmap 5.7 K bytes (86 / 224 files) (250.6 K / 796.2 K bytes)
2026-04-15 20:14:15,436 - CRDS - INFO - Fetching /home/runner/crds/mappings/jwst/jwst_niriss_pars-backgroundstep_0003.rmap 822 bytes (87 / 224 files) (256.2 K / 796.2 K bytes)
2026-04-15 20:14:15,535 - CRDS - INFO - Fetching /home/runner/crds/mappings/jwst/jwst_niriss_nrm_0005.rmap 663 bytes (88 / 224 files) (257.0 K / 796.2 K bytes)
2026-04-15 20:14:15,623 - CRDS - INFO - Fetching /home/runner/crds/mappings/jwst/jwst_niriss_mask_0025.rmap 1.6 K bytes (89 / 224 files) (257.7 K / 796.2 K bytes)
2026-04-15 20:14:15,703 - CRDS - INFO - Fetching /home/runner/crds/mappings/jwst/jwst_niriss_linearity_0022.rmap 961 bytes (90 / 224 files) (259.3 K / 796.2 K bytes)
2026-04-15 20:14:15,780 - CRDS - INFO - Fetching /home/runner/crds/mappings/jwst/jwst_niriss_ipc_0007.rmap 651 bytes (91 / 224 files) (260.3 K / 796.2 K bytes)
2026-04-15 20:14:15,870 - CRDS - INFO - Fetching /home/runner/crds/mappings/jwst/jwst_niriss_gain_0011.rmap 797 bytes (92 / 224 files) (260.9 K / 796.2 K bytes)
2026-04-15 20:14:15,963 - CRDS - INFO - Fetching /home/runner/crds/mappings/jwst/jwst_niriss_flat_0023.rmap 5.9 K bytes (93 / 224 files) (261.7 K / 796.2 K bytes)
2026-04-15 20:14:16,059 - CRDS - INFO - Fetching /home/runner/crds/mappings/jwst/jwst_niriss_filteroffset_0010.rmap 853 bytes (94 / 224 files) (267.6 K / 796.2 K bytes)
2026-04-15 20:14:16,145 - CRDS - INFO - Fetching /home/runner/crds/mappings/jwst/jwst_niriss_extract1d_0007.rmap 905 bytes (95 / 224 files) (268.4 K / 796.2 K bytes)
2026-04-15 20:14:16,237 - CRDS - INFO - Fetching /home/runner/crds/mappings/jwst/jwst_niriss_drizpars_0004.rmap 519 bytes (96 / 224 files) (269.3 K / 796.2 K bytes)
2026-04-15 20:14:16,321 - CRDS - INFO - Fetching /home/runner/crds/mappings/jwst/jwst_niriss_distortion_0025.rmap 3.4 K bytes (97 / 224 files) (269.9 K / 796.2 K bytes)
2026-04-15 20:14:16,404 - CRDS - INFO - Fetching /home/runner/crds/mappings/jwst/jwst_niriss_dark_0039.rmap 8.3 K bytes (98 / 224 files) (273.3 K / 796.2 K bytes)
2026-04-15 20:14:16,491 - CRDS - INFO - Fetching /home/runner/crds/mappings/jwst/jwst_niriss_bkg_0005.rmap 3.1 K bytes (99 / 224 files) (281.6 K / 796.2 K bytes)
2026-04-15 20:14:16,586 - CRDS - INFO - Fetching /home/runner/crds/mappings/jwst/jwst_niriss_area_0014.rmap 2.7 K bytes (100 / 224 files) (284.7 K / 796.2 K bytes)
2026-04-15 20:14:16,669 - CRDS - INFO - Fetching /home/runner/crds/mappings/jwst/jwst_niriss_apcorr_0010.rmap 4.3 K bytes (101 / 224 files) (287.4 K / 796.2 K bytes)
2026-04-15 20:14:16,749 - CRDS - INFO - Fetching /home/runner/crds/mappings/jwst/jwst_niriss_abvegaoffset_0004.rmap 1.4 K bytes (102 / 224 files) (291.7 K / 796.2 K bytes)
2026-04-15 20:14:16,831 - CRDS - INFO - Fetching /home/runner/crds/mappings/jwst/jwst_niriss_0308.imap 5.9 K bytes (103 / 224 files) (293.0 K / 796.2 K bytes)
2026-04-15 20:14:16,922 - CRDS - INFO - Fetching /home/runner/crds/mappings/jwst/jwst_nircam_wavelengthrange_0012.rmap 996 bytes (104 / 224 files) (299.0 K / 796.2 K bytes)
2026-04-15 20:14:17,010 - CRDS - INFO - Fetching /home/runner/crds/mappings/jwst/jwst_nircam_tsophot_0003.rmap 896 bytes (105 / 224 files) (300.0 K / 796.2 K bytes)
2026-04-15 20:14:17,092 - CRDS - INFO - Fetching /home/runner/crds/mappings/jwst/jwst_nircam_trappars_0003.rmap 1.6 K bytes (106 / 224 files) (300.9 K / 796.2 K bytes)
2026-04-15 20:14:17,181 - CRDS - INFO - Fetching /home/runner/crds/mappings/jwst/jwst_nircam_trapdensity_0003.rmap 1.6 K bytes (107 / 224 files) (302.5 K / 796.2 K bytes)
2026-04-15 20:14:17,264 - CRDS - INFO - Fetching /home/runner/crds/mappings/jwst/jwst_nircam_superbias_0022.rmap 25.5 K bytes (108 / 224 files) (304.1 K / 796.2 K bytes)
2026-04-15 20:14:17,370 - CRDS - INFO - Fetching /home/runner/crds/mappings/jwst/jwst_nircam_specwcs_0027.rmap 8.0 K bytes (109 / 224 files) (329.6 K / 796.2 K bytes)
2026-04-15 20:14:17,451 - CRDS - INFO - Fetching /home/runner/crds/mappings/jwst/jwst_nircam_sirskernel_0003.rmap 671 bytes (110 / 224 files) (337.6 K / 796.2 K bytes)
2026-04-15 20:14:17,534 - CRDS - INFO - Fetching /home/runner/crds/mappings/jwst/jwst_nircam_saturation_0011.rmap 2.8 K bytes (111 / 224 files) (338.3 K / 796.2 K bytes)
2026-04-15 20:14:17,611 - CRDS - INFO - Fetching /home/runner/crds/mappings/jwst/jwst_nircam_regions_0003.rmap 3.4 K bytes (112 / 224 files) (341.1 K / 796.2 K bytes)
2026-04-15 20:14:17,699 - CRDS - INFO - Fetching /home/runner/crds/mappings/jwst/jwst_nircam_readnoise_0028.rmap 27.1 K bytes (113 / 224 files) (344.5 K / 796.2 K bytes)
2026-04-15 20:14:17,798 - CRDS - INFO - Fetching /home/runner/crds/mappings/jwst/jwst_nircam_psfmask_0008.rmap 28.4 K bytes (114 / 224 files) (371.7 K / 796.2 K bytes)
2026-04-15 20:14:17,903 - CRDS - INFO - Fetching /home/runner/crds/mappings/jwst/jwst_nircam_photom_0031.rmap 3.4 K bytes (115 / 224 files) (400.0 K / 796.2 K bytes)
2026-04-15 20:14:17,985 - CRDS - INFO - Fetching /home/runner/crds/mappings/jwst/jwst_nircam_persat_0005.rmap 1.6 K bytes (116 / 224 files) (403.5 K / 796.2 K bytes)
2026-04-15 20:14:18,068 - CRDS - INFO - Fetching /home/runner/crds/mappings/jwst/jwst_nircam_pars-whitelightstep_0004.rmap 2.0 K bytes (117 / 224 files) (405.0 K / 796.2 K bytes)
2026-04-15 20:14:18,165 - CRDS - INFO - Fetching /home/runner/crds/mappings/jwst/jwst_nircam_pars-wfsscontamstep_0001.rmap 797 bytes (118 / 224 files) (407.0 K / 796.2 K bytes)
2026-04-15 20:14:18,246 - CRDS - INFO - Fetching /home/runner/crds/mappings/jwst/jwst_nircam_pars-tweakregstep_0003.rmap 4.5 K bytes (119 / 224 files) (407.8 K / 796.2 K bytes)
2026-04-15 20:14:18,333 - CRDS - INFO - Fetching /home/runner/crds/mappings/jwst/jwst_nircam_pars-tsophotometrystep_0003.rmap 1.1 K bytes (120 / 224 files) (412.3 K / 796.2 K bytes)
2026-04-15 20:14:18,424 - CRDS - INFO - Fetching /home/runner/crds/mappings/jwst/jwst_nircam_pars-spec2pipeline_0009.rmap 984 bytes (121 / 224 files) (413.4 K / 796.2 K bytes)
2026-04-15 20:14:18,517 - CRDS - INFO - Fetching /home/runner/crds/mappings/jwst/jwst_nircam_pars-sourcecatalogstep_0002.rmap 4.6 K bytes (122 / 224 files) (414.4 K / 796.2 K bytes)
2026-04-15 20:14:18,604 - CRDS - INFO - Fetching /home/runner/crds/mappings/jwst/jwst_nircam_pars-resamplestep_0002.rmap 687 bytes (123 / 224 files) (419.0 K / 796.2 K bytes)
2026-04-15 20:14:18,692 - CRDS - INFO - Fetching /home/runner/crds/mappings/jwst/jwst_nircam_pars-outlierdetectionstep_0003.rmap 940 bytes (124 / 224 files) (419.7 K / 796.2 K bytes)
2026-04-15 20:14:18,778 - CRDS - INFO - Fetching /home/runner/crds/mappings/jwst/jwst_nircam_pars-jumpstep_0005.rmap 806 bytes (125 / 224 files) (420.6 K / 796.2 K bytes)
2026-04-15 20:14:18,867 - CRDS - INFO - Fetching /home/runner/crds/mappings/jwst/jwst_nircam_pars-image2pipeline_0004.rmap 1.1 K bytes (126 / 224 files) (421.4 K / 796.2 K bytes)
2026-04-15 20:14:18,952 - CRDS - INFO - Fetching /home/runner/crds/mappings/jwst/jwst_nircam_pars-detector1pipeline_0007.rmap 1.7 K bytes (127 / 224 files) (422.6 K / 796.2 K bytes)
2026-04-15 20:14:19,033 - CRDS - INFO - Fetching /home/runner/crds/mappings/jwst/jwst_nircam_pars-darkpipeline_0002.rmap 868 bytes (128 / 224 files) (424.3 K / 796.2 K bytes)
2026-04-15 20:14:19,125 - CRDS - INFO - Fetching /home/runner/crds/mappings/jwst/jwst_nircam_pars-darkcurrentstep_0001.rmap 618 bytes (129 / 224 files) (425.2 K / 796.2 K bytes)
2026-04-15 20:14:19,208 - CRDS - INFO - Fetching /home/runner/crds/mappings/jwst/jwst_nircam_pars-backgroundstep_0003.rmap 822 bytes (130 / 224 files) (425.8 K / 796.2 K bytes)
2026-04-15 20:14:19,289 - CRDS - INFO - Fetching /home/runner/crds/mappings/jwst/jwst_nircam_mask_0014.rmap 5.4 K bytes (131 / 224 files) (426.6 K / 796.2 K bytes)
2026-04-15 20:14:19,366 - CRDS - INFO - Fetching /home/runner/crds/mappings/jwst/jwst_nircam_linearity_0011.rmap 2.4 K bytes (132 / 224 files) (432.0 K / 796.2 K bytes)
2026-04-15 20:14:19,447 - CRDS - INFO - Fetching /home/runner/crds/mappings/jwst/jwst_nircam_ipc_0003.rmap 2.0 K bytes (133 / 224 files) (434.4 K / 796.2 K bytes)
2026-04-15 20:14:19,527 - CRDS - INFO - Fetching /home/runner/crds/mappings/jwst/jwst_nircam_gain_0016.rmap 2.1 K bytes (134 / 224 files) (436.4 K / 796.2 K bytes)
2026-04-15 20:14:19,614 - CRDS - INFO - Fetching /home/runner/crds/mappings/jwst/jwst_nircam_flat_0028.rmap 51.7 K bytes (135 / 224 files) (438.5 K / 796.2 K bytes)
2026-04-15 20:14:19,743 - CRDS - INFO - Fetching /home/runner/crds/mappings/jwst/jwst_nircam_filteroffset_0004.rmap 1.4 K bytes (136 / 224 files) (490.2 K / 796.2 K bytes)
2026-04-15 20:14:19,831 - CRDS - INFO - Fetching /home/runner/crds/mappings/jwst/jwst_nircam_extract1d_0007.rmap 2.2 K bytes (137 / 224 files) (491.6 K / 796.2 K bytes)
2026-04-15 20:14:19,922 - CRDS - INFO - Fetching /home/runner/crds/mappings/jwst/jwst_nircam_drizpars_0001.rmap 519 bytes (138 / 224 files) (493.8 K / 796.2 K bytes)
2026-04-15 20:14:20,006 - CRDS - INFO - Fetching /home/runner/crds/mappings/jwst/jwst_nircam_distortion_0034.rmap 53.4 K bytes (139 / 224 files) (494.3 K / 796.2 K bytes)
2026-04-15 20:14:20,131 - CRDS - INFO - Fetching /home/runner/crds/mappings/jwst/jwst_nircam_dark_0054.rmap 33.9 K bytes (140 / 224 files) (547.6 K / 796.2 K bytes)
2026-04-15 20:14:20,237 - CRDS - INFO - Fetching /home/runner/crds/mappings/jwst/jwst_nircam_bkg_0002.rmap 7.0 K bytes (141 / 224 files) (581.5 K / 796.2 K bytes)
2026-04-15 20:14:20,320 - CRDS - INFO - Fetching /home/runner/crds/mappings/jwst/jwst_nircam_area_0012.rmap 33.5 K bytes (142 / 224 files) (588.5 K / 796.2 K bytes)
2026-04-15 20:14:20,423 - CRDS - INFO - Fetching /home/runner/crds/mappings/jwst/jwst_nircam_apcorr_0009.rmap 4.3 K bytes (143 / 224 files) (622.0 K / 796.2 K bytes)
2026-04-15 20:14:20,506 - CRDS - INFO - Fetching /home/runner/crds/mappings/jwst/jwst_nircam_abvegaoffset_0004.rmap 1.3 K bytes (144 / 224 files) (626.2 K / 796.2 K bytes)
2026-04-15 20:14:20,593 - CRDS - INFO - Fetching /home/runner/crds/mappings/jwst/jwst_nircam_0354.imap 5.8 K bytes (145 / 224 files) (627.5 K / 796.2 K bytes)
2026-04-15 20:14:20,682 - CRDS - INFO - Fetching /home/runner/crds/mappings/jwst/jwst_miri_wavelengthrange_0030.rmap 1.0 K bytes (146 / 224 files) (633.3 K / 796.2 K bytes)
2026-04-15 20:14:20,766 - CRDS - INFO - Fetching /home/runner/crds/mappings/jwst/jwst_miri_tsophot_0004.rmap 882 bytes (147 / 224 files) (634.3 K / 796.2 K bytes)
2026-04-15 20:14:20,857 - CRDS - INFO - Fetching /home/runner/crds/mappings/jwst/jwst_miri_straymask_0009.rmap 987 bytes (148 / 224 files) (635.2 K / 796.2 K bytes)
2026-04-15 20:14:20,933 - CRDS - INFO - Fetching /home/runner/crds/mappings/jwst/jwst_miri_specwcs_0048.rmap 5.9 K bytes (149 / 224 files) (636.2 K / 796.2 K bytes)
2026-04-15 20:14:21,014 - CRDS - INFO - Fetching /home/runner/crds/mappings/jwst/jwst_miri_saturation_0015.rmap 1.2 K bytes (150 / 224 files) (642.1 K / 796.2 K bytes)
2026-04-15 20:14:21,099 - CRDS - INFO - Fetching /home/runner/crds/mappings/jwst/jwst_miri_rscd_0010.rmap 1.0 K bytes (151 / 224 files) (643.3 K / 796.2 K bytes)
2026-04-15 20:14:21,180 - CRDS - INFO - Fetching /home/runner/crds/mappings/jwst/jwst_miri_resol_0006.rmap 790 bytes (152 / 224 files) (644.3 K / 796.2 K bytes)
2026-04-15 20:14:21,257 - CRDS - INFO - Fetching /home/runner/crds/mappings/jwst/jwst_miri_reset_0026.rmap 3.9 K bytes (153 / 224 files) (645.1 K / 796.2 K bytes)
2026-04-15 20:14:21,338 - CRDS - INFO - Fetching /home/runner/crds/mappings/jwst/jwst_miri_regions_0036.rmap 4.4 K bytes (154 / 224 files) (649.0 K / 796.2 K bytes)
2026-04-15 20:14:21,425 - CRDS - INFO - Fetching /home/runner/crds/mappings/jwst/jwst_miri_readnoise_0023.rmap 1.6 K bytes (155 / 224 files) (653.3 K / 796.2 K bytes)
2026-04-15 20:14:21,579 - CRDS - INFO - Fetching /home/runner/crds/mappings/jwst/jwst_miri_psfmask_0009.rmap 2.1 K bytes (156 / 224 files) (655.0 K / 796.2 K bytes)
2026-04-15 20:14:21,659 - CRDS - INFO - Fetching /home/runner/crds/mappings/jwst/jwst_miri_psf_0008.rmap 2.6 K bytes (157 / 224 files) (657.1 K / 796.2 K bytes)
2026-04-15 20:14:21,749 - CRDS - INFO - Fetching /home/runner/crds/mappings/jwst/jwst_miri_photom_0063.rmap 3.9 K bytes (158 / 224 files) (659.7 K / 796.2 K bytes)
2026-04-15 20:14:21,833 - CRDS - INFO - Fetching /home/runner/crds/mappings/jwst/jwst_miri_pathloss_0005.rmap 866 bytes (159 / 224 files) (663.6 K / 796.2 K bytes)
2026-04-15 20:14:21,913 - CRDS - INFO - Fetching /home/runner/crds/mappings/jwst/jwst_miri_pars-whitelightstep_0003.rmap 912 bytes (160 / 224 files) (664.4 K / 796.2 K bytes)
2026-04-15 20:14:21,992 - CRDS - INFO - Fetching /home/runner/crds/mappings/jwst/jwst_miri_pars-wfsscontamstep_0001.rmap 787 bytes (161 / 224 files) (665.4 K / 796.2 K bytes)
2026-04-15 20:14:22,082 - CRDS - INFO - Fetching /home/runner/crds/mappings/jwst/jwst_miri_pars-tweakregstep_0003.rmap 1.8 K bytes (162 / 224 files) (666.1 K / 796.2 K bytes)
2026-04-15 20:14:22,166 - CRDS - INFO - Fetching /home/runner/crds/mappings/jwst/jwst_miri_pars-tsophotometrystep_0003.rmap 2.7 K bytes (163 / 224 files) (668.0 K / 796.2 K bytes)
2026-04-15 20:14:22,248 - CRDS - INFO - Fetching /home/runner/crds/mappings/jwst/jwst_miri_pars-spec3pipeline_0011.rmap 886 bytes (164 / 224 files) (670.6 K / 796.2 K bytes)
2026-04-15 20:14:22,331 - CRDS - INFO - Fetching /home/runner/crds/mappings/jwst/jwst_miri_pars-spec2pipeline_0013.rmap 1.4 K bytes (165 / 224 files) (671.5 K / 796.2 K bytes)
2026-04-15 20:14:22,413 - CRDS - INFO - Fetching /home/runner/crds/mappings/jwst/jwst_miri_pars-sourcecatalogstep_0003.rmap 1.9 K bytes (166 / 224 files) (672.9 K / 796.2 K bytes)
2026-04-15 20:14:22,498 - CRDS - INFO - Fetching /home/runner/crds/mappings/jwst/jwst_miri_pars-resamplestep_0002.rmap 677 bytes (167 / 224 files) (674.9 K / 796.2 K bytes)
2026-04-15 20:14:22,575 - CRDS - INFO - Fetching /home/runner/crds/mappings/jwst/jwst_miri_pars-resamplespecstep_0002.rmap 706 bytes (168 / 224 files) (675.5 K / 796.2 K bytes)
2026-04-15 20:14:22,657 - CRDS - INFO - Fetching /home/runner/crds/mappings/jwst/jwst_miri_pars-outlierdetectionstep_0020.rmap 3.4 K bytes (169 / 224 files) (676.2 K / 796.2 K bytes)
2026-04-15 20:14:22,747 - CRDS - INFO - Fetching /home/runner/crds/mappings/jwst/jwst_miri_pars-jumpstep_0011.rmap 1.6 K bytes (170 / 224 files) (679.6 K / 796.2 K bytes)
2026-04-15 20:14:22,830 - CRDS - INFO - Fetching /home/runner/crds/mappings/jwst/jwst_miri_pars-image2pipeline_0010.rmap 1.1 K bytes (171 / 224 files) (681.2 K / 796.2 K bytes)
2026-04-15 20:14:22,915 - CRDS - INFO - Fetching /home/runner/crds/mappings/jwst/jwst_miri_pars-extract1dstep_0003.rmap 807 bytes (172 / 224 files) (682.3 K / 796.2 K bytes)
2026-04-15 20:14:22,998 - CRDS - INFO - Fetching /home/runner/crds/mappings/jwst/jwst_miri_pars-emicorrstep_0003.rmap 796 bytes (173 / 224 files) (683.1 K / 796.2 K bytes)
2026-04-15 20:14:23,080 - CRDS - INFO - Fetching /home/runner/crds/mappings/jwst/jwst_miri_pars-detector1pipeline_0010.rmap 1.6 K bytes (174 / 224 files) (683.9 K / 796.2 K bytes)
2026-04-15 20:14:23,159 - CRDS - INFO - Fetching /home/runner/crds/mappings/jwst/jwst_miri_pars-darkpipeline_0002.rmap 860 bytes (175 / 224 files) (685.5 K / 796.2 K bytes)
2026-04-15 20:14:23,247 - CRDS - INFO - Fetching /home/runner/crds/mappings/jwst/jwst_miri_pars-darkcurrentstep_0002.rmap 683 bytes (176 / 224 files) (686.3 K / 796.2 K bytes)
2026-04-15 20:14:23,330 - CRDS - INFO - Fetching /home/runner/crds/mappings/jwst/jwst_miri_pars-backgroundstep_0003.rmap 814 bytes (177 / 224 files) (687.0 K / 796.2 K bytes)
2026-04-15 20:14:23,410 - CRDS - INFO - Fetching /home/runner/crds/mappings/jwst/jwst_miri_pars-adaptivetracemodelstep_0002.rmap 979 bytes (178 / 224 files) (687.8 K / 796.2 K bytes)
2026-04-15 20:14:23,487 - CRDS - INFO - Fetching /home/runner/crds/mappings/jwst/jwst_miri_mrsxartcorr_0002.rmap 2.2 K bytes (179 / 224 files) (688.8 K / 796.2 K bytes)
2026-04-15 20:14:23,569 - CRDS - INFO - Fetching /home/runner/crds/mappings/jwst/jwst_miri_mrsptcorr_0005.rmap 2.0 K bytes (180 / 224 files) (691.0 K / 796.2 K bytes)
2026-04-15 20:14:23,656 - CRDS - INFO - Fetching /home/runner/crds/mappings/jwst/jwst_miri_mask_0036.rmap 8.6 K bytes (181 / 224 files) (692.9 K / 796.2 K bytes)
2026-04-15 20:14:23,735 - CRDS - INFO - Fetching /home/runner/crds/mappings/jwst/jwst_miri_linearity_0018.rmap 2.8 K bytes (182 / 224 files) (701.6 K / 796.2 K bytes)
2026-04-15 20:14:23,818 - CRDS - INFO - Fetching /home/runner/crds/mappings/jwst/jwst_miri_ipc_0008.rmap 700 bytes (183 / 224 files) (704.4 K / 796.2 K bytes)
2026-04-15 20:14:23,898 - CRDS - INFO - Fetching /home/runner/crds/mappings/jwst/jwst_miri_gain_0013.rmap 3.9 K bytes (184 / 224 files) (705.1 K / 796.2 K bytes)
2026-04-15 20:14:23,977 - CRDS - INFO - Fetching /home/runner/crds/mappings/jwst/jwst_miri_fringefreq_0003.rmap 1.4 K bytes (185 / 224 files) (709.0 K / 796.2 K bytes)
2026-04-15 20:14:24,062 - CRDS - INFO - Fetching /home/runner/crds/mappings/jwst/jwst_miri_fringe_0019.rmap 3.9 K bytes (186 / 224 files) (710.5 K / 796.2 K bytes)
2026-04-15 20:14:24,148 - CRDS - INFO - Fetching /home/runner/crds/mappings/jwst/jwst_miri_flat_0073.rmap 16.5 K bytes (187 / 224 files) (714.4 K / 796.2 K bytes)
2026-04-15 20:14:24,248 - CRDS - INFO - Fetching /home/runner/crds/mappings/jwst/jwst_miri_filteroffset_0029.rmap 2.4 K bytes (188 / 224 files) (730.9 K / 796.2 K bytes)
2026-04-15 20:14:24,334 - CRDS - INFO - Fetching /home/runner/crds/mappings/jwst/jwst_miri_extract1d_0022.rmap 1.0 K bytes (189 / 224 files) (733.3 K / 796.2 K bytes)
2026-04-15 20:14:24,419 - CRDS - INFO - Fetching /home/runner/crds/mappings/jwst/jwst_miri_emicorr_0004.rmap 663 bytes (190 / 224 files) (734.3 K / 796.2 K bytes)
2026-04-15 20:14:24,502 - CRDS - INFO - Fetching /home/runner/crds/mappings/jwst/jwst_miri_drizpars_0002.rmap 511 bytes (191 / 224 files) (735.0 K / 796.2 K bytes)
2026-04-15 20:14:24,585 - CRDS - INFO - Fetching /home/runner/crds/mappings/jwst/jwst_miri_distortion_0043.rmap 4.8 K bytes (192 / 224 files) (735.5 K / 796.2 K bytes)
2026-04-15 20:14:24,666 - CRDS - INFO - Fetching /home/runner/crds/mappings/jwst/jwst_miri_dark_0039.rmap 4.3 K bytes (193 / 224 files) (740.3 K / 796.2 K bytes)
2026-04-15 20:14:24,766 - CRDS - INFO - Fetching /home/runner/crds/mappings/jwst/jwst_miri_cubepar_0017.rmap 800 bytes (194 / 224 files) (744.6 K / 796.2 K bytes)
2026-04-15 20:14:24,850 - CRDS - INFO - Fetching /home/runner/crds/mappings/jwst/jwst_miri_bkg_0004.rmap 712 bytes (195 / 224 files) (745.4 K / 796.2 K bytes)
2026-04-15 20:14:24,931 - CRDS - INFO - Fetching /home/runner/crds/mappings/jwst/jwst_miri_area_0015.rmap 866 bytes (196 / 224 files) (746.1 K / 796.2 K bytes)
2026-04-15 20:14:25,009 - CRDS - INFO - Fetching /home/runner/crds/mappings/jwst/jwst_miri_apcorr_0023.rmap 5.0 K bytes (197 / 224 files) (746.9 K / 796.2 K bytes)
2026-04-15 20:14:25,099 - CRDS - INFO - Fetching /home/runner/crds/mappings/jwst/jwst_miri_abvegaoffset_0003.rmap 1.3 K bytes (198 / 224 files) (752.0 K / 796.2 K bytes)
2026-04-15 20:14:25,184 - CRDS - INFO - Fetching /home/runner/crds/mappings/jwst/jwst_miri_0487.imap 6.0 K bytes (199 / 224 files) (753.2 K / 796.2 K bytes)
2026-04-15 20:14:25,272 - CRDS - INFO - Fetching /home/runner/crds/mappings/jwst/jwst_fgs_trappars_0004.rmap 903 bytes (200 / 224 files) (759.3 K / 796.2 K bytes)
2026-04-15 20:14:25,367 - CRDS - INFO - Fetching /home/runner/crds/mappings/jwst/jwst_fgs_trapdensity_0006.rmap 930 bytes (201 / 224 files) (760.2 K / 796.2 K bytes)
2026-04-15 20:14:25,448 - CRDS - INFO - Fetching /home/runner/crds/mappings/jwst/jwst_fgs_superbias_0017.rmap 3.8 K bytes (202 / 224 files) (761.1 K / 796.2 K bytes)
2026-04-15 20:14:25,526 - CRDS - INFO - Fetching /home/runner/crds/mappings/jwst/jwst_fgs_saturation_0009.rmap 779 bytes (203 / 224 files) (764.9 K / 796.2 K bytes)
2026-04-15 20:14:25,609 - CRDS - INFO - Fetching /home/runner/crds/mappings/jwst/jwst_fgs_readnoise_0014.rmap 1.3 K bytes (204 / 224 files) (765.7 K / 796.2 K bytes)
2026-04-15 20:14:25,686 - CRDS - INFO - Fetching /home/runner/crds/mappings/jwst/jwst_fgs_photom_0014.rmap 1.1 K bytes (205 / 224 files) (766.9 K / 796.2 K bytes)
2026-04-15 20:14:25,766 - CRDS - INFO - Fetching /home/runner/crds/mappings/jwst/jwst_fgs_persat_0006.rmap 884 bytes (206 / 224 files) (768.1 K / 796.2 K bytes)
2026-04-15 20:14:25,842 - CRDS - INFO - Fetching /home/runner/crds/mappings/jwst/jwst_fgs_pars-tweakregstep_0002.rmap 850 bytes (207 / 224 files) (769.0 K / 796.2 K bytes)
2026-04-15 20:14:25,976 - CRDS - INFO - Fetching /home/runner/crds/mappings/jwst/jwst_fgs_pars-sourcecatalogstep_0001.rmap 636 bytes (208 / 224 files) (769.8 K / 796.2 K bytes)
2026-04-15 20:14:26,065 - CRDS - INFO - Fetching /home/runner/crds/mappings/jwst/jwst_fgs_pars-outlierdetectionstep_0001.rmap 654 bytes (209 / 224 files) (770.4 K / 796.2 K bytes)
2026-04-15 20:14:26,148 - CRDS - INFO - Fetching /home/runner/crds/mappings/jwst/jwst_fgs_pars-image2pipeline_0005.rmap 974 bytes (210 / 224 files) (771.1 K / 796.2 K bytes)
2026-04-15 20:14:26,234 - CRDS - INFO - Fetching /home/runner/crds/mappings/jwst/jwst_fgs_pars-detector1pipeline_0002.rmap 1.0 K bytes (211 / 224 files) (772.1 K / 796.2 K bytes)
2026-04-15 20:14:26,318 - CRDS - INFO - Fetching /home/runner/crds/mappings/jwst/jwst_fgs_pars-darkpipeline_0002.rmap 856 bytes (212 / 224 files) (773.1 K / 796.2 K bytes)
2026-04-15 20:14:26,404 - CRDS - INFO - Fetching /home/runner/crds/mappings/jwst/jwst_fgs_mask_0023.rmap 1.1 K bytes (213 / 224 files) (774.0 K / 796.2 K bytes)
2026-04-15 20:14:26,486 - CRDS - INFO - Fetching /home/runner/crds/mappings/jwst/jwst_fgs_linearity_0015.rmap 925 bytes (214 / 224 files) (775.0 K / 796.2 K bytes)
2026-04-15 20:14:26,568 - CRDS - INFO - Fetching /home/runner/crds/mappings/jwst/jwst_fgs_ipc_0003.rmap 614 bytes (215 / 224 files) (775.9 K / 796.2 K bytes)
2026-04-15 20:14:26,651 - CRDS - INFO - Fetching /home/runner/crds/mappings/jwst/jwst_fgs_gain_0010.rmap 890 bytes (216 / 224 files) (776.5 K / 796.2 K bytes)
2026-04-15 20:14:26,731 - CRDS - INFO - Fetching /home/runner/crds/mappings/jwst/jwst_fgs_flat_0009.rmap 1.1 K bytes (217 / 224 files) (777.4 K / 796.2 K bytes)
2026-04-15 20:14:26,810 - CRDS - INFO - Fetching /home/runner/crds/mappings/jwst/jwst_fgs_distortion_0011.rmap 1.2 K bytes (218 / 224 files) (778.6 K / 796.2 K bytes)
2026-04-15 20:14:26,894 - CRDS - INFO - Fetching /home/runner/crds/mappings/jwst/jwst_fgs_dark_0017.rmap 4.3 K bytes (219 / 224 files) (779.8 K / 796.2 K bytes)
2026-04-15 20:14:26,982 - CRDS - INFO - Fetching /home/runner/crds/mappings/jwst/jwst_fgs_area_0010.rmap 1.2 K bytes (220 / 224 files) (784.1 K / 796.2 K bytes)
2026-04-15 20:14:27,067 - CRDS - INFO - Fetching /home/runner/crds/mappings/jwst/jwst_fgs_apcorr_0004.rmap 4.0 K bytes (221 / 224 files) (785.2 K / 796.2 K bytes)
2026-04-15 20:14:27,148 - CRDS - INFO - Fetching /home/runner/crds/mappings/jwst/jwst_fgs_abvegaoffset_0002.rmap 1.3 K bytes (222 / 224 files) (789.2 K / 796.2 K bytes)
2026-04-15 20:14:27,230 - CRDS - INFO - Fetching /home/runner/crds/mappings/jwst/jwst_fgs_0125.imap 5.1 K bytes (223 / 224 files) (790.5 K / 796.2 K bytes)
2026-04-15 20:14:27,328 - CRDS - INFO - Fetching /home/runner/crds/mappings/jwst/jwst_1535.pmap 580 bytes (224 / 224 files) (795.6 K / 796.2 K bytes)
2026-04-15 20:14:27,556 - CRDS - ERROR - Error determining best reference for 'pars-darkcurrentstep' = No match found.
2026-04-15 20:14:27,560 - CRDS - INFO - Fetching /home/runner/crds/references/jwst/niriss/jwst_niriss_pars-chargemigrationstep_0038.asdf 2.1 K bytes (1 / 1 files) (0 / 2.1 K bytes)
2026-04-15 20:14:27,648 - stpipe.step - INFO - PARS-CHARGEMIGRATIONSTEP parameters found: /home/runner/crds/references/jwst/niriss/jwst_niriss_pars-chargemigrationstep_0038.asdf
2026-04-15 20:14:27,659 - CRDS - INFO - Fetching /home/runner/crds/references/jwst/niriss/jwst_niriss_pars-jumpstep_0072.asdf 1.6 K bytes (1 / 1 files) (0 / 1.6 K bytes)
2026-04-15 20:14:27,757 - stpipe.step - INFO - PARS-JUMPSTEP parameters found: /home/runner/crds/references/jwst/niriss/jwst_niriss_pars-jumpstep_0072.asdf
2026-04-15 20:14:27,769 - CRDS - INFO - Fetching /home/runner/crds/references/jwst/niriss/jwst_niriss_pars-detector1pipeline_0004.asdf 1.7 K bytes (1 / 1 files) (0 / 1.7 K bytes)
2026-04-15 20:14:27,872 - stpipe.pipeline - INFO - PARS-DETECTOR1PIPELINE parameters found: /home/runner/crds/references/jwst/niriss/jwst_niriss_pars-detector1pipeline_0004.asdf
2026-04-15 20:14:27,888 - stpipe.step - INFO - Detector1Pipeline instance created.
2026-04-15 20:14:27,888 - stpipe.step - INFO - GroupScaleStep instance created.
2026-04-15 20:14:27,889 - stpipe.step - INFO - DQInitStep instance created.
2026-04-15 20:14:27,890 - stpipe.step - INFO - EmiCorrStep instance created.
2026-04-15 20:14:27,890 - stpipe.step - INFO - SaturationStep instance created.
2026-04-15 20:14:27,891 - stpipe.step - INFO - IPCStep instance created.
2026-04-15 20:14:27,892 - stpipe.step - INFO - SuperBiasStep instance created.
2026-04-15 20:14:27,893 - stpipe.step - INFO - RefPixStep instance created.
2026-04-15 20:14:27,893 - stpipe.step - INFO - RscdStep instance created.
2026-04-15 20:14:27,894 - stpipe.step - INFO - FirstFrameStep instance created.
2026-04-15 20:14:27,894 - stpipe.step - INFO - LastFrameStep instance created.
2026-04-15 20:14:27,895 - stpipe.step - INFO - LinearityStep instance created.
2026-04-15 20:14:27,896 - stpipe.step - INFO - DarkCurrentStep instance created.
2026-04-15 20:14:27,896 - stpipe.step - INFO - ResetStep instance created.
2026-04-15 20:14:27,897 - stpipe.step - INFO - PersistenceStep instance created.
2026-04-15 20:14:27,898 - stpipe.step - INFO - ChargeMigrationStep instance created.
2026-04-15 20:14:27,899 - stpipe.step - INFO - JumpStep instance created.
2026-04-15 20:14:27,899 - stpipe.step - INFO - PictureFrameStep instance created.
2026-04-15 20:14:27,900 - stpipe.step - INFO - CleanFlickerNoiseStep instance created.
2026-04-15 20:14:27,901 - stpipe.step - INFO - RampFitStep instance created.
2026-04-15 20:14:27,901 - stpipe.step - INFO - GainScaleStep instance created.
2026-04-15 20:14:28,078 - stpipe.step - INFO - Step Detector1Pipeline running with args ('./nis_ami_demo_data/PID_1093/uncal/jw01093012001_03102_00001_nis_uncal.fits',).
2026-04-15 20:14:28,093 - stpipe.step - INFO - Step Detector1Pipeline parameters are:
pre_hooks: []
post_hooks: []
output_file: None
output_dir: ./nis_ami_demo_data/PID_1093/stage1
output_ext: .fits
output_use_model: False
output_use_index: True
save_results: True
skip: False
suffix: None
search_output_file: True
input_dir: ''
save_calibrated_ramp: True
steps:
group_scale:
pre_hooks: []
post_hooks: []
output_file: None
output_dir: None
output_ext: .fits
output_use_model: False
output_use_index: True
save_results: False
skip: False
suffix: None
search_output_file: True
input_dir: ''
dq_init:
pre_hooks: []
post_hooks: []
output_file: None
output_dir: None
output_ext: .fits
output_use_model: False
output_use_index: True
save_results: False
skip: False
suffix: None
search_output_file: True
input_dir: ''
user_supplied_dq: None
emicorr:
pre_hooks: []
post_hooks: []
output_file: None
output_dir: None
output_ext: .fits
output_use_model: False
output_use_index: True
save_results: False
skip: True
suffix: None
search_output_file: True
input_dir: ''
algorithm: joint
nints_to_phase: None
nbins: None
scale_reference: True
onthefly_corr_freq: None
use_n_cycles: 3
fit_ints_separately: False
user_supplied_reffile: None
save_intermediate_results: False
saturation:
pre_hooks: []
post_hooks: []
output_file: None
output_dir: None
output_ext: .fits
output_use_model: False
output_use_index: True
save_results: False
skip: False
suffix: None
search_output_file: True
input_dir: ''
n_pix_grow_sat: 1
use_readpatt: True
ipc:
pre_hooks: []
post_hooks: []
output_file: None
output_dir: None
output_ext: .fits
output_use_model: False
output_use_index: True
save_results: False
skip: True
suffix: None
search_output_file: True
input_dir: ''
superbias:
pre_hooks: []
post_hooks: []
output_file: None
output_dir: None
output_ext: .fits
output_use_model: False
output_use_index: True
save_results: False
skip: False
suffix: None
search_output_file: True
input_dir: ''
refpix:
pre_hooks: []
post_hooks: []
output_file: None
output_dir: None
output_ext: .fits
output_use_model: False
output_use_index: True
save_results: False
skip: False
suffix: None
search_output_file: True
input_dir: ''
odd_even_columns: True
use_side_ref_pixels: True
side_smoothing_length: 11
side_gain: 1.0
odd_even_rows: True
ovr_corr_mitigation_ftr: 3.0
preserve_irs2_refpix: False
irs2_mean_subtraction: False
refpix_algorithm: median
sigreject: 4.0
gaussmooth: 1.0
halfwidth: 30
rscd:
pre_hooks: []
post_hooks: []
output_file: None
output_dir: None
output_ext: .fits
output_use_model: False
output_use_index: True
save_results: False
skip: False
suffix: None
search_output_file: True
input_dir: ''
firstframe:
pre_hooks: []
post_hooks: []
output_file: None
output_dir: None
output_ext: .fits
output_use_model: False
output_use_index: True
save_results: False
skip: True
suffix: None
search_output_file: True
input_dir: ''
bright_use_group1: True
lastframe:
pre_hooks: []
post_hooks: []
output_file: None
output_dir: None
output_ext: .fits
output_use_model: False
output_use_index: True
save_results: False
skip: False
suffix: None
search_output_file: True
input_dir: ''
linearity:
pre_hooks: []
post_hooks: []
output_file: None
output_dir: None
output_ext: .fits
output_use_model: False
output_use_index: True
save_results: False
skip: False
suffix: None
search_output_file: True
input_dir: ''
dark_current:
pre_hooks: []
post_hooks: []
output_file: None
output_dir: None
output_ext: .fits
output_use_model: False
output_use_index: True
save_results: False
skip: True
suffix: None
search_output_file: True
input_dir: ''
dark_output: None
average_dark_current: None
reset:
pre_hooks: []
post_hooks: []
output_file: None
output_dir: None
output_ext: .fits
output_use_model: False
output_use_index: True
save_results: False
skip: False
suffix: None
search_output_file: True
input_dir: ''
persistence:
pre_hooks: []
post_hooks: []
output_file: None
output_dir: None
output_ext: .fits
output_use_model: False
output_use_index: True
save_results: False
skip: True
suffix: None
search_output_file: True
input_dir: ''
input_trapsfilled: ''
flag_pers_cutoff: 40.0
save_persistence: False
save_trapsfilled: True
modify_input: False
charge_migration:
pre_hooks: []
post_hooks: []
output_file: None
output_dir: None
output_ext: .fits
output_use_model: False
output_use_index: True
save_results: False
skip: False
suffix: None
search_output_file: True
input_dir: ''
signal_threshold: 14465.0
jump:
pre_hooks: []
post_hooks: []
output_file: None
output_dir: None
output_ext: .fits
output_use_model: False
output_use_index: True
save_results: False
skip: False
suffix: None
search_output_file: True
input_dir: ''
rejection_threshold: 4.0
three_group_rejection_threshold: 6.0
four_group_rejection_threshold: 5.0
maximum_cores: half
flag_4_neighbors: False
max_jump_to_flag_neighbors: 200.0
min_jump_to_flag_neighbors: 10.0
after_jump_flag_dn1: 1000
after_jump_flag_time1: 90
after_jump_flag_dn2: 0
after_jump_flag_time2: 0
expand_large_events: True
min_sat_area: 5
min_jump_area: 15.0
expand_factor: 1.75
use_ellipses: False
sat_required_snowball: True
min_sat_radius_extend: 5.0
sat_expand: 0
edge_size: 20
mask_snowball_core_next_int: True
snowball_time_masked_next_int: 4000
find_showers: False
max_shower_amplitude: 4.0
extend_snr_threshold: 1.2
extend_min_area: 90
extend_inner_radius: 1.0
extend_outer_radius: 2.6
extend_ellipse_expand_ratio: 1.1
time_masked_after_shower: 15.0
min_diffs_single_pass: 10
max_extended_radius: 100
minimum_groups: 3
minimum_sigclip_groups: 100
only_use_ints: True
picture_frame:
pre_hooks: []
post_hooks: []
output_file: None
output_dir: None
output_ext: .fits
output_use_model: False
output_use_index: True
save_results: False
skip: True
suffix: None
search_output_file: True
input_dir: ''
mask_science_regions: True
n_sigma: 2.0
save_mask: False
save_correction: False
clean_flicker_noise:
pre_hooks: []
post_hooks: []
output_file: None
output_dir: None
output_ext: .fits
output_use_model: False
output_use_index: True
save_results: False
skip: True
suffix: None
search_output_file: True
input_dir: ''
autoparam: False
fit_method: median
fit_by_channel: False
background_method: median
background_box_size: None
mask_science_regions: False
apply_flat_field: False
n_sigma: 2.0
fit_histogram: False
single_mask: True
user_mask: None
save_mask: False
save_background: False
save_noise: False
ramp_fit:
pre_hooks: []
post_hooks: []
output_file: None
output_dir: None
output_ext: .fits
output_use_model: False
output_use_index: True
save_results: False
skip: False
suffix: None
search_output_file: True
input_dir: ''
algorithm: OLS_C
int_name: ''
save_opt: False
opt_name: ''
suppress_one_group: True
firstgroup: None
lastgroup: None
maximum_cores: '1'
gain_scale:
pre_hooks: []
post_hooks: []
output_file: None
output_dir: None
output_ext: .fits
output_use_model: False
output_use_index: True
save_results: False
skip: False
suffix: None
search_output_file: True
input_dir: ''
2026-04-15 20:14:28,113 - stpipe.pipeline - INFO - Prefetching reference files for dataset: 'jw01093012001_03102_00001_nis_uncal.fits' reftypes = ['gain', 'linearity', 'mask', 'readnoise', 'refpix', 'reset', 'rscd', 'saturation', 'sirskernel', 'superbias']
2026-04-15 20:14:28,115 - CRDS - INFO - Fetching /home/runner/crds/references/jwst/niriss/jwst_niriss_gain_0006.fits 16.8 M bytes (1 / 7 files) (0 / 289.7 M bytes)
2026-04-15 20:14:28,536 - CRDS - INFO - Fetching /home/runner/crds/references/jwst/niriss/jwst_niriss_linearity_0017.fits 205.5 M bytes (2 / 7 files) (16.8 M / 289.7 M bytes)
2026-04-15 20:14:30,495 - CRDS - INFO - Fetching /home/runner/crds/references/jwst/niriss/jwst_niriss_mask_0016.fits 16.8 M bytes (3 / 7 files) (222.3 M / 289.7 M bytes)
2026-04-15 20:14:31,189 - CRDS - INFO - Fetching /home/runner/crds/references/jwst/niriss/jwst_niriss_readnoise_0005.fits 16.8 M bytes (4 / 7 files) (239.1 M / 289.7 M bytes)
2026-04-15 20:14:31,814 - CRDS - INFO - Fetching /home/runner/crds/references/jwst/niriss/jwst_niriss_saturation_0015.fits 33.6 M bytes (5 / 7 files) (255.9 M / 289.7 M bytes)
2026-04-15 20:14:32,683 - CRDS - INFO - Fetching /home/runner/crds/references/jwst/niriss/jwst_niriss_sirskernel_0001.asdf 67.4 K bytes (6 / 7 files) (289.5 M / 289.7 M bytes)
2026-04-15 20:14:32,840 - CRDS - INFO - Fetching /home/runner/crds/references/jwst/niriss/jwst_niriss_superbias_0182.fits 97.9 K bytes (7 / 7 files) (289.6 M / 289.7 M bytes)
2026-04-15 20:14:32,987 - stpipe.pipeline - INFO - Prefetch for GAIN reference file is '/home/runner/crds/references/jwst/niriss/jwst_niriss_gain_0006.fits'.
2026-04-15 20:14:32,987 - stpipe.pipeline - INFO - Prefetch for LINEARITY reference file is '/home/runner/crds/references/jwst/niriss/jwst_niriss_linearity_0017.fits'.
2026-04-15 20:14:32,988 - stpipe.pipeline - INFO - Prefetch for MASK reference file is '/home/runner/crds/references/jwst/niriss/jwst_niriss_mask_0016.fits'.
2026-04-15 20:14:32,988 - stpipe.pipeline - INFO - Prefetch for READNOISE reference file is '/home/runner/crds/references/jwst/niriss/jwst_niriss_readnoise_0005.fits'.
2026-04-15 20:14:32,989 - stpipe.pipeline - INFO - Prefetch for REFPIX reference file is 'N/A'.
2026-04-15 20:14:32,989 - stpipe.pipeline - INFO - Prefetch for RESET reference file is 'N/A'.
2026-04-15 20:14:32,990 - stpipe.pipeline - INFO - Prefetch for RSCD reference file is 'N/A'.
2026-04-15 20:14:32,990 - stpipe.pipeline - INFO - Prefetch for SATURATION reference file is '/home/runner/crds/references/jwst/niriss/jwst_niriss_saturation_0015.fits'.
2026-04-15 20:14:32,991 - stpipe.pipeline - INFO - Prefetch for SIRSKERNEL reference file is '/home/runner/crds/references/jwst/niriss/jwst_niriss_sirskernel_0001.asdf'.
2026-04-15 20:14:32,991 - stpipe.pipeline - INFO - Prefetch for SUPERBIAS reference file is '/home/runner/crds/references/jwst/niriss/jwst_niriss_superbias_0182.fits'.
2026-04-15 20:14:32,992 - jwst.pipeline.calwebb_detector1 - INFO - Starting calwebb_detector1 ...
2026-04-15 20:14:33,247 - stpipe.step - INFO - Step group_scale running with args (<RampModel(69, 5, 80, 80) from jw01093012001_03102_00001_nis_uncal.fits>,).
2026-04-15 20:14:33,248 - jwst.group_scale.group_scale_step - INFO - NFRAMES and FRMDIVSR are equal; correction not needed
2026-04-15 20:14:33,249 - jwst.group_scale.group_scale_step - INFO - Step will be skipped
2026-04-15 20:14:33,250 - stpipe.step - INFO - Step group_scale done
2026-04-15 20:14:33,424 - stpipe.step - INFO - Step dq_init running with args (<RampModel(69, 5, 80, 80) from jw01093012001_03102_00001_nis_uncal.fits>,).
2026-04-15 20:14:33,432 - jwst.dq_init.dq_init_step - INFO - Using MASK reference file /home/runner/crds/references/jwst/niriss/jwst_niriss_mask_0016.fits
2026-04-15 20:14:33,484 - stdatamodels.dynamicdq - WARNING - Keyword NON_LINEAR does not correspond to an existing DQ mnemonic, so will be ignored
2026-04-15 20:14:33,514 - jwst.dq_init.dq_initialization - INFO - Extracting mask subarray to match science data
2026-04-15 20:14:33,535 - CRDS - INFO - Calibration SW Found: jwst 2.0.0 (/home/runner/micromamba/envs/ci-env/lib/python3.13/site-packages/jwst-2.0.0.dist-info)
2026-04-15 20:14:33,630 - stpipe.step - INFO - Step dq_init done
2026-04-15 20:14:33,801 - stpipe.step - INFO - Step saturation running with args (<RampModel(69, 5, 80, 80) from jw01093012001_03102_00001_nis_uncal.fits>,).
2026-04-15 20:14:33,806 - jwst.saturation.saturation_step - INFO - Using SATURATION reference file /home/runner/crds/references/jwst/niriss/jwst_niriss_saturation_0015.fits
2026-04-15 20:14:33,807 - jwst.saturation.saturation_step - INFO - Using SUPERBIAS reference file /home/runner/crds/references/jwst/niriss/jwst_niriss_superbias_0182.fits
2026-04-15 20:14:33,839 - stdatamodels.dynamicdq - WARNING - Keyword LOWILLUM does not correspond to an existing DQ mnemonic, so will be ignored
2026-04-15 20:14:33,840 - stdatamodels.dynamicdq - WARNING - Keyword LOWRESP does not correspond to an existing DQ mnemonic, so will be ignored
2026-04-15 20:14:33,844 - stdatamodels.dynamicdq - WARNING - Keyword UNCERTAIN does not correspond to an existing DQ mnemonic, so will be ignored
2026-04-15 20:14:33,880 - jwst.saturation.saturation - INFO - Extracting reference file subarray to match science data
2026-04-15 20:14:33,895 - jwst.saturation.saturation - INFO - Using read_pattern with nframes 1
2026-04-15 20:14:33,939 - stcal.saturation.saturation - INFO - Detected 0 saturated pixels
2026-04-15 20:14:33,940 - stcal.saturation.saturation - INFO - Detected 0 A/D floor pixels
2026-04-15 20:14:33,950 - stpipe.step - INFO - Step saturation done
2026-04-15 20:14:34,132 - stpipe.step - INFO - Step ipc running with args (<RampModel(69, 5, 80, 80) from jw01093012001_03102_00001_nis_uncal.fits>,).
2026-04-15 20:14:34,133 - stpipe.step - INFO - Step skipped.
2026-04-15 20:14:34,318 - stpipe.step - INFO - Step superbias running with args (<RampModel(69, 5, 80, 80) from jw01093012001_03102_00001_nis_uncal.fits>,).
2026-04-15 20:14:34,326 - jwst.superbias.superbias_step - INFO - Using SUPERBIAS reference file /home/runner/crds/references/jwst/niriss/jwst_niriss_superbias_0182.fits
2026-04-15 20:14:34,366 - stpipe.step - INFO - Step superbias done
2026-04-15 20:14:34,546 - stpipe.step - INFO - Step refpix running with args (<RampModel(69, 5, 80, 80) from jw01093012001_03102_00001_nis_uncal.fits>,).
2026-04-15 20:14:34,549 - jwst.refpix.reference_pixels - INFO - NIR subarray data
2026-04-15 20:14:34,551 - jwst.refpix.reference_pixels - INFO - Single readout amplifier used
2026-04-15 20:14:34,551 - jwst.refpix.reference_pixels - INFO - No valid reference pixels. This step will have no effect.
2026-04-15 20:14:35,052 - stpipe.step - INFO - Step refpix done
2026-04-15 20:14:35,234 - stpipe.step - INFO - Step linearity running with args (<RampModel(69, 5, 80, 80) from jw01093012001_03102_00001_nis_uncal.fits>,).
2026-04-15 20:14:35,239 - jwst.linearity.linearity_step - INFO - Using Linearity reference file /home/runner/crds/references/jwst/niriss/jwst_niriss_linearity_0017.fits
2026-04-15 20:14:35,282 - stdatamodels.dynamicdq - WARNING - Keyword LOWILLUM does not correspond to an existing DQ mnemonic, so will be ignored
2026-04-15 20:14:35,283 - stdatamodels.dynamicdq - WARNING - Keyword LOWRESP does not correspond to an existing DQ mnemonic, so will be ignored
2026-04-15 20:14:35,288 - stdatamodels.dynamicdq - WARNING - Keyword UNCERTAIN does not correspond to an existing DQ mnemonic, so will be ignored
2026-04-15 20:14:35,327 - stpipe.step - INFO - Step linearity done
2026-04-15 20:14:35,507 - stpipe.step - INFO - Step persistence running with args (<RampModel(69, 5, 80, 80) from jw01093012001_03102_00001_nis_uncal.fits>,).
2026-04-15 20:14:35,507 - stpipe.step - INFO - Step skipped.
2026-04-15 20:14:35,688 - stpipe.step - INFO - Step dark_current running with args (<RampModel(69, 5, 80, 80) from jw01093012001_03102_00001_nis_uncal.fits>,).
2026-04-15 20:14:35,689 - stpipe.step - INFO - Step skipped.
2026-04-15 20:14:35,870 - stpipe.step - INFO - Step charge_migration running with args (<RampModel(69, 5, 80, 80) from jw01093012001_03102_00001_nis_uncal.fits>,).
2026-04-15 20:14:35,871 - jwst.charge_migration.charge_migration - INFO - Using signal_threshold: 14465.00
2026-04-15 20:14:35,878 - stpipe.step - INFO - Step charge_migration done
2026-04-15 20:14:36,057 - stpipe.step - INFO - Step jump running with args (<RampModel(69, 5, 80, 80) from jw01093012001_03102_00001_nis_uncal.fits>,).
2026-04-15 20:14:36,058 - jwst.jump.jump_step - INFO - CR rejection threshold = 4 sigma
2026-04-15 20:14:36,059 - jwst.jump.jump_step - INFO - Maximum cores to use = half
2026-04-15 20:14:36,065 - jwst.jump.jump_step - INFO - Using GAIN reference file: /home/runner/crds/references/jwst/niriss/jwst_niriss_gain_0006.fits
2026-04-15 20:14:36,067 - jwst.jump.jump_step - INFO - Using READNOISE reference file: /home/runner/crds/references/jwst/niriss/jwst_niriss_readnoise_0005.fits
2026-04-15 20:14:36,095 - jwst.jump.jump_step - INFO - Extracting gain subarray to match science data
2026-04-15 20:14:36,106 - jwst.jump.jump_step - INFO - Extracting readnoise subarray to match science data
2026-04-15 20:14:36,118 - stcal.jump.jump - INFO - Executing two-point difference method
2026-04-15 20:14:36,119 - stcal.jump.jump - INFO - Creating 2 processes for jump detection
2026-04-15 20:14:37,050 - stcal.jump.jump - INFO - Flagging Snowballs
2026-04-15 20:14:37,103 - stcal.jump.jump - INFO - Total snowballs = 0
2026-04-15 20:14:37,104 - stcal.jump.jump - INFO - Total elapsed time = 0.985013 sec
2026-04-15 20:14:37,114 - jwst.jump.jump_step - INFO - The execution time in seconds: 1.056278
2026-04-15 20:14:37,117 - stpipe.step - INFO - Step jump done
2026-04-15 20:14:37,297 - stpipe.step - INFO - Step picture_frame running with args (<RampModel(69, 5, 80, 80) from jw01093012001_03102_00001_nis_uncal.fits>,).
2026-04-15 20:14:37,297 - stpipe.step - INFO - Step skipped.
2026-04-15 20:14:37,481 - stpipe.step - INFO - Step clean_flicker_noise running with args (<RampModel(69, 5, 80, 80) from jw01093012001_03102_00001_nis_uncal.fits>,).
2026-04-15 20:14:37,482 - stpipe.step - INFO - Step skipped.
2026-04-15 20:14:37,528 - stpipe.step - INFO - Saved model in ./nis_ami_demo_data/PID_1093/stage1/jw01093012001_03102_00001_nis_ramp.fits
2026-04-15 20:14:37,710 - stpipe.step - INFO - Step ramp_fit running with args (<RampModel(69, 5, 80, 80) from jw01093012001_03102_00001_nis_ramp.fits>,).
2026-04-15 20:14:37,719 - jwst.ramp_fitting.ramp_fit_step - INFO - Using READNOISE reference file: /home/runner/crds/references/jwst/niriss/jwst_niriss_readnoise_0005.fits
2026-04-15 20:14:37,720 - jwst.ramp_fitting.ramp_fit_step - INFO - Using GAIN reference file: /home/runner/crds/references/jwst/niriss/jwst_niriss_gain_0006.fits
2026-04-15 20:14:37,746 - jwst.ramp_fitting.ramp_fit_step - INFO - Extracting gain subarray to match science data
2026-04-15 20:14:37,757 - jwst.ramp_fitting.ramp_fit_step - INFO - Extracting readnoise subarray to match science data
2026-04-15 20:14:37,768 - jwst.ramp_fitting.ramp_fit_step - INFO - Using algorithm = OLS_C
2026-04-15 20:14:37,768 - jwst.ramp_fitting.ramp_fit_step - INFO - Using weighting = optimal
2026-04-15 20:14:37,773 - stcal.ramp_fitting.ols_fit - INFO - Number of multiprocessing slices: 1
2026-04-15 20:14:37,870 - stcal.ramp_fitting.ols_fit - INFO - Ramp Fitting C Time: 0.0966644287109375
2026-04-15 20:14:37,969 - stpipe.step - INFO - Step ramp_fit done
2026-04-15 20:14:38,156 - stpipe.step - INFO - Step gain_scale running with args (<ImageModel(80, 80) from jw01093012001_03102_00001_nis_ramp.fits>,).
2026-04-15 20:14:38,163 - jwst.gain_scale.gain_scale_step - INFO - Using GAIN reference file: /home/runner/crds/references/jwst/niriss/jwst_niriss_gain_0006.fits
2026-04-15 20:14:38,175 - jwst.gain_scale.gain_scale_step - INFO - GAINFACT not found in gain reference file
2026-04-15 20:14:38,176 - jwst.gain_scale.gain_scale_step - INFO - Step will be skipped
2026-04-15 20:14:38,178 - stpipe.step - INFO - Step gain_scale done
2026-04-15 20:14:38,363 - stpipe.step - INFO - Step gain_scale running with args (<CubeModel(69, 80, 80) from jw01093012001_03102_00001_nis_ramp.fits>,).
2026-04-15 20:14:38,365 - jwst.gain_scale.gain_scale_step - INFO - Using GAIN reference file: /home/runner/crds/references/jwst/niriss/jwst_niriss_gain_0006.fits
2026-04-15 20:14:38,378 - jwst.gain_scale.gain_scale_step - INFO - GAINFACT not found in gain reference file
2026-04-15 20:14:38,379 - jwst.gain_scale.gain_scale_step - INFO - Step will be skipped
2026-04-15 20:14:38,381 - stpipe.step - INFO - Step gain_scale done
2026-04-15 20:14:38,419 - stpipe.step - INFO - Saved model in ./nis_ami_demo_data/PID_1093/stage1/jw01093012001_03102_00001_nis_rateints.fits
2026-04-15 20:14:38,420 - jwst.pipeline.calwebb_detector1 - INFO - ... ending calwebb_detector1
2026-04-15 20:14:38,422 - jwst.stpipe.core - INFO - Results used CRDS context: jwst_1535.pmap
2026-04-15 20:14:38,455 - stpipe.step - INFO - Saved model in ./nis_ami_demo_data/PID_1093/stage1/jw01093012001_03102_00001_nis_rate.fits
2026-04-15 20:14:38,455 - stpipe.step - INFO - Step Detector1Pipeline done
2026-04-15 20:14:38,456 - jwst.stpipe.core - INFO - Results used jwst version: 2.0.0
2026-04-15 20:14:38,478 - CRDS - ERROR - Error determining best reference for 'pars-darkcurrentstep' = No match found.
2026-04-15 20:14:38,481 - stpipe.step - INFO - PARS-CHARGEMIGRATIONSTEP parameters found: /home/runner/crds/references/jwst/niriss/jwst_niriss_pars-chargemigrationstep_0038.asdf
2026-04-15 20:14:38,489 - stpipe.step - INFO - PARS-JUMPSTEP parameters found: /home/runner/crds/references/jwst/niriss/jwst_niriss_pars-jumpstep_0072.asdf
2026-04-15 20:14:38,500 - stpipe.pipeline - INFO - PARS-DETECTOR1PIPELINE parameters found: /home/runner/crds/references/jwst/niriss/jwst_niriss_pars-detector1pipeline_0004.asdf
2026-04-15 20:14:38,512 - stpipe.step - INFO - Detector1Pipeline instance created.
2026-04-15 20:14:38,513 - stpipe.step - INFO - GroupScaleStep instance created.
2026-04-15 20:14:38,513 - stpipe.step - INFO - DQInitStep instance created.
2026-04-15 20:14:38,514 - stpipe.step - INFO - EmiCorrStep instance created.
2026-04-15 20:14:38,515 - stpipe.step - INFO - SaturationStep instance created.
2026-04-15 20:14:38,515 - stpipe.step - INFO - IPCStep instance created.
2026-04-15 20:14:38,516 - stpipe.step - INFO - SuperBiasStep instance created.
2026-04-15 20:14:38,517 - stpipe.step - INFO - RefPixStep instance created.
2026-04-15 20:14:38,517 - stpipe.step - INFO - RscdStep instance created.
2026-04-15 20:14:38,518 - stpipe.step - INFO - FirstFrameStep instance created.
2026-04-15 20:14:38,518 - stpipe.step - INFO - LastFrameStep instance created.
2026-04-15 20:14:38,519 - stpipe.step - INFO - LinearityStep instance created.
2026-04-15 20:14:38,519 - stpipe.step - INFO - DarkCurrentStep instance created.
2026-04-15 20:14:38,520 - stpipe.step - INFO - ResetStep instance created.
2026-04-15 20:14:38,521 - stpipe.step - INFO - PersistenceStep instance created.
2026-04-15 20:14:38,521 - stpipe.step - INFO - ChargeMigrationStep instance created.
2026-04-15 20:14:38,523 - stpipe.step - INFO - JumpStep instance created.
2026-04-15 20:14:38,524 - stpipe.step - INFO - PictureFrameStep instance created.
2026-04-15 20:14:38,525 - stpipe.step - INFO - CleanFlickerNoiseStep instance created.
2026-04-15 20:14:38,525 - stpipe.step - INFO - RampFitStep instance created.
2026-04-15 20:14:38,526 - stpipe.step - INFO - GainScaleStep instance created.
2026-04-15 20:14:38,717 - stpipe.step - INFO - Step Detector1Pipeline running with args ('./nis_ami_demo_data/PID_1093/uncal/jw01093015001_03102_00001_nis_uncal.fits',).
2026-04-15 20:14:38,731 - stpipe.step - INFO - Step Detector1Pipeline parameters are:
pre_hooks: []
post_hooks: []
output_file: None
output_dir: ./nis_ami_demo_data/PID_1093/stage1
output_ext: .fits
output_use_model: False
output_use_index: True
save_results: True
skip: False
suffix: None
search_output_file: True
input_dir: ''
save_calibrated_ramp: True
steps:
group_scale:
pre_hooks: []
post_hooks: []
output_file: None
output_dir: None
output_ext: .fits
output_use_model: False
output_use_index: True
save_results: False
skip: False
suffix: None
search_output_file: True
input_dir: ''
dq_init:
pre_hooks: []
post_hooks: []
output_file: None
output_dir: None
output_ext: .fits
output_use_model: False
output_use_index: True
save_results: False
skip: False
suffix: None
search_output_file: True
input_dir: ''
user_supplied_dq: None
emicorr:
pre_hooks: []
post_hooks: []
output_file: None
output_dir: None
output_ext: .fits
output_use_model: False
output_use_index: True
save_results: False
skip: True
suffix: None
search_output_file: True
input_dir: ''
algorithm: joint
nints_to_phase: None
nbins: None
scale_reference: True
onthefly_corr_freq: None
use_n_cycles: 3
fit_ints_separately: False
user_supplied_reffile: None
save_intermediate_results: False
saturation:
pre_hooks: []
post_hooks: []
output_file: None
output_dir: None
output_ext: .fits
output_use_model: False
output_use_index: True
save_results: False
skip: False
suffix: None
search_output_file: True
input_dir: ''
n_pix_grow_sat: 1
use_readpatt: True
ipc:
pre_hooks: []
post_hooks: []
output_file: None
output_dir: None
output_ext: .fits
output_use_model: False
output_use_index: True
save_results: False
skip: True
suffix: None
search_output_file: True
input_dir: ''
superbias:
pre_hooks: []
post_hooks: []
output_file: None
output_dir: None
output_ext: .fits
output_use_model: False
output_use_index: True
save_results: False
skip: False
suffix: None
search_output_file: True
input_dir: ''
refpix:
pre_hooks: []
post_hooks: []
output_file: None
output_dir: None
output_ext: .fits
output_use_model: False
output_use_index: True
save_results: False
skip: False
suffix: None
search_output_file: True
input_dir: ''
odd_even_columns: True
use_side_ref_pixels: True
side_smoothing_length: 11
side_gain: 1.0
odd_even_rows: True
ovr_corr_mitigation_ftr: 3.0
preserve_irs2_refpix: False
irs2_mean_subtraction: False
refpix_algorithm: median
sigreject: 4.0
gaussmooth: 1.0
halfwidth: 30
rscd:
pre_hooks: []
post_hooks: []
output_file: None
output_dir: None
output_ext: .fits
output_use_model: False
output_use_index: True
save_results: False
skip: False
suffix: None
search_output_file: True
input_dir: ''
firstframe:
pre_hooks: []
post_hooks: []
output_file: None
output_dir: None
output_ext: .fits
output_use_model: False
output_use_index: True
save_results: False
skip: True
suffix: None
search_output_file: True
input_dir: ''
bright_use_group1: True
lastframe:
pre_hooks: []
post_hooks: []
output_file: None
output_dir: None
output_ext: .fits
output_use_model: False
output_use_index: True
save_results: False
skip: False
suffix: None
search_output_file: True
input_dir: ''
linearity:
pre_hooks: []
post_hooks: []
output_file: None
output_dir: None
output_ext: .fits
output_use_model: False
output_use_index: True
save_results: False
skip: False
suffix: None
search_output_file: True
input_dir: ''
dark_current:
pre_hooks: []
post_hooks: []
output_file: None
output_dir: None
output_ext: .fits
output_use_model: False
output_use_index: True
save_results: False
skip: True
suffix: None
search_output_file: True
input_dir: ''
dark_output: None
average_dark_current: None
reset:
pre_hooks: []
post_hooks: []
output_file: None
output_dir: None
output_ext: .fits
output_use_model: False
output_use_index: True
save_results: False
skip: False
suffix: None
search_output_file: True
input_dir: ''
persistence:
pre_hooks: []
post_hooks: []
output_file: None
output_dir: None
output_ext: .fits
output_use_model: False
output_use_index: True
save_results: False
skip: True
suffix: None
search_output_file: True
input_dir: ''
input_trapsfilled: ''
flag_pers_cutoff: 40.0
save_persistence: False
save_trapsfilled: True
modify_input: False
charge_migration:
pre_hooks: []
post_hooks: []
output_file: None
output_dir: None
output_ext: .fits
output_use_model: False
output_use_index: True
save_results: False
skip: False
suffix: None
search_output_file: True
input_dir: ''
signal_threshold: 14465.0
jump:
pre_hooks: []
post_hooks: []
output_file: None
output_dir: None
output_ext: .fits
output_use_model: False
output_use_index: True
save_results: False
skip: False
suffix: None
search_output_file: True
input_dir: ''
rejection_threshold: 4.0
three_group_rejection_threshold: 6.0
four_group_rejection_threshold: 5.0
maximum_cores: half
flag_4_neighbors: False
max_jump_to_flag_neighbors: 200.0
min_jump_to_flag_neighbors: 10.0
after_jump_flag_dn1: 1000
after_jump_flag_time1: 90
after_jump_flag_dn2: 0
after_jump_flag_time2: 0
expand_large_events: True
min_sat_area: 5
min_jump_area: 15.0
expand_factor: 1.75
use_ellipses: False
sat_required_snowball: True
min_sat_radius_extend: 5.0
sat_expand: 0
edge_size: 20
mask_snowball_core_next_int: True
snowball_time_masked_next_int: 4000
find_showers: False
max_shower_amplitude: 4.0
extend_snr_threshold: 1.2
extend_min_area: 90
extend_inner_radius: 1.0
extend_outer_radius: 2.6
extend_ellipse_expand_ratio: 1.1
time_masked_after_shower: 15.0
min_diffs_single_pass: 10
max_extended_radius: 100
minimum_groups: 3
minimum_sigclip_groups: 100
only_use_ints: True
picture_frame:
pre_hooks: []
post_hooks: []
output_file: None
output_dir: None
output_ext: .fits
output_use_model: False
output_use_index: True
save_results: False
skip: True
suffix: None
search_output_file: True
input_dir: ''
mask_science_regions: True
n_sigma: 2.0
save_mask: False
save_correction: False
clean_flicker_noise:
pre_hooks: []
post_hooks: []
output_file: None
output_dir: None
output_ext: .fits
output_use_model: False
output_use_index: True
save_results: False
skip: True
suffix: None
search_output_file: True
input_dir: ''
autoparam: False
fit_method: median
fit_by_channel: False
background_method: median
background_box_size: None
mask_science_regions: False
apply_flat_field: False
n_sigma: 2.0
fit_histogram: False
single_mask: True
user_mask: None
save_mask: False
save_background: False
save_noise: False
ramp_fit:
pre_hooks: []
post_hooks: []
output_file: None
output_dir: None
output_ext: .fits
output_use_model: False
output_use_index: True
save_results: False
skip: False
suffix: None
search_output_file: True
input_dir: ''
algorithm: OLS_C
int_name: ''
save_opt: False
opt_name: ''
suppress_one_group: True
firstgroup: None
lastgroup: None
maximum_cores: '1'
gain_scale:
pre_hooks: []
post_hooks: []
output_file: None
output_dir: None
output_ext: .fits
output_use_model: False
output_use_index: True
save_results: False
skip: False
suffix: None
search_output_file: True
input_dir: ''
2026-04-15 20:14:38,751 - stpipe.pipeline - INFO - Prefetching reference files for dataset: 'jw01093015001_03102_00001_nis_uncal.fits' reftypes = ['gain', 'linearity', 'mask', 'readnoise', 'refpix', 'reset', 'rscd', 'saturation', 'sirskernel', 'superbias']
2026-04-15 20:14:38,753 - stpipe.pipeline - INFO - Prefetch for GAIN reference file is '/home/runner/crds/references/jwst/niriss/jwst_niriss_gain_0006.fits'.
2026-04-15 20:14:38,754 - stpipe.pipeline - INFO - Prefetch for LINEARITY reference file is '/home/runner/crds/references/jwst/niriss/jwst_niriss_linearity_0017.fits'.
2026-04-15 20:14:38,754 - stpipe.pipeline - INFO - Prefetch for MASK reference file is '/home/runner/crds/references/jwst/niriss/jwst_niriss_mask_0016.fits'.
2026-04-15 20:14:38,755 - stpipe.pipeline - INFO - Prefetch for READNOISE reference file is '/home/runner/crds/references/jwst/niriss/jwst_niriss_readnoise_0005.fits'.
2026-04-15 20:14:38,755 - stpipe.pipeline - INFO - Prefetch for REFPIX reference file is 'N/A'.
2026-04-15 20:14:38,755 - stpipe.pipeline - INFO - Prefetch for RESET reference file is 'N/A'.
2026-04-15 20:14:38,756 - stpipe.pipeline - INFO - Prefetch for RSCD reference file is 'N/A'.
2026-04-15 20:14:38,756 - stpipe.pipeline - INFO - Prefetch for SATURATION reference file is '/home/runner/crds/references/jwst/niriss/jwst_niriss_saturation_0015.fits'.
2026-04-15 20:14:38,757 - stpipe.pipeline - INFO - Prefetch for SIRSKERNEL reference file is '/home/runner/crds/references/jwst/niriss/jwst_niriss_sirskernel_0001.asdf'.
2026-04-15 20:14:38,757 - stpipe.pipeline - INFO - Prefetch for SUPERBIAS reference file is '/home/runner/crds/references/jwst/niriss/jwst_niriss_superbias_0182.fits'.
2026-04-15 20:14:38,758 - jwst.pipeline.calwebb_detector1 - INFO - Starting calwebb_detector1 ...
2026-04-15 20:14:39,036 - stpipe.step - INFO - Step group_scale running with args (<RampModel(61, 12, 80, 80) from jw01093015001_03102_00001_nis_uncal.fits>,).
2026-04-15 20:14:39,037 - jwst.group_scale.group_scale_step - INFO - NFRAMES and FRMDIVSR are equal; correction not needed
2026-04-15 20:14:39,037 - jwst.group_scale.group_scale_step - INFO - Step will be skipped
2026-04-15 20:14:39,039 - stpipe.step - INFO - Step group_scale done
2026-04-15 20:14:39,224 - stpipe.step - INFO - Step dq_init running with args (<RampModel(61, 12, 80, 80) from jw01093015001_03102_00001_nis_uncal.fits>,).
2026-04-15 20:14:39,227 - jwst.dq_init.dq_init_step - INFO - Using MASK reference file /home/runner/crds/references/jwst/niriss/jwst_niriss_mask_0016.fits
2026-04-15 20:14:39,275 - stdatamodels.dynamicdq - WARNING - Keyword NON_LINEAR does not correspond to an existing DQ mnemonic, so will be ignored
2026-04-15 20:14:39,307 - jwst.dq_init.dq_initialization - INFO - Extracting mask subarray to match science data
2026-04-15 20:14:39,328 - stpipe.step - INFO - Step dq_init done
2026-04-15 20:14:39,515 - stpipe.step - INFO - Step saturation running with args (<RampModel(61, 12, 80, 80) from jw01093015001_03102_00001_nis_uncal.fits>,).
2026-04-15 20:14:39,519 - jwst.saturation.saturation_step - INFO - Using SATURATION reference file /home/runner/crds/references/jwst/niriss/jwst_niriss_saturation_0015.fits
2026-04-15 20:14:39,519 - jwst.saturation.saturation_step - INFO - Using SUPERBIAS reference file /home/runner/crds/references/jwst/niriss/jwst_niriss_superbias_0182.fits
2026-04-15 20:14:39,551 - stdatamodels.dynamicdq - WARNING - Keyword LOWILLUM does not correspond to an existing DQ mnemonic, so will be ignored
2026-04-15 20:14:39,552 - stdatamodels.dynamicdq - WARNING - Keyword LOWRESP does not correspond to an existing DQ mnemonic, so will be ignored
2026-04-15 20:14:39,557 - stdatamodels.dynamicdq - WARNING - Keyword UNCERTAIN does not correspond to an existing DQ mnemonic, so will be ignored
2026-04-15 20:14:39,592 - jwst.saturation.saturation - INFO - Extracting reference file subarray to match science data
2026-04-15 20:14:39,607 - jwst.saturation.saturation - INFO - Using read_pattern with nframes 1
2026-04-15 20:14:39,694 - stcal.saturation.saturation - INFO - Detected 0 saturated pixels
2026-04-15 20:14:39,695 - stcal.saturation.saturation - INFO - Detected 0 A/D floor pixels
2026-04-15 20:14:39,706 - stpipe.step - INFO - Step saturation done
2026-04-15 20:14:39,894 - stpipe.step - INFO - Step ipc running with args (<RampModel(61, 12, 80, 80) from jw01093015001_03102_00001_nis_uncal.fits>,).
2026-04-15 20:14:39,895 - stpipe.step - INFO - Step skipped.
2026-04-15 20:14:40,083 - stpipe.step - INFO - Step superbias running with args (<RampModel(61, 12, 80, 80) from jw01093015001_03102_00001_nis_uncal.fits>,).
2026-04-15 20:14:40,086 - jwst.superbias.superbias_step - INFO - Using SUPERBIAS reference file /home/runner/crds/references/jwst/niriss/jwst_niriss_superbias_0182.fits
2026-04-15 20:14:40,126 - stpipe.step - INFO - Step superbias done
2026-04-15 20:14:40,313 - stpipe.step - INFO - Step refpix running with args (<RampModel(61, 12, 80, 80) from jw01093015001_03102_00001_nis_uncal.fits>,).
2026-04-15 20:14:40,315 - jwst.refpix.reference_pixels - INFO - NIR subarray data
2026-04-15 20:14:40,317 - jwst.refpix.reference_pixels - INFO - Single readout amplifier used
2026-04-15 20:14:40,318 - jwst.refpix.reference_pixels - INFO - No valid reference pixels. This step will have no effect.
2026-04-15 20:14:41,285 - stpipe.step - INFO - Step refpix done
2026-04-15 20:14:41,480 - stpipe.step - INFO - Step linearity running with args (<RampModel(61, 12, 80, 80) from jw01093015001_03102_00001_nis_uncal.fits>,).
2026-04-15 20:14:41,483 - jwst.linearity.linearity_step - INFO - Using Linearity reference file /home/runner/crds/references/jwst/niriss/jwst_niriss_linearity_0017.fits
2026-04-15 20:14:41,525 - stdatamodels.dynamicdq - WARNING - Keyword LOWILLUM does not correspond to an existing DQ mnemonic, so will be ignored
2026-04-15 20:14:41,526 - stdatamodels.dynamicdq - WARNING - Keyword LOWRESP does not correspond to an existing DQ mnemonic, so will be ignored
2026-04-15 20:14:41,531 - stdatamodels.dynamicdq - WARNING - Keyword UNCERTAIN does not correspond to an existing DQ mnemonic, so will be ignored
2026-04-15 20:14:41,579 - stpipe.step - INFO - Step linearity done
2026-04-15 20:14:41,764 - stpipe.step - INFO - Step persistence running with args (<RampModel(61, 12, 80, 80) from jw01093015001_03102_00001_nis_uncal.fits>,).
2026-04-15 20:14:41,764 - stpipe.step - INFO - Step skipped.
2026-04-15 20:14:41,952 - stpipe.step - INFO - Step dark_current running with args (<RampModel(61, 12, 80, 80) from jw01093015001_03102_00001_nis_uncal.fits>,).
2026-04-15 20:14:41,953 - stpipe.step - INFO - Step skipped.
2026-04-15 20:14:42,139 - stpipe.step - INFO - Step charge_migration running with args (<RampModel(61, 12, 80, 80) from jw01093015001_03102_00001_nis_uncal.fits>,).
2026-04-15 20:14:42,140 - jwst.charge_migration.charge_migration - INFO - Using signal_threshold: 14465.00
2026-04-15 20:14:42,153 - stpipe.step - INFO - Step charge_migration done
2026-04-15 20:14:42,339 - stpipe.step - INFO - Step jump running with args (<RampModel(61, 12, 80, 80) from jw01093015001_03102_00001_nis_uncal.fits>,).
2026-04-15 20:14:42,340 - jwst.jump.jump_step - INFO - CR rejection threshold = 4 sigma
2026-04-15 20:14:42,340 - jwst.jump.jump_step - INFO - Maximum cores to use = half
2026-04-15 20:14:42,342 - jwst.jump.jump_step - INFO - Using GAIN reference file: /home/runner/crds/references/jwst/niriss/jwst_niriss_gain_0006.fits
2026-04-15 20:14:42,344 - jwst.jump.jump_step - INFO - Using READNOISE reference file: /home/runner/crds/references/jwst/niriss/jwst_niriss_readnoise_0005.fits
2026-04-15 20:14:42,371 - jwst.jump.jump_step - INFO - Extracting gain subarray to match science data
2026-04-15 20:14:42,382 - jwst.jump.jump_step - INFO - Extracting readnoise subarray to match science data
2026-04-15 20:14:42,396 - stcal.jump.jump - INFO - Executing two-point difference method
2026-04-15 20:14:42,397 - stcal.jump.jump - INFO - Creating 2 processes for jump detection
2026-04-15 20:14:42,824 - stcal.jump.jump - INFO - Flagging Snowballs
2026-04-15 20:14:42,963 - stcal.jump.jump - INFO - Total snowballs = 0
2026-04-15 20:14:42,964 - stcal.jump.jump - INFO - Total elapsed time = 0.566495 sec
2026-04-15 20:14:42,976 - jwst.jump.jump_step - INFO - The execution time in seconds: 0.636318
2026-04-15 20:14:42,979 - stpipe.step - INFO - Step jump done
2026-04-15 20:14:43,166 - stpipe.step - INFO - Step picture_frame running with args (<RampModel(61, 12, 80, 80) from jw01093015001_03102_00001_nis_uncal.fits>,).
2026-04-15 20:14:43,167 - stpipe.step - INFO - Step skipped.
2026-04-15 20:14:43,361 - stpipe.step - INFO - Step clean_flicker_noise running with args (<RampModel(61, 12, 80, 80) from jw01093015001_03102_00001_nis_uncal.fits>,).
2026-04-15 20:14:43,361 - stpipe.step - INFO - Step skipped.
2026-04-15 20:14:43,409 - stpipe.step - INFO - Saved model in ./nis_ami_demo_data/PID_1093/stage1/jw01093015001_03102_00001_nis_ramp.fits
2026-04-15 20:14:43,601 - stpipe.step - INFO - Step ramp_fit running with args (<RampModel(61, 12, 80, 80) from jw01093015001_03102_00001_nis_ramp.fits>,).
2026-04-15 20:14:43,605 - jwst.ramp_fitting.ramp_fit_step - INFO - Using READNOISE reference file: /home/runner/crds/references/jwst/niriss/jwst_niriss_readnoise_0005.fits
2026-04-15 20:14:43,606 - jwst.ramp_fitting.ramp_fit_step - INFO - Using GAIN reference file: /home/runner/crds/references/jwst/niriss/jwst_niriss_gain_0006.fits
2026-04-15 20:14:43,635 - jwst.ramp_fitting.ramp_fit_step - INFO - Extracting gain subarray to match science data
2026-04-15 20:14:43,648 - jwst.ramp_fitting.ramp_fit_step - INFO - Extracting readnoise subarray to match science data
2026-04-15 20:14:43,659 - jwst.ramp_fitting.ramp_fit_step - INFO - Using algorithm = OLS_C
2026-04-15 20:14:43,659 - jwst.ramp_fitting.ramp_fit_step - INFO - Using weighting = optimal
2026-04-15 20:14:43,667 - stcal.ramp_fitting.ols_fit - INFO - Number of multiprocessing slices: 1
2026-04-15 20:14:43,852 - stcal.ramp_fitting.ols_fit - INFO - Ramp Fitting C Time: 0.18394756317138672
2026-04-15 20:14:43,943 - stpipe.step - INFO - Step ramp_fit done
2026-04-15 20:14:44,133 - stpipe.step - INFO - Step gain_scale running with args (<ImageModel(80, 80) from jw01093015001_03102_00001_nis_ramp.fits>,).
2026-04-15 20:14:44,135 - jwst.gain_scale.gain_scale_step - INFO - Using GAIN reference file: /home/runner/crds/references/jwst/niriss/jwst_niriss_gain_0006.fits
2026-04-15 20:14:44,148 - jwst.gain_scale.gain_scale_step - INFO - GAINFACT not found in gain reference file
2026-04-15 20:14:44,149 - jwst.gain_scale.gain_scale_step - INFO - Step will be skipped
2026-04-15 20:14:44,151 - stpipe.step - INFO - Step gain_scale done
2026-04-15 20:14:44,335 - stpipe.step - INFO - Step gain_scale running with args (<CubeModel(61, 80, 80) from jw01093015001_03102_00001_nis_ramp.fits>,).
2026-04-15 20:14:44,338 - jwst.gain_scale.gain_scale_step - INFO - Using GAIN reference file: /home/runner/crds/references/jwst/niriss/jwst_niriss_gain_0006.fits
2026-04-15 20:14:44,351 - jwst.gain_scale.gain_scale_step - INFO - GAINFACT not found in gain reference file
2026-04-15 20:14:44,351 - jwst.gain_scale.gain_scale_step - INFO - Step will be skipped
2026-04-15 20:14:44,354 - stpipe.step - INFO - Step gain_scale done
2026-04-15 20:14:44,392 - stpipe.step - INFO - Saved model in ./nis_ami_demo_data/PID_1093/stage1/jw01093015001_03102_00001_nis_rateints.fits
2026-04-15 20:14:44,392 - jwst.pipeline.calwebb_detector1 - INFO - ... ending calwebb_detector1
2026-04-15 20:14:44,394 - jwst.stpipe.core - INFO - Results used CRDS context: jwst_1535.pmap
2026-04-15 20:14:44,427 - stpipe.step - INFO - Saved model in ./nis_ami_demo_data/PID_1093/stage1/jw01093015001_03102_00001_nis_rate.fits
2026-04-15 20:14:44,428 - stpipe.step - INFO - Step Detector1Pipeline done
2026-04-15 20:14:44,428 - jwst.stpipe.core - INFO - Results used jwst version: 2.0.0
# Print out the time benchmark
time1 = time.perf_counter()
print(f"Runtime for Detector1: {time1 - time0:0.0f} seconds")
Runtime for Detector1: 76 seconds
Exploring the data#
Identify *_rateints.fits files and verify which pipeline steps were run and
which calibration reference files were applied.
The header contains information about which calibration steps were completed and skipped and which reference files were used to process the data.
if dodet1:
# find rateints files
rateints_files = sorted(glob.glob(os.path.join(det1_dir, '*_rateints.fits')))
# Restrict to selected filter if applicable
rateints_files = select_filter_files(rateints_files, use_filter)
# Read in the first file as datamodel as an example
rateints = datamodels.open(rateints_files[0])
# Check which steps were run
for step, status in rateints.meta.cal_step.instance.items():
print(f"{step}: {status}")
charge_migration: COMPLETE
clean_flicker_noise: SKIPPED
dq_init: COMPLETE
gain_scale: SKIPPED
group_scale: SKIPPED
ipc: SKIPPED
jump: COMPLETE
linearity: COMPLETE
persistence: SKIPPED
picture_frame: SKIPPED
ramp_fit: COMPLETE
refpix: COMPLETE
saturation: COMPLETE
superbias: COMPLETE
Check which CRDS version and reference files were used to calibrate the dataset:
if dodet1:
for key, val in rateints.meta.ref_file.instance.items():
print(f"{key}:")
for param in rateints.meta.ref_file.instance[key]:
print(f"\t{rateints.meta.ref_file.instance[key][param]}")
crds:
jwst_1535.pmap
13.1.13
gain:
crds://jwst_niriss_gain_0006.fits
linearity:
crds://jwst_niriss_linearity_0017.fits
mask:
crds://jwst_niriss_mask_0016.fits
readnoise:
crds://jwst_niriss_readnoise_0005.fits
saturation:
crds://jwst_niriss_saturation_0015.fits
superbias:
crds://jwst_niriss_superbias_0182.fits
6. Image2 Pipeline#
In the Image2 stage of the pipeline,
calibrated data products are created (*_cal.fits or
*_calints.fits files, depending on whether the input files are
*_rate.fits or *_rateints.fits).
In this pipeline processing stage, the data are flat fielded. For AMI, we do not perform any of the other Image2 steps such as photometric calibration, so our output data products still have units of countrate (ADU/s).
time_image2 = time.perf_counter()
# Set up a dictionary to define how the Image2 pipeline should be configured.
# Boilerplate dictionary setup
image2dict = defaultdict(dict)
image2steps = ['assign_wcs', 'flat_field', 'photom', 'resample']
# Overrides for whether or not certain steps should be skipped (example)
image2dict['photom']['skip'] = True
image2dict['resample']['skip'] = True
# Overrides for various reference files
# Files should be in the base local directory or provide full path
#image2dict['flat_field']['override_flat'] = 'myfile.fits' # Pixel flatfield
Find and sort the input files, ensuring use of absolute paths:
# Use files from the detector1 output folder
rateints_files = sorted(glob.glob(os.path.join(det1_dir, 'jw*rateints.fits')))
# Restrict to selected filter if applicable
rateints_files = select_filter_files(rateints_files, use_filter)
for ii in range(len(rateints_files)):
rateints_files[ii] = os.path.abspath(rateints_files[ii])
print(f"Found {str(len(rateints_files))} science files")
Found 2 science files
# Run Image2 stage of pipeline, specifying:
# output directory to save *_calints.fits files
# save_results flag set to True so the calints files are saved
if doimage2:
for rateints in rateints_files:
calints_result = Image2Pipeline.call(rateints,
output_dir=image2_dir,
steps=image2dict,
save_results=True)
else:
print("Skipping Image2 processing.")
2026-04-15 20:14:44,535 - CRDS - INFO - Fetching /home/runner/crds/references/jwst/niriss/jwst_niriss_pars-resamplestep_0001.asdf 1.2 K bytes (1 / 1 files) (0 / 1.2 K bytes)
2026-04-15 20:14:44,632 - stpipe.step - INFO - PARS-RESAMPLESTEP parameters found: /home/runner/crds/references/jwst/niriss/jwst_niriss_pars-resamplestep_0001.asdf
2026-04-15 20:14:44,641 - CRDS - INFO - Fetching /home/runner/crds/references/jwst/niriss/jwst_niriss_pars-image2pipeline_0001.asdf 1.0 K bytes (1 / 1 files) (0 / 1.0 K bytes)
2026-04-15 20:14:44,730 - stpipe.pipeline - INFO - PARS-IMAGE2PIPELINE parameters found: /home/runner/crds/references/jwst/niriss/jwst_niriss_pars-image2pipeline_0001.asdf
2026-04-15 20:14:44,740 - stpipe.step - INFO - Image2Pipeline instance created.
2026-04-15 20:14:44,741 - stpipe.step - INFO - BackgroundStep instance created.
2026-04-15 20:14:44,742 - stpipe.step - INFO - AssignWcsStep instance created.
2026-04-15 20:14:44,742 - stpipe.step - INFO - FlatFieldStep instance created.
2026-04-15 20:14:44,743 - stpipe.step - INFO - PhotomStep instance created.
2026-04-15 20:14:44,744 - stpipe.step - INFO - ResampleStep instance created.
2026-04-15 20:14:44,928 - stpipe.step - INFO - Step Image2Pipeline running with args ('/home/runner/work/jwst-pipeline-notebooks/jwst-pipeline-notebooks/notebooks/NIRISS/AMI/nis_ami_demo_data/PID_1093/stage1/jw01093012001_03102_00001_nis_rateints.fits',).
2026-04-15 20:14:44,933 - stpipe.step - INFO - Step Image2Pipeline parameters are:
pre_hooks: []
post_hooks: []
output_file: None
output_dir: ./nis_ami_demo_data/PID_1093/stage2
output_ext: .fits
output_use_model: False
output_use_index: True
save_results: True
skip: False
suffix: None
search_output_file: True
input_dir: ''
save_bsub: False
steps:
bkg_subtract:
pre_hooks: []
post_hooks: []
output_file: None
output_dir: None
output_ext: .fits
output_use_model: False
output_use_index: True
save_results: False
skip: False
suffix: None
search_output_file: True
input_dir: ''
bkg_list: None
save_combined_background: False
sigma: 3.0
maxiters: None
soss_source_percentile: 35.0
soss_bkg_percentile: None
wfss_mmag_extract: None
wfss_mask: None
wfss_maxiter: 5
wfss_rms_stop: 0.0
wfss_outlier_percent: 1.0
assign_wcs:
pre_hooks: []
post_hooks: []
output_file: None
output_dir: None
output_ext: .fits
output_use_model: False
output_use_index: True
save_results: False
skip: False
suffix: None
search_output_file: True
input_dir: ''
sip_approx: True
sip_max_pix_error: 0.01
sip_degree: None
sip_max_inv_pix_error: 0.01
sip_inv_degree: None
sip_npoints: 12
slit_y_low: -0.55
slit_y_high: 0.55
nrs_ifu_slice_wcs: False
flat_field:
pre_hooks: []
post_hooks: []
output_file: None
output_dir: None
output_ext: .fits
output_use_model: False
output_use_index: True
save_results: False
skip: False
suffix: None
search_output_file: True
input_dir: ''
save_interpolated_flat: False
user_supplied_flat: None
inverse: False
photom:
pre_hooks: []
post_hooks: []
output_file: None
output_dir: None
output_ext: .fits
output_use_model: False
output_use_index: True
save_results: False
skip: True
suffix: None
search_output_file: True
input_dir: ''
inverse: False
source_type: None
apply_time_correction: True
resample:
pre_hooks: []
post_hooks: []
output_file: None
output_dir: None
output_ext: .fits
output_use_model: False
output_use_index: True
save_results: False
skip: True
suffix: None
search_output_file: True
input_dir: ''
pixfrac: 1.0
kernel: square
fillval: NAN
weight_type: ivm
output_shape: None
crpix: None
crval: None
rotation: None
pixel_scale_ratio: 1.0
pixel_scale: None
output_wcs: ''
single: False
blendheaders: True
in_memory: True
enable_ctx: True
enable_err: True
report_var: True
propagate_dq: False
pixmap_stepsize: 1.0
pixmap_order: 1
2026-04-15 20:14:44,948 - stpipe.pipeline - INFO - Prefetching reference files for dataset: 'jw01093012001_03102_00001_nis_rateints.fits' reftypes = ['bkg', 'camera', 'collimator', 'dflat', 'disperser', 'distortion', 'fflat', 'filteroffset', 'flat', 'fore', 'fpa', 'ifufore', 'ifupost', 'ifuslicer', 'msa', 'ote', 'regions', 'sflat', 'specwcs', 'wavelengthrange']
2026-04-15 20:14:44,950 - CRDS - INFO - Fetching /home/runner/crds/references/jwst/niriss/jwst_niriss_distortion_0023.asdf 9.6 K bytes (1 / 3 files) (0 / 67.1 M bytes)
2026-04-15 20:14:45,049 - CRDS - INFO - Fetching /home/runner/crds/references/jwst/niriss/jwst_niriss_filteroffset_0006.asdf 5.4 K bytes (2 / 3 files) (9.6 K / 67.1 M bytes)
2026-04-15 20:14:45,138 - CRDS - INFO - Fetching /home/runner/crds/references/jwst/niriss/jwst_niriss_flat_0277.fits 67.1 M bytes (3 / 3 files) (15.0 K / 67.1 M bytes)
2026-04-15 20:14:45,965 - stpipe.pipeline - INFO - Prefetch for BKG reference file is 'N/A'.
2026-04-15 20:14:45,965 - stpipe.pipeline - INFO - Prefetch for CAMERA reference file is 'N/A'.
2026-04-15 20:14:45,966 - stpipe.pipeline - INFO - Prefetch for COLLIMATOR reference file is 'N/A'.
2026-04-15 20:14:45,966 - stpipe.pipeline - INFO - Prefetch for DFLAT reference file is 'N/A'.
2026-04-15 20:14:45,967 - stpipe.pipeline - INFO - Prefetch for DISPERSER reference file is 'N/A'.
2026-04-15 20:14:45,967 - stpipe.pipeline - INFO - Prefetch for DISTORTION reference file is '/home/runner/crds/references/jwst/niriss/jwst_niriss_distortion_0023.asdf'.
2026-04-15 20:14:45,968 - stpipe.pipeline - INFO - Prefetch for FFLAT reference file is 'N/A'.
2026-04-15 20:14:45,968 - stpipe.pipeline - INFO - Prefetch for FILTEROFFSET reference file is '/home/runner/crds/references/jwst/niriss/jwst_niriss_filteroffset_0006.asdf'.
2026-04-15 20:14:45,969 - stpipe.pipeline - INFO - Prefetch for FLAT reference file is '/home/runner/crds/references/jwst/niriss/jwst_niriss_flat_0277.fits'.
2026-04-15 20:14:45,969 - stpipe.pipeline - INFO - Prefetch for FORE reference file is 'N/A'.
2026-04-15 20:14:45,970 - stpipe.pipeline - INFO - Prefetch for FPA reference file is 'N/A'.
2026-04-15 20:14:45,970 - stpipe.pipeline - INFO - Prefetch for IFUFORE reference file is 'N/A'.
2026-04-15 20:14:45,970 - stpipe.pipeline - INFO - Prefetch for IFUPOST reference file is 'N/A'.
2026-04-15 20:14:45,971 - stpipe.pipeline - INFO - Prefetch for IFUSLICER reference file is 'N/A'.
2026-04-15 20:14:45,971 - stpipe.pipeline - INFO - Prefetch for MSA reference file is 'N/A'.
2026-04-15 20:14:45,972 - stpipe.pipeline - INFO - Prefetch for OTE reference file is 'N/A'.
2026-04-15 20:14:45,972 - stpipe.pipeline - INFO - Prefetch for REGIONS reference file is 'N/A'.
2026-04-15 20:14:45,972 - stpipe.pipeline - INFO - Prefetch for SFLAT reference file is 'N/A'.
2026-04-15 20:14:45,973 - stpipe.pipeline - INFO - Prefetch for SPECWCS reference file is 'N/A'.
2026-04-15 20:14:45,973 - stpipe.pipeline - INFO - Prefetch for WAVELENGTHRANGE reference file is 'N/A'.
2026-04-15 20:14:45,973 - jwst.pipeline.calwebb_image2 - INFO - Starting calwebb_image2 ...
2026-04-15 20:14:45,974 - jwst.pipeline.calwebb_image2 - INFO - Processing product /home/runner/work/jwst-pipeline-notebooks/jwst-pipeline-notebooks/notebooks/NIRISS/AMI/nis_ami_demo_data/PID_1093/stage1/jw01093012001_03102_00001_nis
2026-04-15 20:14:45,974 - jwst.pipeline.calwebb_image2 - INFO - Working on input /home/runner/work/jwst-pipeline-notebooks/jwst-pipeline-notebooks/notebooks/NIRISS/AMI/nis_ami_demo_data/PID_1093/stage1/jw01093012001_03102_00001_nis_rateints.fits ...
2026-04-15 20:14:46,216 - stpipe.step - INFO - Step assign_wcs running with args (<CubeModel(69, 80, 80) from ./nis_ami_demo_data/PID_1093/stage2/jw01093012001_03102_00001_nis_image2pipeline.fits>,).
2026-04-15 20:14:46,277 - jwst.lib.reffile_utils - WARNING - Expected to find one matching row in table, found 0.
2026-04-15 20:14:46,302 - stcal.alignment.util - INFO - Update S_REGION to POLYGON ICRS 82.185417647 -65.447025854 82.185879050 -65.448473720 82.189340336 -65.448276665 82.188878915 -65.446828751
2026-04-15 20:14:46,303 - jwst.assign_wcs.assign_wcs - INFO - assign_wcs updated S_REGION to POLYGON ICRS 82.185417647 -65.447025854 82.185879050 -65.448473720 82.189340336 -65.448276665 82.188878915 -65.446828751
2026-04-15 20:14:46,304 - jwst.assign_wcs.assign_wcs - INFO - COMPLETED assign_wcs
2026-04-15 20:14:46,325 - stpipe.step - INFO - Step assign_wcs done
2026-04-15 20:14:46,523 - stpipe.step - INFO - Step flat_field running with args (<CubeModel(69, 80, 80) from ./nis_ami_demo_data/PID_1093/stage2/jw01093012001_03102_00001_nis_image2pipeline.fits>,).
2026-04-15 20:14:46,606 - jwst.flatfield.flat_field_step - INFO - Using FLAT reference file: /home/runner/crds/references/jwst/niriss/jwst_niriss_flat_0277.fits
2026-04-15 20:14:46,607 - jwst.flatfield.flat_field_step - INFO - No reference found for type FFLAT
2026-04-15 20:14:46,607 - jwst.flatfield.flat_field_step - INFO - No reference found for type SFLAT
2026-04-15 20:14:46,607 - jwst.flatfield.flat_field_step - INFO - No reference found for type DFLAT
2026-04-15 20:14:46,608 - jwst.flatfield.flat_field - INFO - Extracting matching subarray from flat
2026-04-15 20:14:46,655 - stpipe.step - INFO - Step flat_field done
2026-04-15 20:14:46,849 - stpipe.step - INFO - Step photom running with args (<CubeModel(69, 80, 80) from ./nis_ami_demo_data/PID_1093/stage2/jw01093012001_03102_00001_nis_image2pipeline.fits>,).
2026-04-15 20:14:46,850 - stpipe.step - INFO - Step skipped.
2026-04-15 20:14:46,851 - jwst.pipeline.calwebb_image2 - INFO - Finished processing product /home/runner/work/jwst-pipeline-notebooks/jwst-pipeline-notebooks/notebooks/NIRISS/AMI/nis_ami_demo_data/PID_1093/stage1/jw01093012001_03102_00001_nis
2026-04-15 20:14:46,852 - jwst.pipeline.calwebb_image2 - INFO - ... ending calwebb_image2
2026-04-15 20:14:46,852 - jwst.stpipe.core - INFO - Results used CRDS context: jwst_1535.pmap
2026-04-15 20:14:46,914 - stpipe.step - INFO - Saved model in ./nis_ami_demo_data/PID_1093/stage2/jw01093012001_03102_00001_nis_calints.fits
2026-04-15 20:14:46,915 - stpipe.step - INFO - Step Image2Pipeline done
2026-04-15 20:14:46,915 - jwst.stpipe.core - INFO - Results used jwst version: 2.0.0
2026-04-15 20:14:46,933 - stpipe.step - INFO - PARS-RESAMPLESTEP parameters found: /home/runner/crds/references/jwst/niriss/jwst_niriss_pars-resamplestep_0001.asdf
2026-04-15 20:14:46,941 - stpipe.pipeline - INFO - PARS-IMAGE2PIPELINE parameters found: /home/runner/crds/references/jwst/niriss/jwst_niriss_pars-image2pipeline_0001.asdf
2026-04-15 20:14:46,949 - stpipe.step - INFO - Image2Pipeline instance created.
2026-04-15 20:14:46,950 - stpipe.step - INFO - BackgroundStep instance created.
2026-04-15 20:14:46,951 - stpipe.step - INFO - AssignWcsStep instance created.
2026-04-15 20:14:46,952 - stpipe.step - INFO - FlatFieldStep instance created.
2026-04-15 20:14:46,952 - stpipe.step - INFO - PhotomStep instance created.
2026-04-15 20:14:46,953 - stpipe.step - INFO - ResampleStep instance created.
2026-04-15 20:14:47,146 - stpipe.step - INFO - Step Image2Pipeline running with args ('/home/runner/work/jwst-pipeline-notebooks/jwst-pipeline-notebooks/notebooks/NIRISS/AMI/nis_ami_demo_data/PID_1093/stage1/jw01093015001_03102_00001_nis_rateints.fits',).
2026-04-15 20:14:47,152 - stpipe.step - INFO - Step Image2Pipeline parameters are:
pre_hooks: []
post_hooks: []
output_file: None
output_dir: ./nis_ami_demo_data/PID_1093/stage2
output_ext: .fits
output_use_model: False
output_use_index: True
save_results: True
skip: False
suffix: None
search_output_file: True
input_dir: ''
save_bsub: False
steps:
bkg_subtract:
pre_hooks: []
post_hooks: []
output_file: None
output_dir: None
output_ext: .fits
output_use_model: False
output_use_index: True
save_results: False
skip: False
suffix: None
search_output_file: True
input_dir: ''
bkg_list: None
save_combined_background: False
sigma: 3.0
maxiters: None
soss_source_percentile: 35.0
soss_bkg_percentile: None
wfss_mmag_extract: None
wfss_mask: None
wfss_maxiter: 5
wfss_rms_stop: 0.0
wfss_outlier_percent: 1.0
assign_wcs:
pre_hooks: []
post_hooks: []
output_file: None
output_dir: None
output_ext: .fits
output_use_model: False
output_use_index: True
save_results: False
skip: False
suffix: None
search_output_file: True
input_dir: ''
sip_approx: True
sip_max_pix_error: 0.01
sip_degree: None
sip_max_inv_pix_error: 0.01
sip_inv_degree: None
sip_npoints: 12
slit_y_low: -0.55
slit_y_high: 0.55
nrs_ifu_slice_wcs: False
flat_field:
pre_hooks: []
post_hooks: []
output_file: None
output_dir: None
output_ext: .fits
output_use_model: False
output_use_index: True
save_results: False
skip: False
suffix: None
search_output_file: True
input_dir: ''
save_interpolated_flat: False
user_supplied_flat: None
inverse: False
photom:
pre_hooks: []
post_hooks: []
output_file: None
output_dir: None
output_ext: .fits
output_use_model: False
output_use_index: True
save_results: False
skip: True
suffix: None
search_output_file: True
input_dir: ''
inverse: False
source_type: None
apply_time_correction: True
resample:
pre_hooks: []
post_hooks: []
output_file: None
output_dir: None
output_ext: .fits
output_use_model: False
output_use_index: True
save_results: False
skip: True
suffix: None
search_output_file: True
input_dir: ''
pixfrac: 1.0
kernel: square
fillval: NAN
weight_type: ivm
output_shape: None
crpix: None
crval: None
rotation: None
pixel_scale_ratio: 1.0
pixel_scale: None
output_wcs: ''
single: False
blendheaders: True
in_memory: True
enable_ctx: True
enable_err: True
report_var: True
propagate_dq: False
pixmap_stepsize: 1.0
pixmap_order: 1
2026-04-15 20:14:47,167 - stpipe.pipeline - INFO - Prefetching reference files for dataset: 'jw01093015001_03102_00001_nis_rateints.fits' reftypes = ['bkg', 'camera', 'collimator', 'dflat', 'disperser', 'distortion', 'fflat', 'filteroffset', 'flat', 'fore', 'fpa', 'ifufore', 'ifupost', 'ifuslicer', 'msa', 'ote', 'regions', 'sflat', 'specwcs', 'wavelengthrange']
2026-04-15 20:14:47,169 - stpipe.pipeline - INFO - Prefetch for BKG reference file is 'N/A'.
2026-04-15 20:14:47,169 - stpipe.pipeline - INFO - Prefetch for CAMERA reference file is 'N/A'.
2026-04-15 20:14:47,170 - stpipe.pipeline - INFO - Prefetch for COLLIMATOR reference file is 'N/A'.
2026-04-15 20:14:47,170 - stpipe.pipeline - INFO - Prefetch for DFLAT reference file is 'N/A'.
2026-04-15 20:14:47,171 - stpipe.pipeline - INFO - Prefetch for DISPERSER reference file is 'N/A'.
2026-04-15 20:14:47,171 - stpipe.pipeline - INFO - Prefetch for DISTORTION reference file is '/home/runner/crds/references/jwst/niriss/jwst_niriss_distortion_0023.asdf'.
2026-04-15 20:14:47,172 - stpipe.pipeline - INFO - Prefetch for FFLAT reference file is 'N/A'.
2026-04-15 20:14:47,172 - stpipe.pipeline - INFO - Prefetch for FILTEROFFSET reference file is '/home/runner/crds/references/jwst/niriss/jwst_niriss_filteroffset_0006.asdf'.
2026-04-15 20:14:47,173 - stpipe.pipeline - INFO - Prefetch for FLAT reference file is '/home/runner/crds/references/jwst/niriss/jwst_niriss_flat_0277.fits'.
2026-04-15 20:14:47,173 - stpipe.pipeline - INFO - Prefetch for FORE reference file is 'N/A'.
2026-04-15 20:14:47,173 - stpipe.pipeline - INFO - Prefetch for FPA reference file is 'N/A'.
2026-04-15 20:14:47,174 - stpipe.pipeline - INFO - Prefetch for IFUFORE reference file is 'N/A'.
2026-04-15 20:14:47,174 - stpipe.pipeline - INFO - Prefetch for IFUPOST reference file is 'N/A'.
2026-04-15 20:14:47,175 - stpipe.pipeline - INFO - Prefetch for IFUSLICER reference file is 'N/A'.
2026-04-15 20:14:47,175 - stpipe.pipeline - INFO - Prefetch for MSA reference file is 'N/A'.
2026-04-15 20:14:47,176 - stpipe.pipeline - INFO - Prefetch for OTE reference file is 'N/A'.
2026-04-15 20:14:47,176 - stpipe.pipeline - INFO - Prefetch for REGIONS reference file is 'N/A'.
2026-04-15 20:14:47,177 - stpipe.pipeline - INFO - Prefetch for SFLAT reference file is 'N/A'.
2026-04-15 20:14:47,177 - stpipe.pipeline - INFO - Prefetch for SPECWCS reference file is 'N/A'.
2026-04-15 20:14:47,177 - stpipe.pipeline - INFO - Prefetch for WAVELENGTHRANGE reference file is 'N/A'.
2026-04-15 20:14:47,178 - jwst.pipeline.calwebb_image2 - INFO - Starting calwebb_image2 ...
2026-04-15 20:14:47,178 - jwst.pipeline.calwebb_image2 - INFO - Processing product /home/runner/work/jwst-pipeline-notebooks/jwst-pipeline-notebooks/notebooks/NIRISS/AMI/nis_ami_demo_data/PID_1093/stage1/jw01093015001_03102_00001_nis
2026-04-15 20:14:47,179 - jwst.pipeline.calwebb_image2 - INFO - Working on input /home/runner/work/jwst-pipeline-notebooks/jwst-pipeline-notebooks/notebooks/NIRISS/AMI/nis_ami_demo_data/PID_1093/stage1/jw01093015001_03102_00001_nis_rateints.fits ...
2026-04-15 20:14:47,423 - stpipe.step - INFO - Step assign_wcs running with args (<CubeModel(61, 80, 80) from ./nis_ami_demo_data/PID_1093/stage2/jw01093015001_03102_00001_nis_image2pipeline.fits>,).
2026-04-15 20:14:47,477 - jwst.lib.reffile_utils - WARNING - Expected to find one matching row in table, found 0.
2026-04-15 20:14:47,500 - stcal.alignment.util - INFO - Update S_REGION to POLYGON ICRS 82.782385811 -65.127657322 82.782869145 -65.129103610 82.786284904 -65.128895072 82.785801555 -65.127448736
2026-04-15 20:14:47,501 - jwst.assign_wcs.assign_wcs - INFO - assign_wcs updated S_REGION to POLYGON ICRS 82.782385811 -65.127657322 82.782869145 -65.129103610 82.786284904 -65.128895072 82.785801555 -65.127448736
2026-04-15 20:14:47,502 - jwst.assign_wcs.assign_wcs - INFO - COMPLETED assign_wcs
2026-04-15 20:14:47,521 - stpipe.step - INFO - Step assign_wcs done
2026-04-15 20:14:47,720 - stpipe.step - INFO - Step flat_field running with args (<CubeModel(61, 80, 80) from ./nis_ami_demo_data/PID_1093/stage2/jw01093015001_03102_00001_nis_image2pipeline.fits>,).
2026-04-15 20:14:47,789 - jwst.flatfield.flat_field_step - INFO - Using FLAT reference file: /home/runner/crds/references/jwst/niriss/jwst_niriss_flat_0277.fits
2026-04-15 20:14:47,790 - jwst.flatfield.flat_field_step - INFO - No reference found for type FFLAT
2026-04-15 20:14:47,790 - jwst.flatfield.flat_field_step - INFO - No reference found for type SFLAT
2026-04-15 20:14:47,791 - jwst.flatfield.flat_field_step - INFO - No reference found for type DFLAT
2026-04-15 20:14:47,791 - jwst.flatfield.flat_field - INFO - Extracting matching subarray from flat
2026-04-15 20:14:47,840 - stpipe.step - INFO - Step flat_field done
2026-04-15 20:14:48,045 - stpipe.step - INFO - Step photom running with args (<CubeModel(61, 80, 80) from ./nis_ami_demo_data/PID_1093/stage2/jw01093015001_03102_00001_nis_image2pipeline.fits>,).
2026-04-15 20:14:48,046 - stpipe.step - INFO - Step skipped.
2026-04-15 20:14:48,047 - jwst.pipeline.calwebb_image2 - INFO - Finished processing product /home/runner/work/jwst-pipeline-notebooks/jwst-pipeline-notebooks/notebooks/NIRISS/AMI/nis_ami_demo_data/PID_1093/stage1/jw01093015001_03102_00001_nis
2026-04-15 20:14:48,048 - jwst.pipeline.calwebb_image2 - INFO - ... ending calwebb_image2
2026-04-15 20:14:48,048 - jwst.stpipe.core - INFO - Results used CRDS context: jwst_1535.pmap
2026-04-15 20:14:48,111 - stpipe.step - INFO - Saved model in ./nis_ami_demo_data/PID_1093/stage2/jw01093015001_03102_00001_nis_calints.fits
2026-04-15 20:14:48,112 - stpipe.step - INFO - Step Image2Pipeline done
2026-04-15 20:14:48,112 - jwst.stpipe.core - INFO - Results used jwst version: 2.0.0
# Print out the time benchmark
time1 = time.perf_counter()
print(f"Runtime so far: {time1 - time0:0.0f} seconds")
print(f"Runtime for Image2: {time1 - time_image2:0.0f} seconds")
Runtime so far: 80 seconds
Runtime for Image2: 4 seconds
Verify which pipeline steps were run:
if doimage2:
# Identify *_calints.fits files
calints_files = sorted(glob.glob(os.path.join(image2_dir, '*_calints.fits')))
# Restrict to selected filter if applicable
calints_files = select_filter_files(calints_files, use_filter)
# Read in the first file as datamodel as an example
calints = datamodels.open(calints_files[0])
# Check which steps were run
for step, status in calints.meta.cal_step.instance.items():
print(f"{step}: {status}")
assign_wcs: COMPLETE
charge_migration: COMPLETE
clean_flicker_noise: SKIPPED
dq_init: COMPLETE
flat_field: COMPLETE
gain_scale: SKIPPED
group_scale: SKIPPED
ipc: SKIPPED
jump: COMPLETE
linearity: COMPLETE
persistence: SKIPPED
photom: SKIPPED
picture_frame: SKIPPED
ramp_fit: COMPLETE
refpix: COMPLETE
saturation: COMPLETE
superbias: COMPLETE
Check which reference files were used to calibrate the dataset:
if doimage2:
for key, val in calints.meta.ref_file.instance.items():
print(f"{key}:")
for param in calints.meta.ref_file.instance[key]:
print(f"\t{calints.meta.ref_file.instance[key][param]}")
camera:
N/A
collimator:
N/A
crds:
jwst_1535.pmap
13.1.13
dflat:
N/A
disperser:
N/A
distortion:
crds://jwst_niriss_distortion_0023.asdf
fflat:
N/A
filteroffset:
crds://jwst_niriss_filteroffset_0006.asdf
flat:
crds://jwst_niriss_flat_0277.fits
fore:
N/A
fpa:
N/A
gain:
crds://jwst_niriss_gain_0006.fits
ifufore:
N/A
ifupost:
N/A
ifuslicer:
N/A
linearity:
crds://jwst_niriss_linearity_0017.fits
mask:
crds://jwst_niriss_mask_0016.fits
msa:
N/A
ote:
N/A
readnoise:
crds://jwst_niriss_readnoise_0005.fits
regions:
N/A
saturation:
crds://jwst_niriss_saturation_0015.fits
sflat:
N/A
specwcs:
N/A
superbias:
crds://jwst_niriss_superbias_0182.fits
wavelengthrange:
N/A
7. AMI3 Pipeline#
In the AMI3 stage of the pipeline,
the target and reference star *_calints.fits files are analyzed to extract interferometric observables, and then the target’s observables are normalized by those of the reference star to produce a final set of calibrated observables.
In order to run the AMI3 stage, an Association file needs to be created to inform the pipeline which exposures should be treated as targets and which as reference stars.
By default, the AMI3 stage of the pipeline performs the following steps on NIRISS data:
ami_analyze - fits a model to each integration of the input image and computes interferometric observables (fringe phases, amplitudes, and derived quantities).
ami_normalize - normalizes the target’s observables by the reference star observables.
While a previous version of the AMI3 pipeline included an intermediate step to average together the observables from multiple exposures (ami_average), the step is not currently supported.
time_ami3 = time.perf_counter()
Create ASDF File#
The ami_analyze step has several optional arguments, some can be provided in an ASDF file containing a particular data tree. In here we will modify this file to provide an specific affine distortion matrix (affine2d).
For affine2d the default parameters from commissioning are accessed with a special string: ‘commissioning.’ If affine2d = None, it will perform a search for the best-fit rotation only. To use a different affine distortion, such as one measured directly from the data or an ideal distortion, it must be specified in an ASDF file as shown here.
# Example of writing an ASDF file specifying an affine distortion matrix to use
# Create an ASDF file
asdf_affine2d = os.path.join(sci_dir, 'affine2d_ideal.asdf')
aff_tree = {'mx': 1., # dimensionless x-magnification
'my': 1., # dimensionless y-magnification
'sx': 0., # dimensionless x shear
'sy': 0., # dimensionless y shear
'xo': 0., # x-offset in pupil space
'yo': 0., # y-offset in pupil space
'rotradccw': None}
with open(asdf_affine2d, 'wb') as fh:
af = asdf.AsdfFile(aff_tree)
af.write_to(fh)
af.close()
An example of using the affine distortion ASDF file created above is shown below.
# Set up a dictionary to define how the AMI3 pipeline should be configured
# Boilerplate dictionary setup
ami3dict = defaultdict(dict)
# Options for ami_analyze step
#ami3dict['ami_analyze']['firstfew'] = 5 # Analyze only the first 5 integrations to speed up demo
#ami3dict['ami_analyze']['affine2d'] = 11 # Increase oversampling of image plane fit (increases runtime)
#ami3dict['ami_analyze']['bandpass'] = 'myfile.asdf' # Provide a custom bandpass (e.g., from synphot)
ami3dict['ami_analyze']['affine2d'] = asdf_affine2d # Use the affine distortion ASDF file we created
ami3dict['ami_analyze']['save_results'] = True # Turn on optional output results for display purposes
# Overrides for whether or not certain steps should be skipped (example)
#ami3dict['ami_normalize']['skip'] = True
# Overrides for various reference files
# Files should be in the base local directory or provide full path
#ami3dict['ami_analyze']['override_nrm'] = 'mynrmfile.fits' # NRM mask geometry file
Find and sort all of the input files, ensuring use of absolute paths
# AMI3 takes the calints.fits files
calints_files = sorted(glob.glob(os.path.join(image2_dir, 'jw*calints.fits')))
# Restrict to selected filter if applicable
calints_files = select_filter_files(calints_files, use_filter)
calints_files = [os.path.abspath(calints) for calints in calints_files]
print(f'Found {str(len(calints_files))} science files to process')
Found 2 science files to process
Create Association Files#
An association file lists the exposures to calibrate together in Stage 3
of the pipeline. Note that an association file is available for download
from MAST, with a filename of *_asn.json, though it may require additional manipulation for AMI.
Here we create association files for each pairing of input science and reference PSF exposures.
Note that the final output products will have a rootname that is specified by the product_name
in the association file.
# Create Level 3 Associations
if doami3:
# Separate inputs into science and PSF reference exposures
scifiles, psffiles = split_scipsf_files(calints_files)
# Make an association file for every valid science/psf file pair
for sci in scifiles:
hdr = fits.getheader(sci)
thisfilter = hdr['FILTER']
# Potential PSF calibration files are those for which filter matches
psfoptions = select_filter_files(psffiles, thisfilter)
for psf in psfoptions:
# Construct product name from the input headers
prodname = 'ami3_' + hdr['TARGPROP'] + '_' + hdr['FILTER'] + '_' + hdr['ACT_ID']
prodname = prodname.replace(" ", "")
asn = asn_from_list.asn_from_list([sci],
rule=DMS_Level3_Base,
product_name=prodname)
# Set the second observation as the psf reference star
asn['products'][0]['members'].append({'expname': psf, 'exptype': 'psf'})
asn.data['asn_type'] = 'ami3'
asn.data['program'] = hdr['PROGRAM']
# Format association as .json file
asn_filename = prodname + '_asn.json'
_, serialized = asn.dump(format="json")
# Write out association file
association_ami3 = os.path.join(sci_dir, asn_filename)
with open(association_ami3, "w") as fd:
fd.write(serialized)
# List all associations
all_asn = sorted(glob.glob(os.path.join(sci_dir, '*_asn.json')))
/home/runner/micromamba/envs/ci-env/lib/python3.13/site-packages/jwst/associations/association.py:232: UserWarning: Input association file contains path information; note that this can complicate usage and/or sharing of such files.
warnings.warn(err_str, UserWarning, stacklevel=1)
Check that file paths have been correctly updated.
# Open an ASN file as an example.
if doami3:
if isinstance(all_asn, str):
with open(all_asn, 'r') as f_obj:
asnfile_data = json.load(f_obj)
elif isinstance(all_asn, list):
with open(all_asn[0], 'r') as f_obj:
asnfile_data = json.load(f_obj)
expanded_json = json.dumps(asnfile_data, indent=2) # 'expanded=True' maps to 'indent'
print(expanded_json)
{
"asn_type": "ami3",
"asn_rule": "DMS_Level3_Base",
"version_id": null,
"code_version": "2.0.0",
"degraded_status": "No known degraded exposures in association.",
"program": "01093",
"constraints": "No constraints",
"asn_id": "a3001",
"target": "none",
"asn_pool": "none",
"products": [
{
"name": "ami3_AB-DOR_F480M_02",
"members": [
{
"expname": "/home/runner/work/jwst-pipeline-notebooks/jwst-pipeline-notebooks/notebooks/NIRISS/AMI/nis_ami_demo_data/PID_1093/stage2/jw01093012001_03102_00001_nis_calints.fits",
"exptype": "science"
},
{
"expname": "/home/runner/work/jwst-pipeline-notebooks/jwst-pipeline-notebooks/notebooks/NIRISS/AMI/nis_ami_demo_data/PID_1093/stage2/jw01093015001_03102_00001_nis_calints.fits",
"exptype": "psf"
}
]
}
]
}
Run AMI3 stage of the pipeline#
For the target and reference star exposures listed in the association file, the
AMI3 stage of the pipeline will produce:
*ami-oi.fitsfiles (one for the target, one for the reference star) from theami_analyzestep containing averaged interferometric observables*aminorm-oi.fitsfile from theami_normalizestep containing normalized interferometric observables
The *ami-oi.fits and *aminorm-oi.fits files adhere to the OIFITS2 format, which is a registered FITS standard for optical and infrared interferometry data.
# Run Stage 3
if doami3:
for asn in all_asn:
ami3_result = Ami3Pipeline.call(asn,
output_dir=ami3_dir,
steps=ami3dict)
else:
print('Skipping AMI3 processing')
2026-04-15 20:14:48,554 - stpipe.step - INFO - Ami3Pipeline instance created.
2026-04-15 20:14:48,555 - stpipe.step - INFO - AmiAnalyzeStep instance created.
2026-04-15 20:14:48,555 - stpipe.step - INFO - AmiNormalizeStep instance created.
2026-04-15 20:14:48,764 - stpipe.step - INFO - Step Ami3Pipeline running with args ('./nis_ami_demo_data/PID_1093/ami3_AB-DOR_F480M_02_asn.json',).
2026-04-15 20:14:48,767 - stpipe.step - INFO - Step Ami3Pipeline parameters are:
pre_hooks: []
post_hooks: []
output_file: None
output_dir: ./nis_ami_demo_data/PID_1093/stage3
output_ext: .fits
output_use_model: False
output_use_index: True
save_results: False
skip: False
suffix: None
search_output_file: True
input_dir: ''
steps:
ami_analyze:
pre_hooks: []
post_hooks: []
output_file: None
output_dir: None
output_ext: .fits
output_use_model: False
output_use_index: True
save_results: True
skip: False
suffix: None
search_output_file: True
input_dir: ''
oversample: 3
rotation: 0.0
psf_offset: 0.0 0.0
rotation_search: -3 3 1
bandpass: None
usebp: True
firstfew: None
chooseholes: None
affine2d: ./nis_ami_demo_data/PID_1093/affine2d_ideal.asdf
run_bpfix: True
ami_normalize:
pre_hooks: []
post_hooks: []
output_file: None
output_dir: None
output_ext: .fits
output_use_model: False
output_use_index: True
save_results: False
skip: False
suffix: aminorm-oi
search_output_file: True
input_dir: ''
2026-04-15 20:14:48,809 - stpipe.pipeline - INFO - Prefetching reference files for dataset: 'ami3_AB-DOR_F480M_02_asn.json' reftypes = ['nrm', 'throughput']
2026-04-15 20:14:48,811 - CRDS - INFO - Fetching /home/runner/crds/references/jwst/niriss/jwst_niriss_nrm_0004.fits 4.2 M bytes (1 / 2 files) (0 / 4.3 M bytes)
2026-04-15 20:14:49,139 - CRDS - INFO - Fetching /home/runner/crds/references/jwst/niriss/jwst_niriss_throughput_0012.fits 86.4 K bytes (2 / 2 files) (4.2 M / 4.3 M bytes)
2026-04-15 20:14:49,270 - stpipe.pipeline - INFO - Prefetch for NRM reference file is '/home/runner/crds/references/jwst/niriss/jwst_niriss_nrm_0004.fits'.
2026-04-15 20:14:49,271 - stpipe.pipeline - INFO - Prefetch for THROUGHPUT reference file is '/home/runner/crds/references/jwst/niriss/jwst_niriss_throughput_0012.fits'.
2026-04-15 20:14:49,271 - jwst.pipeline.calwebb_ami3 - INFO - Starting calwebb_ami3
2026-04-15 20:14:49,471 - stpipe.step - INFO - Step ami_analyze running with args ('/home/runner/work/jwst-pipeline-notebooks/jwst-pipeline-notebooks/notebooks/NIRISS/AMI/nis_ami_demo_data/PID_1093/stage2/jw01093012001_03102_00001_nis_calints.fits',).
2026-04-15 20:14:49,472 - jwst.ami.ami_analyze_step - INFO - Oversampling factor = 3
2026-04-15 20:14:49,472 - jwst.ami.ami_analyze_step - INFO - Initial rotation guess = 0.0 deg
2026-04-15 20:14:49,473 - jwst.ami.ami_analyze_step - INFO - Initial values to use for psf offset = [0.0, 0.0]
2026-04-15 20:14:49,562 - jwst.ami.ami_analyze_step - INFO - Using filter throughput reference file /home/runner/crds/references/jwst/niriss/jwst_niriss_throughput_0012.fits
2026-04-15 20:14:49,565 - jwst.ami.ami_analyze_step - INFO - Using affine transform from ASDF file ./nis_ami_demo_data/PID_1093/affine2d_ideal.asdf
2026-04-15 20:14:49,568 - jwst.ami.ami_analyze_step - INFO - Using NRM reference file /home/runner/crds/references/jwst/niriss/jwst_niriss_nrm_0004.fits
2026-04-15 20:14:49,592 - jwst.ami.utils - INFO - Reading throughput model data for F480M.
2026-04-15 20:14:49,769 - jwst.ami.utils - INFO - Using flat spectrum model.
2026-04-15 20:14:50,094 - jwst.ami.ami_analyze - INFO - Using affine transform with parameters:
2026-04-15 20:14:50,095 - jwst.ami.ami_analyze - INFO - mx=1.000000 my=1.000000
2026-04-15 20:14:50,095 - jwst.ami.ami_analyze - INFO - sx=0.000000 sy=0.000000
2026-04-15 20:14:50,096 - jwst.ami.ami_analyze - INFO - xo=0.000000 yo=0.000000
2026-04-15 20:14:50,096 - jwst.ami.ami_analyze - INFO - rotradccw=None
2026-04-15 20:14:50,097 - jwst.ami.nrm_core - INFO - leastsqnrm.matrix_operations() - equally-weighted
2026-04-15 20:14:50,098 - jwst.ami.instrument_data - INFO - Rotating mask hole centers clockwise by 172.436 degrees
2026-04-15 20:14:50,107 - jwst.ami.instrument_data - INFO - 0 additional pixels >10-sig from median of stack found
2026-04-15 20:14:50,108 - jwst.ami.instrument_data - INFO - 0 DO_NOT_USE flags added to DQ array for found outlier pixels
2026-04-15 20:14:50,109 - jwst.ami.instrument_data - INFO - Cropping all integrations to 69x69 pixels around peak (40,45)
2026-04-15 20:14:50,109 - jwst.ami.instrument_data - INFO - Applying Fourier bad pixel correction to cropped data, updating DQ array
2026-04-15 20:14:50,111 - jwst.ami.bp_fix - INFO - 2533 pixels flagged DO_NOT_USE in cropped data
2026-04-15 20:14:50,112 - jwst.ami.bp_fix - INFO - Identified 2484 NaN pixels to correct
2026-04-15 20:14:50,114 - jwst.ami.bp_fix - INFO - FOV = 4.5 arcsec, Fourier sampling = 0.223 m/pix
2026-04-15 20:14:50,115 - jwst.ami.bp_fix - INFO - F480M: 4.817 to 4.986 micron
2026-04-15 20:14:50,150 - jwst.ami.bp_fix - INFO - Frame 1 of 69
2026-04-15 20:14:50,158 - jwst.ami.bp_fix - INFO - Identified 0 bad pixels (0.00%)
2026-04-15 20:14:50,159 - jwst.ami.bp_fix - INFO - 10.259
2026-04-15 20:14:50,160 - jwst.ami.bp_fix - INFO - Iteration 1: 0 new bad pixels, sdev of norm noise = 1.406
2026-04-15 20:14:50,165 - jwst.ami.bp_fix - INFO - Frame 2 of 69
2026-04-15 20:14:50,171 - jwst.ami.bp_fix - INFO - Identified 0 bad pixels (0.00%)
2026-04-15 20:14:50,172 - jwst.ami.bp_fix - INFO - 10.249
2026-04-15 20:14:50,172 - jwst.ami.bp_fix - INFO - Iteration 1: 0 new bad pixels, sdev of norm noise = 1.420
2026-04-15 20:14:50,177 - jwst.ami.bp_fix - INFO - Frame 3 of 69
2026-04-15 20:14:50,184 - jwst.ami.bp_fix - INFO - Identified 0 bad pixels (0.00%)
2026-04-15 20:14:50,184 - jwst.ami.bp_fix - INFO - 13.776
2026-04-15 20:14:50,185 - jwst.ami.bp_fix - INFO - Iteration 1: 0 new bad pixels, sdev of norm noise = 1.458
2026-04-15 20:14:50,190 - jwst.ami.bp_fix - INFO - Frame 4 of 69
2026-04-15 20:14:50,196 - jwst.ami.bp_fix - INFO - Identified 0 bad pixels (0.00%)
2026-04-15 20:14:50,197 - jwst.ami.bp_fix - INFO - 12.124
2026-04-15 20:14:50,197 - jwst.ami.bp_fix - INFO - Iteration 1: 0 new bad pixels, sdev of norm noise = 1.402
2026-04-15 20:14:50,202 - jwst.ami.bp_fix - INFO - Frame 5 of 69
2026-04-15 20:14:50,209 - jwst.ami.bp_fix - INFO - Identified 0 bad pixels (0.00%)
2026-04-15 20:14:50,209 - jwst.ami.bp_fix - INFO - 11.156
2026-04-15 20:14:50,210 - jwst.ami.bp_fix - INFO - Iteration 1: 0 new bad pixels, sdev of norm noise = 1.385
2026-04-15 20:14:50,215 - jwst.ami.bp_fix - INFO - Frame 6 of 69
2026-04-15 20:14:50,221 - jwst.ami.bp_fix - INFO - Identified 0 bad pixels (0.00%)
2026-04-15 20:14:50,222 - jwst.ami.bp_fix - INFO - 10.320
2026-04-15 20:14:50,222 - jwst.ami.bp_fix - INFO - Iteration 1: 0 new bad pixels, sdev of norm noise = 1.412
2026-04-15 20:14:50,227 - jwst.ami.bp_fix - INFO - Frame 7 of 69
2026-04-15 20:14:50,234 - jwst.ami.bp_fix - INFO - Identified 0 bad pixels (0.00%)
2026-04-15 20:14:50,235 - jwst.ami.bp_fix - INFO - 14.956
2026-04-15 20:14:50,235 - jwst.ami.bp_fix - INFO - Iteration 1: 0 new bad pixels, sdev of norm noise = 1.391
2026-04-15 20:14:50,240 - jwst.ami.bp_fix - INFO - Frame 8 of 69
2026-04-15 20:14:50,247 - jwst.ami.bp_fix - INFO - Identified 0 bad pixels (0.00%)
2026-04-15 20:14:50,247 - jwst.ami.bp_fix - INFO - 7.710
2026-04-15 20:14:50,248 - jwst.ami.bp_fix - INFO - Iteration 1: 0 new bad pixels, sdev of norm noise = 1.433
2026-04-15 20:14:50,253 - jwst.ami.bp_fix - INFO - Frame 9 of 69
2026-04-15 20:14:50,260 - jwst.ami.bp_fix - INFO - Identified 0 bad pixels (0.00%)
2026-04-15 20:14:50,260 - jwst.ami.bp_fix - INFO - 10.835
2026-04-15 20:14:50,261 - jwst.ami.bp_fix - INFO - Iteration 1: 0 new bad pixels, sdev of norm noise = 1.433
2026-04-15 20:14:50,266 - jwst.ami.bp_fix - INFO - Frame 10 of 69
2026-04-15 20:14:50,272 - jwst.ami.bp_fix - INFO - Identified 0 bad pixels (0.00%)
2026-04-15 20:14:50,273 - jwst.ami.bp_fix - INFO - 10.754
2026-04-15 20:14:50,274 - jwst.ami.bp_fix - INFO - Iteration 1: 0 new bad pixels, sdev of norm noise = 1.459
2026-04-15 20:14:50,279 - jwst.ami.bp_fix - INFO - Frame 11 of 69
2026-04-15 20:14:50,285 - jwst.ami.bp_fix - INFO - Identified 0 bad pixels (0.00%)
2026-04-15 20:14:50,286 - jwst.ami.bp_fix - INFO - 8.676
2026-04-15 20:14:50,286 - jwst.ami.bp_fix - INFO - Iteration 1: 0 new bad pixels, sdev of norm noise = 1.423
2026-04-15 20:14:50,291 - jwst.ami.bp_fix - INFO - Frame 12 of 69
2026-04-15 20:14:50,298 - jwst.ami.bp_fix - INFO - Identified 0 bad pixels (0.00%)
2026-04-15 20:14:50,299 - jwst.ami.bp_fix - INFO - 10.871
2026-04-15 20:14:50,299 - jwst.ami.bp_fix - INFO - Iteration 1: 0 new bad pixels, sdev of norm noise = 1.401
2026-04-15 20:14:50,304 - jwst.ami.bp_fix - INFO - Frame 13 of 69
2026-04-15 20:14:50,311 - jwst.ami.bp_fix - INFO - Identified 0 bad pixels (0.00%)
2026-04-15 20:14:50,312 - jwst.ami.bp_fix - INFO - 10.029
2026-04-15 20:14:50,313 - jwst.ami.bp_fix - INFO - Iteration 1: 0 new bad pixels, sdev of norm noise = 1.412
2026-04-15 20:14:50,317 - jwst.ami.bp_fix - INFO - Frame 14 of 69
2026-04-15 20:14:50,324 - jwst.ami.bp_fix - INFO - Identified 0 bad pixels (0.00%)
2026-04-15 20:14:50,325 - jwst.ami.bp_fix - INFO - 8.190
2026-04-15 20:14:50,325 - jwst.ami.bp_fix - INFO - Iteration 1: 0 new bad pixels, sdev of norm noise = 1.367
2026-04-15 20:14:50,330 - jwst.ami.bp_fix - INFO - Frame 15 of 69
2026-04-15 20:14:50,337 - jwst.ami.bp_fix - INFO - Identified 0 bad pixels (0.00%)
2026-04-15 20:14:50,337 - jwst.ami.bp_fix - INFO - 9.356
2026-04-15 20:14:50,338 - jwst.ami.bp_fix - INFO - Iteration 1: 0 new bad pixels, sdev of norm noise = 1.430
2026-04-15 20:14:50,343 - jwst.ami.bp_fix - INFO - Frame 16 of 69
2026-04-15 20:14:50,350 - jwst.ami.bp_fix - INFO - Identified 0 bad pixels (0.00%)
2026-04-15 20:14:50,350 - jwst.ami.bp_fix - INFO - 7.686
2026-04-15 20:14:50,351 - jwst.ami.bp_fix - INFO - Iteration 1: 0 new bad pixels, sdev of norm noise = 1.409
2026-04-15 20:14:50,356 - jwst.ami.bp_fix - INFO - Frame 17 of 69
2026-04-15 20:14:50,363 - jwst.ami.bp_fix - INFO - Identified 0 bad pixels (0.00%)
2026-04-15 20:14:50,363 - jwst.ami.bp_fix - INFO - 12.175
2026-04-15 20:14:50,364 - jwst.ami.bp_fix - INFO - Iteration 1: 0 new bad pixels, sdev of norm noise = 1.448
2026-04-15 20:14:50,369 - jwst.ami.bp_fix - INFO - Frame 18 of 69
2026-04-15 20:14:50,375 - jwst.ami.bp_fix - INFO - Identified 0 bad pixels (0.00%)
2026-04-15 20:14:50,376 - jwst.ami.bp_fix - INFO - 10.743
2026-04-15 20:14:50,377 - jwst.ami.bp_fix - INFO - Iteration 1: 0 new bad pixels, sdev of norm noise = 1.418
2026-04-15 20:14:50,382 - jwst.ami.bp_fix - INFO - Frame 19 of 69
2026-04-15 20:14:50,388 - jwst.ami.bp_fix - INFO - Identified 0 bad pixels (0.00%)
2026-04-15 20:14:50,389 - jwst.ami.bp_fix - INFO - 10.106
2026-04-15 20:14:50,390 - jwst.ami.bp_fix - INFO - Iteration 1: 0 new bad pixels, sdev of norm noise = 1.465
2026-04-15 20:14:50,395 - jwst.ami.bp_fix - INFO - Frame 20 of 69
2026-04-15 20:14:50,401 - jwst.ami.bp_fix - INFO - Identified 0 bad pixels (0.00%)
2026-04-15 20:14:50,402 - jwst.ami.bp_fix - INFO - 9.324
2026-04-15 20:14:50,403 - jwst.ami.bp_fix - INFO - Iteration 1: 0 new bad pixels, sdev of norm noise = 1.415
2026-04-15 20:14:50,408 - jwst.ami.bp_fix - INFO - Frame 21 of 69
2026-04-15 20:14:50,415 - jwst.ami.bp_fix - INFO - Identified 0 bad pixels (0.00%)
2026-04-15 20:14:50,415 - jwst.ami.bp_fix - INFO - 8.822
2026-04-15 20:14:50,416 - jwst.ami.bp_fix - INFO - Iteration 1: 0 new bad pixels, sdev of norm noise = 1.422
2026-04-15 20:14:50,421 - jwst.ami.bp_fix - INFO - Frame 22 of 69
2026-04-15 20:14:50,427 - jwst.ami.bp_fix - INFO - Identified 0 bad pixels (0.00%)
2026-04-15 20:14:50,428 - jwst.ami.bp_fix - INFO - 9.344
2026-04-15 20:14:50,429 - jwst.ami.bp_fix - INFO - Iteration 1: 0 new bad pixels, sdev of norm noise = 1.447
2026-04-15 20:14:50,434 - jwst.ami.bp_fix - INFO - Frame 23 of 69
2026-04-15 20:14:50,440 - jwst.ami.bp_fix - INFO - Identified 0 bad pixels (0.00%)
2026-04-15 20:14:50,441 - jwst.ami.bp_fix - INFO - 10.405
2026-04-15 20:14:50,442 - jwst.ami.bp_fix - INFO - Iteration 1: 0 new bad pixels, sdev of norm noise = 1.465
2026-04-15 20:14:50,446 - jwst.ami.bp_fix - INFO - Frame 24 of 69
2026-04-15 20:14:50,453 - jwst.ami.bp_fix - INFO - Identified 0 bad pixels (0.00%)
2026-04-15 20:14:50,454 - jwst.ami.bp_fix - INFO - 8.012
2026-04-15 20:14:50,455 - jwst.ami.bp_fix - INFO - Iteration 1: 0 new bad pixels, sdev of norm noise = 1.389
2026-04-15 20:14:50,460 - jwst.ami.bp_fix - INFO - Frame 25 of 69
2026-04-15 20:14:50,467 - jwst.ami.bp_fix - INFO - Identified 0 bad pixels (0.00%)
2026-04-15 20:14:50,467 - jwst.ami.bp_fix - INFO - 11.463
2026-04-15 20:14:50,468 - jwst.ami.bp_fix - INFO - Iteration 1: 0 new bad pixels, sdev of norm noise = 1.385
2026-04-15 20:14:50,473 - jwst.ami.bp_fix - INFO - Frame 26 of 69
2026-04-15 20:14:50,480 - jwst.ami.bp_fix - INFO - Identified 0 bad pixels (0.00%)
2026-04-15 20:14:50,480 - jwst.ami.bp_fix - INFO - 9.516
2026-04-15 20:14:50,481 - jwst.ami.bp_fix - INFO - Iteration 1: 0 new bad pixels, sdev of norm noise = 1.411
2026-04-15 20:14:50,486 - jwst.ami.bp_fix - INFO - Frame 27 of 69
2026-04-15 20:14:50,493 - jwst.ami.bp_fix - INFO - Identified 0 bad pixels (0.00%)
2026-04-15 20:14:50,493 - jwst.ami.bp_fix - INFO - 9.740
2026-04-15 20:14:50,494 - jwst.ami.bp_fix - INFO - Iteration 1: 0 new bad pixels, sdev of norm noise = 1.479
2026-04-15 20:14:50,499 - jwst.ami.bp_fix - INFO - Frame 28 of 69
2026-04-15 20:14:50,505 - jwst.ami.bp_fix - INFO - Identified 0 bad pixels (0.00%)
2026-04-15 20:14:50,506 - jwst.ami.bp_fix - INFO - 8.965
2026-04-15 20:14:50,507 - jwst.ami.bp_fix - INFO - Iteration 1: 0 new bad pixels, sdev of norm noise = 1.434
2026-04-15 20:14:50,512 - jwst.ami.bp_fix - INFO - Frame 29 of 69
2026-04-15 20:14:50,518 - jwst.ami.bp_fix - INFO - Identified 0 bad pixels (0.00%)
2026-04-15 20:14:50,519 - jwst.ami.bp_fix - INFO - 8.571
2026-04-15 20:14:50,520 - jwst.ami.bp_fix - INFO - Iteration 1: 0 new bad pixels, sdev of norm noise = 1.413
2026-04-15 20:14:50,525 - jwst.ami.bp_fix - INFO - Frame 30 of 69
2026-04-15 20:14:50,532 - jwst.ami.bp_fix - INFO - Identified 0 bad pixels (0.00%)
2026-04-15 20:14:50,533 - jwst.ami.bp_fix - INFO - 8.463
2026-04-15 20:14:50,534 - jwst.ami.bp_fix - INFO - Iteration 1: 0 new bad pixels, sdev of norm noise = 1.438
2026-04-15 20:14:50,539 - jwst.ami.bp_fix - INFO - Frame 31 of 69
2026-04-15 20:14:50,546 - jwst.ami.bp_fix - INFO - Identified 0 bad pixels (0.00%)
2026-04-15 20:14:50,547 - jwst.ami.bp_fix - INFO - 8.444
2026-04-15 20:14:50,547 - jwst.ami.bp_fix - INFO - Iteration 1: 0 new bad pixels, sdev of norm noise = 1.425
2026-04-15 20:14:50,552 - jwst.ami.bp_fix - INFO - Frame 32 of 69
2026-04-15 20:14:50,559 - jwst.ami.bp_fix - INFO - Identified 0 bad pixels (0.00%)
2026-04-15 20:14:50,560 - jwst.ami.bp_fix - INFO - 9.010
2026-04-15 20:14:50,560 - jwst.ami.bp_fix - INFO - Iteration 1: 0 new bad pixels, sdev of norm noise = 1.369
2026-04-15 20:14:50,565 - jwst.ami.bp_fix - INFO - Frame 33 of 69
2026-04-15 20:14:50,572 - jwst.ami.bp_fix - INFO - Identified 0 bad pixels (0.00%)
2026-04-15 20:14:50,573 - jwst.ami.bp_fix - INFO - 10.819
2026-04-15 20:14:50,573 - jwst.ami.bp_fix - INFO - Iteration 1: 0 new bad pixels, sdev of norm noise = 1.407
2026-04-15 20:14:50,578 - jwst.ami.bp_fix - INFO - Frame 34 of 69
2026-04-15 20:14:50,585 - jwst.ami.bp_fix - INFO - Identified 0 bad pixels (0.00%)
2026-04-15 20:14:50,586 - jwst.ami.bp_fix - INFO - 8.463
2026-04-15 20:14:50,586 - jwst.ami.bp_fix - INFO - Iteration 1: 0 new bad pixels, sdev of norm noise = 1.396
2026-04-15 20:14:50,591 - jwst.ami.bp_fix - INFO - Frame 35 of 69
2026-04-15 20:14:50,598 - jwst.ami.bp_fix - INFO - Identified 0 bad pixels (0.00%)
2026-04-15 20:14:50,599 - jwst.ami.bp_fix - INFO - 8.651
2026-04-15 20:14:50,599 - jwst.ami.bp_fix - INFO - Iteration 1: 0 new bad pixels, sdev of norm noise = 1.447
2026-04-15 20:14:50,604 - jwst.ami.bp_fix - INFO - Frame 36 of 69
2026-04-15 20:14:50,611 - jwst.ami.bp_fix - INFO - Identified 0 bad pixels (0.00%)
2026-04-15 20:14:50,611 - jwst.ami.bp_fix - INFO - 10.672
2026-04-15 20:14:50,612 - jwst.ami.bp_fix - INFO - Iteration 1: 0 new bad pixels, sdev of norm noise = 1.433
2026-04-15 20:14:50,617 - jwst.ami.bp_fix - INFO - Frame 37 of 69
2026-04-15 20:14:50,623 - jwst.ami.bp_fix - INFO - Identified 0 bad pixels (0.00%)
2026-04-15 20:14:50,624 - jwst.ami.bp_fix - INFO - 8.945
2026-04-15 20:14:50,625 - jwst.ami.bp_fix - INFO - Iteration 1: 0 new bad pixels, sdev of norm noise = 1.451
2026-04-15 20:14:50,630 - jwst.ami.bp_fix - INFO - Frame 38 of 69
2026-04-15 20:14:50,636 - jwst.ami.bp_fix - INFO - Identified 0 bad pixels (0.00%)
2026-04-15 20:14:50,637 - jwst.ami.bp_fix - INFO - 10.037
2026-04-15 20:14:50,637 - jwst.ami.bp_fix - INFO - Iteration 1: 0 new bad pixels, sdev of norm noise = 1.438
2026-04-15 20:14:50,642 - jwst.ami.bp_fix - INFO - Frame 39 of 69
2026-04-15 20:14:50,648 - jwst.ami.bp_fix - INFO - Identified 0 bad pixels (0.00%)
2026-04-15 20:14:50,649 - jwst.ami.bp_fix - INFO - 10.640
2026-04-15 20:14:50,650 - jwst.ami.bp_fix - INFO - Iteration 1: 0 new bad pixels, sdev of norm noise = 1.423
2026-04-15 20:14:50,655 - jwst.ami.bp_fix - INFO - Frame 40 of 69
2026-04-15 20:14:50,661 - jwst.ami.bp_fix - INFO - Identified 0 bad pixels (0.00%)
2026-04-15 20:14:50,662 - jwst.ami.bp_fix - INFO - 10.640
2026-04-15 20:14:50,663 - jwst.ami.bp_fix - INFO - Iteration 1: 0 new bad pixels, sdev of norm noise = 1.389
2026-04-15 20:14:50,668 - jwst.ami.bp_fix - INFO - Frame 41 of 69
2026-04-15 20:14:50,674 - jwst.ami.bp_fix - INFO - Identified 0 bad pixels (0.00%)
2026-04-15 20:14:50,675 - jwst.ami.bp_fix - INFO - 8.345
2026-04-15 20:14:50,676 - jwst.ami.bp_fix - INFO - Iteration 1: 0 new bad pixels, sdev of norm noise = 1.411
2026-04-15 20:14:50,681 - jwst.ami.bp_fix - INFO - Frame 42 of 69
2026-04-15 20:14:50,687 - jwst.ami.bp_fix - INFO - Identified 0 bad pixels (0.00%)
2026-04-15 20:14:50,688 - jwst.ami.bp_fix - INFO - 8.467
2026-04-15 20:14:50,688 - jwst.ami.bp_fix - INFO - Iteration 1: 0 new bad pixels, sdev of norm noise = 1.451
2026-04-15 20:14:50,693 - jwst.ami.bp_fix - INFO - Frame 43 of 69
2026-04-15 20:14:50,700 - jwst.ami.bp_fix - INFO - Identified 0 bad pixels (0.00%)
2026-04-15 20:14:50,701 - jwst.ami.bp_fix - INFO - 8.430
2026-04-15 20:14:50,701 - jwst.ami.bp_fix - INFO - Iteration 1: 0 new bad pixels, sdev of norm noise = 1.410
2026-04-15 20:14:50,706 - jwst.ami.bp_fix - INFO - Frame 44 of 69
2026-04-15 20:14:50,713 - jwst.ami.bp_fix - INFO - Identified 0 bad pixels (0.00%)
2026-04-15 20:14:50,714 - jwst.ami.bp_fix - INFO - 8.467
2026-04-15 20:14:50,714 - jwst.ami.bp_fix - INFO - Iteration 1: 0 new bad pixels, sdev of norm noise = 1.411
2026-04-15 20:14:50,719 - jwst.ami.bp_fix - INFO - Frame 45 of 69
2026-04-15 20:14:50,726 - jwst.ami.bp_fix - INFO - Identified 0 bad pixels (0.00%)
2026-04-15 20:14:50,727 - jwst.ami.bp_fix - INFO - 11.723
2026-04-15 20:14:50,727 - jwst.ami.bp_fix - INFO - Iteration 1: 0 new bad pixels, sdev of norm noise = 1.392
2026-04-15 20:14:50,733 - jwst.ami.bp_fix - INFO - Frame 46 of 69
2026-04-15 20:14:50,739 - jwst.ami.bp_fix - INFO - Identified 0 bad pixels (0.00%)
2026-04-15 20:14:50,740 - jwst.ami.bp_fix - INFO - 8.934
2026-04-15 20:14:50,740 - jwst.ami.bp_fix - INFO - Iteration 1: 0 new bad pixels, sdev of norm noise = 1.417
2026-04-15 20:14:50,745 - jwst.ami.bp_fix - INFO - Frame 47 of 69
2026-04-15 20:14:50,752 - jwst.ami.bp_fix - INFO - Identified 0 bad pixels (0.00%)
2026-04-15 20:14:50,753 - jwst.ami.bp_fix - INFO - 10.026
2026-04-15 20:14:50,753 - jwst.ami.bp_fix - INFO - Iteration 1: 0 new bad pixels, sdev of norm noise = 1.407
2026-04-15 20:14:50,758 - jwst.ami.bp_fix - INFO - Frame 48 of 69
2026-04-15 20:14:50,765 - jwst.ami.bp_fix - INFO - Identified 0 bad pixels (0.00%)
2026-04-15 20:14:50,765 - jwst.ami.bp_fix - INFO - 10.768
2026-04-15 20:14:50,766 - jwst.ami.bp_fix - INFO - Iteration 1: 0 new bad pixels, sdev of norm noise = 1.394
2026-04-15 20:14:50,771 - jwst.ami.bp_fix - INFO - Frame 49 of 69
2026-04-15 20:14:50,777 - jwst.ami.bp_fix - INFO - Identified 0 bad pixels (0.00%)
2026-04-15 20:14:50,778 - jwst.ami.bp_fix - INFO - 8.079
2026-04-15 20:14:50,779 - jwst.ami.bp_fix - INFO - Iteration 1: 0 new bad pixels, sdev of norm noise = 1.461
2026-04-15 20:14:50,784 - jwst.ami.bp_fix - INFO - Frame 50 of 69
2026-04-15 20:14:50,790 - jwst.ami.bp_fix - INFO - Identified 0 bad pixels (0.00%)
2026-04-15 20:14:50,791 - jwst.ami.bp_fix - INFO - 10.683
2026-04-15 20:14:50,791 - jwst.ami.bp_fix - INFO - Iteration 1: 0 new bad pixels, sdev of norm noise = 1.415
2026-04-15 20:14:50,796 - jwst.ami.bp_fix - INFO - Frame 51 of 69
2026-04-15 20:14:50,803 - jwst.ami.bp_fix - INFO - Identified 0 bad pixels (0.00%)
2026-04-15 20:14:50,803 - jwst.ami.bp_fix - INFO - 11.176
2026-04-15 20:14:50,804 - jwst.ami.bp_fix - INFO - Iteration 1: 0 new bad pixels, sdev of norm noise = 1.400
2026-04-15 20:14:50,809 - jwst.ami.bp_fix - INFO - Frame 52 of 69
2026-04-15 20:14:50,815 - jwst.ami.bp_fix - INFO - Identified 0 bad pixels (0.00%)
2026-04-15 20:14:50,816 - jwst.ami.bp_fix - INFO - 10.702
2026-04-15 20:14:50,817 - jwst.ami.bp_fix - INFO - Iteration 1: 0 new bad pixels, sdev of norm noise = 1.384
2026-04-15 20:14:50,822 - jwst.ami.bp_fix - INFO - Frame 53 of 69
2026-04-15 20:14:50,828 - jwst.ami.bp_fix - INFO - Identified 0 bad pixels (0.00%)
2026-04-15 20:14:50,829 - jwst.ami.bp_fix - INFO - 11.950
2026-04-15 20:14:50,829 - jwst.ami.bp_fix - INFO - Iteration 1: 0 new bad pixels, sdev of norm noise = 1.369
2026-04-15 20:14:50,834 - jwst.ami.bp_fix - INFO - Frame 54 of 69
2026-04-15 20:14:50,841 - jwst.ami.bp_fix - INFO - Identified 0 bad pixels (0.00%)
2026-04-15 20:14:50,841 - jwst.ami.bp_fix - INFO - 7.721
2026-04-15 20:14:50,842 - jwst.ami.bp_fix - INFO - Iteration 1: 0 new bad pixels, sdev of norm noise = 1.439
2026-04-15 20:14:50,847 - jwst.ami.bp_fix - INFO - Frame 55 of 69
2026-04-15 20:14:50,853 - jwst.ami.bp_fix - INFO - Identified 0 bad pixels (0.00%)
2026-04-15 20:14:50,854 - jwst.ami.bp_fix - INFO - 7.191
2026-04-15 20:14:50,855 - jwst.ami.bp_fix - INFO - Iteration 1: 0 new bad pixels, sdev of norm noise = 1.415
2026-04-15 20:14:50,860 - jwst.ami.bp_fix - INFO - Frame 56 of 69
2026-04-15 20:14:50,866 - jwst.ami.bp_fix - INFO - Identified 0 bad pixels (0.00%)
2026-04-15 20:14:50,867 - jwst.ami.bp_fix - INFO - 10.088
2026-04-15 20:14:50,867 - jwst.ami.bp_fix - INFO - Iteration 1: 0 new bad pixels, sdev of norm noise = 1.444
2026-04-15 20:14:50,872 - jwst.ami.bp_fix - INFO - Frame 57 of 69
2026-04-15 20:14:50,879 - jwst.ami.bp_fix - INFO - Identified 0 bad pixels (0.00%)
2026-04-15 20:14:50,879 - jwst.ami.bp_fix - INFO - 9.143
2026-04-15 20:14:50,880 - jwst.ami.bp_fix - INFO - Iteration 1: 0 new bad pixels, sdev of norm noise = 1.399
2026-04-15 20:14:50,885 - jwst.ami.bp_fix - INFO - Frame 58 of 69
2026-04-15 20:14:50,891 - jwst.ami.bp_fix - INFO - Identified 0 bad pixels (0.00%)
2026-04-15 20:14:50,892 - jwst.ami.bp_fix - INFO - 11.554
2026-04-15 20:14:50,893 - jwst.ami.bp_fix - INFO - Iteration 1: 0 new bad pixels, sdev of norm noise = 1.424
2026-04-15 20:14:50,898 - jwst.ami.bp_fix - INFO - Frame 59 of 69
2026-04-15 20:14:50,904 - jwst.ami.bp_fix - INFO - Identified 0 bad pixels (0.00%)
2026-04-15 20:14:50,905 - jwst.ami.bp_fix - INFO - 7.861
2026-04-15 20:14:50,905 - jwst.ami.bp_fix - INFO - Iteration 1: 0 new bad pixels, sdev of norm noise = 1.399
2026-04-15 20:14:50,910 - jwst.ami.bp_fix - INFO - Frame 60 of 69
2026-04-15 20:14:50,917 - jwst.ami.bp_fix - INFO - Identified 0 bad pixels (0.00%)
2026-04-15 20:14:50,917 - jwst.ami.bp_fix - INFO - 12.362
2026-04-15 20:14:50,918 - jwst.ami.bp_fix - INFO - Iteration 1: 0 new bad pixels, sdev of norm noise = 1.394
2026-04-15 20:14:50,923 - jwst.ami.bp_fix - INFO - Frame 61 of 69
2026-04-15 20:14:50,929 - jwst.ami.bp_fix - INFO - Identified 0 bad pixels (0.00%)
2026-04-15 20:14:50,930 - jwst.ami.bp_fix - INFO - 7.923
2026-04-15 20:14:50,931 - jwst.ami.bp_fix - INFO - Iteration 1: 0 new bad pixels, sdev of norm noise = 1.380
2026-04-15 20:14:50,936 - jwst.ami.bp_fix - INFO - Frame 62 of 69
2026-04-15 20:14:50,942 - jwst.ami.bp_fix - INFO - Identified 0 bad pixels (0.00%)
2026-04-15 20:14:50,943 - jwst.ami.bp_fix - INFO - 10.594
2026-04-15 20:14:50,944 - jwst.ami.bp_fix - INFO - Iteration 1: 0 new bad pixels, sdev of norm noise = 1.403
2026-04-15 20:14:50,949 - jwst.ami.bp_fix - INFO - Frame 63 of 69
2026-04-15 20:14:50,955 - jwst.ami.bp_fix - INFO - Identified 0 bad pixels (0.00%)
2026-04-15 20:14:50,956 - jwst.ami.bp_fix - INFO - 10.089
2026-04-15 20:14:50,956 - jwst.ami.bp_fix - INFO - Iteration 1: 0 new bad pixels, sdev of norm noise = 1.424
2026-04-15 20:14:50,961 - jwst.ami.bp_fix - INFO - Frame 64 of 69
2026-04-15 20:14:50,968 - jwst.ami.bp_fix - INFO - Identified 0 bad pixels (0.00%)
2026-04-15 20:14:50,968 - jwst.ami.bp_fix - INFO - 9.734
2026-04-15 20:14:50,969 - jwst.ami.bp_fix - INFO - Iteration 1: 0 new bad pixels, sdev of norm noise = 1.411
2026-04-15 20:14:50,974 - jwst.ami.bp_fix - INFO - Frame 65 of 69
2026-04-15 20:14:50,980 - jwst.ami.bp_fix - INFO - Identified 0 bad pixels (0.00%)
2026-04-15 20:14:50,981 - jwst.ami.bp_fix - INFO - 11.395
2026-04-15 20:14:50,982 - jwst.ami.bp_fix - INFO - Iteration 1: 0 new bad pixels, sdev of norm noise = 1.429
2026-04-15 20:14:50,986 - jwst.ami.bp_fix - INFO - Frame 66 of 69
2026-04-15 20:14:50,993 - jwst.ami.bp_fix - INFO - Identified 0 bad pixels (0.00%)
2026-04-15 20:14:50,994 - jwst.ami.bp_fix - INFO - 9.381
2026-04-15 20:14:50,994 - jwst.ami.bp_fix - INFO - Iteration 1: 0 new bad pixels, sdev of norm noise = 1.397
2026-04-15 20:14:50,999 - jwst.ami.bp_fix - INFO - Frame 67 of 69
2026-04-15 20:14:51,006 - jwst.ami.bp_fix - INFO - Identified 0 bad pixels (0.00%)
2026-04-15 20:14:51,007 - jwst.ami.bp_fix - INFO - 8.719
2026-04-15 20:14:51,007 - jwst.ami.bp_fix - INFO - Iteration 1: 0 new bad pixels, sdev of norm noise = 1.425
2026-04-15 20:14:51,012 - jwst.ami.bp_fix - INFO - Frame 68 of 69
2026-04-15 20:14:51,019 - jwst.ami.bp_fix - INFO - Identified 0 bad pixels (0.00%)
2026-04-15 20:14:51,019 - jwst.ami.bp_fix - INFO - 9.895
2026-04-15 20:14:51,020 - jwst.ami.bp_fix - INFO - Iteration 1: 0 new bad pixels, sdev of norm noise = 1.387
2026-04-15 20:14:51,025 - jwst.ami.bp_fix - INFO - Frame 69 of 69
2026-04-15 20:14:51,032 - jwst.ami.bp_fix - INFO - Identified 0 bad pixels (0.00%)
2026-04-15 20:14:51,032 - jwst.ami.bp_fix - INFO - 9.363
2026-04-15 20:14:51,033 - jwst.ami.bp_fix - INFO - Iteration 1: 0 new bad pixels, sdev of norm noise = 1.398
2026-04-15 20:14:51,038 - jwst.ami.instrument_data - INFO - usebp flag set to TRUE: bad pixels will be excluded from model fit
2026-04-15 20:14:51,040 - jwst.ami.nrm_core - INFO - Fitting fringes for iteration 0 of 69
2026-04-15 20:14:52,106 - jwst.ami.leastsqnrm - INFO - fringefitting.leastsqnrm.matrix_operations():
2026-04-15 20:14:52,107 - jwst.ami.leastsqnrm - INFO - img (69, 69)
2026-04-15 20:14:52,107 - jwst.ami.leastsqnrm - INFO - L x W = 69 x 69 = 4761
2026-04-15 20:14:52,108 - jwst.ami.leastsqnrm - INFO - flatimg (4761,)
2026-04-15 20:14:52,108 - jwst.ami.leastsqnrm - INFO -
2026-04-15 20:14:52,108 - jwst.ami.leastsqnrm - INFO - type(dqm) <class 'numpy.ndarray'>
2026-04-15 20:14:52,109 - jwst.ami.leastsqnrm - INFO - type(nanlist) <class 'tuple'>, len=1
2026-04-15 20:14:52,110 - jwst.ami.leastsqnrm - INFO - number of nanlist pixels: 37 items
2026-04-15 20:14:52,110 - jwst.ami.leastsqnrm - INFO - 37 DO_NOT_USE pixels found in data slice
2026-04-15 20:14:52,111 - jwst.ami.leastsqnrm - INFO - flatimg (4724,) after deleting 37
2026-04-15 20:14:52,112 - jwst.ami.leastsqnrm - INFO - flatmodel_nan (4761, 44)
2026-04-15 20:14:52,112 - jwst.ami.leastsqnrm - INFO - flatmodel (4724, 44)
2026-04-15 20:14:52,112 - jwst.ami.leastsqnrm - INFO - difference 37
2026-04-15 20:14:52,113 - jwst.ami.leastsqnrm - INFO - flat model dimensions (4724, 44)
2026-04-15 20:14:52,113 - jwst.ami.leastsqnrm - INFO - flat image dimensions (4724,)
2026-04-15 20:14:52,116 - jwst.ami.leastsqnrm - INFO - data flux 2.7496585e+06
2026-04-15 20:14:52,117 - jwst.ami.leastsqnrm - INFO - flat model dimensions (4724, 44)
2026-04-15 20:14:52,117 - jwst.ami.leastsqnrm - INFO - model transpose dimensions (44, 4724)
2026-04-15 20:14:52,118 - jwst.ami.leastsqnrm - INFO - flat image dimensions (4724,)
2026-04-15 20:14:52,118 - jwst.ami.leastsqnrm - INFO - transpose * image data dimensions (44,)
2026-04-15 20:14:52,118 - jwst.ami.leastsqnrm - INFO - flat img * transpose dimensions (44, 44)
2026-04-15 20:14:52,119 - jwst.ami.leastsqnrm - INFO - linearfit not attempted, no covariances saved.
2026-04-15 20:14:52,121 - jwst.ami.nrm_core - INFO - Fitting fringes for iteration 1 of 69
2026-04-15 20:14:53,186 - jwst.ami.leastsqnrm - INFO - fringefitting.leastsqnrm.matrix_operations():
2026-04-15 20:14:53,187 - jwst.ami.leastsqnrm - INFO - img (69, 69)
2026-04-15 20:14:53,188 - jwst.ami.leastsqnrm - INFO - L x W = 69 x 69 = 4761
2026-04-15 20:14:53,188 - jwst.ami.leastsqnrm - INFO - flatimg (4761,)
2026-04-15 20:14:53,189 - jwst.ami.leastsqnrm - INFO -
2026-04-15 20:14:53,189 - jwst.ami.leastsqnrm - INFO - type(dqm) <class 'numpy.ndarray'>
2026-04-15 20:14:53,189 - jwst.ami.leastsqnrm - INFO - type(nanlist) <class 'tuple'>, len=1
2026-04-15 20:14:53,190 - jwst.ami.leastsqnrm - INFO - number of nanlist pixels: 36 items
2026-04-15 20:14:53,190 - jwst.ami.leastsqnrm - INFO - 36 DO_NOT_USE pixels found in data slice
2026-04-15 20:14:53,191 - jwst.ami.leastsqnrm - INFO - flatimg (4725,) after deleting 36
2026-04-15 20:14:53,192 - jwst.ami.leastsqnrm - INFO - flatmodel_nan (4761, 44)
2026-04-15 20:14:53,192 - jwst.ami.leastsqnrm - INFO - flatmodel (4725, 44)
2026-04-15 20:14:53,193 - jwst.ami.leastsqnrm - INFO - difference 36
2026-04-15 20:14:53,193 - jwst.ami.leastsqnrm - INFO - flat model dimensions (4725, 44)
2026-04-15 20:14:53,193 - jwst.ami.leastsqnrm - INFO - flat image dimensions (4725,)
2026-04-15 20:14:53,196 - jwst.ami.leastsqnrm - INFO - data flux 2.7338485e+06
2026-04-15 20:14:53,196 - jwst.ami.leastsqnrm - INFO - flat model dimensions (4725, 44)
2026-04-15 20:14:53,197 - jwst.ami.leastsqnrm - INFO - model transpose dimensions (44, 4725)
2026-04-15 20:14:53,197 - jwst.ami.leastsqnrm - INFO - flat image dimensions (4725,)
2026-04-15 20:14:53,197 - jwst.ami.leastsqnrm - INFO - transpose * image data dimensions (44,)
2026-04-15 20:14:53,198 - jwst.ami.leastsqnrm - INFO - flat img * transpose dimensions (44, 44)
2026-04-15 20:14:53,198 - jwst.ami.leastsqnrm - INFO - linearfit not attempted, no covariances saved.
2026-04-15 20:14:53,200 - jwst.ami.nrm_core - INFO - Fitting fringes for iteration 2 of 69
2026-04-15 20:14:54,271 - jwst.ami.leastsqnrm - INFO - fringefitting.leastsqnrm.matrix_operations():
2026-04-15 20:14:54,272 - jwst.ami.leastsqnrm - INFO - img (69, 69)
2026-04-15 20:14:54,272 - jwst.ami.leastsqnrm - INFO - L x W = 69 x 69 = 4761
2026-04-15 20:14:54,273 - jwst.ami.leastsqnrm - INFO - flatimg (4761,)
2026-04-15 20:14:54,273 - jwst.ami.leastsqnrm - INFO -
2026-04-15 20:14:54,273 - jwst.ami.leastsqnrm - INFO - type(dqm) <class 'numpy.ndarray'>
2026-04-15 20:14:54,274 - jwst.ami.leastsqnrm - INFO - type(nanlist) <class 'tuple'>, len=1
2026-04-15 20:14:54,274 - jwst.ami.leastsqnrm - INFO - number of nanlist pixels: 36 items
2026-04-15 20:14:54,275 - jwst.ami.leastsqnrm - INFO - 36 DO_NOT_USE pixels found in data slice
2026-04-15 20:14:54,275 - jwst.ami.leastsqnrm - INFO - flatimg (4725,) after deleting 36
2026-04-15 20:14:54,276 - jwst.ami.leastsqnrm - INFO - flatmodel_nan (4761, 44)
2026-04-15 20:14:54,277 - jwst.ami.leastsqnrm - INFO - flatmodel (4725, 44)
2026-04-15 20:14:54,277 - jwst.ami.leastsqnrm - INFO - difference 36
2026-04-15 20:14:54,277 - jwst.ami.leastsqnrm - INFO - flat model dimensions (4725, 44)
2026-04-15 20:14:54,278 - jwst.ami.leastsqnrm - INFO - flat image dimensions (4725,)
2026-04-15 20:14:54,280 - jwst.ami.leastsqnrm - INFO - data flux 2.753694e+06
2026-04-15 20:14:54,281 - jwst.ami.leastsqnrm - INFO - flat model dimensions (4725, 44)
2026-04-15 20:14:54,281 - jwst.ami.leastsqnrm - INFO - model transpose dimensions (44, 4725)
2026-04-15 20:14:54,282 - jwst.ami.leastsqnrm - INFO - flat image dimensions (4725,)
2026-04-15 20:14:54,282 - jwst.ami.leastsqnrm - INFO - transpose * image data dimensions (44,)
2026-04-15 20:14:54,282 - jwst.ami.leastsqnrm - INFO - flat img * transpose dimensions (44, 44)
2026-04-15 20:14:54,283 - jwst.ami.leastsqnrm - INFO - linearfit not attempted, no covariances saved.
2026-04-15 20:14:54,285 - jwst.ami.nrm_core - INFO - Fitting fringes for iteration 3 of 69
2026-04-15 20:14:55,351 - jwst.ami.leastsqnrm - INFO - fringefitting.leastsqnrm.matrix_operations():
2026-04-15 20:14:55,351 - jwst.ami.leastsqnrm - INFO - img (69, 69)
2026-04-15 20:14:55,352 - jwst.ami.leastsqnrm - INFO - L x W = 69 x 69 = 4761
2026-04-15 20:14:55,352 - jwst.ami.leastsqnrm - INFO - flatimg (4761,)
2026-04-15 20:14:55,353 - jwst.ami.leastsqnrm - INFO -
2026-04-15 20:14:55,353 - jwst.ami.leastsqnrm - INFO - type(dqm) <class 'numpy.ndarray'>
2026-04-15 20:14:55,354 - jwst.ami.leastsqnrm - INFO - type(nanlist) <class 'tuple'>, len=1
2026-04-15 20:14:55,354 - jwst.ami.leastsqnrm - INFO - number of nanlist pixels: 36 items
2026-04-15 20:14:55,355 - jwst.ami.leastsqnrm - INFO - 36 DO_NOT_USE pixels found in data slice
2026-04-15 20:14:55,355 - jwst.ami.leastsqnrm - INFO - flatimg (4725,) after deleting 36
2026-04-15 20:14:55,356 - jwst.ami.leastsqnrm - INFO - flatmodel_nan (4761, 44)
2026-04-15 20:14:55,356 - jwst.ami.leastsqnrm - INFO - flatmodel (4725, 44)
2026-04-15 20:14:55,357 - jwst.ami.leastsqnrm - INFO - difference 36
2026-04-15 20:14:55,357 - jwst.ami.leastsqnrm - INFO - flat model dimensions (4725, 44)
2026-04-15 20:14:55,358 - jwst.ami.leastsqnrm - INFO - flat image dimensions (4725,)
2026-04-15 20:14:55,360 - jwst.ami.leastsqnrm - INFO - data flux 2.7543598e+06
2026-04-15 20:14:55,361 - jwst.ami.leastsqnrm - INFO - flat model dimensions (4725, 44)
2026-04-15 20:14:55,361 - jwst.ami.leastsqnrm - INFO - model transpose dimensions (44, 4725)
2026-04-15 20:14:55,362 - jwst.ami.leastsqnrm - INFO - flat image dimensions (4725,)
2026-04-15 20:14:55,362 - jwst.ami.leastsqnrm - INFO - transpose * image data dimensions (44,)
2026-04-15 20:14:55,362 - jwst.ami.leastsqnrm - INFO - flat img * transpose dimensions (44, 44)
2026-04-15 20:14:55,363 - jwst.ami.leastsqnrm - INFO - linearfit not attempted, no covariances saved.
2026-04-15 20:14:55,364 - jwst.ami.nrm_core - INFO - Fitting fringes for iteration 4 of 69
2026-04-15 20:14:56,426 - jwst.ami.leastsqnrm - INFO - fringefitting.leastsqnrm.matrix_operations():
2026-04-15 20:14:56,426 - jwst.ami.leastsqnrm - INFO - img (69, 69)
2026-04-15 20:14:56,427 - jwst.ami.leastsqnrm - INFO - L x W = 69 x 69 = 4761
2026-04-15 20:14:56,427 - jwst.ami.leastsqnrm - INFO - flatimg (4761,)
2026-04-15 20:14:56,428 - jwst.ami.leastsqnrm - INFO -
2026-04-15 20:14:56,428 - jwst.ami.leastsqnrm - INFO - type(dqm) <class 'numpy.ndarray'>
2026-04-15 20:14:56,429 - jwst.ami.leastsqnrm - INFO - type(nanlist) <class 'tuple'>, len=1
2026-04-15 20:14:56,429 - jwst.ami.leastsqnrm - INFO - number of nanlist pixels: 37 items
2026-04-15 20:14:56,429 - jwst.ami.leastsqnrm - INFO - 37 DO_NOT_USE pixels found in data slice
2026-04-15 20:14:56,430 - jwst.ami.leastsqnrm - INFO - flatimg (4724,) after deleting 37
2026-04-15 20:14:56,431 - jwst.ami.leastsqnrm - INFO - flatmodel_nan (4761, 44)
2026-04-15 20:14:56,431 - jwst.ami.leastsqnrm - INFO - flatmodel (4724, 44)
2026-04-15 20:14:56,432 - jwst.ami.leastsqnrm - INFO - difference 37
2026-04-15 20:14:56,432 - jwst.ami.leastsqnrm - INFO - flat model dimensions (4724, 44)
2026-04-15 20:14:56,433 - jwst.ami.leastsqnrm - INFO - flat image dimensions (4724,)
2026-04-15 20:14:56,435 - jwst.ami.leastsqnrm - INFO - data flux 2.745931e+06
2026-04-15 20:14:56,435 - jwst.ami.leastsqnrm - INFO - flat model dimensions (4724, 44)
2026-04-15 20:14:56,436 - jwst.ami.leastsqnrm - INFO - model transpose dimensions (44, 4724)
2026-04-15 20:14:56,436 - jwst.ami.leastsqnrm - INFO - flat image dimensions (4724,)
2026-04-15 20:14:56,437 - jwst.ami.leastsqnrm - INFO - transpose * image data dimensions (44,)
2026-04-15 20:14:56,437 - jwst.ami.leastsqnrm - INFO - flat img * transpose dimensions (44, 44)
2026-04-15 20:14:56,438 - jwst.ami.leastsqnrm - INFO - linearfit not attempted, no covariances saved.
2026-04-15 20:14:56,439 - jwst.ami.nrm_core - INFO - Fitting fringes for iteration 5 of 69
2026-04-15 20:14:57,504 - jwst.ami.leastsqnrm - INFO - fringefitting.leastsqnrm.matrix_operations():
2026-04-15 20:14:57,505 - jwst.ami.leastsqnrm - INFO - img (69, 69)
2026-04-15 20:14:57,505 - jwst.ami.leastsqnrm - INFO - L x W = 69 x 69 = 4761
2026-04-15 20:14:57,506 - jwst.ami.leastsqnrm - INFO - flatimg (4761,)
2026-04-15 20:14:57,506 - jwst.ami.leastsqnrm - INFO -
2026-04-15 20:14:57,507 - jwst.ami.leastsqnrm - INFO - type(dqm) <class 'numpy.ndarray'>
2026-04-15 20:14:57,507 - jwst.ami.leastsqnrm - INFO - type(nanlist) <class 'tuple'>, len=1
2026-04-15 20:14:57,508 - jwst.ami.leastsqnrm - INFO - number of nanlist pixels: 37 items
2026-04-15 20:14:57,508 - jwst.ami.leastsqnrm - INFO - 37 DO_NOT_USE pixels found in data slice
2026-04-15 20:14:57,509 - jwst.ami.leastsqnrm - INFO - flatimg (4724,) after deleting 37
2026-04-15 20:14:57,509 - jwst.ami.leastsqnrm - INFO - flatmodel_nan (4761, 44)
2026-04-15 20:14:57,510 - jwst.ami.leastsqnrm - INFO - flatmodel (4724, 44)
2026-04-15 20:14:57,510 - jwst.ami.leastsqnrm - INFO - difference 37
2026-04-15 20:14:57,511 - jwst.ami.leastsqnrm - INFO - flat model dimensions (4724, 44)
2026-04-15 20:14:57,511 - jwst.ami.leastsqnrm - INFO - flat image dimensions (4724,)
2026-04-15 20:14:57,513 - jwst.ami.leastsqnrm - INFO - data flux 2.7196975e+06
2026-04-15 20:14:57,514 - jwst.ami.leastsqnrm - INFO - flat model dimensions (4724, 44)
2026-04-15 20:14:57,514 - jwst.ami.leastsqnrm - INFO - model transpose dimensions (44, 4724)
2026-04-15 20:14:57,515 - jwst.ami.leastsqnrm - INFO - flat image dimensions (4724,)
2026-04-15 20:14:57,515 - jwst.ami.leastsqnrm - INFO - transpose * image data dimensions (44,)
2026-04-15 20:14:57,516 - jwst.ami.leastsqnrm - INFO - flat img * transpose dimensions (44, 44)
2026-04-15 20:14:57,516 - jwst.ami.leastsqnrm - INFO - linearfit not attempted, no covariances saved.
2026-04-15 20:14:57,518 - jwst.ami.nrm_core - INFO - Fitting fringes for iteration 6 of 69
2026-04-15 20:14:58,586 - jwst.ami.leastsqnrm - INFO - fringefitting.leastsqnrm.matrix_operations():
2026-04-15 20:14:58,587 - jwst.ami.leastsqnrm - INFO - img (69, 69)
2026-04-15 20:14:58,588 - jwst.ami.leastsqnrm - INFO - L x W = 69 x 69 = 4761
2026-04-15 20:14:58,588 - jwst.ami.leastsqnrm - INFO - flatimg (4761,)
2026-04-15 20:14:58,589 - jwst.ami.leastsqnrm - INFO -
2026-04-15 20:14:58,589 - jwst.ami.leastsqnrm - INFO - type(dqm) <class 'numpy.ndarray'>
2026-04-15 20:14:58,589 - jwst.ami.leastsqnrm - INFO - type(nanlist) <class 'tuple'>, len=1
2026-04-15 20:14:58,590 - jwst.ami.leastsqnrm - INFO - number of nanlist pixels: 37 items
2026-04-15 20:14:58,590 - jwst.ami.leastsqnrm - INFO - 37 DO_NOT_USE pixels found in data slice
2026-04-15 20:14:58,591 - jwst.ami.leastsqnrm - INFO - flatimg (4724,) after deleting 37
2026-04-15 20:14:58,591 - jwst.ami.leastsqnrm - INFO - flatmodel_nan (4761, 44)
2026-04-15 20:14:58,592 - jwst.ami.leastsqnrm - INFO - flatmodel (4724, 44)
2026-04-15 20:14:58,592 - jwst.ami.leastsqnrm - INFO - difference 37
2026-04-15 20:14:58,593 - jwst.ami.leastsqnrm - INFO - flat model dimensions (4724, 44)
2026-04-15 20:14:58,593 - jwst.ami.leastsqnrm - INFO - flat image dimensions (4724,)
2026-04-15 20:14:58,596 - jwst.ami.leastsqnrm - INFO - data flux 2.7419098e+06
2026-04-15 20:14:58,596 - jwst.ami.leastsqnrm - INFO - flat model dimensions (4724, 44)
2026-04-15 20:14:58,597 - jwst.ami.leastsqnrm - INFO - model transpose dimensions (44, 4724)
2026-04-15 20:14:58,597 - jwst.ami.leastsqnrm - INFO - flat image dimensions (4724,)
2026-04-15 20:14:58,597 - jwst.ami.leastsqnrm - INFO - transpose * image data dimensions (44,)
2026-04-15 20:14:58,598 - jwst.ami.leastsqnrm - INFO - flat img * transpose dimensions (44, 44)
2026-04-15 20:14:58,598 - jwst.ami.leastsqnrm - INFO - linearfit not attempted, no covariances saved.
2026-04-15 20:14:58,600 - jwst.ami.nrm_core - INFO - Fitting fringes for iteration 7 of 69
2026-04-15 20:14:59,663 - jwst.ami.leastsqnrm - INFO - fringefitting.leastsqnrm.matrix_operations():
2026-04-15 20:14:59,664 - jwst.ami.leastsqnrm - INFO - img (69, 69)
2026-04-15 20:14:59,664 - jwst.ami.leastsqnrm - INFO - L x W = 69 x 69 = 4761
2026-04-15 20:14:59,665 - jwst.ami.leastsqnrm - INFO - flatimg (4761,)
2026-04-15 20:14:59,665 - jwst.ami.leastsqnrm - INFO -
2026-04-15 20:14:59,665 - jwst.ami.leastsqnrm - INFO - type(dqm) <class 'numpy.ndarray'>
2026-04-15 20:14:59,666 - jwst.ami.leastsqnrm - INFO - type(nanlist) <class 'tuple'>, len=1
2026-04-15 20:14:59,666 - jwst.ami.leastsqnrm - INFO - number of nanlist pixels: 37 items
2026-04-15 20:14:59,667 - jwst.ami.leastsqnrm - INFO - 37 DO_NOT_USE pixels found in data slice
2026-04-15 20:14:59,667 - jwst.ami.leastsqnrm - INFO - flatimg (4724,) after deleting 37
2026-04-15 20:14:59,668 - jwst.ami.leastsqnrm - INFO - flatmodel_nan (4761, 44)
2026-04-15 20:14:59,669 - jwst.ami.leastsqnrm - INFO - flatmodel (4724, 44)
2026-04-15 20:14:59,669 - jwst.ami.leastsqnrm - INFO - difference 37
2026-04-15 20:14:59,669 - jwst.ami.leastsqnrm - INFO - flat model dimensions (4724, 44)
2026-04-15 20:14:59,670 - jwst.ami.leastsqnrm - INFO - flat image dimensions (4724,)
2026-04-15 20:14:59,673 - jwst.ami.leastsqnrm - INFO - data flux 2.749396e+06
2026-04-15 20:14:59,673 - jwst.ami.leastsqnrm - INFO - flat model dimensions (4724, 44)
2026-04-15 20:14:59,673 - jwst.ami.leastsqnrm - INFO - model transpose dimensions (44, 4724)
2026-04-15 20:14:59,674 - jwst.ami.leastsqnrm - INFO - flat image dimensions (4724,)
2026-04-15 20:14:59,674 - jwst.ami.leastsqnrm - INFO - transpose * image data dimensions (44,)
2026-04-15 20:14:59,675 - jwst.ami.leastsqnrm - INFO - flat img * transpose dimensions (44, 44)
2026-04-15 20:14:59,675 - jwst.ami.leastsqnrm - INFO - linearfit not attempted, no covariances saved.
2026-04-15 20:14:59,677 - jwst.ami.nrm_core - INFO - Fitting fringes for iteration 8 of 69
2026-04-15 20:15:00,746 - jwst.ami.leastsqnrm - INFO - fringefitting.leastsqnrm.matrix_operations():
2026-04-15 20:15:00,747 - jwst.ami.leastsqnrm - INFO - img (69, 69)
2026-04-15 20:15:00,747 - jwst.ami.leastsqnrm - INFO - L x W = 69 x 69 = 4761
2026-04-15 20:15:00,748 - jwst.ami.leastsqnrm - INFO - flatimg (4761,)
2026-04-15 20:15:00,748 - jwst.ami.leastsqnrm - INFO -
2026-04-15 20:15:00,749 - jwst.ami.leastsqnrm - INFO - type(dqm) <class 'numpy.ndarray'>
2026-04-15 20:15:00,749 - jwst.ami.leastsqnrm - INFO - type(nanlist) <class 'tuple'>, len=1
2026-04-15 20:15:00,750 - jwst.ami.leastsqnrm - INFO - number of nanlist pixels: 39 items
2026-04-15 20:15:00,750 - jwst.ami.leastsqnrm - INFO - 39 DO_NOT_USE pixels found in data slice
2026-04-15 20:15:00,751 - jwst.ami.leastsqnrm - INFO - flatimg (4722,) after deleting 39
2026-04-15 20:15:00,751 - jwst.ami.leastsqnrm - INFO - flatmodel_nan (4761, 44)
2026-04-15 20:15:00,751 - jwst.ami.leastsqnrm - INFO - flatmodel (4722, 44)
2026-04-15 20:15:00,752 - jwst.ami.leastsqnrm - INFO - difference 39
2026-04-15 20:15:00,752 - jwst.ami.leastsqnrm - INFO - flat model dimensions (4722, 44)
2026-04-15 20:15:00,753 - jwst.ami.leastsqnrm - INFO - flat image dimensions (4722,)
2026-04-15 20:15:00,756 - jwst.ami.leastsqnrm - INFO - data flux 2.7422292e+06
2026-04-15 20:15:00,756 - jwst.ami.leastsqnrm - INFO - flat model dimensions (4722, 44)
2026-04-15 20:15:00,757 - jwst.ami.leastsqnrm - INFO - model transpose dimensions (44, 4722)
2026-04-15 20:15:00,757 - jwst.ami.leastsqnrm - INFO - flat image dimensions (4722,)
2026-04-15 20:15:00,758 - jwst.ami.leastsqnrm - INFO - transpose * image data dimensions (44,)
2026-04-15 20:15:00,758 - jwst.ami.leastsqnrm - INFO - flat img * transpose dimensions (44, 44)
2026-04-15 20:15:00,758 - jwst.ami.leastsqnrm - INFO - linearfit not attempted, no covariances saved.
2026-04-15 20:15:00,760 - jwst.ami.nrm_core - INFO - Fitting fringes for iteration 9 of 69
2026-04-15 20:15:01,824 - jwst.ami.leastsqnrm - INFO - fringefitting.leastsqnrm.matrix_operations():
2026-04-15 20:15:01,825 - jwst.ami.leastsqnrm - INFO - img (69, 69)
2026-04-15 20:15:01,825 - jwst.ami.leastsqnrm - INFO - L x W = 69 x 69 = 4761
2026-04-15 20:15:01,826 - jwst.ami.leastsqnrm - INFO - flatimg (4761,)
2026-04-15 20:15:01,826 - jwst.ami.leastsqnrm - INFO -
2026-04-15 20:15:01,827 - jwst.ami.leastsqnrm - INFO - type(dqm) <class 'numpy.ndarray'>
2026-04-15 20:15:01,827 - jwst.ami.leastsqnrm - INFO - type(nanlist) <class 'tuple'>, len=1
2026-04-15 20:15:01,828 - jwst.ami.leastsqnrm - INFO - number of nanlist pixels: 36 items
2026-04-15 20:15:01,828 - jwst.ami.leastsqnrm - INFO - 36 DO_NOT_USE pixels found in data slice
2026-04-15 20:15:01,829 - jwst.ami.leastsqnrm - INFO - flatimg (4725,) after deleting 36
2026-04-15 20:15:01,829 - jwst.ami.leastsqnrm - INFO - flatmodel_nan (4761, 44)
2026-04-15 20:15:01,830 - jwst.ami.leastsqnrm - INFO - flatmodel (4725, 44)
2026-04-15 20:15:01,830 - jwst.ami.leastsqnrm - INFO - difference 36
2026-04-15 20:15:01,831 - jwst.ami.leastsqnrm - INFO - flat model dimensions (4725, 44)
2026-04-15 20:15:01,831 - jwst.ami.leastsqnrm - INFO - flat image dimensions (4725,)
2026-04-15 20:15:01,834 - jwst.ami.leastsqnrm - INFO - data flux 2.7339092e+06
2026-04-15 20:15:01,834 - jwst.ami.leastsqnrm - INFO - flat model dimensions (4725, 44)
2026-04-15 20:15:01,835 - jwst.ami.leastsqnrm - INFO - model transpose dimensions (44, 4725)
2026-04-15 20:15:01,835 - jwst.ami.leastsqnrm - INFO - flat image dimensions (4725,)
2026-04-15 20:15:01,836 - jwst.ami.leastsqnrm - INFO - transpose * image data dimensions (44,)
2026-04-15 20:15:01,836 - jwst.ami.leastsqnrm - INFO - flat img * transpose dimensions (44, 44)
2026-04-15 20:15:01,836 - jwst.ami.leastsqnrm - INFO - linearfit not attempted, no covariances saved.
2026-04-15 20:15:01,838 - jwst.ami.nrm_core - INFO - Fitting fringes for iteration 10 of 69
2026-04-15 20:15:02,903 - jwst.ami.leastsqnrm - INFO - fringefitting.leastsqnrm.matrix_operations():
2026-04-15 20:15:02,903 - jwst.ami.leastsqnrm - INFO - img (69, 69)
2026-04-15 20:15:02,904 - jwst.ami.leastsqnrm - INFO - L x W = 69 x 69 = 4761
2026-04-15 20:15:02,904 - jwst.ami.leastsqnrm - INFO - flatimg (4761,)
2026-04-15 20:15:02,905 - jwst.ami.leastsqnrm - INFO -
2026-04-15 20:15:02,905 - jwst.ami.leastsqnrm - INFO - type(dqm) <class 'numpy.ndarray'>
2026-04-15 20:15:02,906 - jwst.ami.leastsqnrm - INFO - type(nanlist) <class 'tuple'>, len=1
2026-04-15 20:15:02,906 - jwst.ami.leastsqnrm - INFO - number of nanlist pixels: 36 items
2026-04-15 20:15:02,907 - jwst.ami.leastsqnrm - INFO - 36 DO_NOT_USE pixels found in data slice
2026-04-15 20:15:02,907 - jwst.ami.leastsqnrm - INFO - flatimg (4725,) after deleting 36
2026-04-15 20:15:02,908 - jwst.ami.leastsqnrm - INFO - flatmodel_nan (4761, 44)
2026-04-15 20:15:02,908 - jwst.ami.leastsqnrm - INFO - flatmodel (4725, 44)
2026-04-15 20:15:02,909 - jwst.ami.leastsqnrm - INFO - difference 36
2026-04-15 20:15:02,909 - jwst.ami.leastsqnrm - INFO - flat model dimensions (4725, 44)
2026-04-15 20:15:02,910 - jwst.ami.leastsqnrm - INFO - flat image dimensions (4725,)
2026-04-15 20:15:02,912 - jwst.ami.leastsqnrm - INFO - data flux 2.787834e+06
2026-04-15 20:15:02,912 - jwst.ami.leastsqnrm - INFO - flat model dimensions (4725, 44)
2026-04-15 20:15:02,913 - jwst.ami.leastsqnrm - INFO - model transpose dimensions (44, 4725)
2026-04-15 20:15:02,913 - jwst.ami.leastsqnrm - INFO - flat image dimensions (4725,)
2026-04-15 20:15:02,914 - jwst.ami.leastsqnrm - INFO - transpose * image data dimensions (44,)
2026-04-15 20:15:02,914 - jwst.ami.leastsqnrm - INFO - flat img * transpose dimensions (44, 44)
2026-04-15 20:15:02,915 - jwst.ami.leastsqnrm - INFO - linearfit not attempted, no covariances saved.
2026-04-15 20:15:02,916 - jwst.ami.nrm_core - INFO - Fitting fringes for iteration 11 of 69
2026-04-15 20:15:03,980 - jwst.ami.leastsqnrm - INFO - fringefitting.leastsqnrm.matrix_operations():
2026-04-15 20:15:03,980 - jwst.ami.leastsqnrm - INFO - img (69, 69)
2026-04-15 20:15:03,981 - jwst.ami.leastsqnrm - INFO - L x W = 69 x 69 = 4761
2026-04-15 20:15:03,981 - jwst.ami.leastsqnrm - INFO - flatimg (4761,)
2026-04-15 20:15:03,982 - jwst.ami.leastsqnrm - INFO -
2026-04-15 20:15:03,982 - jwst.ami.leastsqnrm - INFO - type(dqm) <class 'numpy.ndarray'>
2026-04-15 20:15:03,983 - jwst.ami.leastsqnrm - INFO - type(nanlist) <class 'tuple'>, len=1
2026-04-15 20:15:03,983 - jwst.ami.leastsqnrm - INFO - number of nanlist pixels: 39 items
2026-04-15 20:15:03,983 - jwst.ami.leastsqnrm - INFO - 39 DO_NOT_USE pixels found in data slice
2026-04-15 20:15:03,984 - jwst.ami.leastsqnrm - INFO - flatimg (4722,) after deleting 39
2026-04-15 20:15:03,985 - jwst.ami.leastsqnrm - INFO - flatmodel_nan (4761, 44)
2026-04-15 20:15:03,985 - jwst.ami.leastsqnrm - INFO - flatmodel (4722, 44)
2026-04-15 20:15:03,986 - jwst.ami.leastsqnrm - INFO - difference 39
2026-04-15 20:15:03,986 - jwst.ami.leastsqnrm - INFO - flat model dimensions (4722, 44)
2026-04-15 20:15:03,987 - jwst.ami.leastsqnrm - INFO - flat image dimensions (4722,)
2026-04-15 20:15:03,989 - jwst.ami.leastsqnrm - INFO - data flux 2.682108e+06
2026-04-15 20:15:03,990 - jwst.ami.leastsqnrm - INFO - flat model dimensions (4722, 44)
2026-04-15 20:15:03,990 - jwst.ami.leastsqnrm - INFO - model transpose dimensions (44, 4722)
2026-04-15 20:15:03,990 - jwst.ami.leastsqnrm - INFO - flat image dimensions (4722,)
2026-04-15 20:15:03,991 - jwst.ami.leastsqnrm - INFO - transpose * image data dimensions (44,)
2026-04-15 20:15:03,991 - jwst.ami.leastsqnrm - INFO - flat img * transpose dimensions (44, 44)
2026-04-15 20:15:03,992 - jwst.ami.leastsqnrm - INFO - linearfit not attempted, no covariances saved.
2026-04-15 20:15:03,993 - jwst.ami.nrm_core - INFO - Fitting fringes for iteration 12 of 69
2026-04-15 20:15:05,056 - jwst.ami.leastsqnrm - INFO - fringefitting.leastsqnrm.matrix_operations():
2026-04-15 20:15:05,057 - jwst.ami.leastsqnrm - INFO - img (69, 69)
2026-04-15 20:15:05,057 - jwst.ami.leastsqnrm - INFO - L x W = 69 x 69 = 4761
2026-04-15 20:15:05,058 - jwst.ami.leastsqnrm - INFO - flatimg (4761,)
2026-04-15 20:15:05,058 - jwst.ami.leastsqnrm - INFO -
2026-04-15 20:15:05,059 - jwst.ami.leastsqnrm - INFO - type(dqm) <class 'numpy.ndarray'>
2026-04-15 20:15:05,059 - jwst.ami.leastsqnrm - INFO - type(nanlist) <class 'tuple'>, len=1
2026-04-15 20:15:05,060 - jwst.ami.leastsqnrm - INFO - number of nanlist pixels: 36 items
2026-04-15 20:15:05,060 - jwst.ami.leastsqnrm - INFO - 36 DO_NOT_USE pixels found in data slice
2026-04-15 20:15:05,061 - jwst.ami.leastsqnrm - INFO - flatimg (4725,) after deleting 36
2026-04-15 20:15:05,061 - jwst.ami.leastsqnrm - INFO - flatmodel_nan (4761, 44)
2026-04-15 20:15:05,062 - jwst.ami.leastsqnrm - INFO - flatmodel (4725, 44)
2026-04-15 20:15:05,062 - jwst.ami.leastsqnrm - INFO - difference 36
2026-04-15 20:15:05,063 - jwst.ami.leastsqnrm - INFO - flat model dimensions (4725, 44)
2026-04-15 20:15:05,063 - jwst.ami.leastsqnrm - INFO - flat image dimensions (4725,)
2026-04-15 20:15:05,065 - jwst.ami.leastsqnrm - INFO - data flux 2.73109e+06
2026-04-15 20:15:05,066 - jwst.ami.leastsqnrm - INFO - flat model dimensions (4725, 44)
2026-04-15 20:15:05,066 - jwst.ami.leastsqnrm - INFO - model transpose dimensions (44, 4725)
2026-04-15 20:15:05,067 - jwst.ami.leastsqnrm - INFO - flat image dimensions (4725,)
2026-04-15 20:15:05,067 - jwst.ami.leastsqnrm - INFO - transpose * image data dimensions (44,)
2026-04-15 20:15:05,067 - jwst.ami.leastsqnrm - INFO - flat img * transpose dimensions (44, 44)
2026-04-15 20:15:05,068 - jwst.ami.leastsqnrm - INFO - linearfit not attempted, no covariances saved.
2026-04-15 20:15:05,069 - jwst.ami.nrm_core - INFO - Fitting fringes for iteration 13 of 69
2026-04-15 20:15:06,130 - jwst.ami.leastsqnrm - INFO - fringefitting.leastsqnrm.matrix_operations():
2026-04-15 20:15:06,131 - jwst.ami.leastsqnrm - INFO - img (69, 69)
2026-04-15 20:15:06,131 - jwst.ami.leastsqnrm - INFO - L x W = 69 x 69 = 4761
2026-04-15 20:15:06,132 - jwst.ami.leastsqnrm - INFO - flatimg (4761,)
2026-04-15 20:15:06,132 - jwst.ami.leastsqnrm - INFO -
2026-04-15 20:15:06,132 - jwst.ami.leastsqnrm - INFO - type(dqm) <class 'numpy.ndarray'>
2026-04-15 20:15:06,133 - jwst.ami.leastsqnrm - INFO - type(nanlist) <class 'tuple'>, len=1
2026-04-15 20:15:06,133 - jwst.ami.leastsqnrm - INFO - number of nanlist pixels: 37 items
2026-04-15 20:15:06,134 - jwst.ami.leastsqnrm - INFO - 37 DO_NOT_USE pixels found in data slice
2026-04-15 20:15:06,134 - jwst.ami.leastsqnrm - INFO - flatimg (4724,) after deleting 37
2026-04-15 20:15:06,135 - jwst.ami.leastsqnrm - INFO - flatmodel_nan (4761, 44)
2026-04-15 20:15:06,135 - jwst.ami.leastsqnrm - INFO - flatmodel (4724, 44)
2026-04-15 20:15:06,136 - jwst.ami.leastsqnrm - INFO - difference 37
2026-04-15 20:15:06,136 - jwst.ami.leastsqnrm - INFO - flat model dimensions (4724, 44)
2026-04-15 20:15:06,137 - jwst.ami.leastsqnrm - INFO - flat image dimensions (4724,)
2026-04-15 20:15:06,139 - jwst.ami.leastsqnrm - INFO - data flux 2.757338e+06
2026-04-15 20:15:06,140 - jwst.ami.leastsqnrm - INFO - flat model dimensions (4724, 44)
2026-04-15 20:15:06,140 - jwst.ami.leastsqnrm - INFO - model transpose dimensions (44, 4724)
2026-04-15 20:15:06,141 - jwst.ami.leastsqnrm - INFO - flat image dimensions (4724,)
2026-04-15 20:15:06,141 - jwst.ami.leastsqnrm - INFO - transpose * image data dimensions (44,)
2026-04-15 20:15:06,141 - jwst.ami.leastsqnrm - INFO - flat img * transpose dimensions (44, 44)
2026-04-15 20:15:06,142 - jwst.ami.leastsqnrm - INFO - linearfit not attempted, no covariances saved.
2026-04-15 20:15:06,144 - jwst.ami.nrm_core - INFO - Fitting fringes for iteration 14 of 69
2026-04-15 20:15:07,214 - jwst.ami.leastsqnrm - INFO - fringefitting.leastsqnrm.matrix_operations():
2026-04-15 20:15:07,215 - jwst.ami.leastsqnrm - INFO - img (69, 69)
2026-04-15 20:15:07,216 - jwst.ami.leastsqnrm - INFO - L x W = 69 x 69 = 4761
2026-04-15 20:15:07,216 - jwst.ami.leastsqnrm - INFO - flatimg (4761,)
2026-04-15 20:15:07,216 - jwst.ami.leastsqnrm - INFO -
2026-04-15 20:15:07,217 - jwst.ami.leastsqnrm - INFO - type(dqm) <class 'numpy.ndarray'>
2026-04-15 20:15:07,218 - jwst.ami.leastsqnrm - INFO - type(nanlist) <class 'tuple'>, len=1
2026-04-15 20:15:07,218 - jwst.ami.leastsqnrm - INFO - number of nanlist pixels: 36 items
2026-04-15 20:15:07,219 - jwst.ami.leastsqnrm - INFO - 36 DO_NOT_USE pixels found in data slice
2026-04-15 20:15:07,219 - jwst.ami.leastsqnrm - INFO - flatimg (4725,) after deleting 36
2026-04-15 20:15:07,220 - jwst.ami.leastsqnrm - INFO - flatmodel_nan (4761, 44)
2026-04-15 20:15:07,220 - jwst.ami.leastsqnrm - INFO - flatmodel (4725, 44)
2026-04-15 20:15:07,221 - jwst.ami.leastsqnrm - INFO - difference 36
2026-04-15 20:15:07,221 - jwst.ami.leastsqnrm - INFO - flat model dimensions (4725, 44)
2026-04-15 20:15:07,222 - jwst.ami.leastsqnrm - INFO - flat image dimensions (4725,)
2026-04-15 20:15:07,224 - jwst.ami.leastsqnrm - INFO - data flux 2.7244265e+06
2026-04-15 20:15:07,224 - jwst.ami.leastsqnrm - INFO - flat model dimensions (4725, 44)
2026-04-15 20:15:07,225 - jwst.ami.leastsqnrm - INFO - model transpose dimensions (44, 4725)
2026-04-15 20:15:07,225 - jwst.ami.leastsqnrm - INFO - flat image dimensions (4725,)
2026-04-15 20:15:07,226 - jwst.ami.leastsqnrm - INFO - transpose * image data dimensions (44,)
2026-04-15 20:15:07,226 - jwst.ami.leastsqnrm - INFO - flat img * transpose dimensions (44, 44)
2026-04-15 20:15:07,226 - jwst.ami.leastsqnrm - INFO - linearfit not attempted, no covariances saved.
2026-04-15 20:15:07,228 - jwst.ami.nrm_core - INFO - Fitting fringes for iteration 15 of 69
2026-04-15 20:15:08,290 - jwst.ami.leastsqnrm - INFO - fringefitting.leastsqnrm.matrix_operations():
2026-04-15 20:15:08,291 - jwst.ami.leastsqnrm - INFO - img (69, 69)
2026-04-15 20:15:08,291 - jwst.ami.leastsqnrm - INFO - L x W = 69 x 69 = 4761
2026-04-15 20:15:08,292 - jwst.ami.leastsqnrm - INFO - flatimg (4761,)
2026-04-15 20:15:08,292 - jwst.ami.leastsqnrm - INFO -
2026-04-15 20:15:08,293 - jwst.ami.leastsqnrm - INFO - type(dqm) <class 'numpy.ndarray'>
2026-04-15 20:15:08,293 - jwst.ami.leastsqnrm - INFO - type(nanlist) <class 'tuple'>, len=1
2026-04-15 20:15:08,293 - jwst.ami.leastsqnrm - INFO - number of nanlist pixels: 37 items
2026-04-15 20:15:08,294 - jwst.ami.leastsqnrm - INFO - 37 DO_NOT_USE pixels found in data slice
2026-04-15 20:15:08,294 - jwst.ami.leastsqnrm - INFO - flatimg (4724,) after deleting 37
2026-04-15 20:15:08,295 - jwst.ami.leastsqnrm - INFO - flatmodel_nan (4761, 44)
2026-04-15 20:15:08,296 - jwst.ami.leastsqnrm - INFO - flatmodel (4724, 44)
2026-04-15 20:15:08,296 - jwst.ami.leastsqnrm - INFO - difference 37
2026-04-15 20:15:08,296 - jwst.ami.leastsqnrm - INFO - flat model dimensions (4724, 44)
2026-04-15 20:15:08,297 - jwst.ami.leastsqnrm - INFO - flat image dimensions (4724,)
2026-04-15 20:15:08,299 - jwst.ami.leastsqnrm - INFO - data flux 2.720188e+06
2026-04-15 20:15:08,300 - jwst.ami.leastsqnrm - INFO - flat model dimensions (4724, 44)
2026-04-15 20:15:08,300 - jwst.ami.leastsqnrm - INFO - model transpose dimensions (44, 4724)
2026-04-15 20:15:08,301 - jwst.ami.leastsqnrm - INFO - flat image dimensions (4724,)
2026-04-15 20:15:08,301 - jwst.ami.leastsqnrm - INFO - transpose * image data dimensions (44,)
2026-04-15 20:15:08,301 - jwst.ami.leastsqnrm - INFO - flat img * transpose dimensions (44, 44)
2026-04-15 20:15:08,302 - jwst.ami.leastsqnrm - INFO - linearfit not attempted, no covariances saved.
2026-04-15 20:15:08,304 - jwst.ami.nrm_core - INFO - Fitting fringes for iteration 16 of 69
2026-04-15 20:15:09,378 - jwst.ami.leastsqnrm - INFO - fringefitting.leastsqnrm.matrix_operations():
2026-04-15 20:15:09,379 - jwst.ami.leastsqnrm - INFO - img (69, 69)
2026-04-15 20:15:09,380 - jwst.ami.leastsqnrm - INFO - L x W = 69 x 69 = 4761
2026-04-15 20:15:09,380 - jwst.ami.leastsqnrm - INFO - flatimg (4761,)
2026-04-15 20:15:09,380 - jwst.ami.leastsqnrm - INFO -
2026-04-15 20:15:09,381 - jwst.ami.leastsqnrm - INFO - type(dqm) <class 'numpy.ndarray'>
2026-04-15 20:15:09,382 - jwst.ami.leastsqnrm - INFO - type(nanlist) <class 'tuple'>, len=1
2026-04-15 20:15:09,382 - jwst.ami.leastsqnrm - INFO - number of nanlist pixels: 36 items
2026-04-15 20:15:09,382 - jwst.ami.leastsqnrm - INFO - 36 DO_NOT_USE pixels found in data slice
2026-04-15 20:15:09,383 - jwst.ami.leastsqnrm - INFO - flatimg (4725,) after deleting 36
2026-04-15 20:15:09,384 - jwst.ami.leastsqnrm - INFO - flatmodel_nan (4761, 44)
2026-04-15 20:15:09,384 - jwst.ami.leastsqnrm - INFO - flatmodel (4725, 44)
2026-04-15 20:15:09,384 - jwst.ami.leastsqnrm - INFO - difference 36
2026-04-15 20:15:09,385 - jwst.ami.leastsqnrm - INFO - flat model dimensions (4725, 44)
2026-04-15 20:15:09,385 - jwst.ami.leastsqnrm - INFO - flat image dimensions (4725,)
2026-04-15 20:15:09,388 - jwst.ami.leastsqnrm - INFO - data flux 2.746328e+06
2026-04-15 20:15:09,388 - jwst.ami.leastsqnrm - INFO - flat model dimensions (4725, 44)
2026-04-15 20:15:09,388 - jwst.ami.leastsqnrm - INFO - model transpose dimensions (44, 4725)
2026-04-15 20:15:09,389 - jwst.ami.leastsqnrm - INFO - flat image dimensions (4725,)
2026-04-15 20:15:09,389 - jwst.ami.leastsqnrm - INFO - transpose * image data dimensions (44,)
2026-04-15 20:15:09,390 - jwst.ami.leastsqnrm - INFO - flat img * transpose dimensions (44, 44)
2026-04-15 20:15:09,390 - jwst.ami.leastsqnrm - INFO - linearfit not attempted, no covariances saved.
2026-04-15 20:15:09,392 - jwst.ami.nrm_core - INFO - Fitting fringes for iteration 17 of 69
2026-04-15 20:15:10,452 - jwst.ami.leastsqnrm - INFO - fringefitting.leastsqnrm.matrix_operations():
2026-04-15 20:15:10,453 - jwst.ami.leastsqnrm - INFO - img (69, 69)
2026-04-15 20:15:10,453 - jwst.ami.leastsqnrm - INFO - L x W = 69 x 69 = 4761
2026-04-15 20:15:10,454 - jwst.ami.leastsqnrm - INFO - flatimg (4761,)
2026-04-15 20:15:10,454 - jwst.ami.leastsqnrm - INFO -
2026-04-15 20:15:10,455 - jwst.ami.leastsqnrm - INFO - type(dqm) <class 'numpy.ndarray'>
2026-04-15 20:15:10,455 - jwst.ami.leastsqnrm - INFO - type(nanlist) <class 'tuple'>, len=1
2026-04-15 20:15:10,455 - jwst.ami.leastsqnrm - INFO - number of nanlist pixels: 37 items
2026-04-15 20:15:10,456 - jwst.ami.leastsqnrm - INFO - 37 DO_NOT_USE pixels found in data slice
2026-04-15 20:15:10,456 - jwst.ami.leastsqnrm - INFO - flatimg (4724,) after deleting 37
2026-04-15 20:15:10,457 - jwst.ami.leastsqnrm - INFO - flatmodel_nan (4761, 44)
2026-04-15 20:15:10,458 - jwst.ami.leastsqnrm - INFO - flatmodel (4724, 44)
2026-04-15 20:15:10,458 - jwst.ami.leastsqnrm - INFO - difference 37
2026-04-15 20:15:10,459 - jwst.ami.leastsqnrm - INFO - flat model dimensions (4724, 44)
2026-04-15 20:15:10,459 - jwst.ami.leastsqnrm - INFO - flat image dimensions (4724,)
2026-04-15 20:15:10,461 - jwst.ami.leastsqnrm - INFO - data flux 2.798918e+06
2026-04-15 20:15:10,462 - jwst.ami.leastsqnrm - INFO - flat model dimensions (4724, 44)
2026-04-15 20:15:10,462 - jwst.ami.leastsqnrm - INFO - model transpose dimensions (44, 4724)
2026-04-15 20:15:10,463 - jwst.ami.leastsqnrm - INFO - flat image dimensions (4724,)
2026-04-15 20:15:10,463 - jwst.ami.leastsqnrm - INFO - transpose * image data dimensions (44,)
2026-04-15 20:15:10,464 - jwst.ami.leastsqnrm - INFO - flat img * transpose dimensions (44, 44)
2026-04-15 20:15:10,464 - jwst.ami.leastsqnrm - INFO - linearfit not attempted, no covariances saved.
2026-04-15 20:15:10,466 - jwst.ami.nrm_core - INFO - Fitting fringes for iteration 18 of 69
2026-04-15 20:15:11,529 - jwst.ami.leastsqnrm - INFO - fringefitting.leastsqnrm.matrix_operations():
2026-04-15 20:15:11,530 - jwst.ami.leastsqnrm - INFO - img (69, 69)
2026-04-15 20:15:11,530 - jwst.ami.leastsqnrm - INFO - L x W = 69 x 69 = 4761
2026-04-15 20:15:11,531 - jwst.ami.leastsqnrm - INFO - flatimg (4761,)
2026-04-15 20:15:11,531 - jwst.ami.leastsqnrm - INFO -
2026-04-15 20:15:11,532 - jwst.ami.leastsqnrm - INFO - type(dqm) <class 'numpy.ndarray'>
2026-04-15 20:15:11,532 - jwst.ami.leastsqnrm - INFO - type(nanlist) <class 'tuple'>, len=1
2026-04-15 20:15:11,533 - jwst.ami.leastsqnrm - INFO - number of nanlist pixels: 36 items
2026-04-15 20:15:11,533 - jwst.ami.leastsqnrm - INFO - 36 DO_NOT_USE pixels found in data slice
2026-04-15 20:15:11,534 - jwst.ami.leastsqnrm - INFO - flatimg (4725,) after deleting 36
2026-04-15 20:15:11,535 - jwst.ami.leastsqnrm - INFO - flatmodel_nan (4761, 44)
2026-04-15 20:15:11,535 - jwst.ami.leastsqnrm - INFO - flatmodel (4725, 44)
2026-04-15 20:15:11,535 - jwst.ami.leastsqnrm - INFO - difference 36
2026-04-15 20:15:11,536 - jwst.ami.leastsqnrm - INFO - flat model dimensions (4725, 44)
2026-04-15 20:15:11,536 - jwst.ami.leastsqnrm - INFO - flat image dimensions (4725,)
2026-04-15 20:15:11,539 - jwst.ami.leastsqnrm - INFO - data flux 2.7706985e+06
2026-04-15 20:15:11,539 - jwst.ami.leastsqnrm - INFO - flat model dimensions (4725, 44)
2026-04-15 20:15:11,539 - jwst.ami.leastsqnrm - INFO - model transpose dimensions (44, 4725)
2026-04-15 20:15:11,540 - jwst.ami.leastsqnrm - INFO - flat image dimensions (4725,)
2026-04-15 20:15:11,540 - jwst.ami.leastsqnrm - INFO - transpose * image data dimensions (44,)
2026-04-15 20:15:11,541 - jwst.ami.leastsqnrm - INFO - flat img * transpose dimensions (44, 44)
2026-04-15 20:15:11,541 - jwst.ami.leastsqnrm - INFO - linearfit not attempted, no covariances saved.
2026-04-15 20:15:11,543 - jwst.ami.nrm_core - INFO - Fitting fringes for iteration 19 of 69
2026-04-15 20:15:12,607 - jwst.ami.leastsqnrm - INFO - fringefitting.leastsqnrm.matrix_operations():
2026-04-15 20:15:12,608 - jwst.ami.leastsqnrm - INFO - img (69, 69)
2026-04-15 20:15:12,608 - jwst.ami.leastsqnrm - INFO - L x W = 69 x 69 = 4761
2026-04-15 20:15:12,609 - jwst.ami.leastsqnrm - INFO - flatimg (4761,)
2026-04-15 20:15:12,609 - jwst.ami.leastsqnrm - INFO -
2026-04-15 20:15:12,610 - jwst.ami.leastsqnrm - INFO - type(dqm) <class 'numpy.ndarray'>
2026-04-15 20:15:12,610 - jwst.ami.leastsqnrm - INFO - type(nanlist) <class 'tuple'>, len=1
2026-04-15 20:15:12,611 - jwst.ami.leastsqnrm - INFO - number of nanlist pixels: 38 items
2026-04-15 20:15:12,611 - jwst.ami.leastsqnrm - INFO - 38 DO_NOT_USE pixels found in data slice
2026-04-15 20:15:12,612 - jwst.ami.leastsqnrm - INFO - flatimg (4723,) after deleting 38
2026-04-15 20:15:12,612 - jwst.ami.leastsqnrm - INFO - flatmodel_nan (4761, 44)
2026-04-15 20:15:12,613 - jwst.ami.leastsqnrm - INFO - flatmodel (4723, 44)
2026-04-15 20:15:12,613 - jwst.ami.leastsqnrm - INFO - difference 38
2026-04-15 20:15:12,614 - jwst.ami.leastsqnrm - INFO - flat model dimensions (4723, 44)
2026-04-15 20:15:12,614 - jwst.ami.leastsqnrm - INFO - flat image dimensions (4723,)
2026-04-15 20:15:12,616 - jwst.ami.leastsqnrm - INFO - data flux 2.7437448e+06
2026-04-15 20:15:12,617 - jwst.ami.leastsqnrm - INFO - flat model dimensions (4723, 44)
2026-04-15 20:15:12,617 - jwst.ami.leastsqnrm - INFO - model transpose dimensions (44, 4723)
2026-04-15 20:15:12,618 - jwst.ami.leastsqnrm - INFO - flat image dimensions (4723,)
2026-04-15 20:15:12,618 - jwst.ami.leastsqnrm - INFO - transpose * image data dimensions (44,)
2026-04-15 20:15:12,619 - jwst.ami.leastsqnrm - INFO - flat img * transpose dimensions (44, 44)
2026-04-15 20:15:12,619 - jwst.ami.leastsqnrm - INFO - linearfit not attempted, no covariances saved.
2026-04-15 20:15:12,621 - jwst.ami.nrm_core - INFO - Fitting fringes for iteration 20 of 69
2026-04-15 20:15:13,678 - jwst.ami.leastsqnrm - INFO - fringefitting.leastsqnrm.matrix_operations():
2026-04-15 20:15:13,679 - jwst.ami.leastsqnrm - INFO - img (69, 69)
2026-04-15 20:15:13,679 - jwst.ami.leastsqnrm - INFO - L x W = 69 x 69 = 4761
2026-04-15 20:15:13,680 - jwst.ami.leastsqnrm - INFO - flatimg (4761,)
2026-04-15 20:15:13,680 - jwst.ami.leastsqnrm - INFO -
2026-04-15 20:15:13,681 - jwst.ami.leastsqnrm - INFO - type(dqm) <class 'numpy.ndarray'>
2026-04-15 20:15:13,681 - jwst.ami.leastsqnrm - INFO - type(nanlist) <class 'tuple'>, len=1
2026-04-15 20:15:13,682 - jwst.ami.leastsqnrm - INFO - number of nanlist pixels: 36 items
2026-04-15 20:15:13,682 - jwst.ami.leastsqnrm - INFO - 36 DO_NOT_USE pixels found in data slice
2026-04-15 20:15:13,683 - jwst.ami.leastsqnrm - INFO - flatimg (4725,) after deleting 36
2026-04-15 20:15:13,683 - jwst.ami.leastsqnrm - INFO - flatmodel_nan (4761, 44)
2026-04-15 20:15:13,684 - jwst.ami.leastsqnrm - INFO - flatmodel (4725, 44)
2026-04-15 20:15:13,684 - jwst.ami.leastsqnrm - INFO - difference 36
2026-04-15 20:15:13,684 - jwst.ami.leastsqnrm - INFO - flat model dimensions (4725, 44)
2026-04-15 20:15:13,685 - jwst.ami.leastsqnrm - INFO - flat image dimensions (4725,)
2026-04-15 20:15:13,688 - jwst.ami.leastsqnrm - INFO - data flux 2.7259565e+06
2026-04-15 20:15:13,688 - jwst.ami.leastsqnrm - INFO - flat model dimensions (4725, 44)
2026-04-15 20:15:13,688 - jwst.ami.leastsqnrm - INFO - model transpose dimensions (44, 4725)
2026-04-15 20:15:13,689 - jwst.ami.leastsqnrm - INFO - flat image dimensions (4725,)
2026-04-15 20:15:13,689 - jwst.ami.leastsqnrm - INFO - transpose * image data dimensions (44,)
2026-04-15 20:15:13,690 - jwst.ami.leastsqnrm - INFO - flat img * transpose dimensions (44, 44)
2026-04-15 20:15:13,690 - jwst.ami.leastsqnrm - INFO - linearfit not attempted, no covariances saved.
2026-04-15 20:15:13,692 - jwst.ami.nrm_core - INFO - Fitting fringes for iteration 21 of 69
2026-04-15 20:15:14,757 - jwst.ami.leastsqnrm - INFO - fringefitting.leastsqnrm.matrix_operations():
2026-04-15 20:15:14,758 - jwst.ami.leastsqnrm - INFO - img (69, 69)
2026-04-15 20:15:14,758 - jwst.ami.leastsqnrm - INFO - L x W = 69 x 69 = 4761
2026-04-15 20:15:14,759 - jwst.ami.leastsqnrm - INFO - flatimg (4761,)
2026-04-15 20:15:14,759 - jwst.ami.leastsqnrm - INFO -
2026-04-15 20:15:14,759 - jwst.ami.leastsqnrm - INFO - type(dqm) <class 'numpy.ndarray'>
2026-04-15 20:15:14,760 - jwst.ami.leastsqnrm - INFO - type(nanlist) <class 'tuple'>, len=1
2026-04-15 20:15:14,760 - jwst.ami.leastsqnrm - INFO - number of nanlist pixels: 36 items
2026-04-15 20:15:14,761 - jwst.ami.leastsqnrm - INFO - 36 DO_NOT_USE pixels found in data slice
2026-04-15 20:15:14,761 - jwst.ami.leastsqnrm - INFO - flatimg (4725,) after deleting 36
2026-04-15 20:15:14,762 - jwst.ami.leastsqnrm - INFO - flatmodel_nan (4761, 44)
2026-04-15 20:15:14,763 - jwst.ami.leastsqnrm - INFO - flatmodel (4725, 44)
2026-04-15 20:15:14,763 - jwst.ami.leastsqnrm - INFO - difference 36
2026-04-15 20:15:14,764 - jwst.ami.leastsqnrm - INFO - flat model dimensions (4725, 44)
2026-04-15 20:15:14,764 - jwst.ami.leastsqnrm - INFO - flat image dimensions (4725,)
2026-04-15 20:15:14,766 - jwst.ami.leastsqnrm - INFO - data flux 2.7325925e+06
2026-04-15 20:15:14,767 - jwst.ami.leastsqnrm - INFO - flat model dimensions (4725, 44)
2026-04-15 20:15:14,767 - jwst.ami.leastsqnrm - INFO - model transpose dimensions (44, 4725)
2026-04-15 20:15:14,768 - jwst.ami.leastsqnrm - INFO - flat image dimensions (4725,)
2026-04-15 20:15:14,769 - jwst.ami.leastsqnrm - INFO - transpose * image data dimensions (44,)
2026-04-15 20:15:14,769 - jwst.ami.leastsqnrm - INFO - flat img * transpose dimensions (44, 44)
2026-04-15 20:15:14,769 - jwst.ami.leastsqnrm - INFO - linearfit not attempted, no covariances saved.
2026-04-15 20:15:14,771 - jwst.ami.nrm_core - INFO - Fitting fringes for iteration 22 of 69
2026-04-15 20:15:15,822 - jwst.ami.leastsqnrm - INFO - fringefitting.leastsqnrm.matrix_operations():
2026-04-15 20:15:15,823 - jwst.ami.leastsqnrm - INFO - img (69, 69)
2026-04-15 20:15:15,823 - jwst.ami.leastsqnrm - INFO - L x W = 69 x 69 = 4761
2026-04-15 20:15:15,824 - jwst.ami.leastsqnrm - INFO - flatimg (4761,)
2026-04-15 20:15:15,824 - jwst.ami.leastsqnrm - INFO -
2026-04-15 20:15:15,825 - jwst.ami.leastsqnrm - INFO - type(dqm) <class 'numpy.ndarray'>
2026-04-15 20:15:15,825 - jwst.ami.leastsqnrm - INFO - type(nanlist) <class 'tuple'>, len=1
2026-04-15 20:15:15,825 - jwst.ami.leastsqnrm - INFO - number of nanlist pixels: 36 items
2026-04-15 20:15:15,826 - jwst.ami.leastsqnrm - INFO - 36 DO_NOT_USE pixels found in data slice
2026-04-15 20:15:15,826 - jwst.ami.leastsqnrm - INFO - flatimg (4725,) after deleting 36
2026-04-15 20:15:15,827 - jwst.ami.leastsqnrm - INFO - flatmodel_nan (4761, 44)
2026-04-15 20:15:15,828 - jwst.ami.leastsqnrm - INFO - flatmodel (4725, 44)
2026-04-15 20:15:15,828 - jwst.ami.leastsqnrm - INFO - difference 36
2026-04-15 20:15:15,829 - jwst.ami.leastsqnrm - INFO - flat model dimensions (4725, 44)
2026-04-15 20:15:15,829 - jwst.ami.leastsqnrm - INFO - flat image dimensions (4725,)
2026-04-15 20:15:15,832 - jwst.ami.leastsqnrm - INFO - data flux 2.738164e+06
2026-04-15 20:15:15,832 - jwst.ami.leastsqnrm - INFO - flat model dimensions (4725, 44)
2026-04-15 20:15:15,832 - jwst.ami.leastsqnrm - INFO - model transpose dimensions (44, 4725)
2026-04-15 20:15:15,833 - jwst.ami.leastsqnrm - INFO - flat image dimensions (4725,)
2026-04-15 20:15:15,833 - jwst.ami.leastsqnrm - INFO - transpose * image data dimensions (44,)
2026-04-15 20:15:15,834 - jwst.ami.leastsqnrm - INFO - flat img * transpose dimensions (44, 44)
2026-04-15 20:15:15,834 - jwst.ami.leastsqnrm - INFO - linearfit not attempted, no covariances saved.
2026-04-15 20:15:15,836 - jwst.ami.nrm_core - INFO - Fitting fringes for iteration 23 of 69
2026-04-15 20:15:16,899 - jwst.ami.leastsqnrm - INFO - fringefitting.leastsqnrm.matrix_operations():
2026-04-15 20:15:16,900 - jwst.ami.leastsqnrm - INFO - img (69, 69)
2026-04-15 20:15:16,901 - jwst.ami.leastsqnrm - INFO - L x W = 69 x 69 = 4761
2026-04-15 20:15:16,901 - jwst.ami.leastsqnrm - INFO - flatimg (4761,)
2026-04-15 20:15:16,901 - jwst.ami.leastsqnrm - INFO -
2026-04-15 20:15:16,902 - jwst.ami.leastsqnrm - INFO - type(dqm) <class 'numpy.ndarray'>
2026-04-15 20:15:16,902 - jwst.ami.leastsqnrm - INFO - type(nanlist) <class 'tuple'>, len=1
2026-04-15 20:15:16,903 - jwst.ami.leastsqnrm - INFO - number of nanlist pixels: 38 items
2026-04-15 20:15:16,903 - jwst.ami.leastsqnrm - INFO - 38 DO_NOT_USE pixels found in data slice
2026-04-15 20:15:16,903 - jwst.ami.leastsqnrm - INFO - flatimg (4723,) after deleting 38
2026-04-15 20:15:16,905 - jwst.ami.leastsqnrm - INFO - flatmodel_nan (4761, 44)
2026-04-15 20:15:16,905 - jwst.ami.leastsqnrm - INFO - flatmodel (4723, 44)
2026-04-15 20:15:16,905 - jwst.ami.leastsqnrm - INFO - difference 38
2026-04-15 20:15:16,906 - jwst.ami.leastsqnrm - INFO - flat model dimensions (4723, 44)
2026-04-15 20:15:16,906 - jwst.ami.leastsqnrm - INFO - flat image dimensions (4723,)
2026-04-15 20:15:16,909 - jwst.ami.leastsqnrm - INFO - data flux 2.7002095e+06
2026-04-15 20:15:16,909 - jwst.ami.leastsqnrm - INFO - flat model dimensions (4723, 44)
2026-04-15 20:15:16,910 - jwst.ami.leastsqnrm - INFO - model transpose dimensions (44, 4723)
2026-04-15 20:15:16,910 - jwst.ami.leastsqnrm - INFO - flat image dimensions (4723,)
2026-04-15 20:15:16,910 - jwst.ami.leastsqnrm - INFO - transpose * image data dimensions (44,)
2026-04-15 20:15:16,911 - jwst.ami.leastsqnrm - INFO - flat img * transpose dimensions (44, 44)
2026-04-15 20:15:16,911 - jwst.ami.leastsqnrm - INFO - linearfit not attempted, no covariances saved.
2026-04-15 20:15:16,913 - jwst.ami.nrm_core - INFO - Fitting fringes for iteration 24 of 69
2026-04-15 20:15:17,973 - jwst.ami.leastsqnrm - INFO - fringefitting.leastsqnrm.matrix_operations():
2026-04-15 20:15:17,974 - jwst.ami.leastsqnrm - INFO - img (69, 69)
2026-04-15 20:15:17,974 - jwst.ami.leastsqnrm - INFO - L x W = 69 x 69 = 4761
2026-04-15 20:15:17,975 - jwst.ami.leastsqnrm - INFO - flatimg (4761,)
2026-04-15 20:15:17,975 - jwst.ami.leastsqnrm - INFO -
2026-04-15 20:15:17,976 - jwst.ami.leastsqnrm - INFO - type(dqm) <class 'numpy.ndarray'>
2026-04-15 20:15:17,976 - jwst.ami.leastsqnrm - INFO - type(nanlist) <class 'tuple'>, len=1
2026-04-15 20:15:17,977 - jwst.ami.leastsqnrm - INFO - number of nanlist pixels: 38 items
2026-04-15 20:15:17,977 - jwst.ami.leastsqnrm - INFO - 38 DO_NOT_USE pixels found in data slice
2026-04-15 20:15:17,978 - jwst.ami.leastsqnrm - INFO - flatimg (4723,) after deleting 38
2026-04-15 20:15:17,978 - jwst.ami.leastsqnrm - INFO - flatmodel_nan (4761, 44)
2026-04-15 20:15:17,979 - jwst.ami.leastsqnrm - INFO - flatmodel (4723, 44)
2026-04-15 20:15:17,979 - jwst.ami.leastsqnrm - INFO - difference 38
2026-04-15 20:15:17,979 - jwst.ami.leastsqnrm - INFO - flat model dimensions (4723, 44)
2026-04-15 20:15:17,980 - jwst.ami.leastsqnrm - INFO - flat image dimensions (4723,)
2026-04-15 20:15:17,983 - jwst.ami.leastsqnrm - INFO - data flux 2.723584e+06
2026-04-15 20:15:17,983 - jwst.ami.leastsqnrm - INFO - flat model dimensions (4723, 44)
2026-04-15 20:15:17,984 - jwst.ami.leastsqnrm - INFO - model transpose dimensions (44, 4723)
2026-04-15 20:15:17,984 - jwst.ami.leastsqnrm - INFO - flat image dimensions (4723,)
2026-04-15 20:15:17,984 - jwst.ami.leastsqnrm - INFO - transpose * image data dimensions (44,)
2026-04-15 20:15:17,985 - jwst.ami.leastsqnrm - INFO - flat img * transpose dimensions (44, 44)
2026-04-15 20:15:17,985 - jwst.ami.leastsqnrm - INFO - linearfit not attempted, no covariances saved.
2026-04-15 20:15:17,987 - jwst.ami.nrm_core - INFO - Fitting fringes for iteration 25 of 69
2026-04-15 20:15:19,044 - jwst.ami.leastsqnrm - INFO - fringefitting.leastsqnrm.matrix_operations():
2026-04-15 20:15:19,044 - jwst.ami.leastsqnrm - INFO - img (69, 69)
2026-04-15 20:15:19,045 - jwst.ami.leastsqnrm - INFO - L x W = 69 x 69 = 4761
2026-04-15 20:15:19,045 - jwst.ami.leastsqnrm - INFO - flatimg (4761,)
2026-04-15 20:15:19,046 - jwst.ami.leastsqnrm - INFO -
2026-04-15 20:15:19,046 - jwst.ami.leastsqnrm - INFO - type(dqm) <class 'numpy.ndarray'>
2026-04-15 20:15:19,047 - jwst.ami.leastsqnrm - INFO - type(nanlist) <class 'tuple'>, len=1
2026-04-15 20:15:19,047 - jwst.ami.leastsqnrm - INFO - number of nanlist pixels: 37 items
2026-04-15 20:15:19,048 - jwst.ami.leastsqnrm - INFO - 37 DO_NOT_USE pixels found in data slice
2026-04-15 20:15:19,048 - jwst.ami.leastsqnrm - INFO - flatimg (4724,) after deleting 37
2026-04-15 20:15:19,049 - jwst.ami.leastsqnrm - INFO - flatmodel_nan (4761, 44)
2026-04-15 20:15:19,049 - jwst.ami.leastsqnrm - INFO - flatmodel (4724, 44)
2026-04-15 20:15:19,050 - jwst.ami.leastsqnrm - INFO - difference 37
2026-04-15 20:15:19,050 - jwst.ami.leastsqnrm - INFO - flat model dimensions (4724, 44)
2026-04-15 20:15:19,051 - jwst.ami.leastsqnrm - INFO - flat image dimensions (4724,)
2026-04-15 20:15:19,053 - jwst.ami.leastsqnrm - INFO - data flux 2.7442655e+06
2026-04-15 20:15:19,053 - jwst.ami.leastsqnrm - INFO - flat model dimensions (4724, 44)
2026-04-15 20:15:19,054 - jwst.ami.leastsqnrm - INFO - model transpose dimensions (44, 4724)
2026-04-15 20:15:19,054 - jwst.ami.leastsqnrm - INFO - flat image dimensions (4724,)
2026-04-15 20:15:19,055 - jwst.ami.leastsqnrm - INFO - transpose * image data dimensions (44,)
2026-04-15 20:15:19,055 - jwst.ami.leastsqnrm - INFO - flat img * transpose dimensions (44, 44)
2026-04-15 20:15:19,055 - jwst.ami.leastsqnrm - INFO - linearfit not attempted, no covariances saved.
2026-04-15 20:15:19,057 - jwst.ami.nrm_core - INFO - Fitting fringes for iteration 26 of 69
2026-04-15 20:15:20,117 - jwst.ami.leastsqnrm - INFO - fringefitting.leastsqnrm.matrix_operations():
2026-04-15 20:15:20,118 - jwst.ami.leastsqnrm - INFO - img (69, 69)
2026-04-15 20:15:20,118 - jwst.ami.leastsqnrm - INFO - L x W = 69 x 69 = 4761
2026-04-15 20:15:20,119 - jwst.ami.leastsqnrm - INFO - flatimg (4761,)
2026-04-15 20:15:20,119 - jwst.ami.leastsqnrm - INFO -
2026-04-15 20:15:20,120 - jwst.ami.leastsqnrm - INFO - type(dqm) <class 'numpy.ndarray'>
2026-04-15 20:15:20,120 - jwst.ami.leastsqnrm - INFO - type(nanlist) <class 'tuple'>, len=1
2026-04-15 20:15:20,121 - jwst.ami.leastsqnrm - INFO - number of nanlist pixels: 37 items
2026-04-15 20:15:20,121 - jwst.ami.leastsqnrm - INFO - 37 DO_NOT_USE pixels found in data slice
2026-04-15 20:15:20,121 - jwst.ami.leastsqnrm - INFO - flatimg (4724,) after deleting 37
2026-04-15 20:15:20,122 - jwst.ami.leastsqnrm - INFO - flatmodel_nan (4761, 44)
2026-04-15 20:15:20,123 - jwst.ami.leastsqnrm - INFO - flatmodel (4724, 44)
2026-04-15 20:15:20,123 - jwst.ami.leastsqnrm - INFO - difference 37
2026-04-15 20:15:20,124 - jwst.ami.leastsqnrm - INFO - flat model dimensions (4724, 44)
2026-04-15 20:15:20,124 - jwst.ami.leastsqnrm - INFO - flat image dimensions (4724,)
2026-04-15 20:15:20,126 - jwst.ami.leastsqnrm - INFO - data flux 2.7179032e+06
2026-04-15 20:15:20,127 - jwst.ami.leastsqnrm - INFO - flat model dimensions (4724, 44)
2026-04-15 20:15:20,127 - jwst.ami.leastsqnrm - INFO - model transpose dimensions (44, 4724)
2026-04-15 20:15:20,128 - jwst.ami.leastsqnrm - INFO - flat image dimensions (4724,)
2026-04-15 20:15:20,128 - jwst.ami.leastsqnrm - INFO - transpose * image data dimensions (44,)
2026-04-15 20:15:20,129 - jwst.ami.leastsqnrm - INFO - flat img * transpose dimensions (44, 44)
2026-04-15 20:15:20,129 - jwst.ami.leastsqnrm - INFO - linearfit not attempted, no covariances saved.
2026-04-15 20:15:20,131 - jwst.ami.nrm_core - INFO - Fitting fringes for iteration 27 of 69
2026-04-15 20:15:21,194 - jwst.ami.leastsqnrm - INFO - fringefitting.leastsqnrm.matrix_operations():
2026-04-15 20:15:21,194 - jwst.ami.leastsqnrm - INFO - img (69, 69)
2026-04-15 20:15:21,195 - jwst.ami.leastsqnrm - INFO - L x W = 69 x 69 = 4761
2026-04-15 20:15:21,195 - jwst.ami.leastsqnrm - INFO - flatimg (4761,)
2026-04-15 20:15:21,196 - jwst.ami.leastsqnrm - INFO -
2026-04-15 20:15:21,196 - jwst.ami.leastsqnrm - INFO - type(dqm) <class 'numpy.ndarray'>
2026-04-15 20:15:21,197 - jwst.ami.leastsqnrm - INFO - type(nanlist) <class 'tuple'>, len=1
2026-04-15 20:15:21,197 - jwst.ami.leastsqnrm - INFO - number of nanlist pixels: 37 items
2026-04-15 20:15:21,197 - jwst.ami.leastsqnrm - INFO - 37 DO_NOT_USE pixels found in data slice
2026-04-15 20:15:21,198 - jwst.ami.leastsqnrm - INFO - flatimg (4724,) after deleting 37
2026-04-15 20:15:21,199 - jwst.ami.leastsqnrm - INFO - flatmodel_nan (4761, 44)
2026-04-15 20:15:21,199 - jwst.ami.leastsqnrm - INFO - flatmodel (4724, 44)
2026-04-15 20:15:21,200 - jwst.ami.leastsqnrm - INFO - difference 37
2026-04-15 20:15:21,200 - jwst.ami.leastsqnrm - INFO - flat model dimensions (4724, 44)
2026-04-15 20:15:21,201 - jwst.ami.leastsqnrm - INFO - flat image dimensions (4724,)
2026-04-15 20:15:21,203 - jwst.ami.leastsqnrm - INFO - data flux 2.724426e+06
2026-04-15 20:15:21,203 - jwst.ami.leastsqnrm - INFO - flat model dimensions (4724, 44)
2026-04-15 20:15:21,204 - jwst.ami.leastsqnrm - INFO - model transpose dimensions (44, 4724)
2026-04-15 20:15:21,204 - jwst.ami.leastsqnrm - INFO - flat image dimensions (4724,)
2026-04-15 20:15:21,205 - jwst.ami.leastsqnrm - INFO - transpose * image data dimensions (44,)
2026-04-15 20:15:21,205 - jwst.ami.leastsqnrm - INFO - flat img * transpose dimensions (44, 44)
2026-04-15 20:15:21,206 - jwst.ami.leastsqnrm - INFO - linearfit not attempted, no covariances saved.
2026-04-15 20:15:21,207 - jwst.ami.nrm_core - INFO - Fitting fringes for iteration 28 of 69
2026-04-15 20:15:22,264 - jwst.ami.leastsqnrm - INFO - fringefitting.leastsqnrm.matrix_operations():
2026-04-15 20:15:22,265 - jwst.ami.leastsqnrm - INFO - img (69, 69)
2026-04-15 20:15:22,265 - jwst.ami.leastsqnrm - INFO - L x W = 69 x 69 = 4761
2026-04-15 20:15:22,266 - jwst.ami.leastsqnrm - INFO - flatimg (4761,)
2026-04-15 20:15:22,266 - jwst.ami.leastsqnrm - INFO -
2026-04-15 20:15:22,267 - jwst.ami.leastsqnrm - INFO - type(dqm) <class 'numpy.ndarray'>
2026-04-15 20:15:22,267 - jwst.ami.leastsqnrm - INFO - type(nanlist) <class 'tuple'>, len=1
2026-04-15 20:15:22,268 - jwst.ami.leastsqnrm - INFO - number of nanlist pixels: 36 items
2026-04-15 20:15:22,268 - jwst.ami.leastsqnrm - INFO - 36 DO_NOT_USE pixels found in data slice
2026-04-15 20:15:22,269 - jwst.ami.leastsqnrm - INFO - flatimg (4725,) after deleting 36
2026-04-15 20:15:22,269 - jwst.ami.leastsqnrm - INFO - flatmodel_nan (4761, 44)
2026-04-15 20:15:22,270 - jwst.ami.leastsqnrm - INFO - flatmodel (4725, 44)
2026-04-15 20:15:22,270 - jwst.ami.leastsqnrm - INFO - difference 36
2026-04-15 20:15:22,271 - jwst.ami.leastsqnrm - INFO - flat model dimensions (4725, 44)
2026-04-15 20:15:22,271 - jwst.ami.leastsqnrm - INFO - flat image dimensions (4725,)
2026-04-15 20:15:22,274 - jwst.ami.leastsqnrm - INFO - data flux 2.7099045e+06
2026-04-15 20:15:22,274 - jwst.ami.leastsqnrm - INFO - flat model dimensions (4725, 44)
2026-04-15 20:15:22,274 - jwst.ami.leastsqnrm - INFO - model transpose dimensions (44, 4725)
2026-04-15 20:15:22,275 - jwst.ami.leastsqnrm - INFO - flat image dimensions (4725,)
2026-04-15 20:15:22,276 - jwst.ami.leastsqnrm - INFO - transpose * image data dimensions (44,)
2026-04-15 20:15:22,276 - jwst.ami.leastsqnrm - INFO - flat img * transpose dimensions (44, 44)
2026-04-15 20:15:22,276 - jwst.ami.leastsqnrm - INFO - linearfit not attempted, no covariances saved.
2026-04-15 20:15:22,278 - jwst.ami.nrm_core - INFO - Fitting fringes for iteration 29 of 69
2026-04-15 20:15:23,334 - jwst.ami.leastsqnrm - INFO - fringefitting.leastsqnrm.matrix_operations():
2026-04-15 20:15:23,335 - jwst.ami.leastsqnrm - INFO - img (69, 69)
2026-04-15 20:15:23,336 - jwst.ami.leastsqnrm - INFO - L x W = 69 x 69 = 4761
2026-04-15 20:15:23,336 - jwst.ami.leastsqnrm - INFO - flatimg (4761,)
2026-04-15 20:15:23,337 - jwst.ami.leastsqnrm - INFO -
2026-04-15 20:15:23,337 - jwst.ami.leastsqnrm - INFO - type(dqm) <class 'numpy.ndarray'>
2026-04-15 20:15:23,338 - jwst.ami.leastsqnrm - INFO - type(nanlist) <class 'tuple'>, len=1
2026-04-15 20:15:23,338 - jwst.ami.leastsqnrm - INFO - number of nanlist pixels: 44 items
2026-04-15 20:15:23,338 - jwst.ami.leastsqnrm - INFO - 44 DO_NOT_USE pixels found in data slice
2026-04-15 20:15:23,339 - jwst.ami.leastsqnrm - INFO - flatimg (4717,) after deleting 44
2026-04-15 20:15:23,340 - jwst.ami.leastsqnrm - INFO - flatmodel_nan (4761, 44)
2026-04-15 20:15:23,341 - jwst.ami.leastsqnrm - INFO - flatmodel (4717, 44)
2026-04-15 20:15:23,341 - jwst.ami.leastsqnrm - INFO - difference 44
2026-04-15 20:15:23,342 - jwst.ami.leastsqnrm - INFO - flat model dimensions (4717, 44)
2026-04-15 20:15:23,342 - jwst.ami.leastsqnrm - INFO - flat image dimensions (4717,)
2026-04-15 20:15:23,344 - jwst.ami.leastsqnrm - INFO - data flux 2.717448e+06
2026-04-15 20:15:23,345 - jwst.ami.leastsqnrm - INFO - flat model dimensions (4717, 44)
2026-04-15 20:15:23,345 - jwst.ami.leastsqnrm - INFO - model transpose dimensions (44, 4717)
2026-04-15 20:15:23,346 - jwst.ami.leastsqnrm - INFO - flat image dimensions (4717,)
2026-04-15 20:15:23,346 - jwst.ami.leastsqnrm - INFO - transpose * image data dimensions (44,)
2026-04-15 20:15:23,346 - jwst.ami.leastsqnrm - INFO - flat img * transpose dimensions (44, 44)
2026-04-15 20:15:23,347 - jwst.ami.leastsqnrm - INFO - linearfit not attempted, no covariances saved.
2026-04-15 20:15:23,349 - jwst.ami.nrm_core - INFO - Fitting fringes for iteration 30 of 69
2026-04-15 20:15:24,404 - jwst.ami.leastsqnrm - INFO - fringefitting.leastsqnrm.matrix_operations():
2026-04-15 20:15:24,404 - jwst.ami.leastsqnrm - INFO - img (69, 69)
2026-04-15 20:15:24,405 - jwst.ami.leastsqnrm - INFO - L x W = 69 x 69 = 4761
2026-04-15 20:15:24,405 - jwst.ami.leastsqnrm - INFO - flatimg (4761,)
2026-04-15 20:15:24,406 - jwst.ami.leastsqnrm - INFO -
2026-04-15 20:15:24,406 - jwst.ami.leastsqnrm - INFO - type(dqm) <class 'numpy.ndarray'>
2026-04-15 20:15:24,406 - jwst.ami.leastsqnrm - INFO - type(nanlist) <class 'tuple'>, len=1
2026-04-15 20:15:24,407 - jwst.ami.leastsqnrm - INFO - number of nanlist pixels: 36 items
2026-04-15 20:15:24,407 - jwst.ami.leastsqnrm - INFO - 36 DO_NOT_USE pixels found in data slice
2026-04-15 20:15:24,408 - jwst.ami.leastsqnrm - INFO - flatimg (4725,) after deleting 36
2026-04-15 20:15:24,409 - jwst.ami.leastsqnrm - INFO - flatmodel_nan (4761, 44)
2026-04-15 20:15:24,409 - jwst.ami.leastsqnrm - INFO - flatmodel (4725, 44)
2026-04-15 20:15:24,410 - jwst.ami.leastsqnrm - INFO - difference 36
2026-04-15 20:15:24,410 - jwst.ami.leastsqnrm - INFO - flat model dimensions (4725, 44)
2026-04-15 20:15:24,411 - jwst.ami.leastsqnrm - INFO - flat image dimensions (4725,)
2026-04-15 20:15:24,413 - jwst.ami.leastsqnrm - INFO - data flux 2.7467295e+06
2026-04-15 20:15:24,414 - jwst.ami.leastsqnrm - INFO - flat model dimensions (4725, 44)
2026-04-15 20:15:24,414 - jwst.ami.leastsqnrm - INFO - model transpose dimensions (44, 4725)
2026-04-15 20:15:24,414 - jwst.ami.leastsqnrm - INFO - flat image dimensions (4725,)
2026-04-15 20:15:24,415 - jwst.ami.leastsqnrm - INFO - transpose * image data dimensions (44,)
2026-04-15 20:15:24,415 - jwst.ami.leastsqnrm - INFO - flat img * transpose dimensions (44, 44)
2026-04-15 20:15:24,416 - jwst.ami.leastsqnrm - INFO - linearfit not attempted, no covariances saved.
2026-04-15 20:15:24,417 - jwst.ami.nrm_core - INFO - Fitting fringes for iteration 31 of 69
2026-04-15 20:15:25,479 - jwst.ami.leastsqnrm - INFO - fringefitting.leastsqnrm.matrix_operations():
2026-04-15 20:15:25,480 - jwst.ami.leastsqnrm - INFO - img (69, 69)
2026-04-15 20:15:25,480 - jwst.ami.leastsqnrm - INFO - L x W = 69 x 69 = 4761
2026-04-15 20:15:25,481 - jwst.ami.leastsqnrm - INFO - flatimg (4761,)
2026-04-15 20:15:25,481 - jwst.ami.leastsqnrm - INFO -
2026-04-15 20:15:25,482 - jwst.ami.leastsqnrm - INFO - type(dqm) <class 'numpy.ndarray'>
2026-04-15 20:15:25,482 - jwst.ami.leastsqnrm - INFO - type(nanlist) <class 'tuple'>, len=1
2026-04-15 20:15:25,483 - jwst.ami.leastsqnrm - INFO - number of nanlist pixels: 37 items
2026-04-15 20:15:25,483 - jwst.ami.leastsqnrm - INFO - 37 DO_NOT_USE pixels found in data slice
2026-04-15 20:15:25,484 - jwst.ami.leastsqnrm - INFO - flatimg (4724,) after deleting 37
2026-04-15 20:15:25,485 - jwst.ami.leastsqnrm - INFO - flatmodel_nan (4761, 44)
2026-04-15 20:15:25,485 - jwst.ami.leastsqnrm - INFO - flatmodel (4724, 44)
2026-04-15 20:15:25,485 - jwst.ami.leastsqnrm - INFO - difference 37
2026-04-15 20:15:25,486 - jwst.ami.leastsqnrm - INFO - flat model dimensions (4724, 44)
2026-04-15 20:15:25,486 - jwst.ami.leastsqnrm - INFO - flat image dimensions (4724,)
2026-04-15 20:15:25,489 - jwst.ami.leastsqnrm - INFO - data flux 2.7321555e+06
2026-04-15 20:15:25,489 - jwst.ami.leastsqnrm - INFO - flat model dimensions (4724, 44)
2026-04-15 20:15:25,489 - jwst.ami.leastsqnrm - INFO - model transpose dimensions (44, 4724)
2026-04-15 20:15:25,490 - jwst.ami.leastsqnrm - INFO - flat image dimensions (4724,)
2026-04-15 20:15:25,490 - jwst.ami.leastsqnrm - INFO - transpose * image data dimensions (44,)
2026-04-15 20:15:25,491 - jwst.ami.leastsqnrm - INFO - flat img * transpose dimensions (44, 44)
2026-04-15 20:15:25,491 - jwst.ami.leastsqnrm - INFO - linearfit not attempted, no covariances saved.
2026-04-15 20:15:25,493 - jwst.ami.nrm_core - INFO - Fitting fringes for iteration 32 of 69
2026-04-15 20:15:26,547 - jwst.ami.leastsqnrm - INFO - fringefitting.leastsqnrm.matrix_operations():
2026-04-15 20:15:26,547 - jwst.ami.leastsqnrm - INFO - img (69, 69)
2026-04-15 20:15:26,548 - jwst.ami.leastsqnrm - INFO - L x W = 69 x 69 = 4761
2026-04-15 20:15:26,548 - jwst.ami.leastsqnrm - INFO - flatimg (4761,)
2026-04-15 20:15:26,549 - jwst.ami.leastsqnrm - INFO -
2026-04-15 20:15:26,549 - jwst.ami.leastsqnrm - INFO - type(dqm) <class 'numpy.ndarray'>
2026-04-15 20:15:26,550 - jwst.ami.leastsqnrm - INFO - type(nanlist) <class 'tuple'>, len=1
2026-04-15 20:15:26,550 - jwst.ami.leastsqnrm - INFO - number of nanlist pixels: 37 items
2026-04-15 20:15:26,550 - jwst.ami.leastsqnrm - INFO - 37 DO_NOT_USE pixels found in data slice
2026-04-15 20:15:26,551 - jwst.ami.leastsqnrm - INFO - flatimg (4724,) after deleting 37
2026-04-15 20:15:26,552 - jwst.ami.leastsqnrm - INFO - flatmodel_nan (4761, 44)
2026-04-15 20:15:26,553 - jwst.ami.leastsqnrm - INFO - flatmodel (4724, 44)
2026-04-15 20:15:26,553 - jwst.ami.leastsqnrm - INFO - difference 37
2026-04-15 20:15:26,553 - jwst.ami.leastsqnrm - INFO - flat model dimensions (4724, 44)
2026-04-15 20:15:26,554 - jwst.ami.leastsqnrm - INFO - flat image dimensions (4724,)
2026-04-15 20:15:26,556 - jwst.ami.leastsqnrm - INFO - data flux 2.7600532e+06
2026-04-15 20:15:26,557 - jwst.ami.leastsqnrm - INFO - flat model dimensions (4724, 44)
2026-04-15 20:15:26,557 - jwst.ami.leastsqnrm - INFO - model transpose dimensions (44, 4724)
2026-04-15 20:15:26,557 - jwst.ami.leastsqnrm - INFO - flat image dimensions (4724,)
2026-04-15 20:15:26,558 - jwst.ami.leastsqnrm - INFO - transpose * image data dimensions (44,)
2026-04-15 20:15:26,559 - jwst.ami.leastsqnrm - INFO - flat img * transpose dimensions (44, 44)
2026-04-15 20:15:26,559 - jwst.ami.leastsqnrm - INFO - linearfit not attempted, no covariances saved.
2026-04-15 20:15:26,561 - jwst.ami.nrm_core - INFO - Fitting fringes for iteration 33 of 69
2026-04-15 20:15:27,622 - jwst.ami.leastsqnrm - INFO - fringefitting.leastsqnrm.matrix_operations():
2026-04-15 20:15:27,623 - jwst.ami.leastsqnrm - INFO - img (69, 69)
2026-04-15 20:15:27,623 - jwst.ami.leastsqnrm - INFO - L x W = 69 x 69 = 4761
2026-04-15 20:15:27,624 - jwst.ami.leastsqnrm - INFO - flatimg (4761,)
2026-04-15 20:15:27,624 - jwst.ami.leastsqnrm - INFO -
2026-04-15 20:15:27,625 - jwst.ami.leastsqnrm - INFO - type(dqm) <class 'numpy.ndarray'>
2026-04-15 20:15:27,625 - jwst.ami.leastsqnrm - INFO - type(nanlist) <class 'tuple'>, len=1
2026-04-15 20:15:27,626 - jwst.ami.leastsqnrm - INFO - number of nanlist pixels: 37 items
2026-04-15 20:15:27,626 - jwst.ami.leastsqnrm - INFO - 37 DO_NOT_USE pixels found in data slice
2026-04-15 20:15:27,627 - jwst.ami.leastsqnrm - INFO - flatimg (4724,) after deleting 37
2026-04-15 20:15:27,627 - jwst.ami.leastsqnrm - INFO - flatmodel_nan (4761, 44)
2026-04-15 20:15:27,628 - jwst.ami.leastsqnrm - INFO - flatmodel (4724, 44)
2026-04-15 20:15:27,628 - jwst.ami.leastsqnrm - INFO - difference 37
2026-04-15 20:15:27,629 - jwst.ami.leastsqnrm - INFO - flat model dimensions (4724, 44)
2026-04-15 20:15:27,629 - jwst.ami.leastsqnrm - INFO - flat image dimensions (4724,)
2026-04-15 20:15:27,632 - jwst.ami.leastsqnrm - INFO - data flux 2.7915135e+06
2026-04-15 20:15:27,632 - jwst.ami.leastsqnrm - INFO - flat model dimensions (4724, 44)
2026-04-15 20:15:27,632 - jwst.ami.leastsqnrm - INFO - model transpose dimensions (44, 4724)
2026-04-15 20:15:27,633 - jwst.ami.leastsqnrm - INFO - flat image dimensions (4724,)
2026-04-15 20:15:27,633 - jwst.ami.leastsqnrm - INFO - transpose * image data dimensions (44,)
2026-04-15 20:15:27,634 - jwst.ami.leastsqnrm - INFO - flat img * transpose dimensions (44, 44)
2026-04-15 20:15:27,634 - jwst.ami.leastsqnrm - INFO - linearfit not attempted, no covariances saved.
2026-04-15 20:15:27,636 - jwst.ami.nrm_core - INFO - Fitting fringes for iteration 34 of 69
2026-04-15 20:15:28,695 - jwst.ami.leastsqnrm - INFO - fringefitting.leastsqnrm.matrix_operations():
2026-04-15 20:15:28,696 - jwst.ami.leastsqnrm - INFO - img (69, 69)
2026-04-15 20:15:28,696 - jwst.ami.leastsqnrm - INFO - L x W = 69 x 69 = 4761
2026-04-15 20:15:28,697 - jwst.ami.leastsqnrm - INFO - flatimg (4761,)
2026-04-15 20:15:28,697 - jwst.ami.leastsqnrm - INFO -
2026-04-15 20:15:28,697 - jwst.ami.leastsqnrm - INFO - type(dqm) <class 'numpy.ndarray'>
2026-04-15 20:15:28,698 - jwst.ami.leastsqnrm - INFO - type(nanlist) <class 'tuple'>, len=1
2026-04-15 20:15:28,698 - jwst.ami.leastsqnrm - INFO - number of nanlist pixels: 36 items
2026-04-15 20:15:28,699 - jwst.ami.leastsqnrm - INFO - 36 DO_NOT_USE pixels found in data slice
2026-04-15 20:15:28,700 - jwst.ami.leastsqnrm - INFO - flatimg (4725,) after deleting 36
2026-04-15 20:15:28,700 - jwst.ami.leastsqnrm - INFO - flatmodel_nan (4761, 44)
2026-04-15 20:15:28,701 - jwst.ami.leastsqnrm - INFO - flatmodel (4725, 44)
2026-04-15 20:15:28,701 - jwst.ami.leastsqnrm - INFO - difference 36
2026-04-15 20:15:28,702 - jwst.ami.leastsqnrm - INFO - flat model dimensions (4725, 44)
2026-04-15 20:15:28,702 - jwst.ami.leastsqnrm - INFO - flat image dimensions (4725,)
2026-04-15 20:15:28,704 - jwst.ami.leastsqnrm - INFO - data flux 2.717814e+06
2026-04-15 20:15:28,705 - jwst.ami.leastsqnrm - INFO - flat model dimensions (4725, 44)
2026-04-15 20:15:28,705 - jwst.ami.leastsqnrm - INFO - model transpose dimensions (44, 4725)
2026-04-15 20:15:28,706 - jwst.ami.leastsqnrm - INFO - flat image dimensions (4725,)
2026-04-15 20:15:28,707 - jwst.ami.leastsqnrm - INFO - transpose * image data dimensions (44,)
2026-04-15 20:15:28,707 - jwst.ami.leastsqnrm - INFO - flat img * transpose dimensions (44, 44)
2026-04-15 20:15:28,707 - jwst.ami.leastsqnrm - INFO - linearfit not attempted, no covariances saved.
2026-04-15 20:15:28,709 - jwst.ami.nrm_core - INFO - Fitting fringes for iteration 35 of 69
2026-04-15 20:15:29,771 - jwst.ami.leastsqnrm - INFO - fringefitting.leastsqnrm.matrix_operations():
2026-04-15 20:15:29,772 - jwst.ami.leastsqnrm - INFO - img (69, 69)
2026-04-15 20:15:29,772 - jwst.ami.leastsqnrm - INFO - L x W = 69 x 69 = 4761
2026-04-15 20:15:29,773 - jwst.ami.leastsqnrm - INFO - flatimg (4761,)
2026-04-15 20:15:29,773 - jwst.ami.leastsqnrm - INFO -
2026-04-15 20:15:29,774 - jwst.ami.leastsqnrm - INFO - type(dqm) <class 'numpy.ndarray'>
2026-04-15 20:15:29,774 - jwst.ami.leastsqnrm - INFO - type(nanlist) <class 'tuple'>, len=1
2026-04-15 20:15:29,774 - jwst.ami.leastsqnrm - INFO - number of nanlist pixels: 37 items
2026-04-15 20:15:29,775 - jwst.ami.leastsqnrm - INFO - 37 DO_NOT_USE pixels found in data slice
2026-04-15 20:15:29,775 - jwst.ami.leastsqnrm - INFO - flatimg (4724,) after deleting 37
2026-04-15 20:15:29,776 - jwst.ami.leastsqnrm - INFO - flatmodel_nan (4761, 44)
2026-04-15 20:15:29,777 - jwst.ami.leastsqnrm - INFO - flatmodel (4724, 44)
2026-04-15 20:15:29,778 - jwst.ami.leastsqnrm - INFO - difference 37
2026-04-15 20:15:29,778 - jwst.ami.leastsqnrm - INFO - flat model dimensions (4724, 44)
2026-04-15 20:15:29,778 - jwst.ami.leastsqnrm - INFO - flat image dimensions (4724,)
2026-04-15 20:15:29,781 - jwst.ami.leastsqnrm - INFO - data flux 2.7261482e+06
2026-04-15 20:15:29,781 - jwst.ami.leastsqnrm - INFO - flat model dimensions (4724, 44)
2026-04-15 20:15:29,781 - jwst.ami.leastsqnrm - INFO - model transpose dimensions (44, 4724)
2026-04-15 20:15:29,782 - jwst.ami.leastsqnrm - INFO - flat image dimensions (4724,)
2026-04-15 20:15:29,782 - jwst.ami.leastsqnrm - INFO - transpose * image data dimensions (44,)
2026-04-15 20:15:29,783 - jwst.ami.leastsqnrm - INFO - flat img * transpose dimensions (44, 44)
2026-04-15 20:15:29,783 - jwst.ami.leastsqnrm - INFO - linearfit not attempted, no covariances saved.
2026-04-15 20:15:29,785 - jwst.ami.nrm_core - INFO - Fitting fringes for iteration 36 of 69
2026-04-15 20:15:30,854 - jwst.ami.leastsqnrm - INFO - fringefitting.leastsqnrm.matrix_operations():
2026-04-15 20:15:30,854 - jwst.ami.leastsqnrm - INFO - img (69, 69)
2026-04-15 20:15:30,855 - jwst.ami.leastsqnrm - INFO - L x W = 69 x 69 = 4761
2026-04-15 20:15:30,855 - jwst.ami.leastsqnrm - INFO - flatimg (4761,)
2026-04-15 20:15:30,856 - jwst.ami.leastsqnrm - INFO -
2026-04-15 20:15:30,856 - jwst.ami.leastsqnrm - INFO - type(dqm) <class 'numpy.ndarray'>
2026-04-15 20:15:30,856 - jwst.ami.leastsqnrm - INFO - type(nanlist) <class 'tuple'>, len=1
2026-04-15 20:15:30,857 - jwst.ami.leastsqnrm - INFO - number of nanlist pixels: 36 items
2026-04-15 20:15:30,857 - jwst.ami.leastsqnrm - INFO - 36 DO_NOT_USE pixels found in data slice
2026-04-15 20:15:30,858 - jwst.ami.leastsqnrm - INFO - flatimg (4725,) after deleting 36
2026-04-15 20:15:30,859 - jwst.ami.leastsqnrm - INFO - flatmodel_nan (4761, 44)
2026-04-15 20:15:30,859 - jwst.ami.leastsqnrm - INFO - flatmodel (4725, 44)
2026-04-15 20:15:30,860 - jwst.ami.leastsqnrm - INFO - difference 36
2026-04-15 20:15:30,860 - jwst.ami.leastsqnrm - INFO - flat model dimensions (4725, 44)
2026-04-15 20:15:30,860 - jwst.ami.leastsqnrm - INFO - flat image dimensions (4725,)
2026-04-15 20:15:30,863 - jwst.ami.leastsqnrm - INFO - data flux 2.748872e+06
2026-04-15 20:15:30,863 - jwst.ami.leastsqnrm - INFO - flat model dimensions (4725, 44)
2026-04-15 20:15:30,864 - jwst.ami.leastsqnrm - INFO - model transpose dimensions (44, 4725)
2026-04-15 20:15:30,864 - jwst.ami.leastsqnrm - INFO - flat image dimensions (4725,)
2026-04-15 20:15:30,865 - jwst.ami.leastsqnrm - INFO - transpose * image data dimensions (44,)
2026-04-15 20:15:30,865 - jwst.ami.leastsqnrm - INFO - flat img * transpose dimensions (44, 44)
2026-04-15 20:15:30,866 - jwst.ami.leastsqnrm - INFO - linearfit not attempted, no covariances saved.
2026-04-15 20:15:30,867 - jwst.ami.nrm_core - INFO - Fitting fringes for iteration 37 of 69
2026-04-15 20:15:31,928 - jwst.ami.leastsqnrm - INFO - fringefitting.leastsqnrm.matrix_operations():
2026-04-15 20:15:31,929 - jwst.ami.leastsqnrm - INFO - img (69, 69)
2026-04-15 20:15:31,929 - jwst.ami.leastsqnrm - INFO - L x W = 69 x 69 = 4761
2026-04-15 20:15:31,930 - jwst.ami.leastsqnrm - INFO - flatimg (4761,)
2026-04-15 20:15:31,930 - jwst.ami.leastsqnrm - INFO -
2026-04-15 20:15:31,931 - jwst.ami.leastsqnrm - INFO - type(dqm) <class 'numpy.ndarray'>
2026-04-15 20:15:31,931 - jwst.ami.leastsqnrm - INFO - type(nanlist) <class 'tuple'>, len=1
2026-04-15 20:15:31,931 - jwst.ami.leastsqnrm - INFO - number of nanlist pixels: 36 items
2026-04-15 20:15:31,932 - jwst.ami.leastsqnrm - INFO - 36 DO_NOT_USE pixels found in data slice
2026-04-15 20:15:31,932 - jwst.ami.leastsqnrm - INFO - flatimg (4725,) after deleting 36
2026-04-15 20:15:31,933 - jwst.ami.leastsqnrm - INFO - flatmodel_nan (4761, 44)
2026-04-15 20:15:31,934 - jwst.ami.leastsqnrm - INFO - flatmodel (4725, 44)
2026-04-15 20:15:31,934 - jwst.ami.leastsqnrm - INFO - difference 36
2026-04-15 20:15:31,934 - jwst.ami.leastsqnrm - INFO - flat model dimensions (4725, 44)
2026-04-15 20:15:31,935 - jwst.ami.leastsqnrm - INFO - flat image dimensions (4725,)
2026-04-15 20:15:31,937 - jwst.ami.leastsqnrm - INFO - data flux 2.7260495e+06
2026-04-15 20:15:31,938 - jwst.ami.leastsqnrm - INFO - flat model dimensions (4725, 44)
2026-04-15 20:15:31,938 - jwst.ami.leastsqnrm - INFO - model transpose dimensions (44, 4725)
2026-04-15 20:15:31,939 - jwst.ami.leastsqnrm - INFO - flat image dimensions (4725,)
2026-04-15 20:15:31,939 - jwst.ami.leastsqnrm - INFO - transpose * image data dimensions (44,)
2026-04-15 20:15:31,939 - jwst.ami.leastsqnrm - INFO - flat img * transpose dimensions (44, 44)
2026-04-15 20:15:31,940 - jwst.ami.leastsqnrm - INFO - linearfit not attempted, no covariances saved.
2026-04-15 20:15:31,941 - jwst.ami.nrm_core - INFO - Fitting fringes for iteration 38 of 69
2026-04-15 20:15:33,000 - jwst.ami.leastsqnrm - INFO - fringefitting.leastsqnrm.matrix_operations():
2026-04-15 20:15:33,000 - jwst.ami.leastsqnrm - INFO - img (69, 69)
2026-04-15 20:15:33,001 - jwst.ami.leastsqnrm - INFO - L x W = 69 x 69 = 4761
2026-04-15 20:15:33,001 - jwst.ami.leastsqnrm - INFO - flatimg (4761,)
2026-04-15 20:15:33,002 - jwst.ami.leastsqnrm - INFO -
2026-04-15 20:15:33,002 - jwst.ami.leastsqnrm - INFO - type(dqm) <class 'numpy.ndarray'>
2026-04-15 20:15:33,003 - jwst.ami.leastsqnrm - INFO - type(nanlist) <class 'tuple'>, len=1
2026-04-15 20:15:33,003 - jwst.ami.leastsqnrm - INFO - number of nanlist pixels: 36 items
2026-04-15 20:15:33,003 - jwst.ami.leastsqnrm - INFO - 36 DO_NOT_USE pixels found in data slice
2026-04-15 20:15:33,004 - jwst.ami.leastsqnrm - INFO - flatimg (4725,) after deleting 36
2026-04-15 20:15:33,005 - jwst.ami.leastsqnrm - INFO - flatmodel_nan (4761, 44)
2026-04-15 20:15:33,005 - jwst.ami.leastsqnrm - INFO - flatmodel (4725, 44)
2026-04-15 20:15:33,005 - jwst.ami.leastsqnrm - INFO - difference 36
2026-04-15 20:15:33,006 - jwst.ami.leastsqnrm - INFO - flat model dimensions (4725, 44)
2026-04-15 20:15:33,006 - jwst.ami.leastsqnrm - INFO - flat image dimensions (4725,)
2026-04-15 20:15:33,009 - jwst.ami.leastsqnrm - INFO - data flux 2.7417185e+06
2026-04-15 20:15:33,009 - jwst.ami.leastsqnrm - INFO - flat model dimensions (4725, 44)
2026-04-15 20:15:33,010 - jwst.ami.leastsqnrm - INFO - model transpose dimensions (44, 4725)
2026-04-15 20:15:33,010 - jwst.ami.leastsqnrm - INFO - flat image dimensions (4725,)
2026-04-15 20:15:33,010 - jwst.ami.leastsqnrm - INFO - transpose * image data dimensions (44,)
2026-04-15 20:15:33,011 - jwst.ami.leastsqnrm - INFO - flat img * transpose dimensions (44, 44)
2026-04-15 20:15:33,011 - jwst.ami.leastsqnrm - INFO - linearfit not attempted, no covariances saved.
2026-04-15 20:15:33,013 - jwst.ami.nrm_core - INFO - Fitting fringes for iteration 39 of 69
2026-04-15 20:15:34,074 - jwst.ami.leastsqnrm - INFO - fringefitting.leastsqnrm.matrix_operations():
2026-04-15 20:15:34,074 - jwst.ami.leastsqnrm - INFO - img (69, 69)
2026-04-15 20:15:34,075 - jwst.ami.leastsqnrm - INFO - L x W = 69 x 69 = 4761
2026-04-15 20:15:34,075 - jwst.ami.leastsqnrm - INFO - flatimg (4761,)
2026-04-15 20:15:34,076 - jwst.ami.leastsqnrm - INFO -
2026-04-15 20:15:34,076 - jwst.ami.leastsqnrm - INFO - type(dqm) <class 'numpy.ndarray'>
2026-04-15 20:15:34,076 - jwst.ami.leastsqnrm - INFO - type(nanlist) <class 'tuple'>, len=1
2026-04-15 20:15:34,077 - jwst.ami.leastsqnrm - INFO - number of nanlist pixels: 37 items
2026-04-15 20:15:34,077 - jwst.ami.leastsqnrm - INFO - 37 DO_NOT_USE pixels found in data slice
2026-04-15 20:15:34,078 - jwst.ami.leastsqnrm - INFO - flatimg (4724,) after deleting 37
2026-04-15 20:15:34,078 - jwst.ami.leastsqnrm - INFO - flatmodel_nan (4761, 44)
2026-04-15 20:15:34,079 - jwst.ami.leastsqnrm - INFO - flatmodel (4724, 44)
2026-04-15 20:15:34,079 - jwst.ami.leastsqnrm - INFO - difference 37
2026-04-15 20:15:34,080 - jwst.ami.leastsqnrm - INFO - flat model dimensions (4724, 44)
2026-04-15 20:15:34,080 - jwst.ami.leastsqnrm - INFO - flat image dimensions (4724,)
2026-04-15 20:15:34,083 - jwst.ami.leastsqnrm - INFO - data flux 2.7865715e+06
2026-04-15 20:15:34,084 - jwst.ami.leastsqnrm - INFO - flat model dimensions (4724, 44)
2026-04-15 20:15:34,084 - jwst.ami.leastsqnrm - INFO - model transpose dimensions (44, 4724)
2026-04-15 20:15:34,085 - jwst.ami.leastsqnrm - INFO - flat image dimensions (4724,)
2026-04-15 20:15:34,085 - jwst.ami.leastsqnrm - INFO - transpose * image data dimensions (44,)
2026-04-15 20:15:34,086 - jwst.ami.leastsqnrm - INFO - flat img * transpose dimensions (44, 44)
2026-04-15 20:15:34,086 - jwst.ami.leastsqnrm - INFO - linearfit not attempted, no covariances saved.
2026-04-15 20:15:34,087 - jwst.ami.nrm_core - INFO - Fitting fringes for iteration 40 of 69
2026-04-15 20:15:35,152 - jwst.ami.leastsqnrm - INFO - fringefitting.leastsqnrm.matrix_operations():
2026-04-15 20:15:35,153 - jwst.ami.leastsqnrm - INFO - img (69, 69)
2026-04-15 20:15:35,153 - jwst.ami.leastsqnrm - INFO - L x W = 69 x 69 = 4761
2026-04-15 20:15:35,153 - jwst.ami.leastsqnrm - INFO - flatimg (4761,)
2026-04-15 20:15:35,154 - jwst.ami.leastsqnrm - INFO -
2026-04-15 20:15:35,154 - jwst.ami.leastsqnrm - INFO - type(dqm) <class 'numpy.ndarray'>
2026-04-15 20:15:35,155 - jwst.ami.leastsqnrm - INFO - type(nanlist) <class 'tuple'>, len=1
2026-04-15 20:15:35,155 - jwst.ami.leastsqnrm - INFO - number of nanlist pixels: 36 items
2026-04-15 20:15:35,156 - jwst.ami.leastsqnrm - INFO - 36 DO_NOT_USE pixels found in data slice
2026-04-15 20:15:35,156 - jwst.ami.leastsqnrm - INFO - flatimg (4725,) after deleting 36
2026-04-15 20:15:35,157 - jwst.ami.leastsqnrm - INFO - flatmodel_nan (4761, 44)
2026-04-15 20:15:35,157 - jwst.ami.leastsqnrm - INFO - flatmodel (4725, 44)
2026-04-15 20:15:35,157 - jwst.ami.leastsqnrm - INFO - difference 36
2026-04-15 20:15:35,158 - jwst.ami.leastsqnrm - INFO - flat model dimensions (4725, 44)
2026-04-15 20:15:35,158 - jwst.ami.leastsqnrm - INFO - flat image dimensions (4725,)
2026-04-15 20:15:35,161 - jwst.ami.leastsqnrm - INFO - data flux 2.7956372e+06
2026-04-15 20:15:35,161 - jwst.ami.leastsqnrm - INFO - flat model dimensions (4725, 44)
2026-04-15 20:15:35,162 - jwst.ami.leastsqnrm - INFO - model transpose dimensions (44, 4725)
2026-04-15 20:15:35,162 - jwst.ami.leastsqnrm - INFO - flat image dimensions (4725,)
2026-04-15 20:15:35,163 - jwst.ami.leastsqnrm - INFO - transpose * image data dimensions (44,)
2026-04-15 20:15:35,163 - jwst.ami.leastsqnrm - INFO - flat img * transpose dimensions (44, 44)
2026-04-15 20:15:35,164 - jwst.ami.leastsqnrm - INFO - linearfit not attempted, no covariances saved.
2026-04-15 20:15:35,165 - jwst.ami.nrm_core - INFO - Fitting fringes for iteration 41 of 69
2026-04-15 20:15:36,230 - jwst.ami.leastsqnrm - INFO - fringefitting.leastsqnrm.matrix_operations():
2026-04-15 20:15:36,231 - jwst.ami.leastsqnrm - INFO - img (69, 69)
2026-04-15 20:15:36,232 - jwst.ami.leastsqnrm - INFO - L x W = 69 x 69 = 4761
2026-04-15 20:15:36,232 - jwst.ami.leastsqnrm - INFO - flatimg (4761,)
2026-04-15 20:15:36,232 - jwst.ami.leastsqnrm - INFO -
2026-04-15 20:15:36,233 - jwst.ami.leastsqnrm - INFO - type(dqm) <class 'numpy.ndarray'>
2026-04-15 20:15:36,233 - jwst.ami.leastsqnrm - INFO - type(nanlist) <class 'tuple'>, len=1
2026-04-15 20:15:36,234 - jwst.ami.leastsqnrm - INFO - number of nanlist pixels: 37 items
2026-04-15 20:15:36,234 - jwst.ami.leastsqnrm - INFO - 37 DO_NOT_USE pixels found in data slice
2026-04-15 20:15:36,235 - jwst.ami.leastsqnrm - INFO - flatimg (4724,) after deleting 37
2026-04-15 20:15:36,235 - jwst.ami.leastsqnrm - INFO - flatmodel_nan (4761, 44)
2026-04-15 20:15:36,236 - jwst.ami.leastsqnrm - INFO - flatmodel (4724, 44)
2026-04-15 20:15:36,236 - jwst.ami.leastsqnrm - INFO - difference 37
2026-04-15 20:15:36,237 - jwst.ami.leastsqnrm - INFO - flat model dimensions (4724, 44)
2026-04-15 20:15:36,237 - jwst.ami.leastsqnrm - INFO - flat image dimensions (4724,)
2026-04-15 20:15:36,240 - jwst.ami.leastsqnrm - INFO - data flux 2.6973695e+06
2026-04-15 20:15:36,240 - jwst.ami.leastsqnrm - INFO - flat model dimensions (4724, 44)
2026-04-15 20:15:36,241 - jwst.ami.leastsqnrm - INFO - model transpose dimensions (44, 4724)
2026-04-15 20:15:36,241 - jwst.ami.leastsqnrm - INFO - flat image dimensions (4724,)
2026-04-15 20:15:36,241 - jwst.ami.leastsqnrm - INFO - transpose * image data dimensions (44,)
2026-04-15 20:15:36,242 - jwst.ami.leastsqnrm - INFO - flat img * transpose dimensions (44, 44)
2026-04-15 20:15:36,242 - jwst.ami.leastsqnrm - INFO - linearfit not attempted, no covariances saved.
2026-04-15 20:15:36,244 - jwst.ami.nrm_core - INFO - Fitting fringes for iteration 42 of 69
2026-04-15 20:15:37,310 - jwst.ami.leastsqnrm - INFO - fringefitting.leastsqnrm.matrix_operations():
2026-04-15 20:15:37,310 - jwst.ami.leastsqnrm - INFO - img (69, 69)
2026-04-15 20:15:37,311 - jwst.ami.leastsqnrm - INFO - L x W = 69 x 69 = 4761
2026-04-15 20:15:37,311 - jwst.ami.leastsqnrm - INFO - flatimg (4761,)
2026-04-15 20:15:37,312 - jwst.ami.leastsqnrm - INFO -
2026-04-15 20:15:37,312 - jwst.ami.leastsqnrm - INFO - type(dqm) <class 'numpy.ndarray'>
2026-04-15 20:15:37,312 - jwst.ami.leastsqnrm - INFO - type(nanlist) <class 'tuple'>, len=1
2026-04-15 20:15:37,313 - jwst.ami.leastsqnrm - INFO - number of nanlist pixels: 36 items
2026-04-15 20:15:37,313 - jwst.ami.leastsqnrm - INFO - 36 DO_NOT_USE pixels found in data slice
2026-04-15 20:15:37,314 - jwst.ami.leastsqnrm - INFO - flatimg (4725,) after deleting 36
2026-04-15 20:15:37,315 - jwst.ami.leastsqnrm - INFO - flatmodel_nan (4761, 44)
2026-04-15 20:15:37,315 - jwst.ami.leastsqnrm - INFO - flatmodel (4725, 44)
2026-04-15 20:15:37,316 - jwst.ami.leastsqnrm - INFO - difference 36
2026-04-15 20:15:37,316 - jwst.ami.leastsqnrm - INFO - flat model dimensions (4725, 44)
2026-04-15 20:15:37,316 - jwst.ami.leastsqnrm - INFO - flat image dimensions (4725,)
2026-04-15 20:15:37,319 - jwst.ami.leastsqnrm - INFO - data flux 2.710892e+06
2026-04-15 20:15:37,319 - jwst.ami.leastsqnrm - INFO - flat model dimensions (4725, 44)
2026-04-15 20:15:37,320 - jwst.ami.leastsqnrm - INFO - model transpose dimensions (44, 4725)
2026-04-15 20:15:37,320 - jwst.ami.leastsqnrm - INFO - flat image dimensions (4725,)
2026-04-15 20:15:37,321 - jwst.ami.leastsqnrm - INFO - transpose * image data dimensions (44,)
2026-04-15 20:15:37,321 - jwst.ami.leastsqnrm - INFO - flat img * transpose dimensions (44, 44)
2026-04-15 20:15:37,322 - jwst.ami.leastsqnrm - INFO - linearfit not attempted, no covariances saved.
2026-04-15 20:15:37,323 - jwst.ami.nrm_core - INFO - Fitting fringes for iteration 43 of 69
2026-04-15 20:15:38,384 - jwst.ami.leastsqnrm - INFO - fringefitting.leastsqnrm.matrix_operations():
2026-04-15 20:15:38,385 - jwst.ami.leastsqnrm - INFO - img (69, 69)
2026-04-15 20:15:38,385 - jwst.ami.leastsqnrm - INFO - L x W = 69 x 69 = 4761
2026-04-15 20:15:38,386 - jwst.ami.leastsqnrm - INFO - flatimg (4761,)
2026-04-15 20:15:38,386 - jwst.ami.leastsqnrm - INFO -
2026-04-15 20:15:38,386 - jwst.ami.leastsqnrm - INFO - type(dqm) <class 'numpy.ndarray'>
2026-04-15 20:15:38,387 - jwst.ami.leastsqnrm - INFO - type(nanlist) <class 'tuple'>, len=1
2026-04-15 20:15:38,387 - jwst.ami.leastsqnrm - INFO - number of nanlist pixels: 36 items
2026-04-15 20:15:38,388 - jwst.ami.leastsqnrm - INFO - 36 DO_NOT_USE pixels found in data slice
2026-04-15 20:15:38,388 - jwst.ami.leastsqnrm - INFO - flatimg (4725,) after deleting 36
2026-04-15 20:15:38,389 - jwst.ami.leastsqnrm - INFO - flatmodel_nan (4761, 44)
2026-04-15 20:15:38,389 - jwst.ami.leastsqnrm - INFO - flatmodel (4725, 44)
2026-04-15 20:15:38,390 - jwst.ami.leastsqnrm - INFO - difference 36
2026-04-15 20:15:38,390 - jwst.ami.leastsqnrm - INFO - flat model dimensions (4725, 44)
2026-04-15 20:15:38,391 - jwst.ami.leastsqnrm - INFO - flat image dimensions (4725,)
2026-04-15 20:15:38,393 - jwst.ami.leastsqnrm - INFO - data flux 2.762559e+06
2026-04-15 20:15:38,394 - jwst.ami.leastsqnrm - INFO - flat model dimensions (4725, 44)
2026-04-15 20:15:38,394 - jwst.ami.leastsqnrm - INFO - model transpose dimensions (44, 4725)
2026-04-15 20:15:38,394 - jwst.ami.leastsqnrm - INFO - flat image dimensions (4725,)
2026-04-15 20:15:38,395 - jwst.ami.leastsqnrm - INFO - transpose * image data dimensions (44,)
2026-04-15 20:15:38,395 - jwst.ami.leastsqnrm - INFO - flat img * transpose dimensions (44, 44)
2026-04-15 20:15:38,396 - jwst.ami.leastsqnrm - INFO - linearfit not attempted, no covariances saved.
2026-04-15 20:15:38,397 - jwst.ami.nrm_core - INFO - Fitting fringes for iteration 44 of 69
2026-04-15 20:15:39,453 - jwst.ami.leastsqnrm - INFO - fringefitting.leastsqnrm.matrix_operations():
2026-04-15 20:15:39,454 - jwst.ami.leastsqnrm - INFO - img (69, 69)
2026-04-15 20:15:39,454 - jwst.ami.leastsqnrm - INFO - L x W = 69 x 69 = 4761
2026-04-15 20:15:39,455 - jwst.ami.leastsqnrm - INFO - flatimg (4761,)
2026-04-15 20:15:39,455 - jwst.ami.leastsqnrm - INFO -
2026-04-15 20:15:39,456 - jwst.ami.leastsqnrm - INFO - type(dqm) <class 'numpy.ndarray'>
2026-04-15 20:15:39,456 - jwst.ami.leastsqnrm - INFO - type(nanlist) <class 'tuple'>, len=1
2026-04-15 20:15:39,456 - jwst.ami.leastsqnrm - INFO - number of nanlist pixels: 39 items
2026-04-15 20:15:39,457 - jwst.ami.leastsqnrm - INFO - 39 DO_NOT_USE pixels found in data slice
2026-04-15 20:15:39,457 - jwst.ami.leastsqnrm - INFO - flatimg (4722,) after deleting 39
2026-04-15 20:15:39,458 - jwst.ami.leastsqnrm - INFO - flatmodel_nan (4761, 44)
2026-04-15 20:15:39,459 - jwst.ami.leastsqnrm - INFO - flatmodel (4722, 44)
2026-04-15 20:15:39,459 - jwst.ami.leastsqnrm - INFO - difference 39
2026-04-15 20:15:39,460 - jwst.ami.leastsqnrm - INFO - flat model dimensions (4722, 44)
2026-04-15 20:15:39,460 - jwst.ami.leastsqnrm - INFO - flat image dimensions (4722,)
2026-04-15 20:15:39,462 - jwst.ami.leastsqnrm - INFO - data flux 2.7623395e+06
2026-04-15 20:15:39,463 - jwst.ami.leastsqnrm - INFO - flat model dimensions (4722, 44)
2026-04-15 20:15:39,463 - jwst.ami.leastsqnrm - INFO - model transpose dimensions (44, 4722)
2026-04-15 20:15:39,464 - jwst.ami.leastsqnrm - INFO - flat image dimensions (4722,)
2026-04-15 20:15:39,464 - jwst.ami.leastsqnrm - INFO - transpose * image data dimensions (44,)
2026-04-15 20:15:39,465 - jwst.ami.leastsqnrm - INFO - flat img * transpose dimensions (44, 44)
2026-04-15 20:15:39,465 - jwst.ami.leastsqnrm - INFO - linearfit not attempted, no covariances saved.
2026-04-15 20:15:39,467 - jwst.ami.nrm_core - INFO - Fitting fringes for iteration 45 of 69
2026-04-15 20:15:40,532 - jwst.ami.leastsqnrm - INFO - fringefitting.leastsqnrm.matrix_operations():
2026-04-15 20:15:40,532 - jwst.ami.leastsqnrm - INFO - img (69, 69)
2026-04-15 20:15:40,533 - jwst.ami.leastsqnrm - INFO - L x W = 69 x 69 = 4761
2026-04-15 20:15:40,533 - jwst.ami.leastsqnrm - INFO - flatimg (4761,)
2026-04-15 20:15:40,534 - jwst.ami.leastsqnrm - INFO -
2026-04-15 20:15:40,534 - jwst.ami.leastsqnrm - INFO - type(dqm) <class 'numpy.ndarray'>
2026-04-15 20:15:40,535 - jwst.ami.leastsqnrm - INFO - type(nanlist) <class 'tuple'>, len=1
2026-04-15 20:15:40,535 - jwst.ami.leastsqnrm - INFO - number of nanlist pixels: 36 items
2026-04-15 20:15:40,535 - jwst.ami.leastsqnrm - INFO - 36 DO_NOT_USE pixels found in data slice
2026-04-15 20:15:40,536 - jwst.ami.leastsqnrm - INFO - flatimg (4725,) after deleting 36
2026-04-15 20:15:40,536 - jwst.ami.leastsqnrm - INFO - flatmodel_nan (4761, 44)
2026-04-15 20:15:40,537 - jwst.ami.leastsqnrm - INFO - flatmodel (4725, 44)
2026-04-15 20:15:40,537 - jwst.ami.leastsqnrm - INFO - difference 36
2026-04-15 20:15:40,538 - jwst.ami.leastsqnrm - INFO - flat model dimensions (4725, 44)
2026-04-15 20:15:40,538 - jwst.ami.leastsqnrm - INFO - flat image dimensions (4725,)
2026-04-15 20:15:40,541 - jwst.ami.leastsqnrm - INFO - data flux 2.7701605e+06
2026-04-15 20:15:40,541 - jwst.ami.leastsqnrm - INFO - flat model dimensions (4725, 44)
2026-04-15 20:15:40,542 - jwst.ami.leastsqnrm - INFO - model transpose dimensions (44, 4725)
2026-04-15 20:15:40,542 - jwst.ami.leastsqnrm - INFO - flat image dimensions (4725,)
2026-04-15 20:15:40,543 - jwst.ami.leastsqnrm - INFO - transpose * image data dimensions (44,)
2026-04-15 20:15:40,543 - jwst.ami.leastsqnrm - INFO - flat img * transpose dimensions (44, 44)
2026-04-15 20:15:40,544 - jwst.ami.leastsqnrm - INFO - linearfit not attempted, no covariances saved.
2026-04-15 20:15:40,545 - jwst.ami.nrm_core - INFO - Fitting fringes for iteration 46 of 69
2026-04-15 20:15:41,607 - jwst.ami.leastsqnrm - INFO - fringefitting.leastsqnrm.matrix_operations():
2026-04-15 20:15:41,608 - jwst.ami.leastsqnrm - INFO - img (69, 69)
2026-04-15 20:15:41,608 - jwst.ami.leastsqnrm - INFO - L x W = 69 x 69 = 4761
2026-04-15 20:15:41,609 - jwst.ami.leastsqnrm - INFO - flatimg (4761,)
2026-04-15 20:15:41,609 - jwst.ami.leastsqnrm - INFO -
2026-04-15 20:15:41,610 - jwst.ami.leastsqnrm - INFO - type(dqm) <class 'numpy.ndarray'>
2026-04-15 20:15:41,610 - jwst.ami.leastsqnrm - INFO - type(nanlist) <class 'tuple'>, len=1
2026-04-15 20:15:41,611 - jwst.ami.leastsqnrm - INFO - number of nanlist pixels: 36 items
2026-04-15 20:15:41,611 - jwst.ami.leastsqnrm - INFO - 36 DO_NOT_USE pixels found in data slice
2026-04-15 20:15:41,612 - jwst.ami.leastsqnrm - INFO - flatimg (4725,) after deleting 36
2026-04-15 20:15:41,612 - jwst.ami.leastsqnrm - INFO - flatmodel_nan (4761, 44)
2026-04-15 20:15:41,613 - jwst.ami.leastsqnrm - INFO - flatmodel (4725, 44)
2026-04-15 20:15:41,613 - jwst.ami.leastsqnrm - INFO - difference 36
2026-04-15 20:15:41,614 - jwst.ami.leastsqnrm - INFO - flat model dimensions (4725, 44)
2026-04-15 20:15:41,614 - jwst.ami.leastsqnrm - INFO - flat image dimensions (4725,)
2026-04-15 20:15:41,616 - jwst.ami.leastsqnrm - INFO - data flux 2.7579032e+06
2026-04-15 20:15:41,617 - jwst.ami.leastsqnrm - INFO - flat model dimensions (4725, 44)
2026-04-15 20:15:41,617 - jwst.ami.leastsqnrm - INFO - model transpose dimensions (44, 4725)
2026-04-15 20:15:41,618 - jwst.ami.leastsqnrm - INFO - flat image dimensions (4725,)
2026-04-15 20:15:41,618 - jwst.ami.leastsqnrm - INFO - transpose * image data dimensions (44,)
2026-04-15 20:15:41,619 - jwst.ami.leastsqnrm - INFO - flat img * transpose dimensions (44, 44)
2026-04-15 20:15:41,619 - jwst.ami.leastsqnrm - INFO - linearfit not attempted, no covariances saved.
2026-04-15 20:15:41,620 - jwst.ami.nrm_core - INFO - Fitting fringes for iteration 47 of 69
2026-04-15 20:15:42,687 - jwst.ami.leastsqnrm - INFO - fringefitting.leastsqnrm.matrix_operations():
2026-04-15 20:15:42,687 - jwst.ami.leastsqnrm - INFO - img (69, 69)
2026-04-15 20:15:42,688 - jwst.ami.leastsqnrm - INFO - L x W = 69 x 69 = 4761
2026-04-15 20:15:42,688 - jwst.ami.leastsqnrm - INFO - flatimg (4761,)
2026-04-15 20:15:42,689 - jwst.ami.leastsqnrm - INFO -
2026-04-15 20:15:42,689 - jwst.ami.leastsqnrm - INFO - type(dqm) <class 'numpy.ndarray'>
2026-04-15 20:15:42,690 - jwst.ami.leastsqnrm - INFO - type(nanlist) <class 'tuple'>, len=1
2026-04-15 20:15:42,690 - jwst.ami.leastsqnrm - INFO - number of nanlist pixels: 37 items
2026-04-15 20:15:42,690 - jwst.ami.leastsqnrm - INFO - 37 DO_NOT_USE pixels found in data slice
2026-04-15 20:15:42,691 - jwst.ami.leastsqnrm - INFO - flatimg (4724,) after deleting 37
2026-04-15 20:15:42,692 - jwst.ami.leastsqnrm - INFO - flatmodel_nan (4761, 44)
2026-04-15 20:15:42,692 - jwst.ami.leastsqnrm - INFO - flatmodel (4724, 44)
2026-04-15 20:15:42,693 - jwst.ami.leastsqnrm - INFO - difference 37
2026-04-15 20:15:42,693 - jwst.ami.leastsqnrm - INFO - flat model dimensions (4724, 44)
2026-04-15 20:15:42,694 - jwst.ami.leastsqnrm - INFO - flat image dimensions (4724,)
2026-04-15 20:15:42,696 - jwst.ami.leastsqnrm - INFO - data flux 2.6784835e+06
2026-04-15 20:15:42,697 - jwst.ami.leastsqnrm - INFO - flat model dimensions (4724, 44)
2026-04-15 20:15:42,697 - jwst.ami.leastsqnrm - INFO - model transpose dimensions (44, 4724)
2026-04-15 20:15:42,697 - jwst.ami.leastsqnrm - INFO - flat image dimensions (4724,)
2026-04-15 20:15:42,698 - jwst.ami.leastsqnrm - INFO - transpose * image data dimensions (44,)
2026-04-15 20:15:42,698 - jwst.ami.leastsqnrm - INFO - flat img * transpose dimensions (44, 44)
2026-04-15 20:15:42,699 - jwst.ami.leastsqnrm - INFO - linearfit not attempted, no covariances saved.
2026-04-15 20:15:42,700 - jwst.ami.nrm_core - INFO - Fitting fringes for iteration 48 of 69
2026-04-15 20:15:43,766 - jwst.ami.leastsqnrm - INFO - fringefitting.leastsqnrm.matrix_operations():
2026-04-15 20:15:43,766 - jwst.ami.leastsqnrm - INFO - img (69, 69)
2026-04-15 20:15:43,767 - jwst.ami.leastsqnrm - INFO - L x W = 69 x 69 = 4761
2026-04-15 20:15:43,767 - jwst.ami.leastsqnrm - INFO - flatimg (4761,)
2026-04-15 20:15:43,768 - jwst.ami.leastsqnrm - INFO -
2026-04-15 20:15:43,768 - jwst.ami.leastsqnrm - INFO - type(dqm) <class 'numpy.ndarray'>
2026-04-15 20:15:43,768 - jwst.ami.leastsqnrm - INFO - type(nanlist) <class 'tuple'>, len=1
2026-04-15 20:15:43,769 - jwst.ami.leastsqnrm - INFO - number of nanlist pixels: 36 items
2026-04-15 20:15:43,769 - jwst.ami.leastsqnrm - INFO - 36 DO_NOT_USE pixels found in data slice
2026-04-15 20:15:43,770 - jwst.ami.leastsqnrm - INFO - flatimg (4725,) after deleting 36
2026-04-15 20:15:43,771 - jwst.ami.leastsqnrm - INFO - flatmodel_nan (4761, 44)
2026-04-15 20:15:43,771 - jwst.ami.leastsqnrm - INFO - flatmodel (4725, 44)
2026-04-15 20:15:43,772 - jwst.ami.leastsqnrm - INFO - difference 36
2026-04-15 20:15:43,772 - jwst.ami.leastsqnrm - INFO - flat model dimensions (4725, 44)
2026-04-15 20:15:43,773 - jwst.ami.leastsqnrm - INFO - flat image dimensions (4725,)
2026-04-15 20:15:43,775 - jwst.ami.leastsqnrm - INFO - data flux 2.7557105e+06
2026-04-15 20:15:43,775 - jwst.ami.leastsqnrm - INFO - flat model dimensions (4725, 44)
2026-04-15 20:15:43,776 - jwst.ami.leastsqnrm - INFO - model transpose dimensions (44, 4725)
2026-04-15 20:15:43,776 - jwst.ami.leastsqnrm - INFO - flat image dimensions (4725,)
2026-04-15 20:15:43,777 - jwst.ami.leastsqnrm - INFO - transpose * image data dimensions (44,)
2026-04-15 20:15:43,777 - jwst.ami.leastsqnrm - INFO - flat img * transpose dimensions (44, 44)
2026-04-15 20:15:43,778 - jwst.ami.leastsqnrm - INFO - linearfit not attempted, no covariances saved.
2026-04-15 20:15:43,779 - jwst.ami.nrm_core - INFO - Fitting fringes for iteration 49 of 69
2026-04-15 20:15:44,841 - jwst.ami.leastsqnrm - INFO - fringefitting.leastsqnrm.matrix_operations():
2026-04-15 20:15:44,842 - jwst.ami.leastsqnrm - INFO - img (69, 69)
2026-04-15 20:15:44,842 - jwst.ami.leastsqnrm - INFO - L x W = 69 x 69 = 4761
2026-04-15 20:15:44,843 - jwst.ami.leastsqnrm - INFO - flatimg (4761,)
2026-04-15 20:15:44,843 - jwst.ami.leastsqnrm - INFO -
2026-04-15 20:15:44,844 - jwst.ami.leastsqnrm - INFO - type(dqm) <class 'numpy.ndarray'>
2026-04-15 20:15:44,844 - jwst.ami.leastsqnrm - INFO - type(nanlist) <class 'tuple'>, len=1
2026-04-15 20:15:44,845 - jwst.ami.leastsqnrm - INFO - number of nanlist pixels: 36 items
2026-04-15 20:15:44,845 - jwst.ami.leastsqnrm - INFO - 36 DO_NOT_USE pixels found in data slice
2026-04-15 20:15:44,846 - jwst.ami.leastsqnrm - INFO - flatimg (4725,) after deleting 36
2026-04-15 20:15:44,846 - jwst.ami.leastsqnrm - INFO - flatmodel_nan (4761, 44)
2026-04-15 20:15:44,847 - jwst.ami.leastsqnrm - INFO - flatmodel (4725, 44)
2026-04-15 20:15:44,847 - jwst.ami.leastsqnrm - INFO - difference 36
2026-04-15 20:15:44,847 - jwst.ami.leastsqnrm - INFO - flat model dimensions (4725, 44)
2026-04-15 20:15:44,848 - jwst.ami.leastsqnrm - INFO - flat image dimensions (4725,)
2026-04-15 20:15:44,850 - jwst.ami.leastsqnrm - INFO - data flux 2.721966e+06
2026-04-15 20:15:44,851 - jwst.ami.leastsqnrm - INFO - flat model dimensions (4725, 44)
2026-04-15 20:15:44,851 - jwst.ami.leastsqnrm - INFO - model transpose dimensions (44, 4725)
2026-04-15 20:15:44,852 - jwst.ami.leastsqnrm - INFO - flat image dimensions (4725,)
2026-04-15 20:15:44,852 - jwst.ami.leastsqnrm - INFO - transpose * image data dimensions (44,)
2026-04-15 20:15:44,853 - jwst.ami.leastsqnrm - INFO - flat img * transpose dimensions (44, 44)
2026-04-15 20:15:44,853 - jwst.ami.leastsqnrm - INFO - linearfit not attempted, no covariances saved.
2026-04-15 20:15:44,855 - jwst.ami.nrm_core - INFO - Fitting fringes for iteration 50 of 69
2026-04-15 20:15:45,920 - jwst.ami.leastsqnrm - INFO - fringefitting.leastsqnrm.matrix_operations():
2026-04-15 20:15:45,921 - jwst.ami.leastsqnrm - INFO - img (69, 69)
2026-04-15 20:15:45,922 - jwst.ami.leastsqnrm - INFO - L x W = 69 x 69 = 4761
2026-04-15 20:15:45,922 - jwst.ami.leastsqnrm - INFO - flatimg (4761,)
2026-04-15 20:15:45,922 - jwst.ami.leastsqnrm - INFO -
2026-04-15 20:15:45,923 - jwst.ami.leastsqnrm - INFO - type(dqm) <class 'numpy.ndarray'>
2026-04-15 20:15:45,923 - jwst.ami.leastsqnrm - INFO - type(nanlist) <class 'tuple'>, len=1
2026-04-15 20:15:45,924 - jwst.ami.leastsqnrm - INFO - number of nanlist pixels: 37 items
2026-04-15 20:15:45,924 - jwst.ami.leastsqnrm - INFO - 37 DO_NOT_USE pixels found in data slice
2026-04-15 20:15:45,925 - jwst.ami.leastsqnrm - INFO - flatimg (4724,) after deleting 37
2026-04-15 20:15:45,926 - jwst.ami.leastsqnrm - INFO - flatmodel_nan (4761, 44)
2026-04-15 20:15:45,926 - jwst.ami.leastsqnrm - INFO - flatmodel (4724, 44)
2026-04-15 20:15:45,926 - jwst.ami.leastsqnrm - INFO - difference 37
2026-04-15 20:15:45,927 - jwst.ami.leastsqnrm - INFO - flat model dimensions (4724, 44)
2026-04-15 20:15:45,927 - jwst.ami.leastsqnrm - INFO - flat image dimensions (4724,)
2026-04-15 20:15:45,930 - jwst.ami.leastsqnrm - INFO - data flux 2.7341735e+06
2026-04-15 20:15:45,930 - jwst.ami.leastsqnrm - INFO - flat model dimensions (4724, 44)
2026-04-15 20:15:45,930 - jwst.ami.leastsqnrm - INFO - model transpose dimensions (44, 4724)
2026-04-15 20:15:45,931 - jwst.ami.leastsqnrm - INFO - flat image dimensions (4724,)
2026-04-15 20:15:45,931 - jwst.ami.leastsqnrm - INFO - transpose * image data dimensions (44,)
2026-04-15 20:15:45,932 - jwst.ami.leastsqnrm - INFO - flat img * transpose dimensions (44, 44)
2026-04-15 20:15:45,932 - jwst.ami.leastsqnrm - INFO - linearfit not attempted, no covariances saved.
2026-04-15 20:15:45,934 - jwst.ami.nrm_core - INFO - Fitting fringes for iteration 51 of 69
2026-04-15 20:15:46,991 - jwst.ami.leastsqnrm - INFO - fringefitting.leastsqnrm.matrix_operations():
2026-04-15 20:15:46,992 - jwst.ami.leastsqnrm - INFO - img (69, 69)
2026-04-15 20:15:46,992 - jwst.ami.leastsqnrm - INFO - L x W = 69 x 69 = 4761
2026-04-15 20:15:46,993 - jwst.ami.leastsqnrm - INFO - flatimg (4761,)
2026-04-15 20:15:46,993 - jwst.ami.leastsqnrm - INFO -
2026-04-15 20:15:46,994 - jwst.ami.leastsqnrm - INFO - type(dqm) <class 'numpy.ndarray'>
2026-04-15 20:15:46,994 - jwst.ami.leastsqnrm - INFO - type(nanlist) <class 'tuple'>, len=1
2026-04-15 20:15:46,995 - jwst.ami.leastsqnrm - INFO - number of nanlist pixels: 36 items
2026-04-15 20:15:46,995 - jwst.ami.leastsqnrm - INFO - 36 DO_NOT_USE pixels found in data slice
2026-04-15 20:15:46,996 - jwst.ami.leastsqnrm - INFO - flatimg (4725,) after deleting 36
2026-04-15 20:15:46,997 - jwst.ami.leastsqnrm - INFO - flatmodel_nan (4761, 44)
2026-04-15 20:15:46,997 - jwst.ami.leastsqnrm - INFO - flatmodel (4725, 44)
2026-04-15 20:15:46,997 - jwst.ami.leastsqnrm - INFO - difference 36
2026-04-15 20:15:46,998 - jwst.ami.leastsqnrm - INFO - flat model dimensions (4725, 44)
2026-04-15 20:15:46,998 - jwst.ami.leastsqnrm - INFO - flat image dimensions (4725,)
2026-04-15 20:15:47,001 - jwst.ami.leastsqnrm - INFO - data flux 2.7371868e+06
2026-04-15 20:15:47,001 - jwst.ami.leastsqnrm - INFO - flat model dimensions (4725, 44)
2026-04-15 20:15:47,001 - jwst.ami.leastsqnrm - INFO - model transpose dimensions (44, 4725)
2026-04-15 20:15:47,002 - jwst.ami.leastsqnrm - INFO - flat image dimensions (4725,)
2026-04-15 20:15:47,002 - jwst.ami.leastsqnrm - INFO - transpose * image data dimensions (44,)
2026-04-15 20:15:47,003 - jwst.ami.leastsqnrm - INFO - flat img * transpose dimensions (44, 44)
2026-04-15 20:15:47,003 - jwst.ami.leastsqnrm - INFO - linearfit not attempted, no covariances saved.
2026-04-15 20:15:47,005 - jwst.ami.nrm_core - INFO - Fitting fringes for iteration 52 of 69
2026-04-15 20:15:48,060 - jwst.ami.leastsqnrm - INFO - fringefitting.leastsqnrm.matrix_operations():
2026-04-15 20:15:48,060 - jwst.ami.leastsqnrm - INFO - img (69, 69)
2026-04-15 20:15:48,061 - jwst.ami.leastsqnrm - INFO - L x W = 69 x 69 = 4761
2026-04-15 20:15:48,061 - jwst.ami.leastsqnrm - INFO - flatimg (4761,)
2026-04-15 20:15:48,062 - jwst.ami.leastsqnrm - INFO -
2026-04-15 20:15:48,062 - jwst.ami.leastsqnrm - INFO - type(dqm) <class 'numpy.ndarray'>
2026-04-15 20:15:48,063 - jwst.ami.leastsqnrm - INFO - type(nanlist) <class 'tuple'>, len=1
2026-04-15 20:15:48,063 - jwst.ami.leastsqnrm - INFO - number of nanlist pixels: 36 items
2026-04-15 20:15:48,064 - jwst.ami.leastsqnrm - INFO - 36 DO_NOT_USE pixels found in data slice
2026-04-15 20:15:48,064 - jwst.ami.leastsqnrm - INFO - flatimg (4725,) after deleting 36
2026-04-15 20:15:48,065 - jwst.ami.leastsqnrm - INFO - flatmodel_nan (4761, 44)
2026-04-15 20:15:48,065 - jwst.ami.leastsqnrm - INFO - flatmodel (4725, 44)
2026-04-15 20:15:48,066 - jwst.ami.leastsqnrm - INFO - difference 36
2026-04-15 20:15:48,066 - jwst.ami.leastsqnrm - INFO - flat model dimensions (4725, 44)
2026-04-15 20:15:48,067 - jwst.ami.leastsqnrm - INFO - flat image dimensions (4725,)
2026-04-15 20:15:48,069 - jwst.ami.leastsqnrm - INFO - data flux 2.757071e+06
2026-04-15 20:15:48,070 - jwst.ami.leastsqnrm - INFO - flat model dimensions (4725, 44)
2026-04-15 20:15:48,070 - jwst.ami.leastsqnrm - INFO - model transpose dimensions (44, 4725)
2026-04-15 20:15:48,070 - jwst.ami.leastsqnrm - INFO - flat image dimensions (4725,)
2026-04-15 20:15:48,071 - jwst.ami.leastsqnrm - INFO - transpose * image data dimensions (44,)
2026-04-15 20:15:48,071 - jwst.ami.leastsqnrm - INFO - flat img * transpose dimensions (44, 44)
2026-04-15 20:15:48,072 - jwst.ami.leastsqnrm - INFO - linearfit not attempted, no covariances saved.
2026-04-15 20:15:48,073 - jwst.ami.nrm_core - INFO - Fitting fringes for iteration 53 of 69
2026-04-15 20:15:49,134 - jwst.ami.leastsqnrm - INFO - fringefitting.leastsqnrm.matrix_operations():
2026-04-15 20:15:49,135 - jwst.ami.leastsqnrm - INFO - img (69, 69)
2026-04-15 20:15:49,135 - jwst.ami.leastsqnrm - INFO - L x W = 69 x 69 = 4761
2026-04-15 20:15:49,136 - jwst.ami.leastsqnrm - INFO - flatimg (4761,)
2026-04-15 20:15:49,136 - jwst.ami.leastsqnrm - INFO -
2026-04-15 20:15:49,137 - jwst.ami.leastsqnrm - INFO - type(dqm) <class 'numpy.ndarray'>
2026-04-15 20:15:49,137 - jwst.ami.leastsqnrm - INFO - type(nanlist) <class 'tuple'>, len=1
2026-04-15 20:15:49,138 - jwst.ami.leastsqnrm - INFO - number of nanlist pixels: 36 items
2026-04-15 20:15:49,138 - jwst.ami.leastsqnrm - INFO - 36 DO_NOT_USE pixels found in data slice
2026-04-15 20:15:49,139 - jwst.ami.leastsqnrm - INFO - flatimg (4725,) after deleting 36
2026-04-15 20:15:49,139 - jwst.ami.leastsqnrm - INFO - flatmodel_nan (4761, 44)
2026-04-15 20:15:49,140 - jwst.ami.leastsqnrm - INFO - flatmodel (4725, 44)
2026-04-15 20:15:49,140 - jwst.ami.leastsqnrm - INFO - difference 36
2026-04-15 20:15:49,140 - jwst.ami.leastsqnrm - INFO - flat model dimensions (4725, 44)
2026-04-15 20:15:49,141 - jwst.ami.leastsqnrm - INFO - flat image dimensions (4725,)
2026-04-15 20:15:49,144 - jwst.ami.leastsqnrm - INFO - data flux 2.7547365e+06
2026-04-15 20:15:49,144 - jwst.ami.leastsqnrm - INFO - flat model dimensions (4725, 44)
2026-04-15 20:15:49,145 - jwst.ami.leastsqnrm - INFO - model transpose dimensions (44, 4725)
2026-04-15 20:15:49,145 - jwst.ami.leastsqnrm - INFO - flat image dimensions (4725,)
2026-04-15 20:15:49,145 - jwst.ami.leastsqnrm - INFO - transpose * image data dimensions (44,)
2026-04-15 20:15:49,146 - jwst.ami.leastsqnrm - INFO - flat img * transpose dimensions (44, 44)
2026-04-15 20:15:49,146 - jwst.ami.leastsqnrm - INFO - linearfit not attempted, no covariances saved.
2026-04-15 20:15:49,148 - jwst.ami.nrm_core - INFO - Fitting fringes for iteration 54 of 69
2026-04-15 20:15:50,208 - jwst.ami.leastsqnrm - INFO - fringefitting.leastsqnrm.matrix_operations():
2026-04-15 20:15:50,209 - jwst.ami.leastsqnrm - INFO - img (69, 69)
2026-04-15 20:15:50,209 - jwst.ami.leastsqnrm - INFO - L x W = 69 x 69 = 4761
2026-04-15 20:15:50,210 - jwst.ami.leastsqnrm - INFO - flatimg (4761,)
2026-04-15 20:15:50,210 - jwst.ami.leastsqnrm - INFO -
2026-04-15 20:15:50,210 - jwst.ami.leastsqnrm - INFO - type(dqm) <class 'numpy.ndarray'>
2026-04-15 20:15:50,211 - jwst.ami.leastsqnrm - INFO - type(nanlist) <class 'tuple'>, len=1
2026-04-15 20:15:50,212 - jwst.ami.leastsqnrm - INFO - number of nanlist pixels: 37 items
2026-04-15 20:15:50,212 - jwst.ami.leastsqnrm - INFO - 37 DO_NOT_USE pixels found in data slice
2026-04-15 20:15:50,213 - jwst.ami.leastsqnrm - INFO - flatimg (4724,) after deleting 37
2026-04-15 20:15:50,213 - jwst.ami.leastsqnrm - INFO - flatmodel_nan (4761, 44)
2026-04-15 20:15:50,214 - jwst.ami.leastsqnrm - INFO - flatmodel (4724, 44)
2026-04-15 20:15:50,214 - jwst.ami.leastsqnrm - INFO - difference 37
2026-04-15 20:15:50,215 - jwst.ami.leastsqnrm - INFO - flat model dimensions (4724, 44)
2026-04-15 20:15:50,215 - jwst.ami.leastsqnrm - INFO - flat image dimensions (4724,)
2026-04-15 20:15:50,217 - jwst.ami.leastsqnrm - INFO - data flux 2.782994e+06
2026-04-15 20:15:50,218 - jwst.ami.leastsqnrm - INFO - flat model dimensions (4724, 44)
2026-04-15 20:15:50,218 - jwst.ami.leastsqnrm - INFO - model transpose dimensions (44, 4724)
2026-04-15 20:15:50,219 - jwst.ami.leastsqnrm - INFO - flat image dimensions (4724,)
2026-04-15 20:15:50,219 - jwst.ami.leastsqnrm - INFO - transpose * image data dimensions (44,)
2026-04-15 20:15:50,220 - jwst.ami.leastsqnrm - INFO - flat img * transpose dimensions (44, 44)
2026-04-15 20:15:50,220 - jwst.ami.leastsqnrm - INFO - linearfit not attempted, no covariances saved.
2026-04-15 20:15:50,222 - jwst.ami.nrm_core - INFO - Fitting fringes for iteration 55 of 69
2026-04-15 20:15:51,288 - jwst.ami.leastsqnrm - INFO - fringefitting.leastsqnrm.matrix_operations():
2026-04-15 20:15:51,289 - jwst.ami.leastsqnrm - INFO - img (69, 69)
2026-04-15 20:15:51,289 - jwst.ami.leastsqnrm - INFO - L x W = 69 x 69 = 4761
2026-04-15 20:15:51,290 - jwst.ami.leastsqnrm - INFO - flatimg (4761,)
2026-04-15 20:15:51,290 - jwst.ami.leastsqnrm - INFO -
2026-04-15 20:15:51,290 - jwst.ami.leastsqnrm - INFO - type(dqm) <class 'numpy.ndarray'>
2026-04-15 20:15:51,291 - jwst.ami.leastsqnrm - INFO - type(nanlist) <class 'tuple'>, len=1
2026-04-15 20:15:51,291 - jwst.ami.leastsqnrm - INFO - number of nanlist pixels: 36 items
2026-04-15 20:15:51,292 - jwst.ami.leastsqnrm - INFO - 36 DO_NOT_USE pixels found in data slice
2026-04-15 20:15:51,292 - jwst.ami.leastsqnrm - INFO - flatimg (4725,) after deleting 36
2026-04-15 20:15:51,293 - jwst.ami.leastsqnrm - INFO - flatmodel_nan (4761, 44)
2026-04-15 20:15:51,294 - jwst.ami.leastsqnrm - INFO - flatmodel (4725, 44)
2026-04-15 20:15:51,294 - jwst.ami.leastsqnrm - INFO - difference 36
2026-04-15 20:15:51,295 - jwst.ami.leastsqnrm - INFO - flat model dimensions (4725, 44)
2026-04-15 20:15:51,295 - jwst.ami.leastsqnrm - INFO - flat image dimensions (4725,)
2026-04-15 20:15:51,298 - jwst.ami.leastsqnrm - INFO - data flux 2.74447e+06
2026-04-15 20:15:51,298 - jwst.ami.leastsqnrm - INFO - flat model dimensions (4725, 44)
2026-04-15 20:15:51,298 - jwst.ami.leastsqnrm - INFO - model transpose dimensions (44, 4725)
2026-04-15 20:15:51,299 - jwst.ami.leastsqnrm - INFO - flat image dimensions (4725,)
2026-04-15 20:15:51,299 - jwst.ami.leastsqnrm - INFO - transpose * image data dimensions (44,)
2026-04-15 20:15:51,300 - jwst.ami.leastsqnrm - INFO - flat img * transpose dimensions (44, 44)
2026-04-15 20:15:51,300 - jwst.ami.leastsqnrm - INFO - linearfit not attempted, no covariances saved.
2026-04-15 20:15:51,302 - jwst.ami.nrm_core - INFO - Fitting fringes for iteration 56 of 69
2026-04-15 20:15:52,371 - jwst.ami.leastsqnrm - INFO - fringefitting.leastsqnrm.matrix_operations():
2026-04-15 20:15:52,371 - jwst.ami.leastsqnrm - INFO - img (69, 69)
2026-04-15 20:15:52,372 - jwst.ami.leastsqnrm - INFO - L x W = 69 x 69 = 4761
2026-04-15 20:15:52,372 - jwst.ami.leastsqnrm - INFO - flatimg (4761,)
2026-04-15 20:15:52,373 - jwst.ami.leastsqnrm - INFO -
2026-04-15 20:15:52,373 - jwst.ami.leastsqnrm - INFO - type(dqm) <class 'numpy.ndarray'>
2026-04-15 20:15:52,373 - jwst.ami.leastsqnrm - INFO - type(nanlist) <class 'tuple'>, len=1
2026-04-15 20:15:52,374 - jwst.ami.leastsqnrm - INFO - number of nanlist pixels: 37 items
2026-04-15 20:15:52,374 - jwst.ami.leastsqnrm - INFO - 37 DO_NOT_USE pixels found in data slice
2026-04-15 20:15:52,375 - jwst.ami.leastsqnrm - INFO - flatimg (4724,) after deleting 37
2026-04-15 20:15:52,375 - jwst.ami.leastsqnrm - INFO - flatmodel_nan (4761, 44)
2026-04-15 20:15:52,376 - jwst.ami.leastsqnrm - INFO - flatmodel (4724, 44)
2026-04-15 20:15:52,376 - jwst.ami.leastsqnrm - INFO - difference 37
2026-04-15 20:15:52,377 - jwst.ami.leastsqnrm - INFO - flat model dimensions (4724, 44)
2026-04-15 20:15:52,377 - jwst.ami.leastsqnrm - INFO - flat image dimensions (4724,)
2026-04-15 20:15:52,380 - jwst.ami.leastsqnrm - INFO - data flux 2.7449462e+06
2026-04-15 20:15:52,380 - jwst.ami.leastsqnrm - INFO - flat model dimensions (4724, 44)
2026-04-15 20:15:52,380 - jwst.ami.leastsqnrm - INFO - model transpose dimensions (44, 4724)
2026-04-15 20:15:52,381 - jwst.ami.leastsqnrm - INFO - flat image dimensions (4724,)
2026-04-15 20:15:52,381 - jwst.ami.leastsqnrm - INFO - transpose * image data dimensions (44,)
2026-04-15 20:15:52,382 - jwst.ami.leastsqnrm - INFO - flat img * transpose dimensions (44, 44)
2026-04-15 20:15:52,382 - jwst.ami.leastsqnrm - INFO - linearfit not attempted, no covariances saved.
2026-04-15 20:15:52,384 - jwst.ami.nrm_core - INFO - Fitting fringes for iteration 57 of 69
2026-04-15 20:15:53,445 - jwst.ami.leastsqnrm - INFO - fringefitting.leastsqnrm.matrix_operations():
2026-04-15 20:15:53,446 - jwst.ami.leastsqnrm - INFO - img (69, 69)
2026-04-15 20:15:53,447 - jwst.ami.leastsqnrm - INFO - L x W = 69 x 69 = 4761
2026-04-15 20:15:53,447 - jwst.ami.leastsqnrm - INFO - flatimg (4761,)
2026-04-15 20:15:53,447 - jwst.ami.leastsqnrm - INFO -
2026-04-15 20:15:53,448 - jwst.ami.leastsqnrm - INFO - type(dqm) <class 'numpy.ndarray'>
2026-04-15 20:15:53,448 - jwst.ami.leastsqnrm - INFO - type(nanlist) <class 'tuple'>, len=1
2026-04-15 20:15:53,449 - jwst.ami.leastsqnrm - INFO - number of nanlist pixels: 36 items
2026-04-15 20:15:53,450 - jwst.ami.leastsqnrm - INFO - 36 DO_NOT_USE pixels found in data slice
2026-04-15 20:15:53,450 - jwst.ami.leastsqnrm - INFO - flatimg (4725,) after deleting 36
2026-04-15 20:15:53,451 - jwst.ami.leastsqnrm - INFO - flatmodel_nan (4761, 44)
2026-04-15 20:15:53,451 - jwst.ami.leastsqnrm - INFO - flatmodel (4725, 44)
2026-04-15 20:15:53,451 - jwst.ami.leastsqnrm - INFO - difference 36
2026-04-15 20:15:53,452 - jwst.ami.leastsqnrm - INFO - flat model dimensions (4725, 44)
2026-04-15 20:15:53,452 - jwst.ami.leastsqnrm - INFO - flat image dimensions (4725,)
2026-04-15 20:15:53,455 - jwst.ami.leastsqnrm - INFO - data flux 2.727575e+06
2026-04-15 20:15:53,455 - jwst.ami.leastsqnrm - INFO - flat model dimensions (4725, 44)
2026-04-15 20:15:53,456 - jwst.ami.leastsqnrm - INFO - model transpose dimensions (44, 4725)
2026-04-15 20:15:53,456 - jwst.ami.leastsqnrm - INFO - flat image dimensions (4725,)
2026-04-15 20:15:53,457 - jwst.ami.leastsqnrm - INFO - transpose * image data dimensions (44,)
2026-04-15 20:15:53,457 - jwst.ami.leastsqnrm - INFO - flat img * transpose dimensions (44, 44)
2026-04-15 20:15:53,457 - jwst.ami.leastsqnrm - INFO - linearfit not attempted, no covariances saved.
2026-04-15 20:15:53,459 - jwst.ami.nrm_core - INFO - Fitting fringes for iteration 58 of 69
2026-04-15 20:15:54,523 - jwst.ami.leastsqnrm - INFO - fringefitting.leastsqnrm.matrix_operations():
2026-04-15 20:15:54,523 - jwst.ami.leastsqnrm - INFO - img (69, 69)
2026-04-15 20:15:54,524 - jwst.ami.leastsqnrm - INFO - L x W = 69 x 69 = 4761
2026-04-15 20:15:54,524 - jwst.ami.leastsqnrm - INFO - flatimg (4761,)
2026-04-15 20:15:54,525 - jwst.ami.leastsqnrm - INFO -
2026-04-15 20:15:54,525 - jwst.ami.leastsqnrm - INFO - type(dqm) <class 'numpy.ndarray'>
2026-04-15 20:15:54,526 - jwst.ami.leastsqnrm - INFO - type(nanlist) <class 'tuple'>, len=1
2026-04-15 20:15:54,526 - jwst.ami.leastsqnrm - INFO - number of nanlist pixels: 37 items
2026-04-15 20:15:54,526 - jwst.ami.leastsqnrm - INFO - 37 DO_NOT_USE pixels found in data slice
2026-04-15 20:15:54,527 - jwst.ami.leastsqnrm - INFO - flatimg (4724,) after deleting 37
2026-04-15 20:15:54,528 - jwst.ami.leastsqnrm - INFO - flatmodel_nan (4761, 44)
2026-04-15 20:15:54,528 - jwst.ami.leastsqnrm - INFO - flatmodel (4724, 44)
2026-04-15 20:15:54,528 - jwst.ami.leastsqnrm - INFO - difference 37
2026-04-15 20:15:54,529 - jwst.ami.leastsqnrm - INFO - flat model dimensions (4724, 44)
2026-04-15 20:15:54,529 - jwst.ami.leastsqnrm - INFO - flat image dimensions (4724,)
2026-04-15 20:15:54,532 - jwst.ami.leastsqnrm - INFO - data flux 2.7207735e+06
2026-04-15 20:15:54,532 - jwst.ami.leastsqnrm - INFO - flat model dimensions (4724, 44)
2026-04-15 20:15:54,533 - jwst.ami.leastsqnrm - INFO - model transpose dimensions (44, 4724)
2026-04-15 20:15:54,533 - jwst.ami.leastsqnrm - INFO - flat image dimensions (4724,)
2026-04-15 20:15:54,534 - jwst.ami.leastsqnrm - INFO - transpose * image data dimensions (44,)
2026-04-15 20:15:54,534 - jwst.ami.leastsqnrm - INFO - flat img * transpose dimensions (44, 44)
2026-04-15 20:15:54,535 - jwst.ami.leastsqnrm - INFO - linearfit not attempted, no covariances saved.
2026-04-15 20:15:54,536 - jwst.ami.nrm_core - INFO - Fitting fringes for iteration 59 of 69
2026-04-15 20:15:55,601 - jwst.ami.leastsqnrm - INFO - fringefitting.leastsqnrm.matrix_operations():
2026-04-15 20:15:55,602 - jwst.ami.leastsqnrm - INFO - img (69, 69)
2026-04-15 20:15:55,602 - jwst.ami.leastsqnrm - INFO - L x W = 69 x 69 = 4761
2026-04-15 20:15:55,603 - jwst.ami.leastsqnrm - INFO - flatimg (4761,)
2026-04-15 20:15:55,603 - jwst.ami.leastsqnrm - INFO -
2026-04-15 20:15:55,603 - jwst.ami.leastsqnrm - INFO - type(dqm) <class 'numpy.ndarray'>
2026-04-15 20:15:55,604 - jwst.ami.leastsqnrm - INFO - type(nanlist) <class 'tuple'>, len=1
2026-04-15 20:15:55,604 - jwst.ami.leastsqnrm - INFO - number of nanlist pixels: 36 items
2026-04-15 20:15:55,605 - jwst.ami.leastsqnrm - INFO - 36 DO_NOT_USE pixels found in data slice
2026-04-15 20:15:55,605 - jwst.ami.leastsqnrm - INFO - flatimg (4725,) after deleting 36
2026-04-15 20:15:55,606 - jwst.ami.leastsqnrm - INFO - flatmodel_nan (4761, 44)
2026-04-15 20:15:55,607 - jwst.ami.leastsqnrm - INFO - flatmodel (4725, 44)
2026-04-15 20:15:55,607 - jwst.ami.leastsqnrm - INFO - difference 36
2026-04-15 20:15:55,607 - jwst.ami.leastsqnrm - INFO - flat model dimensions (4725, 44)
2026-04-15 20:15:55,608 - jwst.ami.leastsqnrm - INFO - flat image dimensions (4725,)
2026-04-15 20:15:55,610 - jwst.ami.leastsqnrm - INFO - data flux 2.7291205e+06
2026-04-15 20:15:55,611 - jwst.ami.leastsqnrm - INFO - flat model dimensions (4725, 44)
2026-04-15 20:15:55,611 - jwst.ami.leastsqnrm - INFO - model transpose dimensions (44, 4725)
2026-04-15 20:15:55,612 - jwst.ami.leastsqnrm - INFO - flat image dimensions (4725,)
2026-04-15 20:15:55,612 - jwst.ami.leastsqnrm - INFO - transpose * image data dimensions (44,)
2026-04-15 20:15:55,612 - jwst.ami.leastsqnrm - INFO - flat img * transpose dimensions (44, 44)
2026-04-15 20:15:55,613 - jwst.ami.leastsqnrm - INFO - linearfit not attempted, no covariances saved.
2026-04-15 20:15:55,614 - jwst.ami.nrm_core - INFO - Fitting fringes for iteration 60 of 69
2026-04-15 20:15:56,674 - jwst.ami.leastsqnrm - INFO - fringefitting.leastsqnrm.matrix_operations():
2026-04-15 20:15:56,675 - jwst.ami.leastsqnrm - INFO - img (69, 69)
2026-04-15 20:15:56,675 - jwst.ami.leastsqnrm - INFO - L x W = 69 x 69 = 4761
2026-04-15 20:15:56,676 - jwst.ami.leastsqnrm - INFO - flatimg (4761,)
2026-04-15 20:15:56,676 - jwst.ami.leastsqnrm - INFO -
2026-04-15 20:15:56,677 - jwst.ami.leastsqnrm - INFO - type(dqm) <class 'numpy.ndarray'>
2026-04-15 20:15:56,677 - jwst.ami.leastsqnrm - INFO - type(nanlist) <class 'tuple'>, len=1
2026-04-15 20:15:56,678 - jwst.ami.leastsqnrm - INFO - number of nanlist pixels: 36 items
2026-04-15 20:15:56,678 - jwst.ami.leastsqnrm - INFO - 36 DO_NOT_USE pixels found in data slice
2026-04-15 20:15:56,679 - jwst.ami.leastsqnrm - INFO - flatimg (4725,) after deleting 36
2026-04-15 20:15:56,680 - jwst.ami.leastsqnrm - INFO - flatmodel_nan (4761, 44)
2026-04-15 20:15:56,680 - jwst.ami.leastsqnrm - INFO - flatmodel (4725, 44)
2026-04-15 20:15:56,680 - jwst.ami.leastsqnrm - INFO - difference 36
2026-04-15 20:15:56,681 - jwst.ami.leastsqnrm - INFO - flat model dimensions (4725, 44)
2026-04-15 20:15:56,681 - jwst.ami.leastsqnrm - INFO - flat image dimensions (4725,)
2026-04-15 20:15:56,684 - jwst.ami.leastsqnrm - INFO - data flux 2.762147e+06
2026-04-15 20:15:56,684 - jwst.ami.leastsqnrm - INFO - flat model dimensions (4725, 44)
2026-04-15 20:15:56,684 - jwst.ami.leastsqnrm - INFO - model transpose dimensions (44, 4725)
2026-04-15 20:15:56,685 - jwst.ami.leastsqnrm - INFO - flat image dimensions (4725,)
2026-04-15 20:15:56,685 - jwst.ami.leastsqnrm - INFO - transpose * image data dimensions (44,)
2026-04-15 20:15:56,686 - jwst.ami.leastsqnrm - INFO - flat img * transpose dimensions (44, 44)
2026-04-15 20:15:56,686 - jwst.ami.leastsqnrm - INFO - linearfit not attempted, no covariances saved.
2026-04-15 20:15:56,688 - jwst.ami.nrm_core - INFO - Fitting fringes for iteration 61 of 69
2026-04-15 20:15:57,748 - jwst.ami.leastsqnrm - INFO - fringefitting.leastsqnrm.matrix_operations():
2026-04-15 20:15:57,748 - jwst.ami.leastsqnrm - INFO - img (69, 69)
2026-04-15 20:15:57,749 - jwst.ami.leastsqnrm - INFO - L x W = 69 x 69 = 4761
2026-04-15 20:15:57,749 - jwst.ami.leastsqnrm - INFO - flatimg (4761,)
2026-04-15 20:15:57,750 - jwst.ami.leastsqnrm - INFO -
2026-04-15 20:15:57,750 - jwst.ami.leastsqnrm - INFO - type(dqm) <class 'numpy.ndarray'>
2026-04-15 20:15:57,750 - jwst.ami.leastsqnrm - INFO - type(nanlist) <class 'tuple'>, len=1
2026-04-15 20:15:57,751 - jwst.ami.leastsqnrm - INFO - number of nanlist pixels: 37 items
2026-04-15 20:15:57,751 - jwst.ami.leastsqnrm - INFO - 37 DO_NOT_USE pixels found in data slice
2026-04-15 20:15:57,752 - jwst.ami.leastsqnrm - INFO - flatimg (4724,) after deleting 37
2026-04-15 20:15:57,753 - jwst.ami.leastsqnrm - INFO - flatmodel_nan (4761, 44)
2026-04-15 20:15:57,753 - jwst.ami.leastsqnrm - INFO - flatmodel (4724, 44)
2026-04-15 20:15:57,753 - jwst.ami.leastsqnrm - INFO - difference 37
2026-04-15 20:15:57,754 - jwst.ami.leastsqnrm - INFO - flat model dimensions (4724, 44)
2026-04-15 20:15:57,754 - jwst.ami.leastsqnrm - INFO - flat image dimensions (4724,)
2026-04-15 20:15:57,757 - jwst.ami.leastsqnrm - INFO - data flux 2.7635725e+06
2026-04-15 20:15:57,757 - jwst.ami.leastsqnrm - INFO - flat model dimensions (4724, 44)
2026-04-15 20:15:57,758 - jwst.ami.leastsqnrm - INFO - model transpose dimensions (44, 4724)
2026-04-15 20:15:57,758 - jwst.ami.leastsqnrm - INFO - flat image dimensions (4724,)
2026-04-15 20:15:57,759 - jwst.ami.leastsqnrm - INFO - transpose * image data dimensions (44,)
2026-04-15 20:15:57,759 - jwst.ami.leastsqnrm - INFO - flat img * transpose dimensions (44, 44)
2026-04-15 20:15:57,759 - jwst.ami.leastsqnrm - INFO - linearfit not attempted, no covariances saved.
2026-04-15 20:15:57,761 - jwst.ami.nrm_core - INFO - Fitting fringes for iteration 62 of 69
2026-04-15 20:15:58,822 - jwst.ami.leastsqnrm - INFO - fringefitting.leastsqnrm.matrix_operations():
2026-04-15 20:15:58,822 - jwst.ami.leastsqnrm - INFO - img (69, 69)
2026-04-15 20:15:58,823 - jwst.ami.leastsqnrm - INFO - L x W = 69 x 69 = 4761
2026-04-15 20:15:58,823 - jwst.ami.leastsqnrm - INFO - flatimg (4761,)
2026-04-15 20:15:58,823 - jwst.ami.leastsqnrm - INFO -
2026-04-15 20:15:58,824 - jwst.ami.leastsqnrm - INFO - type(dqm) <class 'numpy.ndarray'>
2026-04-15 20:15:58,825 - jwst.ami.leastsqnrm - INFO - type(nanlist) <class 'tuple'>, len=1
2026-04-15 20:15:58,825 - jwst.ami.leastsqnrm - INFO - number of nanlist pixels: 36 items
2026-04-15 20:15:58,825 - jwst.ami.leastsqnrm - INFO - 36 DO_NOT_USE pixels found in data slice
2026-04-15 20:15:58,826 - jwst.ami.leastsqnrm - INFO - flatimg (4725,) after deleting 36
2026-04-15 20:15:58,827 - jwst.ami.leastsqnrm - INFO - flatmodel_nan (4761, 44)
2026-04-15 20:15:58,827 - jwst.ami.leastsqnrm - INFO - flatmodel (4725, 44)
2026-04-15 20:15:58,827 - jwst.ami.leastsqnrm - INFO - difference 36
2026-04-15 20:15:58,828 - jwst.ami.leastsqnrm - INFO - flat model dimensions (4725, 44)
2026-04-15 20:15:58,828 - jwst.ami.leastsqnrm - INFO - flat image dimensions (4725,)
2026-04-15 20:15:58,831 - jwst.ami.leastsqnrm - INFO - data flux 2.7254345e+06
2026-04-15 20:15:58,831 - jwst.ami.leastsqnrm - INFO - flat model dimensions (4725, 44)
2026-04-15 20:15:58,832 - jwst.ami.leastsqnrm - INFO - model transpose dimensions (44, 4725)
2026-04-15 20:15:58,832 - jwst.ami.leastsqnrm - INFO - flat image dimensions (4725,)
2026-04-15 20:15:58,832 - jwst.ami.leastsqnrm - INFO - transpose * image data dimensions (44,)
2026-04-15 20:15:58,833 - jwst.ami.leastsqnrm - INFO - flat img * transpose dimensions (44, 44)
2026-04-15 20:15:58,833 - jwst.ami.leastsqnrm - INFO - linearfit not attempted, no covariances saved.
2026-04-15 20:15:58,835 - jwst.ami.nrm_core - INFO - Fitting fringes for iteration 63 of 69
2026-04-15 20:15:59,895 - jwst.ami.leastsqnrm - INFO - fringefitting.leastsqnrm.matrix_operations():
2026-04-15 20:15:59,895 - jwst.ami.leastsqnrm - INFO - img (69, 69)
2026-04-15 20:15:59,896 - jwst.ami.leastsqnrm - INFO - L x W = 69 x 69 = 4761
2026-04-15 20:15:59,896 - jwst.ami.leastsqnrm - INFO - flatimg (4761,)
2026-04-15 20:15:59,897 - jwst.ami.leastsqnrm - INFO -
2026-04-15 20:15:59,897 - jwst.ami.leastsqnrm - INFO - type(dqm) <class 'numpy.ndarray'>
2026-04-15 20:15:59,898 - jwst.ami.leastsqnrm - INFO - type(nanlist) <class 'tuple'>, len=1
2026-04-15 20:15:59,898 - jwst.ami.leastsqnrm - INFO - number of nanlist pixels: 36 items
2026-04-15 20:15:59,899 - jwst.ami.leastsqnrm - INFO - 36 DO_NOT_USE pixels found in data slice
2026-04-15 20:15:59,899 - jwst.ami.leastsqnrm - INFO - flatimg (4725,) after deleting 36
2026-04-15 20:15:59,900 - jwst.ami.leastsqnrm - INFO - flatmodel_nan (4761, 44)
2026-04-15 20:15:59,900 - jwst.ami.leastsqnrm - INFO - flatmodel (4725, 44)
2026-04-15 20:15:59,901 - jwst.ami.leastsqnrm - INFO - difference 36
2026-04-15 20:15:59,901 - jwst.ami.leastsqnrm - INFO - flat model dimensions (4725, 44)
2026-04-15 20:15:59,901 - jwst.ami.leastsqnrm - INFO - flat image dimensions (4725,)
2026-04-15 20:15:59,904 - jwst.ami.leastsqnrm - INFO - data flux 2.750478e+06
2026-04-15 20:15:59,905 - jwst.ami.leastsqnrm - INFO - flat model dimensions (4725, 44)
2026-04-15 20:15:59,905 - jwst.ami.leastsqnrm - INFO - model transpose dimensions (44, 4725)
2026-04-15 20:15:59,905 - jwst.ami.leastsqnrm - INFO - flat image dimensions (4725,)
2026-04-15 20:15:59,906 - jwst.ami.leastsqnrm - INFO - transpose * image data dimensions (44,)
2026-04-15 20:15:59,906 - jwst.ami.leastsqnrm - INFO - flat img * transpose dimensions (44, 44)
2026-04-15 20:15:59,907 - jwst.ami.leastsqnrm - INFO - linearfit not attempted, no covariances saved.
2026-04-15 20:15:59,908 - jwst.ami.nrm_core - INFO - Fitting fringes for iteration 64 of 69
2026-04-15 20:16:00,967 - jwst.ami.leastsqnrm - INFO - fringefitting.leastsqnrm.matrix_operations():
2026-04-15 20:16:00,968 - jwst.ami.leastsqnrm - INFO - img (69, 69)
2026-04-15 20:16:00,969 - jwst.ami.leastsqnrm - INFO - L x W = 69 x 69 = 4761
2026-04-15 20:16:00,969 - jwst.ami.leastsqnrm - INFO - flatimg (4761,)
2026-04-15 20:16:00,970 - jwst.ami.leastsqnrm - INFO -
2026-04-15 20:16:00,970 - jwst.ami.leastsqnrm - INFO - type(dqm) <class 'numpy.ndarray'>
2026-04-15 20:16:00,970 - jwst.ami.leastsqnrm - INFO - type(nanlist) <class 'tuple'>, len=1
2026-04-15 20:16:00,971 - jwst.ami.leastsqnrm - INFO - number of nanlist pixels: 36 items
2026-04-15 20:16:00,971 - jwst.ami.leastsqnrm - INFO - 36 DO_NOT_USE pixels found in data slice
2026-04-15 20:16:00,972 - jwst.ami.leastsqnrm - INFO - flatimg (4725,) after deleting 36
2026-04-15 20:16:00,973 - jwst.ami.leastsqnrm - INFO - flatmodel_nan (4761, 44)
2026-04-15 20:16:00,973 - jwst.ami.leastsqnrm - INFO - flatmodel (4725, 44)
2026-04-15 20:16:00,973 - jwst.ami.leastsqnrm - INFO - difference 36
2026-04-15 20:16:00,974 - jwst.ami.leastsqnrm - INFO - flat model dimensions (4725, 44)
2026-04-15 20:16:00,974 - jwst.ami.leastsqnrm - INFO - flat image dimensions (4725,)
2026-04-15 20:16:00,977 - jwst.ami.leastsqnrm - INFO - data flux 2.7655898e+06
2026-04-15 20:16:00,977 - jwst.ami.leastsqnrm - INFO - flat model dimensions (4725, 44)
2026-04-15 20:16:00,977 - jwst.ami.leastsqnrm - INFO - model transpose dimensions (44, 4725)
2026-04-15 20:16:00,978 - jwst.ami.leastsqnrm - INFO - flat image dimensions (4725,)
2026-04-15 20:16:00,978 - jwst.ami.leastsqnrm - INFO - transpose * image data dimensions (44,)
2026-04-15 20:16:00,979 - jwst.ami.leastsqnrm - INFO - flat img * transpose dimensions (44, 44)
2026-04-15 20:16:00,979 - jwst.ami.leastsqnrm - INFO - linearfit not attempted, no covariances saved.
2026-04-15 20:16:00,981 - jwst.ami.nrm_core - INFO - Fitting fringes for iteration 65 of 69
2026-04-15 20:16:02,044 - jwst.ami.leastsqnrm - INFO - fringefitting.leastsqnrm.matrix_operations():
2026-04-15 20:16:02,044 - jwst.ami.leastsqnrm - INFO - img (69, 69)
2026-04-15 20:16:02,045 - jwst.ami.leastsqnrm - INFO - L x W = 69 x 69 = 4761
2026-04-15 20:16:02,045 - jwst.ami.leastsqnrm - INFO - flatimg (4761,)
2026-04-15 20:16:02,046 - jwst.ami.leastsqnrm - INFO -
2026-04-15 20:16:02,046 - jwst.ami.leastsqnrm - INFO - type(dqm) <class 'numpy.ndarray'>
2026-04-15 20:16:02,047 - jwst.ami.leastsqnrm - INFO - type(nanlist) <class 'tuple'>, len=1
2026-04-15 20:16:02,047 - jwst.ami.leastsqnrm - INFO - number of nanlist pixels: 36 items
2026-04-15 20:16:02,047 - jwst.ami.leastsqnrm - INFO - 36 DO_NOT_USE pixels found in data slice
2026-04-15 20:16:02,048 - jwst.ami.leastsqnrm - INFO - flatimg (4725,) after deleting 36
2026-04-15 20:16:02,048 - jwst.ami.leastsqnrm - INFO - flatmodel_nan (4761, 44)
2026-04-15 20:16:02,049 - jwst.ami.leastsqnrm - INFO - flatmodel (4725, 44)
2026-04-15 20:16:02,049 - jwst.ami.leastsqnrm - INFO - difference 36
2026-04-15 20:16:02,050 - jwst.ami.leastsqnrm - INFO - flat model dimensions (4725, 44)
2026-04-15 20:16:02,050 - jwst.ami.leastsqnrm - INFO - flat image dimensions (4725,)
2026-04-15 20:16:02,053 - jwst.ami.leastsqnrm - INFO - data flux 2.7389355e+06
2026-04-15 20:16:02,053 - jwst.ami.leastsqnrm - INFO - flat model dimensions (4725, 44)
2026-04-15 20:16:02,054 - jwst.ami.leastsqnrm - INFO - model transpose dimensions (44, 4725)
2026-04-15 20:16:02,054 - jwst.ami.leastsqnrm - INFO - flat image dimensions (4725,)
2026-04-15 20:16:02,054 - jwst.ami.leastsqnrm - INFO - transpose * image data dimensions (44,)
2026-04-15 20:16:02,055 - jwst.ami.leastsqnrm - INFO - flat img * transpose dimensions (44, 44)
2026-04-15 20:16:02,055 - jwst.ami.leastsqnrm - INFO - linearfit not attempted, no covariances saved.
2026-04-15 20:16:02,057 - jwst.ami.nrm_core - INFO - Fitting fringes for iteration 66 of 69
2026-04-15 20:16:03,119 - jwst.ami.leastsqnrm - INFO - fringefitting.leastsqnrm.matrix_operations():
2026-04-15 20:16:03,119 - jwst.ami.leastsqnrm - INFO - img (69, 69)
2026-04-15 20:16:03,120 - jwst.ami.leastsqnrm - INFO - L x W = 69 x 69 = 4761
2026-04-15 20:16:03,120 - jwst.ami.leastsqnrm - INFO - flatimg (4761,)
2026-04-15 20:16:03,121 - jwst.ami.leastsqnrm - INFO -
2026-04-15 20:16:03,121 - jwst.ami.leastsqnrm - INFO - type(dqm) <class 'numpy.ndarray'>
2026-04-15 20:16:03,122 - jwst.ami.leastsqnrm - INFO - type(nanlist) <class 'tuple'>, len=1
2026-04-15 20:16:03,122 - jwst.ami.leastsqnrm - INFO - number of nanlist pixels: 37 items
2026-04-15 20:16:03,122 - jwst.ami.leastsqnrm - INFO - 37 DO_NOT_USE pixels found in data slice
2026-04-15 20:16:03,123 - jwst.ami.leastsqnrm - INFO - flatimg (4724,) after deleting 37
2026-04-15 20:16:03,124 - jwst.ami.leastsqnrm - INFO - flatmodel_nan (4761, 44)
2026-04-15 20:16:03,124 - jwst.ami.leastsqnrm - INFO - flatmodel (4724, 44)
2026-04-15 20:16:03,124 - jwst.ami.leastsqnrm - INFO - difference 37
2026-04-15 20:16:03,125 - jwst.ami.leastsqnrm - INFO - flat model dimensions (4724, 44)
2026-04-15 20:16:03,125 - jwst.ami.leastsqnrm - INFO - flat image dimensions (4724,)
2026-04-15 20:16:03,128 - jwst.ami.leastsqnrm - INFO - data flux 2.748589e+06
2026-04-15 20:16:03,128 - jwst.ami.leastsqnrm - INFO - flat model dimensions (4724, 44)
2026-04-15 20:16:03,129 - jwst.ami.leastsqnrm - INFO - model transpose dimensions (44, 4724)
2026-04-15 20:16:03,129 - jwst.ami.leastsqnrm - INFO - flat image dimensions (4724,)
2026-04-15 20:16:03,130 - jwst.ami.leastsqnrm - INFO - transpose * image data dimensions (44,)
2026-04-15 20:16:03,130 - jwst.ami.leastsqnrm - INFO - flat img * transpose dimensions (44, 44)
2026-04-15 20:16:03,130 - jwst.ami.leastsqnrm - INFO - linearfit not attempted, no covariances saved.
2026-04-15 20:16:03,132 - jwst.ami.nrm_core - INFO - Fitting fringes for iteration 67 of 69
2026-04-15 20:16:04,190 - jwst.ami.leastsqnrm - INFO - fringefitting.leastsqnrm.matrix_operations():
2026-04-15 20:16:04,190 - jwst.ami.leastsqnrm - INFO - img (69, 69)
2026-04-15 20:16:04,191 - jwst.ami.leastsqnrm - INFO - L x W = 69 x 69 = 4761
2026-04-15 20:16:04,191 - jwst.ami.leastsqnrm - INFO - flatimg (4761,)
2026-04-15 20:16:04,192 - jwst.ami.leastsqnrm - INFO -
2026-04-15 20:16:04,192 - jwst.ami.leastsqnrm - INFO - type(dqm) <class 'numpy.ndarray'>
2026-04-15 20:16:04,193 - jwst.ami.leastsqnrm - INFO - type(nanlist) <class 'tuple'>, len=1
2026-04-15 20:16:04,193 - jwst.ami.leastsqnrm - INFO - number of nanlist pixels: 37 items
2026-04-15 20:16:04,194 - jwst.ami.leastsqnrm - INFO - 37 DO_NOT_USE pixels found in data slice
2026-04-15 20:16:04,194 - jwst.ami.leastsqnrm - INFO - flatimg (4724,) after deleting 37
2026-04-15 20:16:04,195 - jwst.ami.leastsqnrm - INFO - flatmodel_nan (4761, 44)
2026-04-15 20:16:04,195 - jwst.ami.leastsqnrm - INFO - flatmodel (4724, 44)
2026-04-15 20:16:04,196 - jwst.ami.leastsqnrm - INFO - difference 37
2026-04-15 20:16:04,196 - jwst.ami.leastsqnrm - INFO - flat model dimensions (4724, 44)
2026-04-15 20:16:04,197 - jwst.ami.leastsqnrm - INFO - flat image dimensions (4724,)
2026-04-15 20:16:04,199 - jwst.ami.leastsqnrm - INFO - data flux 2.7444835e+06
2026-04-15 20:16:04,200 - jwst.ami.leastsqnrm - INFO - flat model dimensions (4724, 44)
2026-04-15 20:16:04,200 - jwst.ami.leastsqnrm - INFO - model transpose dimensions (44, 4724)
2026-04-15 20:16:04,200 - jwst.ami.leastsqnrm - INFO - flat image dimensions (4724,)
2026-04-15 20:16:04,201 - jwst.ami.leastsqnrm - INFO - transpose * image data dimensions (44,)
2026-04-15 20:16:04,201 - jwst.ami.leastsqnrm - INFO - flat img * transpose dimensions (44, 44)
2026-04-15 20:16:04,202 - jwst.ami.leastsqnrm - INFO - linearfit not attempted, no covariances saved.
2026-04-15 20:16:04,203 - jwst.ami.nrm_core - INFO - Fitting fringes for iteration 68 of 69
2026-04-15 20:16:05,269 - jwst.ami.leastsqnrm - INFO - fringefitting.leastsqnrm.matrix_operations():
2026-04-15 20:16:05,269 - jwst.ami.leastsqnrm - INFO - img (69, 69)
2026-04-15 20:16:05,270 - jwst.ami.leastsqnrm - INFO - L x W = 69 x 69 = 4761
2026-04-15 20:16:05,270 - jwst.ami.leastsqnrm - INFO - flatimg (4761,)
2026-04-15 20:16:05,271 - jwst.ami.leastsqnrm - INFO -
2026-04-15 20:16:05,271 - jwst.ami.leastsqnrm - INFO - type(dqm) <class 'numpy.ndarray'>
2026-04-15 20:16:05,271 - jwst.ami.leastsqnrm - INFO - type(nanlist) <class 'tuple'>, len=1
2026-04-15 20:16:05,272 - jwst.ami.leastsqnrm - INFO - number of nanlist pixels: 37 items
2026-04-15 20:16:05,272 - jwst.ami.leastsqnrm - INFO - 37 DO_NOT_USE pixels found in data slice
2026-04-15 20:16:05,273 - jwst.ami.leastsqnrm - INFO - flatimg (4724,) after deleting 37
2026-04-15 20:16:05,274 - jwst.ami.leastsqnrm - INFO - flatmodel_nan (4761, 44)
2026-04-15 20:16:05,274 - jwst.ami.leastsqnrm - INFO - flatmodel (4724, 44)
2026-04-15 20:16:05,275 - jwst.ami.leastsqnrm - INFO - difference 37
2026-04-15 20:16:05,275 - jwst.ami.leastsqnrm - INFO - flat model dimensions (4724, 44)
2026-04-15 20:16:05,275 - jwst.ami.leastsqnrm - INFO - flat image dimensions (4724,)
2026-04-15 20:16:05,278 - jwst.ami.leastsqnrm - INFO - data flux 2.7633922e+06
2026-04-15 20:16:05,278 - jwst.ami.leastsqnrm - INFO - flat model dimensions (4724, 44)
2026-04-15 20:16:05,279 - jwst.ami.leastsqnrm - INFO - model transpose dimensions (44, 4724)
2026-04-15 20:16:05,279 - jwst.ami.leastsqnrm - INFO - flat image dimensions (4724,)
2026-04-15 20:16:05,280 - jwst.ami.leastsqnrm - INFO - transpose * image data dimensions (44,)
2026-04-15 20:16:05,280 - jwst.ami.leastsqnrm - INFO - flat img * transpose dimensions (44, 44)
2026-04-15 20:16:05,281 - jwst.ami.leastsqnrm - INFO - linearfit not attempted, no covariances saved.
2026-04-15 20:16:05,641 - stpipe.step - INFO - Saved model in ./nis_ami_demo_data/PID_1093/stage3/ami3_AB-DOR_F480M_02_ami-oi.fits
2026-04-15 20:16:05,745 - stpipe.step - INFO - Saved model in ./nis_ami_demo_data/PID_1093/stage3/ami3_AB-DOR_F480M_02_amimulti-oi.fits
2026-04-15 20:16:05,819 - stpipe.step - INFO - Saved model in ./nis_ami_demo_data/PID_1093/stage3/ami3_AB-DOR_F480M_02_amilg.fits
2026-04-15 20:16:05,820 - stpipe.step - INFO - Step ami_analyze done
2026-04-15 20:16:05,916 - stpipe.step - INFO - Saved model in ./nis_ami_demo_data/PID_1093/stage3/jw01093012001_03102_00001_nis_a3001_ami-oi.fits
2026-04-15 20:16:06,120 - stpipe.step - INFO - Step ami_analyze running with args ('/home/runner/work/jwst-pipeline-notebooks/jwst-pipeline-notebooks/notebooks/NIRISS/AMI/nis_ami_demo_data/PID_1093/stage2/jw01093015001_03102_00001_nis_calints.fits',).
2026-04-15 20:16:06,121 - jwst.ami.ami_analyze_step - INFO - Oversampling factor = 3
2026-04-15 20:16:06,121 - jwst.ami.ami_analyze_step - INFO - Initial rotation guess = 0.0 deg
2026-04-15 20:16:06,122 - jwst.ami.ami_analyze_step - INFO - Initial values to use for psf offset = [0.0, 0.0]
2026-04-15 20:16:06,207 - jwst.ami.ami_analyze_step - INFO - Using filter throughput reference file /home/runner/crds/references/jwst/niriss/jwst_niriss_throughput_0012.fits
2026-04-15 20:16:06,208 - jwst.ami.ami_analyze_step - INFO - Could not use affine2d from <jwst.ami.utils.Affine2d object at 0x7f7c4bf49a90>. See documentation for info on creating a custom bandpass ASDF file.
2026-04-15 20:16:06,209 - jwst.ami.ami_analyze_step - INFO - **** DEFAULTING TO USE IDENTITY TRANSFORM ****
2026-04-15 20:16:06,211 - jwst.ami.ami_analyze_step - INFO - Using NRM reference file /home/runner/crds/references/jwst/niriss/jwst_niriss_nrm_0004.fits
2026-04-15 20:16:06,233 - jwst.ami.utils - INFO - Reading throughput model data for F480M.
2026-04-15 20:16:06,410 - jwst.ami.utils - INFO - Using flat spectrum model.
2026-04-15 20:16:06,727 - jwst.ami.ami_analyze - INFO - Searching for best-fit affine transform
2026-04-15 20:16:06,728 - jwst.ami.ami_analyze - INFO - Initial values to use for rotation search: [-3. -2. -1. 0. 1. 2. 3.]
2026-04-15 20:16:06,735 - jwst.ami.ami_analyze - INFO - Replacing 439 NaNs in median image with median of surrounding pixels
2026-04-15 20:16:06,736 - py.warnings - WARNING - /home/runner/micromamba/envs/ci-env/lib/python3.13/site-packages/numpy/lib/_nanfunctions_impl.py:1213: RuntimeWarning: Mean of empty slice
return np.nanmean(a, axis, out=out, keepdims=keepdims)
2026-04-15 20:16:10,321 - jwst.ami.ami_analyze - INFO - Found rotation: -0.0055 rad (-0.3140 deg)
2026-04-15 20:16:10,322 - jwst.ami.ami_analyze - INFO - Using affine transform with parameters:
2026-04-15 20:16:10,322 - jwst.ami.ami_analyze - INFO - mx=0.999985 my=0.999985
2026-04-15 20:16:10,323 - jwst.ami.ami_analyze - INFO - sx=0.005480 sy=-0.005480
2026-04-15 20:16:10,323 - jwst.ami.ami_analyze - INFO - xo=0.000000 yo=0.000000
2026-04-15 20:16:10,324 - jwst.ami.ami_analyze - INFO - rotradccw=-0.005480167602748006
2026-04-15 20:16:10,324 - jwst.ami.nrm_core - INFO - leastsqnrm.matrix_operations() - equally-weighted
2026-04-15 20:16:10,326 - jwst.ami.instrument_data - INFO - Rotating mask hole centers clockwise by 171.979 degrees
2026-04-15 20:16:10,333 - jwst.ami.instrument_data - INFO - 0 additional pixels >10-sig from median of stack found
2026-04-15 20:16:10,334 - jwst.ami.instrument_data - INFO - 0 DO_NOT_USE flags added to DQ array for found outlier pixels
2026-04-15 20:16:10,335 - jwst.ami.instrument_data - INFO - Cropping all integrations to 69x69 pixels around peak (40,45)
2026-04-15 20:16:10,335 - jwst.ami.instrument_data - INFO - Applying Fourier bad pixel correction to cropped data, updating DQ array
2026-04-15 20:16:10,337 - jwst.ami.bp_fix - INFO - 2380 pixels flagged DO_NOT_USE in cropped data
2026-04-15 20:16:10,338 - jwst.ami.bp_fix - INFO - Identified 2196 NaN pixels to correct
2026-04-15 20:16:10,340 - jwst.ami.bp_fix - INFO - FOV = 4.5 arcsec, Fourier sampling = 0.223 m/pix
2026-04-15 20:16:10,340 - jwst.ami.bp_fix - INFO - F480M: 4.817 to 4.986 micron
2026-04-15 20:16:10,375 - jwst.ami.bp_fix - INFO - Frame 1 of 61
2026-04-15 20:16:10,384 - jwst.ami.bp_fix - INFO - Identified 0 bad pixels (0.00%)
2026-04-15 20:16:10,385 - jwst.ami.bp_fix - INFO - 16.282
2026-04-15 20:16:10,386 - jwst.ami.bp_fix - INFO - Iteration 1: 0 new bad pixels, sdev of norm noise = 0.488
2026-04-15 20:16:10,392 - jwst.ami.bp_fix - INFO - Frame 2 of 61
2026-04-15 20:16:10,399 - jwst.ami.bp_fix - INFO - Identified 0 bad pixels (0.00%)
2026-04-15 20:16:10,400 - jwst.ami.bp_fix - INFO - 22.806
2026-04-15 20:16:10,401 - jwst.ami.bp_fix - INFO - Iteration 1: 0 new bad pixels, sdev of norm noise = 0.486
2026-04-15 20:16:10,407 - jwst.ami.bp_fix - INFO - Frame 3 of 61
2026-04-15 20:16:10,413 - jwst.ami.bp_fix - INFO - Identified 0 bad pixels (0.00%)
2026-04-15 20:16:10,414 - jwst.ami.bp_fix - INFO - 12.093
2026-04-15 20:16:10,416 - jwst.ami.bp_fix - INFO - Iteration 1: 0 new bad pixels, sdev of norm noise = 0.483
2026-04-15 20:16:10,421 - jwst.ami.bp_fix - INFO - Frame 4 of 61
2026-04-15 20:16:10,428 - jwst.ami.bp_fix - INFO - Identified 0 bad pixels (0.00%)
2026-04-15 20:16:10,429 - jwst.ami.bp_fix - INFO - 11.152
2026-04-15 20:16:10,430 - jwst.ami.bp_fix - INFO - Iteration 1: 0 new bad pixels, sdev of norm noise = 0.491
2026-04-15 20:16:10,435 - jwst.ami.bp_fix - INFO - Frame 5 of 61
2026-04-15 20:16:10,442 - jwst.ami.bp_fix - INFO - Identified 0 bad pixels (0.00%)
2026-04-15 20:16:10,443 - jwst.ami.bp_fix - INFO - 15.319
2026-04-15 20:16:10,443 - jwst.ami.bp_fix - INFO - Iteration 1: 0 new bad pixels, sdev of norm noise = 0.487
2026-04-15 20:16:10,448 - jwst.ami.bp_fix - INFO - Frame 6 of 61
2026-04-15 20:16:10,455 - jwst.ami.bp_fix - INFO - Identified 0 bad pixels (0.00%)
2026-04-15 20:16:10,456 - jwst.ami.bp_fix - INFO - 13.970
2026-04-15 20:16:10,456 - jwst.ami.bp_fix - INFO - Iteration 1: 0 new bad pixels, sdev of norm noise = 0.476
2026-04-15 20:16:10,461 - jwst.ami.bp_fix - INFO - Frame 7 of 61
2026-04-15 20:16:10,467 - jwst.ami.bp_fix - INFO - Identified 0 bad pixels (0.00%)
2026-04-15 20:16:10,468 - jwst.ami.bp_fix - INFO - 21.740
2026-04-15 20:16:10,469 - jwst.ami.bp_fix - INFO - Iteration 1: 0 new bad pixels, sdev of norm noise = 0.480
2026-04-15 20:16:10,473 - jwst.ami.bp_fix - INFO - Frame 8 of 61
2026-04-15 20:16:10,480 - jwst.ami.bp_fix - INFO - Identified 0 bad pixels (0.00%)
2026-04-15 20:16:10,481 - jwst.ami.bp_fix - INFO - 16.629
2026-04-15 20:16:10,481 - jwst.ami.bp_fix - INFO - Iteration 1: 0 new bad pixels, sdev of norm noise = 0.491
2026-04-15 20:16:10,486 - jwst.ami.bp_fix - INFO - Frame 9 of 61
2026-04-15 20:16:10,493 - jwst.ami.bp_fix - INFO - Identified 0 bad pixels (0.00%)
2026-04-15 20:16:10,494 - jwst.ami.bp_fix - INFO - 15.579
2026-04-15 20:16:10,494 - jwst.ami.bp_fix - INFO - Iteration 1: 0 new bad pixels, sdev of norm noise = 0.494
2026-04-15 20:16:10,500 - jwst.ami.bp_fix - INFO - Frame 10 of 61
2026-04-15 20:16:10,507 - jwst.ami.bp_fix - INFO - Identified 0 bad pixels (0.00%)
2026-04-15 20:16:10,507 - jwst.ami.bp_fix - INFO - 18.705
2026-04-15 20:16:10,508 - jwst.ami.bp_fix - INFO - Iteration 1: 0 new bad pixels, sdev of norm noise = 0.488
2026-04-15 20:16:10,513 - jwst.ami.bp_fix - INFO - Frame 11 of 61
2026-04-15 20:16:10,520 - jwst.ami.bp_fix - INFO - Identified 0 bad pixels (0.00%)
2026-04-15 20:16:10,520 - jwst.ami.bp_fix - INFO - 16.002
2026-04-15 20:16:10,521 - jwst.ami.bp_fix - INFO - Iteration 1: 0 new bad pixels, sdev of norm noise = 0.488
2026-04-15 20:16:10,526 - jwst.ami.bp_fix - INFO - Frame 12 of 61
2026-04-15 20:16:10,533 - jwst.ami.bp_fix - INFO - Identified 0 bad pixels (0.00%)
2026-04-15 20:16:10,535 - jwst.ami.bp_fix - INFO - 17.010
2026-04-15 20:16:10,536 - jwst.ami.bp_fix - INFO - Iteration 1: 0 new bad pixels, sdev of norm noise = 0.490
2026-04-15 20:16:10,542 - jwst.ami.bp_fix - INFO - Frame 13 of 61
2026-04-15 20:16:10,550 - jwst.ami.bp_fix - INFO - Identified 0 bad pixels (0.00%)
2026-04-15 20:16:10,550 - jwst.ami.bp_fix - INFO - 20.125
2026-04-15 20:16:10,552 - jwst.ami.bp_fix - INFO - Iteration 1: 0 new bad pixels, sdev of norm noise = 0.487
2026-04-15 20:16:10,558 - jwst.ami.bp_fix - INFO - Frame 14 of 61
2026-04-15 20:16:10,565 - jwst.ami.bp_fix - INFO - Identified 0 bad pixels (0.00%)
2026-04-15 20:16:10,566 - jwst.ami.bp_fix - INFO - 11.666
2026-04-15 20:16:10,567 - jwst.ami.bp_fix - INFO - Iteration 1: 0 new bad pixels, sdev of norm noise = 0.492
2026-04-15 20:16:10,573 - jwst.ami.bp_fix - INFO - Frame 15 of 61
2026-04-15 20:16:10,580 - jwst.ami.bp_fix - INFO - Identified 0 bad pixels (0.00%)
2026-04-15 20:16:10,581 - jwst.ami.bp_fix - INFO - 18.430
2026-04-15 20:16:10,582 - jwst.ami.bp_fix - INFO - Iteration 1: 0 new bad pixels, sdev of norm noise = 0.495
2026-04-15 20:16:10,588 - jwst.ami.bp_fix - INFO - Frame 16 of 61
2026-04-15 20:16:10,595 - jwst.ami.bp_fix - INFO - Identified 0 bad pixels (0.00%)
2026-04-15 20:16:10,596 - jwst.ami.bp_fix - INFO - 15.828
2026-04-15 20:16:10,597 - jwst.ami.bp_fix - INFO - Iteration 1: 0 new bad pixels, sdev of norm noise = 0.480
2026-04-15 20:16:10,602 - jwst.ami.bp_fix - INFO - Frame 17 of 61
2026-04-15 20:16:10,609 - jwst.ami.bp_fix - INFO - Identified 0 bad pixels (0.00%)
2026-04-15 20:16:10,611 - jwst.ami.bp_fix - INFO - 15.666
2026-04-15 20:16:10,612 - jwst.ami.bp_fix - INFO - Iteration 1: 0 new bad pixels, sdev of norm noise = 0.491
2026-04-15 20:16:10,617 - jwst.ami.bp_fix - INFO - Frame 18 of 61
2026-04-15 20:16:10,624 - jwst.ami.bp_fix - INFO - Identified 0 bad pixels (0.00%)
2026-04-15 20:16:10,625 - jwst.ami.bp_fix - INFO - 20.669
2026-04-15 20:16:10,626 - jwst.ami.bp_fix - INFO - Iteration 1: 0 new bad pixels, sdev of norm noise = 0.484
2026-04-15 20:16:10,632 - jwst.ami.bp_fix - INFO - Frame 19 of 61
2026-04-15 20:16:10,639 - jwst.ami.bp_fix - INFO - Identified 0 bad pixels (0.00%)
2026-04-15 20:16:10,639 - jwst.ami.bp_fix - INFO - 18.354
2026-04-15 20:16:10,641 - jwst.ami.bp_fix - INFO - Iteration 1: 0 new bad pixels, sdev of norm noise = 0.491
2026-04-15 20:16:10,646 - jwst.ami.bp_fix - INFO - Frame 20 of 61
2026-04-15 20:16:10,653 - jwst.ami.bp_fix - INFO - Identified 0 bad pixels (0.00%)
2026-04-15 20:16:10,655 - jwst.ami.bp_fix - INFO - 14.514
2026-04-15 20:16:10,656 - jwst.ami.bp_fix - INFO - Iteration 1: 0 new bad pixels, sdev of norm noise = 0.494
2026-04-15 20:16:10,662 - jwst.ami.bp_fix - INFO - Frame 21 of 61
2026-04-15 20:16:10,669 - jwst.ami.bp_fix - INFO - Identified 0 bad pixels (0.00%)
2026-04-15 20:16:10,670 - jwst.ami.bp_fix - INFO - 13.478
2026-04-15 20:16:10,671 - jwst.ami.bp_fix - INFO - Iteration 1: 0 new bad pixels, sdev of norm noise = 0.480
2026-04-15 20:16:10,678 - jwst.ami.bp_fix - INFO - Frame 22 of 61
2026-04-15 20:16:10,685 - jwst.ami.bp_fix - INFO - Identified 0 bad pixels (0.00%)
2026-04-15 20:16:10,686 - jwst.ami.bp_fix - INFO - 15.715
2026-04-15 20:16:10,687 - jwst.ami.bp_fix - INFO - Iteration 1: 0 new bad pixels, sdev of norm noise = 0.495
2026-04-15 20:16:10,692 - jwst.ami.bp_fix - INFO - Frame 23 of 61
2026-04-15 20:16:10,699 - jwst.ami.bp_fix - INFO - Identified 0 bad pixels (0.00%)
2026-04-15 20:16:10,700 - jwst.ami.bp_fix - INFO - 17.045
2026-04-15 20:16:10,701 - jwst.ami.bp_fix - INFO - Iteration 1: 0 new bad pixels, sdev of norm noise = 0.475
2026-04-15 20:16:10,707 - jwst.ami.bp_fix - INFO - Frame 24 of 61
2026-04-15 20:16:10,714 - jwst.ami.bp_fix - INFO - Identified 0 bad pixels (0.00%)
2026-04-15 20:16:10,715 - jwst.ami.bp_fix - INFO - 12.418
2026-04-15 20:16:10,716 - jwst.ami.bp_fix - INFO - Iteration 1: 0 new bad pixels, sdev of norm noise = 0.487
2026-04-15 20:16:10,721 - jwst.ami.bp_fix - INFO - Frame 25 of 61
2026-04-15 20:16:10,729 - jwst.ami.bp_fix - INFO - Identified 0 bad pixels (0.00%)
2026-04-15 20:16:10,730 - jwst.ami.bp_fix - INFO - 15.354
2026-04-15 20:16:10,731 - jwst.ami.bp_fix - INFO - Iteration 1: 0 new bad pixels, sdev of norm noise = 0.486
2026-04-15 20:16:10,738 - jwst.ami.bp_fix - INFO - Frame 26 of 61
2026-04-15 20:16:10,745 - jwst.ami.bp_fix - INFO - Identified 0 bad pixels (0.00%)
2026-04-15 20:16:10,746 - jwst.ami.bp_fix - INFO - 12.577
2026-04-15 20:16:10,747 - jwst.ami.bp_fix - INFO - Iteration 1: 0 new bad pixels, sdev of norm noise = 0.483
2026-04-15 20:16:10,753 - jwst.ami.bp_fix - INFO - Frame 27 of 61
2026-04-15 20:16:10,760 - jwst.ami.bp_fix - INFO - Identified 0 bad pixels (0.00%)
2026-04-15 20:16:10,762 - jwst.ami.bp_fix - INFO - 17.428
2026-04-15 20:16:10,763 - jwst.ami.bp_fix - INFO - Iteration 1: 0 new bad pixels, sdev of norm noise = 0.483
2026-04-15 20:16:10,768 - jwst.ami.bp_fix - INFO - Frame 28 of 61
2026-04-15 20:16:10,776 - jwst.ami.bp_fix - INFO - Identified 0 bad pixels (0.00%)
2026-04-15 20:16:10,777 - jwst.ami.bp_fix - INFO - 17.988
2026-04-15 20:16:10,778 - jwst.ami.bp_fix - INFO - Iteration 1: 0 new bad pixels, sdev of norm noise = 0.493
2026-04-15 20:16:10,784 - jwst.ami.bp_fix - INFO - Frame 29 of 61
2026-04-15 20:16:10,791 - jwst.ami.bp_fix - INFO - Identified 0 bad pixels (0.00%)
2026-04-15 20:16:10,792 - jwst.ami.bp_fix - INFO - 16.623
2026-04-15 20:16:10,793 - jwst.ami.bp_fix - INFO - Iteration 1: 0 new bad pixels, sdev of norm noise = 0.476
2026-04-15 20:16:10,799 - jwst.ami.bp_fix - INFO - Frame 30 of 61
2026-04-15 20:16:10,806 - jwst.ami.bp_fix - INFO - Identified 0 bad pixels (0.00%)
2026-04-15 20:16:10,808 - jwst.ami.bp_fix - INFO - 21.112
2026-04-15 20:16:10,809 - jwst.ami.bp_fix - INFO - Iteration 1: 0 new bad pixels, sdev of norm noise = 0.489
2026-04-15 20:16:10,815 - jwst.ami.bp_fix - INFO - Frame 31 of 61
2026-04-15 20:16:10,822 - jwst.ami.bp_fix - INFO - Identified 0 bad pixels (0.00%)
2026-04-15 20:16:10,823 - jwst.ami.bp_fix - INFO - 13.223
2026-04-15 20:16:10,824 - jwst.ami.bp_fix - INFO - Iteration 1: 0 new bad pixels, sdev of norm noise = 0.479
2026-04-15 20:16:10,829 - jwst.ami.bp_fix - INFO - Frame 32 of 61
2026-04-15 20:16:10,837 - jwst.ami.bp_fix - INFO - Identified 0 bad pixels (0.00%)
2026-04-15 20:16:10,838 - jwst.ami.bp_fix - INFO - 13.916
2026-04-15 20:16:10,839 - jwst.ami.bp_fix - INFO - Iteration 1: 0 new bad pixels, sdev of norm noise = 0.482
2026-04-15 20:16:10,845 - jwst.ami.bp_fix - INFO - Frame 33 of 61
2026-04-15 20:16:10,852 - jwst.ami.bp_fix - INFO - Identified 0 bad pixels (0.00%)
2026-04-15 20:16:10,853 - jwst.ami.bp_fix - INFO - 16.777
2026-04-15 20:16:10,854 - jwst.ami.bp_fix - INFO - Iteration 1: 0 new bad pixels, sdev of norm noise = 0.477
2026-04-15 20:16:10,860 - jwst.ami.bp_fix - INFO - Frame 34 of 61
2026-04-15 20:16:10,867 - jwst.ami.bp_fix - INFO - Identified 0 bad pixels (0.00%)
2026-04-15 20:16:10,869 - jwst.ami.bp_fix - INFO - 24.543
2026-04-15 20:16:10,870 - jwst.ami.bp_fix - INFO - Iteration 1: 0 new bad pixels, sdev of norm noise = 0.501
2026-04-15 20:16:10,875 - jwst.ami.bp_fix - INFO - Frame 35 of 61
2026-04-15 20:16:10,882 - jwst.ami.bp_fix - INFO - Identified 0 bad pixels (0.00%)
2026-04-15 20:16:10,884 - jwst.ami.bp_fix - INFO - 18.041
2026-04-15 20:16:10,885 - jwst.ami.bp_fix - INFO - Iteration 1: 0 new bad pixels, sdev of norm noise = 0.489
2026-04-15 20:16:10,890 - jwst.ami.bp_fix - INFO - Frame 36 of 61
2026-04-15 20:16:10,898 - jwst.ami.bp_fix - INFO - Identified 0 bad pixels (0.00%)
2026-04-15 20:16:10,899 - jwst.ami.bp_fix - INFO - 13.791
2026-04-15 20:16:10,900 - jwst.ami.bp_fix - INFO - Iteration 1: 0 new bad pixels, sdev of norm noise = 0.489
2026-04-15 20:16:10,906 - jwst.ami.bp_fix - INFO - Frame 37 of 61
2026-04-15 20:16:10,913 - jwst.ami.bp_fix - INFO - Identified 0 bad pixels (0.00%)
2026-04-15 20:16:10,915 - jwst.ami.bp_fix - INFO - 17.801
2026-04-15 20:16:10,916 - jwst.ami.bp_fix - INFO - Iteration 1: 0 new bad pixels, sdev of norm noise = 0.471
2026-04-15 20:16:10,921 - jwst.ami.bp_fix - INFO - Frame 38 of 61
2026-04-15 20:16:10,929 - jwst.ami.bp_fix - INFO - Identified 0 bad pixels (0.00%)
2026-04-15 20:16:10,930 - jwst.ami.bp_fix - INFO - 16.910
2026-04-15 20:16:10,931 - jwst.ami.bp_fix - INFO - Iteration 1: 0 new bad pixels, sdev of norm noise = 0.500
2026-04-15 20:16:10,937 - jwst.ami.bp_fix - INFO - Frame 39 of 61
2026-04-15 20:16:10,944 - jwst.ami.bp_fix - INFO - Identified 0 bad pixels (0.00%)
2026-04-15 20:16:10,945 - jwst.ami.bp_fix - INFO - 14.869
2026-04-15 20:16:10,946 - jwst.ami.bp_fix - INFO - Iteration 1: 0 new bad pixels, sdev of norm noise = 0.483
2026-04-15 20:16:10,952 - jwst.ami.bp_fix - INFO - Frame 40 of 61
2026-04-15 20:16:10,959 - jwst.ami.bp_fix - INFO - Identified 0 bad pixels (0.00%)
2026-04-15 20:16:10,960 - jwst.ami.bp_fix - INFO - 22.367
2026-04-15 20:16:10,962 - jwst.ami.bp_fix - INFO - Iteration 1: 0 new bad pixels, sdev of norm noise = 0.496
2026-04-15 20:16:10,967 - jwst.ami.bp_fix - INFO - Frame 41 of 61
2026-04-15 20:16:10,974 - jwst.ami.bp_fix - INFO - Identified 0 bad pixels (0.00%)
2026-04-15 20:16:10,976 - jwst.ami.bp_fix - INFO - 16.227
2026-04-15 20:16:10,977 - jwst.ami.bp_fix - INFO - Iteration 1: 0 new bad pixels, sdev of norm noise = 0.478
2026-04-15 20:16:10,985 - jwst.ami.bp_fix - INFO - Frame 42 of 61
2026-04-15 20:16:10,992 - jwst.ami.bp_fix - INFO - Identified 0 bad pixels (0.00%)
2026-04-15 20:16:10,994 - jwst.ami.bp_fix - INFO - 18.333
2026-04-15 20:16:10,995 - jwst.ami.bp_fix - INFO - Iteration 1: 0 new bad pixels, sdev of norm noise = 0.486
2026-04-15 20:16:11,000 - jwst.ami.bp_fix - INFO - Frame 43 of 61
2026-04-15 20:16:11,007 - jwst.ami.bp_fix - INFO - Identified 0 bad pixels (0.00%)
2026-04-15 20:16:11,008 - jwst.ami.bp_fix - INFO - 12.988
2026-04-15 20:16:11,009 - jwst.ami.bp_fix - INFO - Iteration 1: 0 new bad pixels, sdev of norm noise = 0.485
2026-04-15 20:16:11,015 - jwst.ami.bp_fix - INFO - Frame 44 of 61
2026-04-15 20:16:11,022 - jwst.ami.bp_fix - INFO - Identified 0 bad pixels (0.00%)
2026-04-15 20:16:11,024 - jwst.ami.bp_fix - INFO - 20.940
2026-04-15 20:16:11,025 - jwst.ami.bp_fix - INFO - Iteration 1: 0 new bad pixels, sdev of norm noise = 0.491
2026-04-15 20:16:11,030 - jwst.ami.bp_fix - INFO - Frame 45 of 61
2026-04-15 20:16:11,038 - jwst.ami.bp_fix - INFO - Identified 0 bad pixels (0.00%)
2026-04-15 20:16:11,039 - jwst.ami.bp_fix - INFO - 19.796
2026-04-15 20:16:11,041 - jwst.ami.bp_fix - INFO - Iteration 1: 0 new bad pixels, sdev of norm noise = 0.479
2026-04-15 20:16:11,047 - jwst.ami.bp_fix - INFO - Frame 46 of 61
2026-04-15 20:16:11,054 - jwst.ami.bp_fix - INFO - Identified 0 bad pixels (0.00%)
2026-04-15 20:16:11,055 - jwst.ami.bp_fix - INFO - 17.211
2026-04-15 20:16:11,057 - jwst.ami.bp_fix - INFO - Iteration 1: 0 new bad pixels, sdev of norm noise = 0.478
2026-04-15 20:16:11,062 - jwst.ami.bp_fix - INFO - Frame 47 of 61
2026-04-15 20:16:11,069 - jwst.ami.bp_fix - INFO - Identified 0 bad pixels (0.00%)
2026-04-15 20:16:11,070 - jwst.ami.bp_fix - INFO - 16.383
2026-04-15 20:16:11,071 - jwst.ami.bp_fix - INFO - Iteration 1: 0 new bad pixels, sdev of norm noise = 0.489
2026-04-15 20:16:11,078 - jwst.ami.bp_fix - INFO - Frame 48 of 61
2026-04-15 20:16:11,086 - jwst.ami.bp_fix - INFO - Identified 0 bad pixels (0.00%)
2026-04-15 20:16:11,087 - jwst.ami.bp_fix - INFO - 17.444
2026-04-15 20:16:11,088 - jwst.ami.bp_fix - INFO - Iteration 1: 0 new bad pixels, sdev of norm noise = 0.475
2026-04-15 20:16:11,094 - jwst.ami.bp_fix - INFO - Frame 49 of 61
2026-04-15 20:16:11,101 - jwst.ami.bp_fix - INFO - Identified 0 bad pixels (0.00%)
2026-04-15 20:16:11,103 - jwst.ami.bp_fix - INFO - 16.141
2026-04-15 20:16:11,104 - jwst.ami.bp_fix - INFO - Iteration 1: 0 new bad pixels, sdev of norm noise = 0.489
2026-04-15 20:16:11,109 - jwst.ami.bp_fix - INFO - Frame 50 of 61
2026-04-15 20:16:11,117 - jwst.ami.bp_fix - INFO - Identified 0 bad pixels (0.00%)
2026-04-15 20:16:11,118 - jwst.ami.bp_fix - INFO - 16.609
2026-04-15 20:16:11,119 - jwst.ami.bp_fix - INFO - Iteration 1: 0 new bad pixels, sdev of norm noise = 0.484
2026-04-15 20:16:11,125 - jwst.ami.bp_fix - INFO - Frame 51 of 61
2026-04-15 20:16:11,132 - jwst.ami.bp_fix - INFO - Identified 0 bad pixels (0.00%)
2026-04-15 20:16:11,133 - jwst.ami.bp_fix - INFO - 13.163
2026-04-15 20:16:11,134 - jwst.ami.bp_fix - INFO - Iteration 1: 0 new bad pixels, sdev of norm noise = 0.488
2026-04-15 20:16:11,140 - jwst.ami.bp_fix - INFO - Frame 52 of 61
2026-04-15 20:16:11,146 - jwst.ami.bp_fix - INFO - Identified 0 bad pixels (0.00%)
2026-04-15 20:16:11,148 - jwst.ami.bp_fix - INFO - 17.378
2026-04-15 20:16:11,149 - jwst.ami.bp_fix - INFO - Iteration 1: 0 new bad pixels, sdev of norm noise = 0.478
2026-04-15 20:16:11,154 - jwst.ami.bp_fix - INFO - Frame 53 of 61
2026-04-15 20:16:11,161 - jwst.ami.bp_fix - INFO - Identified 0 bad pixels (0.00%)
2026-04-15 20:16:11,163 - jwst.ami.bp_fix - INFO - 16.394
2026-04-15 20:16:11,164 - jwst.ami.bp_fix - INFO - Iteration 1: 0 new bad pixels, sdev of norm noise = 0.482
2026-04-15 20:16:11,169 - jwst.ami.bp_fix - INFO - Frame 54 of 61
2026-04-15 20:16:11,177 - jwst.ami.bp_fix - INFO - Identified 0 bad pixels (0.00%)
2026-04-15 20:16:11,178 - jwst.ami.bp_fix - INFO - 16.563
2026-04-15 20:16:11,179 - jwst.ami.bp_fix - INFO - Iteration 1: 0 new bad pixels, sdev of norm noise = 0.488
2026-04-15 20:16:11,185 - jwst.ami.bp_fix - INFO - Frame 55 of 61
2026-04-15 20:16:11,192 - jwst.ami.bp_fix - INFO - Identified 0 bad pixels (0.00%)
2026-04-15 20:16:11,194 - jwst.ami.bp_fix - INFO - 12.153
2026-04-15 20:16:11,195 - jwst.ami.bp_fix - INFO - Iteration 1: 0 new bad pixels, sdev of norm noise = 0.504
2026-04-15 20:16:11,200 - jwst.ami.bp_fix - INFO - Frame 56 of 61
2026-04-15 20:16:11,207 - jwst.ami.bp_fix - INFO - Identified 0 bad pixels (0.00%)
2026-04-15 20:16:11,209 - jwst.ami.bp_fix - INFO - 18.506
2026-04-15 20:16:11,210 - jwst.ami.bp_fix - INFO - Iteration 1: 0 new bad pixels, sdev of norm noise = 0.486
2026-04-15 20:16:11,215 - jwst.ami.bp_fix - INFO - Frame 57 of 61
2026-04-15 20:16:11,223 - jwst.ami.bp_fix - INFO - Identified 0 bad pixels (0.00%)
2026-04-15 20:16:11,224 - jwst.ami.bp_fix - INFO - 13.017
2026-04-15 20:16:11,225 - jwst.ami.bp_fix - INFO - Iteration 1: 0 new bad pixels, sdev of norm noise = 0.492
2026-04-15 20:16:11,232 - jwst.ami.bp_fix - INFO - Frame 58 of 61
2026-04-15 20:16:11,239 - jwst.ami.bp_fix - INFO - Identified 0 bad pixels (0.00%)
2026-04-15 20:16:11,240 - jwst.ami.bp_fix - INFO - 16.055
2026-04-15 20:16:11,241 - jwst.ami.bp_fix - INFO - Iteration 1: 0 new bad pixels, sdev of norm noise = 0.485
2026-04-15 20:16:11,247 - jwst.ami.bp_fix - INFO - Frame 59 of 61
2026-04-15 20:16:11,254 - jwst.ami.bp_fix - INFO - Identified 0 bad pixels (0.00%)
2026-04-15 20:16:11,256 - jwst.ami.bp_fix - INFO - 20.476
2026-04-15 20:16:11,257 - jwst.ami.bp_fix - INFO - Iteration 1: 0 new bad pixels, sdev of norm noise = 0.483
2026-04-15 20:16:11,263 - jwst.ami.bp_fix - INFO - Frame 60 of 61
2026-04-15 20:16:11,270 - jwst.ami.bp_fix - INFO - Identified 0 bad pixels (0.00%)
2026-04-15 20:16:11,271 - jwst.ami.bp_fix - INFO - 17.496
2026-04-15 20:16:11,272 - jwst.ami.bp_fix - INFO - Iteration 1: 0 new bad pixels, sdev of norm noise = 0.485
2026-04-15 20:16:11,278 - jwst.ami.bp_fix - INFO - Frame 61 of 61
2026-04-15 20:16:11,285 - jwst.ami.bp_fix - INFO - Identified 0 bad pixels (0.00%)
2026-04-15 20:16:11,286 - jwst.ami.bp_fix - INFO - 17.379
2026-04-15 20:16:11,287 - jwst.ami.bp_fix - INFO - Iteration 1: 0 new bad pixels, sdev of norm noise = 0.506
2026-04-15 20:16:11,293 - jwst.ami.instrument_data - INFO - usebp flag set to TRUE: bad pixels will be excluded from model fit
2026-04-15 20:16:11,295 - jwst.ami.nrm_core - INFO - Fitting fringes for iteration 0 of 61
2026-04-15 20:16:12,362 - jwst.ami.leastsqnrm - INFO - fringefitting.leastsqnrm.matrix_operations():
2026-04-15 20:16:12,363 - jwst.ami.leastsqnrm - INFO - img (69, 69)
2026-04-15 20:16:12,363 - jwst.ami.leastsqnrm - INFO - L x W = 69 x 69 = 4761
2026-04-15 20:16:12,364 - jwst.ami.leastsqnrm - INFO - flatimg (4761,)
2026-04-15 20:16:12,364 - jwst.ami.leastsqnrm - INFO -
2026-04-15 20:16:12,364 - jwst.ami.leastsqnrm - INFO - type(dqm) <class 'numpy.ndarray'>
2026-04-15 20:16:12,365 - jwst.ami.leastsqnrm - INFO - type(nanlist) <class 'tuple'>, len=1
2026-04-15 20:16:12,365 - jwst.ami.leastsqnrm - INFO - number of nanlist pixels: 39 items
2026-04-15 20:16:12,366 - jwst.ami.leastsqnrm - INFO - 39 DO_NOT_USE pixels found in data slice
2026-04-15 20:16:12,366 - jwst.ami.leastsqnrm - INFO - flatimg (4722,) after deleting 39
2026-04-15 20:16:12,367 - jwst.ami.leastsqnrm - INFO - flatmodel_nan (4761, 44)
2026-04-15 20:16:12,367 - jwst.ami.leastsqnrm - INFO - flatmodel (4722, 44)
2026-04-15 20:16:12,368 - jwst.ami.leastsqnrm - INFO - difference 39
2026-04-15 20:16:12,368 - jwst.ami.leastsqnrm - INFO - flat model dimensions (4722, 44)
2026-04-15 20:16:12,369 - jwst.ami.leastsqnrm - INFO - flat image dimensions (4722,)
2026-04-15 20:16:12,371 - jwst.ami.leastsqnrm - INFO - data flux 1.0185039e+06
2026-04-15 20:16:12,372 - jwst.ami.leastsqnrm - INFO - flat model dimensions (4722, 44)
2026-04-15 20:16:12,372 - jwst.ami.leastsqnrm - INFO - model transpose dimensions (44, 4722)
2026-04-15 20:16:12,372 - jwst.ami.leastsqnrm - INFO - flat image dimensions (4722,)
2026-04-15 20:16:12,373 - jwst.ami.leastsqnrm - INFO - transpose * image data dimensions (44,)
2026-04-15 20:16:12,373 - jwst.ami.leastsqnrm - INFO - flat img * transpose dimensions (44, 44)
2026-04-15 20:16:12,374 - jwst.ami.leastsqnrm - INFO - linearfit not attempted, no covariances saved.
2026-04-15 20:16:12,375 - jwst.ami.nrm_core - INFO - Fitting fringes for iteration 1 of 61
2026-04-15 20:16:13,436 - jwst.ami.leastsqnrm - INFO - fringefitting.leastsqnrm.matrix_operations():
2026-04-15 20:16:13,436 - jwst.ami.leastsqnrm - INFO - img (69, 69)
2026-04-15 20:16:13,437 - jwst.ami.leastsqnrm - INFO - L x W = 69 x 69 = 4761
2026-04-15 20:16:13,437 - jwst.ami.leastsqnrm - INFO - flatimg (4761,)
2026-04-15 20:16:13,437 - jwst.ami.leastsqnrm - INFO -
2026-04-15 20:16:13,438 - jwst.ami.leastsqnrm - INFO - type(dqm) <class 'numpy.ndarray'>
2026-04-15 20:16:13,438 - jwst.ami.leastsqnrm - INFO - type(nanlist) <class 'tuple'>, len=1
2026-04-15 20:16:13,439 - jwst.ami.leastsqnrm - INFO - number of nanlist pixels: 38 items
2026-04-15 20:16:13,439 - jwst.ami.leastsqnrm - INFO - 38 DO_NOT_USE pixels found in data slice
2026-04-15 20:16:13,440 - jwst.ami.leastsqnrm - INFO - flatimg (4723,) after deleting 38
2026-04-15 20:16:13,441 - jwst.ami.leastsqnrm - INFO - flatmodel_nan (4761, 44)
2026-04-15 20:16:13,441 - jwst.ami.leastsqnrm - INFO - flatmodel (4723, 44)
2026-04-15 20:16:13,441 - jwst.ami.leastsqnrm - INFO - difference 38
2026-04-15 20:16:13,442 - jwst.ami.leastsqnrm - INFO - flat model dimensions (4723, 44)
2026-04-15 20:16:13,442 - jwst.ami.leastsqnrm - INFO - flat image dimensions (4723,)
2026-04-15 20:16:13,445 - jwst.ami.leastsqnrm - INFO - data flux 1.0292195e+06
2026-04-15 20:16:13,445 - jwst.ami.leastsqnrm - INFO - flat model dimensions (4723, 44)
2026-04-15 20:16:13,446 - jwst.ami.leastsqnrm - INFO - model transpose dimensions (44, 4723)
2026-04-15 20:16:13,446 - jwst.ami.leastsqnrm - INFO - flat image dimensions (4723,)
2026-04-15 20:16:13,447 - jwst.ami.leastsqnrm - INFO - transpose * image data dimensions (44,)
2026-04-15 20:16:13,447 - jwst.ami.leastsqnrm - INFO - flat img * transpose dimensions (44, 44)
2026-04-15 20:16:13,448 - jwst.ami.leastsqnrm - INFO - linearfit not attempted, no covariances saved.
2026-04-15 20:16:13,449 - jwst.ami.nrm_core - INFO - Fitting fringes for iteration 2 of 61
2026-04-15 20:16:14,501 - jwst.ami.leastsqnrm - INFO - fringefitting.leastsqnrm.matrix_operations():
2026-04-15 20:16:14,502 - jwst.ami.leastsqnrm - INFO - img (69, 69)
2026-04-15 20:16:14,502 - jwst.ami.leastsqnrm - INFO - L x W = 69 x 69 = 4761
2026-04-15 20:16:14,503 - jwst.ami.leastsqnrm - INFO - flatimg (4761,)
2026-04-15 20:16:14,503 - jwst.ami.leastsqnrm - INFO -
2026-04-15 20:16:14,503 - jwst.ami.leastsqnrm - INFO - type(dqm) <class 'numpy.ndarray'>
2026-04-15 20:16:14,504 - jwst.ami.leastsqnrm - INFO - type(nanlist) <class 'tuple'>, len=1
2026-04-15 20:16:14,504 - jwst.ami.leastsqnrm - INFO - number of nanlist pixels: 37 items
2026-04-15 20:16:14,505 - jwst.ami.leastsqnrm - INFO - 37 DO_NOT_USE pixels found in data slice
2026-04-15 20:16:14,505 - jwst.ami.leastsqnrm - INFO - flatimg (4724,) after deleting 37
2026-04-15 20:16:14,506 - jwst.ami.leastsqnrm - INFO - flatmodel_nan (4761, 44)
2026-04-15 20:16:14,507 - jwst.ami.leastsqnrm - INFO - flatmodel (4724, 44)
2026-04-15 20:16:14,507 - jwst.ami.leastsqnrm - INFO - difference 37
2026-04-15 20:16:14,507 - jwst.ami.leastsqnrm - INFO - flat model dimensions (4724, 44)
2026-04-15 20:16:14,508 - jwst.ami.leastsqnrm - INFO - flat image dimensions (4724,)
2026-04-15 20:16:14,510 - jwst.ami.leastsqnrm - INFO - data flux 1.04200406e+06
2026-04-15 20:16:14,511 - jwst.ami.leastsqnrm - INFO - flat model dimensions (4724, 44)
2026-04-15 20:16:14,511 - jwst.ami.leastsqnrm - INFO - model transpose dimensions (44, 4724)
2026-04-15 20:16:14,512 - jwst.ami.leastsqnrm - INFO - flat image dimensions (4724,)
2026-04-15 20:16:14,512 - jwst.ami.leastsqnrm - INFO - transpose * image data dimensions (44,)
2026-04-15 20:16:14,513 - jwst.ami.leastsqnrm - INFO - flat img * transpose dimensions (44, 44)
2026-04-15 20:16:14,513 - jwst.ami.leastsqnrm - INFO - linearfit not attempted, no covariances saved.
2026-04-15 20:16:14,515 - jwst.ami.nrm_core - INFO - Fitting fringes for iteration 3 of 61
2026-04-15 20:16:15,574 - jwst.ami.leastsqnrm - INFO - fringefitting.leastsqnrm.matrix_operations():
2026-04-15 20:16:15,574 - jwst.ami.leastsqnrm - INFO - img (69, 69)
2026-04-15 20:16:15,575 - jwst.ami.leastsqnrm - INFO - L x W = 69 x 69 = 4761
2026-04-15 20:16:15,575 - jwst.ami.leastsqnrm - INFO - flatimg (4761,)
2026-04-15 20:16:15,576 - jwst.ami.leastsqnrm - INFO -
2026-04-15 20:16:15,576 - jwst.ami.leastsqnrm - INFO - type(dqm) <class 'numpy.ndarray'>
2026-04-15 20:16:15,576 - jwst.ami.leastsqnrm - INFO - type(nanlist) <class 'tuple'>, len=1
2026-04-15 20:16:15,577 - jwst.ami.leastsqnrm - INFO - number of nanlist pixels: 39 items
2026-04-15 20:16:15,577 - jwst.ami.leastsqnrm - INFO - 39 DO_NOT_USE pixels found in data slice
2026-04-15 20:16:15,578 - jwst.ami.leastsqnrm - INFO - flatimg (4722,) after deleting 39
2026-04-15 20:16:15,578 - jwst.ami.leastsqnrm - INFO - flatmodel_nan (4761, 44)
2026-04-15 20:16:15,579 - jwst.ami.leastsqnrm - INFO - flatmodel (4722, 44)
2026-04-15 20:16:15,579 - jwst.ami.leastsqnrm - INFO - difference 39
2026-04-15 20:16:15,580 - jwst.ami.leastsqnrm - INFO - flat model dimensions (4722, 44)
2026-04-15 20:16:15,580 - jwst.ami.leastsqnrm - INFO - flat image dimensions (4722,)
2026-04-15 20:16:15,583 - jwst.ami.leastsqnrm - INFO - data flux 1.03344494e+06
2026-04-15 20:16:15,583 - jwst.ami.leastsqnrm - INFO - flat model dimensions (4722, 44)
2026-04-15 20:16:15,584 - jwst.ami.leastsqnrm - INFO - model transpose dimensions (44, 4722)
2026-04-15 20:16:15,584 - jwst.ami.leastsqnrm - INFO - flat image dimensions (4722,)
2026-04-15 20:16:15,585 - jwst.ami.leastsqnrm - INFO - transpose * image data dimensions (44,)
2026-04-15 20:16:15,585 - jwst.ami.leastsqnrm - INFO - flat img * transpose dimensions (44, 44)
2026-04-15 20:16:15,585 - jwst.ami.leastsqnrm - INFO - linearfit not attempted, no covariances saved.
2026-04-15 20:16:15,587 - jwst.ami.nrm_core - INFO - Fitting fringes for iteration 4 of 61
2026-04-15 20:16:16,639 - jwst.ami.leastsqnrm - INFO - fringefitting.leastsqnrm.matrix_operations():
2026-04-15 20:16:16,640 - jwst.ami.leastsqnrm - INFO - img (69, 69)
2026-04-15 20:16:16,641 - jwst.ami.leastsqnrm - INFO - L x W = 69 x 69 = 4761
2026-04-15 20:16:16,641 - jwst.ami.leastsqnrm - INFO - flatimg (4761,)
2026-04-15 20:16:16,641 - jwst.ami.leastsqnrm - INFO -
2026-04-15 20:16:16,642 - jwst.ami.leastsqnrm - INFO - type(dqm) <class 'numpy.ndarray'>
2026-04-15 20:16:16,642 - jwst.ami.leastsqnrm - INFO - type(nanlist) <class 'tuple'>, len=1
2026-04-15 20:16:16,643 - jwst.ami.leastsqnrm - INFO - number of nanlist pixels: 40 items
2026-04-15 20:16:16,643 - jwst.ami.leastsqnrm - INFO - 40 DO_NOT_USE pixels found in data slice
2026-04-15 20:16:16,644 - jwst.ami.leastsqnrm - INFO - flatimg (4721,) after deleting 40
2026-04-15 20:16:16,645 - jwst.ami.leastsqnrm - INFO - flatmodel_nan (4761, 44)
2026-04-15 20:16:16,645 - jwst.ami.leastsqnrm - INFO - flatmodel (4721, 44)
2026-04-15 20:16:16,645 - jwst.ami.leastsqnrm - INFO - difference 40
2026-04-15 20:16:16,646 - jwst.ami.leastsqnrm - INFO - flat model dimensions (4721, 44)
2026-04-15 20:16:16,646 - jwst.ami.leastsqnrm - INFO - flat image dimensions (4721,)
2026-04-15 20:16:16,649 - jwst.ami.leastsqnrm - INFO - data flux 1.04107744e+06
2026-04-15 20:16:16,649 - jwst.ami.leastsqnrm - INFO - flat model dimensions (4721, 44)
2026-04-15 20:16:16,650 - jwst.ami.leastsqnrm - INFO - model transpose dimensions (44, 4721)
2026-04-15 20:16:16,650 - jwst.ami.leastsqnrm - INFO - flat image dimensions (4721,)
2026-04-15 20:16:16,650 - jwst.ami.leastsqnrm - INFO - transpose * image data dimensions (44,)
2026-04-15 20:16:16,651 - jwst.ami.leastsqnrm - INFO - flat img * transpose dimensions (44, 44)
2026-04-15 20:16:16,652 - jwst.ami.leastsqnrm - INFO - linearfit not attempted, no covariances saved.
2026-04-15 20:16:16,653 - jwst.ami.nrm_core - INFO - Fitting fringes for iteration 5 of 61
2026-04-15 20:16:17,709 - jwst.ami.leastsqnrm - INFO - fringefitting.leastsqnrm.matrix_operations():
2026-04-15 20:16:17,710 - jwst.ami.leastsqnrm - INFO - img (69, 69)
2026-04-15 20:16:17,710 - jwst.ami.leastsqnrm - INFO - L x W = 69 x 69 = 4761
2026-04-15 20:16:17,711 - jwst.ami.leastsqnrm - INFO - flatimg (4761,)
2026-04-15 20:16:17,712 - jwst.ami.leastsqnrm - INFO -
2026-04-15 20:16:17,712 - jwst.ami.leastsqnrm - INFO - type(dqm) <class 'numpy.ndarray'>
2026-04-15 20:16:17,712 - jwst.ami.leastsqnrm - INFO - type(nanlist) <class 'tuple'>, len=1
2026-04-15 20:16:17,713 - jwst.ami.leastsqnrm - INFO - number of nanlist pixels: 39 items
2026-04-15 20:16:17,713 - jwst.ami.leastsqnrm - INFO - 39 DO_NOT_USE pixels found in data slice
2026-04-15 20:16:17,714 - jwst.ami.leastsqnrm - INFO - flatimg (4722,) after deleting 39
2026-04-15 20:16:17,714 - jwst.ami.leastsqnrm - INFO - flatmodel_nan (4761, 44)
2026-04-15 20:16:17,715 - jwst.ami.leastsqnrm - INFO - flatmodel (4722, 44)
2026-04-15 20:16:17,715 - jwst.ami.leastsqnrm - INFO - difference 39
2026-04-15 20:16:17,716 - jwst.ami.leastsqnrm - INFO - flat model dimensions (4722, 44)
2026-04-15 20:16:17,716 - jwst.ami.leastsqnrm - INFO - flat image dimensions (4722,)
2026-04-15 20:16:17,719 - jwst.ami.leastsqnrm - INFO - data flux 1.0342415e+06
2026-04-15 20:16:17,719 - jwst.ami.leastsqnrm - INFO - flat model dimensions (4722, 44)
2026-04-15 20:16:17,720 - jwst.ami.leastsqnrm - INFO - model transpose dimensions (44, 4722)
2026-04-15 20:16:17,720 - jwst.ami.leastsqnrm - INFO - flat image dimensions (4722,)
2026-04-15 20:16:17,721 - jwst.ami.leastsqnrm - INFO - transpose * image data dimensions (44,)
2026-04-15 20:16:17,721 - jwst.ami.leastsqnrm - INFO - flat img * transpose dimensions (44, 44)
2026-04-15 20:16:17,721 - jwst.ami.leastsqnrm - INFO - linearfit not attempted, no covariances saved.
2026-04-15 20:16:17,723 - jwst.ami.nrm_core - INFO - Fitting fringes for iteration 6 of 61
2026-04-15 20:16:18,776 - jwst.ami.leastsqnrm - INFO - fringefitting.leastsqnrm.matrix_operations():
2026-04-15 20:16:18,777 - jwst.ami.leastsqnrm - INFO - img (69, 69)
2026-04-15 20:16:18,777 - jwst.ami.leastsqnrm - INFO - L x W = 69 x 69 = 4761
2026-04-15 20:16:18,777 - jwst.ami.leastsqnrm - INFO - flatimg (4761,)
2026-04-15 20:16:18,778 - jwst.ami.leastsqnrm - INFO -
2026-04-15 20:16:18,778 - jwst.ami.leastsqnrm - INFO - type(dqm) <class 'numpy.ndarray'>
2026-04-15 20:16:18,779 - jwst.ami.leastsqnrm - INFO - type(nanlist) <class 'tuple'>, len=1
2026-04-15 20:16:18,779 - jwst.ami.leastsqnrm - INFO - number of nanlist pixels: 36 items
2026-04-15 20:16:18,779 - jwst.ami.leastsqnrm - INFO - 36 DO_NOT_USE pixels found in data slice
2026-04-15 20:16:18,780 - jwst.ami.leastsqnrm - INFO - flatimg (4725,) after deleting 36
2026-04-15 20:16:18,781 - jwst.ami.leastsqnrm - INFO - flatmodel_nan (4761, 44)
2026-04-15 20:16:18,781 - jwst.ami.leastsqnrm - INFO - flatmodel (4725, 44)
2026-04-15 20:16:18,782 - jwst.ami.leastsqnrm - INFO - difference 36
2026-04-15 20:16:18,782 - jwst.ami.leastsqnrm - INFO - flat model dimensions (4725, 44)
2026-04-15 20:16:18,782 - jwst.ami.leastsqnrm - INFO - flat image dimensions (4725,)
2026-04-15 20:16:18,785 - jwst.ami.leastsqnrm - INFO - data flux 1.03511094e+06
2026-04-15 20:16:18,785 - jwst.ami.leastsqnrm - INFO - flat model dimensions (4725, 44)
2026-04-15 20:16:18,786 - jwst.ami.leastsqnrm - INFO - model transpose dimensions (44, 4725)
2026-04-15 20:16:18,786 - jwst.ami.leastsqnrm - INFO - flat image dimensions (4725,)
2026-04-15 20:16:18,787 - jwst.ami.leastsqnrm - INFO - transpose * image data dimensions (44,)
2026-04-15 20:16:18,787 - jwst.ami.leastsqnrm - INFO - flat img * transpose dimensions (44, 44)
2026-04-15 20:16:18,787 - jwst.ami.leastsqnrm - INFO - linearfit not attempted, no covariances saved.
2026-04-15 20:16:18,789 - jwst.ami.nrm_core - INFO - Fitting fringes for iteration 7 of 61
2026-04-15 20:16:19,842 - jwst.ami.leastsqnrm - INFO - fringefitting.leastsqnrm.matrix_operations():
2026-04-15 20:16:19,843 - jwst.ami.leastsqnrm - INFO - img (69, 69)
2026-04-15 20:16:19,843 - jwst.ami.leastsqnrm - INFO - L x W = 69 x 69 = 4761
2026-04-15 20:16:19,844 - jwst.ami.leastsqnrm - INFO - flatimg (4761,)
2026-04-15 20:16:19,844 - jwst.ami.leastsqnrm - INFO -
2026-04-15 20:16:19,844 - jwst.ami.leastsqnrm - INFO - type(dqm) <class 'numpy.ndarray'>
2026-04-15 20:16:19,845 - jwst.ami.leastsqnrm - INFO - type(nanlist) <class 'tuple'>, len=1
2026-04-15 20:16:19,845 - jwst.ami.leastsqnrm - INFO - number of nanlist pixels: 37 items
2026-04-15 20:16:19,846 - jwst.ami.leastsqnrm - INFO - 37 DO_NOT_USE pixels found in data slice
2026-04-15 20:16:19,846 - jwst.ami.leastsqnrm - INFO - flatimg (4724,) after deleting 37
2026-04-15 20:16:19,848 - jwst.ami.leastsqnrm - INFO - flatmodel_nan (4761, 44)
2026-04-15 20:16:19,848 - jwst.ami.leastsqnrm - INFO - flatmodel (4724, 44)
2026-04-15 20:16:19,848 - jwst.ami.leastsqnrm - INFO - difference 37
2026-04-15 20:16:19,849 - jwst.ami.leastsqnrm - INFO - flat model dimensions (4724, 44)
2026-04-15 20:16:19,849 - jwst.ami.leastsqnrm - INFO - flat image dimensions (4724,)
2026-04-15 20:16:19,851 - jwst.ami.leastsqnrm - INFO - data flux 1.0351639e+06
2026-04-15 20:16:19,852 - jwst.ami.leastsqnrm - INFO - flat model dimensions (4724, 44)
2026-04-15 20:16:19,852 - jwst.ami.leastsqnrm - INFO - model transpose dimensions (44, 4724)
2026-04-15 20:16:19,853 - jwst.ami.leastsqnrm - INFO - flat image dimensions (4724,)
2026-04-15 20:16:19,853 - jwst.ami.leastsqnrm - INFO - transpose * image data dimensions (44,)
2026-04-15 20:16:19,854 - jwst.ami.leastsqnrm - INFO - flat img * transpose dimensions (44, 44)
2026-04-15 20:16:19,854 - jwst.ami.leastsqnrm - INFO - linearfit not attempted, no covariances saved.
2026-04-15 20:16:19,856 - jwst.ami.nrm_core - INFO - Fitting fringes for iteration 8 of 61
2026-04-15 20:16:20,906 - jwst.ami.leastsqnrm - INFO - fringefitting.leastsqnrm.matrix_operations():
2026-04-15 20:16:20,906 - jwst.ami.leastsqnrm - INFO - img (69, 69)
2026-04-15 20:16:20,907 - jwst.ami.leastsqnrm - INFO - L x W = 69 x 69 = 4761
2026-04-15 20:16:20,907 - jwst.ami.leastsqnrm - INFO - flatimg (4761,)
2026-04-15 20:16:20,908 - jwst.ami.leastsqnrm - INFO -
2026-04-15 20:16:20,908 - jwst.ami.leastsqnrm - INFO - type(dqm) <class 'numpy.ndarray'>
2026-04-15 20:16:20,909 - jwst.ami.leastsqnrm - INFO - type(nanlist) <class 'tuple'>, len=1
2026-04-15 20:16:20,909 - jwst.ami.leastsqnrm - INFO - number of nanlist pixels: 42 items
2026-04-15 20:16:20,910 - jwst.ami.leastsqnrm - INFO - 42 DO_NOT_USE pixels found in data slice
2026-04-15 20:16:20,910 - jwst.ami.leastsqnrm - INFO - flatimg (4719,) after deleting 42
2026-04-15 20:16:20,911 - jwst.ami.leastsqnrm - INFO - flatmodel_nan (4761, 44)
2026-04-15 20:16:20,911 - jwst.ami.leastsqnrm - INFO - flatmodel (4719, 44)
2026-04-15 20:16:20,912 - jwst.ami.leastsqnrm - INFO - difference 42
2026-04-15 20:16:20,912 - jwst.ami.leastsqnrm - INFO - flat model dimensions (4719, 44)
2026-04-15 20:16:20,913 - jwst.ami.leastsqnrm - INFO - flat image dimensions (4719,)
2026-04-15 20:16:20,915 - jwst.ami.leastsqnrm - INFO - data flux 1.0338327e+06
2026-04-15 20:16:20,915 - jwst.ami.leastsqnrm - INFO - flat model dimensions (4719, 44)
2026-04-15 20:16:20,916 - jwst.ami.leastsqnrm - INFO - model transpose dimensions (44, 4719)
2026-04-15 20:16:20,916 - jwst.ami.leastsqnrm - INFO - flat image dimensions (4719,)
2026-04-15 20:16:20,916 - jwst.ami.leastsqnrm - INFO - transpose * image data dimensions (44,)
2026-04-15 20:16:20,917 - jwst.ami.leastsqnrm - INFO - flat img * transpose dimensions (44, 44)
2026-04-15 20:16:20,917 - jwst.ami.leastsqnrm - INFO - linearfit not attempted, no covariances saved.
2026-04-15 20:16:20,919 - jwst.ami.nrm_core - INFO - Fitting fringes for iteration 9 of 61
2026-04-15 20:16:21,972 - jwst.ami.leastsqnrm - INFO - fringefitting.leastsqnrm.matrix_operations():
2026-04-15 20:16:21,973 - jwst.ami.leastsqnrm - INFO - img (69, 69)
2026-04-15 20:16:21,974 - jwst.ami.leastsqnrm - INFO - L x W = 69 x 69 = 4761
2026-04-15 20:16:21,974 - jwst.ami.leastsqnrm - INFO - flatimg (4761,)
2026-04-15 20:16:21,974 - jwst.ami.leastsqnrm - INFO -
2026-04-15 20:16:21,975 - jwst.ami.leastsqnrm - INFO - type(dqm) <class 'numpy.ndarray'>
2026-04-15 20:16:21,975 - jwst.ami.leastsqnrm - INFO - type(nanlist) <class 'tuple'>, len=1
2026-04-15 20:16:21,976 - jwst.ami.leastsqnrm - INFO - number of nanlist pixels: 39 items
2026-04-15 20:16:21,976 - jwst.ami.leastsqnrm - INFO - 39 DO_NOT_USE pixels found in data slice
2026-04-15 20:16:21,977 - jwst.ami.leastsqnrm - INFO - flatimg (4722,) after deleting 39
2026-04-15 20:16:21,977 - jwst.ami.leastsqnrm - INFO - flatmodel_nan (4761, 44)
2026-04-15 20:16:21,978 - jwst.ami.leastsqnrm - INFO - flatmodel (4722, 44)
2026-04-15 20:16:21,978 - jwst.ami.leastsqnrm - INFO - difference 39
2026-04-15 20:16:21,979 - jwst.ami.leastsqnrm - INFO - flat model dimensions (4722, 44)
2026-04-15 20:16:21,979 - jwst.ami.leastsqnrm - INFO - flat image dimensions (4722,)
2026-04-15 20:16:21,982 - jwst.ami.leastsqnrm - INFO - data flux 1.03530725e+06
2026-04-15 20:16:21,982 - jwst.ami.leastsqnrm - INFO - flat model dimensions (4722, 44)
2026-04-15 20:16:21,982 - jwst.ami.leastsqnrm - INFO - model transpose dimensions (44, 4722)
2026-04-15 20:16:21,983 - jwst.ami.leastsqnrm - INFO - flat image dimensions (4722,)
2026-04-15 20:16:21,983 - jwst.ami.leastsqnrm - INFO - transpose * image data dimensions (44,)
2026-04-15 20:16:21,984 - jwst.ami.leastsqnrm - INFO - flat img * transpose dimensions (44, 44)
2026-04-15 20:16:21,985 - jwst.ami.leastsqnrm - INFO - linearfit not attempted, no covariances saved.
2026-04-15 20:16:21,986 - jwst.ami.nrm_core - INFO - Fitting fringes for iteration 10 of 61
2026-04-15 20:16:23,049 - jwst.ami.leastsqnrm - INFO - fringefitting.leastsqnrm.matrix_operations():
2026-04-15 20:16:23,049 - jwst.ami.leastsqnrm - INFO - img (69, 69)
2026-04-15 20:16:23,050 - jwst.ami.leastsqnrm - INFO - L x W = 69 x 69 = 4761
2026-04-15 20:16:23,050 - jwst.ami.leastsqnrm - INFO - flatimg (4761,)
2026-04-15 20:16:23,051 - jwst.ami.leastsqnrm - INFO -
2026-04-15 20:16:23,052 - jwst.ami.leastsqnrm - INFO - type(dqm) <class 'numpy.ndarray'>
2026-04-15 20:16:23,052 - jwst.ami.leastsqnrm - INFO - type(nanlist) <class 'tuple'>, len=1
2026-04-15 20:16:23,052 - jwst.ami.leastsqnrm - INFO - number of nanlist pixels: 39 items
2026-04-15 20:16:23,053 - jwst.ami.leastsqnrm - INFO - 39 DO_NOT_USE pixels found in data slice
2026-04-15 20:16:23,053 - jwst.ami.leastsqnrm - INFO - flatimg (4722,) after deleting 39
2026-04-15 20:16:23,054 - jwst.ami.leastsqnrm - INFO - flatmodel_nan (4761, 44)
2026-04-15 20:16:23,054 - jwst.ami.leastsqnrm - INFO - flatmodel (4722, 44)
2026-04-15 20:16:23,055 - jwst.ami.leastsqnrm - INFO - difference 39
2026-04-15 20:16:23,055 - jwst.ami.leastsqnrm - INFO - flat model dimensions (4722, 44)
2026-04-15 20:16:23,056 - jwst.ami.leastsqnrm - INFO - flat image dimensions (4722,)
2026-04-15 20:16:23,058 - jwst.ami.leastsqnrm - INFO - data flux 1.0295228e+06
2026-04-15 20:16:23,059 - jwst.ami.leastsqnrm - INFO - flat model dimensions (4722, 44)
2026-04-15 20:16:23,059 - jwst.ami.leastsqnrm - INFO - model transpose dimensions (44, 4722)
2026-04-15 20:16:23,060 - jwst.ami.leastsqnrm - INFO - flat image dimensions (4722,)
2026-04-15 20:16:23,060 - jwst.ami.leastsqnrm - INFO - transpose * image data dimensions (44,)
2026-04-15 20:16:23,060 - jwst.ami.leastsqnrm - INFO - flat img * transpose dimensions (44, 44)
2026-04-15 20:16:23,061 - jwst.ami.leastsqnrm - INFO - linearfit not attempted, no covariances saved.
2026-04-15 20:16:23,062 - jwst.ami.nrm_core - INFO - Fitting fringes for iteration 11 of 61
2026-04-15 20:16:24,118 - jwst.ami.leastsqnrm - INFO - fringefitting.leastsqnrm.matrix_operations():
2026-04-15 20:16:24,119 - jwst.ami.leastsqnrm - INFO - img (69, 69)
2026-04-15 20:16:24,120 - jwst.ami.leastsqnrm - INFO - L x W = 69 x 69 = 4761
2026-04-15 20:16:24,120 - jwst.ami.leastsqnrm - INFO - flatimg (4761,)
2026-04-15 20:16:24,120 - jwst.ami.leastsqnrm - INFO -
2026-04-15 20:16:24,121 - jwst.ami.leastsqnrm - INFO - type(dqm) <class 'numpy.ndarray'>
2026-04-15 20:16:24,121 - jwst.ami.leastsqnrm - INFO - type(nanlist) <class 'tuple'>, len=1
2026-04-15 20:16:24,122 - jwst.ami.leastsqnrm - INFO - number of nanlist pixels: 45 items
2026-04-15 20:16:24,122 - jwst.ami.leastsqnrm - INFO - 45 DO_NOT_USE pixels found in data slice
2026-04-15 20:16:24,123 - jwst.ami.leastsqnrm - INFO - flatimg (4716,) after deleting 45
2026-04-15 20:16:24,123 - jwst.ami.leastsqnrm - INFO - flatmodel_nan (4761, 44)
2026-04-15 20:16:24,124 - jwst.ami.leastsqnrm - INFO - flatmodel (4716, 44)
2026-04-15 20:16:24,124 - jwst.ami.leastsqnrm - INFO - difference 45
2026-04-15 20:16:24,125 - jwst.ami.leastsqnrm - INFO - flat model dimensions (4716, 44)
2026-04-15 20:16:24,125 - jwst.ami.leastsqnrm - INFO - flat image dimensions (4716,)
2026-04-15 20:16:24,128 - jwst.ami.leastsqnrm - INFO - data flux 1.0313929e+06
2026-04-15 20:16:24,128 - jwst.ami.leastsqnrm - INFO - flat model dimensions (4716, 44)
2026-04-15 20:16:24,129 - jwst.ami.leastsqnrm - INFO - model transpose dimensions (44, 4716)
2026-04-15 20:16:24,129 - jwst.ami.leastsqnrm - INFO - flat image dimensions (4716,)
2026-04-15 20:16:24,130 - jwst.ami.leastsqnrm - INFO - transpose * image data dimensions (44,)
2026-04-15 20:16:24,130 - jwst.ami.leastsqnrm - INFO - flat img * transpose dimensions (44, 44)
2026-04-15 20:16:24,130 - jwst.ami.leastsqnrm - INFO - linearfit not attempted, no covariances saved.
2026-04-15 20:16:24,132 - jwst.ami.nrm_core - INFO - Fitting fringes for iteration 12 of 61
2026-04-15 20:16:25,197 - jwst.ami.leastsqnrm - INFO - fringefitting.leastsqnrm.matrix_operations():
2026-04-15 20:16:25,198 - jwst.ami.leastsqnrm - INFO - img (69, 69)
2026-04-15 20:16:25,198 - jwst.ami.leastsqnrm - INFO - L x W = 69 x 69 = 4761
2026-04-15 20:16:25,199 - jwst.ami.leastsqnrm - INFO - flatimg (4761,)
2026-04-15 20:16:25,199 - jwst.ami.leastsqnrm - INFO -
2026-04-15 20:16:25,200 - jwst.ami.leastsqnrm - INFO - type(dqm) <class 'numpy.ndarray'>
2026-04-15 20:16:25,200 - jwst.ami.leastsqnrm - INFO - type(nanlist) <class 'tuple'>, len=1
2026-04-15 20:16:25,200 - jwst.ami.leastsqnrm - INFO - number of nanlist pixels: 43 items
2026-04-15 20:16:25,201 - jwst.ami.leastsqnrm - INFO - 43 DO_NOT_USE pixels found in data slice
2026-04-15 20:16:25,201 - jwst.ami.leastsqnrm - INFO - flatimg (4718,) after deleting 43
2026-04-15 20:16:25,202 - jwst.ami.leastsqnrm - INFO - flatmodel_nan (4761, 44)
2026-04-15 20:16:25,202 - jwst.ami.leastsqnrm - INFO - flatmodel (4718, 44)
2026-04-15 20:16:25,203 - jwst.ami.leastsqnrm - INFO - difference 43
2026-04-15 20:16:25,203 - jwst.ami.leastsqnrm - INFO - flat model dimensions (4718, 44)
2026-04-15 20:16:25,204 - jwst.ami.leastsqnrm - INFO - flat image dimensions (4718,)
2026-04-15 20:16:25,206 - jwst.ami.leastsqnrm - INFO - data flux 1.0323545e+06
2026-04-15 20:16:25,207 - jwst.ami.leastsqnrm - INFO - flat model dimensions (4718, 44)
2026-04-15 20:16:25,208 - jwst.ami.leastsqnrm - INFO - model transpose dimensions (44, 4718)
2026-04-15 20:16:25,208 - jwst.ami.leastsqnrm - INFO - flat image dimensions (4718,)
2026-04-15 20:16:25,208 - jwst.ami.leastsqnrm - INFO - transpose * image data dimensions (44,)
2026-04-15 20:16:25,209 - jwst.ami.leastsqnrm - INFO - flat img * transpose dimensions (44, 44)
2026-04-15 20:16:25,209 - jwst.ami.leastsqnrm - INFO - linearfit not attempted, no covariances saved.
2026-04-15 20:16:25,211 - jwst.ami.nrm_core - INFO - Fitting fringes for iteration 13 of 61
2026-04-15 20:16:26,269 - jwst.ami.leastsqnrm - INFO - fringefitting.leastsqnrm.matrix_operations():
2026-04-15 20:16:26,269 - jwst.ami.leastsqnrm - INFO - img (69, 69)
2026-04-15 20:16:26,270 - jwst.ami.leastsqnrm - INFO - L x W = 69 x 69 = 4761
2026-04-15 20:16:26,270 - jwst.ami.leastsqnrm - INFO - flatimg (4761,)
2026-04-15 20:16:26,271 - jwst.ami.leastsqnrm - INFO -
2026-04-15 20:16:26,271 - jwst.ami.leastsqnrm - INFO - type(dqm) <class 'numpy.ndarray'>
2026-04-15 20:16:26,271 - jwst.ami.leastsqnrm - INFO - type(nanlist) <class 'tuple'>, len=1
2026-04-15 20:16:26,272 - jwst.ami.leastsqnrm - INFO - number of nanlist pixels: 39 items
2026-04-15 20:16:26,272 - jwst.ami.leastsqnrm - INFO - 39 DO_NOT_USE pixels found in data slice
2026-04-15 20:16:26,273 - jwst.ami.leastsqnrm - INFO - flatimg (4722,) after deleting 39
2026-04-15 20:16:26,273 - jwst.ami.leastsqnrm - INFO - flatmodel_nan (4761, 44)
2026-04-15 20:16:26,274 - jwst.ami.leastsqnrm - INFO - flatmodel (4722, 44)
2026-04-15 20:16:26,274 - jwst.ami.leastsqnrm - INFO - difference 39
2026-04-15 20:16:26,275 - jwst.ami.leastsqnrm - INFO - flat model dimensions (4722, 44)
2026-04-15 20:16:26,275 - jwst.ami.leastsqnrm - INFO - flat image dimensions (4722,)
2026-04-15 20:16:26,278 - jwst.ami.leastsqnrm - INFO - data flux 1.02544175e+06
2026-04-15 20:16:26,278 - jwst.ami.leastsqnrm - INFO - flat model dimensions (4722, 44)
2026-04-15 20:16:26,279 - jwst.ami.leastsqnrm - INFO - model transpose dimensions (44, 4722)
2026-04-15 20:16:26,279 - jwst.ami.leastsqnrm - INFO - flat image dimensions (4722,)
2026-04-15 20:16:26,279 - jwst.ami.leastsqnrm - INFO - transpose * image data dimensions (44,)
2026-04-15 20:16:26,280 - jwst.ami.leastsqnrm - INFO - flat img * transpose dimensions (44, 44)
2026-04-15 20:16:26,280 - jwst.ami.leastsqnrm - INFO - linearfit not attempted, no covariances saved.
2026-04-15 20:16:26,282 - jwst.ami.nrm_core - INFO - Fitting fringes for iteration 14 of 61
2026-04-15 20:16:27,338 - jwst.ami.leastsqnrm - INFO - fringefitting.leastsqnrm.matrix_operations():
2026-04-15 20:16:27,339 - jwst.ami.leastsqnrm - INFO - img (69, 69)
2026-04-15 20:16:27,340 - jwst.ami.leastsqnrm - INFO - L x W = 69 x 69 = 4761
2026-04-15 20:16:27,340 - jwst.ami.leastsqnrm - INFO - flatimg (4761,)
2026-04-15 20:16:27,340 - jwst.ami.leastsqnrm - INFO -
2026-04-15 20:16:27,341 - jwst.ami.leastsqnrm - INFO - type(dqm) <class 'numpy.ndarray'>
2026-04-15 20:16:27,341 - jwst.ami.leastsqnrm - INFO - type(nanlist) <class 'tuple'>, len=1
2026-04-15 20:16:27,342 - jwst.ami.leastsqnrm - INFO - number of nanlist pixels: 39 items
2026-04-15 20:16:27,342 - jwst.ami.leastsqnrm - INFO - 39 DO_NOT_USE pixels found in data slice
2026-04-15 20:16:27,343 - jwst.ami.leastsqnrm - INFO - flatimg (4722,) after deleting 39
2026-04-15 20:16:27,343 - jwst.ami.leastsqnrm - INFO - flatmodel_nan (4761, 44)
2026-04-15 20:16:27,344 - jwst.ami.leastsqnrm - INFO - flatmodel (4722, 44)
2026-04-15 20:16:27,344 - jwst.ami.leastsqnrm - INFO - difference 39
2026-04-15 20:16:27,345 - jwst.ami.leastsqnrm - INFO - flat model dimensions (4722, 44)
2026-04-15 20:16:27,345 - jwst.ami.leastsqnrm - INFO - flat image dimensions (4722,)
2026-04-15 20:16:27,348 - jwst.ami.leastsqnrm - INFO - data flux 1.02627925e+06
2026-04-15 20:16:27,348 - jwst.ami.leastsqnrm - INFO - flat model dimensions (4722, 44)
2026-04-15 20:16:27,349 - jwst.ami.leastsqnrm - INFO - model transpose dimensions (44, 4722)
2026-04-15 20:16:27,349 - jwst.ami.leastsqnrm - INFO - flat image dimensions (4722,)
2026-04-15 20:16:27,349 - jwst.ami.leastsqnrm - INFO - transpose * image data dimensions (44,)
2026-04-15 20:16:27,350 - jwst.ami.leastsqnrm - INFO - flat img * transpose dimensions (44, 44)
2026-04-15 20:16:27,350 - jwst.ami.leastsqnrm - INFO - linearfit not attempted, no covariances saved.
2026-04-15 20:16:27,352 - jwst.ami.nrm_core - INFO - Fitting fringes for iteration 15 of 61
2026-04-15 20:16:28,414 - jwst.ami.leastsqnrm - INFO - fringefitting.leastsqnrm.matrix_operations():
2026-04-15 20:16:28,415 - jwst.ami.leastsqnrm - INFO - img (69, 69)
2026-04-15 20:16:28,415 - jwst.ami.leastsqnrm - INFO - L x W = 69 x 69 = 4761
2026-04-15 20:16:28,415 - jwst.ami.leastsqnrm - INFO - flatimg (4761,)
2026-04-15 20:16:28,416 - jwst.ami.leastsqnrm - INFO -
2026-04-15 20:16:28,416 - jwst.ami.leastsqnrm - INFO - type(dqm) <class 'numpy.ndarray'>
2026-04-15 20:16:28,417 - jwst.ami.leastsqnrm - INFO - type(nanlist) <class 'tuple'>, len=1
2026-04-15 20:16:28,417 - jwst.ami.leastsqnrm - INFO - number of nanlist pixels: 37 items
2026-04-15 20:16:28,418 - jwst.ami.leastsqnrm - INFO - 37 DO_NOT_USE pixels found in data slice
2026-04-15 20:16:28,418 - jwst.ami.leastsqnrm - INFO - flatimg (4724,) after deleting 37
2026-04-15 20:16:28,419 - jwst.ami.leastsqnrm - INFO - flatmodel_nan (4761, 44)
2026-04-15 20:16:28,419 - jwst.ami.leastsqnrm - INFO - flatmodel (4724, 44)
2026-04-15 20:16:28,420 - jwst.ami.leastsqnrm - INFO - difference 37
2026-04-15 20:16:28,420 - jwst.ami.leastsqnrm - INFO - flat model dimensions (4724, 44)
2026-04-15 20:16:28,420 - jwst.ami.leastsqnrm - INFO - flat image dimensions (4724,)
2026-04-15 20:16:28,423 - jwst.ami.leastsqnrm - INFO - data flux 1.03422075e+06
2026-04-15 20:16:28,424 - jwst.ami.leastsqnrm - INFO - flat model dimensions (4724, 44)
2026-04-15 20:16:28,424 - jwst.ami.leastsqnrm - INFO - model transpose dimensions (44, 4724)
2026-04-15 20:16:28,424 - jwst.ami.leastsqnrm - INFO - flat image dimensions (4724,)
2026-04-15 20:16:28,425 - jwst.ami.leastsqnrm - INFO - transpose * image data dimensions (44,)
2026-04-15 20:16:28,425 - jwst.ami.leastsqnrm - INFO - flat img * transpose dimensions (44, 44)
2026-04-15 20:16:28,426 - jwst.ami.leastsqnrm - INFO - linearfit not attempted, no covariances saved.
2026-04-15 20:16:28,427 - jwst.ami.nrm_core - INFO - Fitting fringes for iteration 16 of 61
2026-04-15 20:16:29,483 - jwst.ami.leastsqnrm - INFO - fringefitting.leastsqnrm.matrix_operations():
2026-04-15 20:16:29,483 - jwst.ami.leastsqnrm - INFO - img (69, 69)
2026-04-15 20:16:29,484 - jwst.ami.leastsqnrm - INFO - L x W = 69 x 69 = 4761
2026-04-15 20:16:29,484 - jwst.ami.leastsqnrm - INFO - flatimg (4761,)
2026-04-15 20:16:29,485 - jwst.ami.leastsqnrm - INFO -
2026-04-15 20:16:29,485 - jwst.ami.leastsqnrm - INFO - type(dqm) <class 'numpy.ndarray'>
2026-04-15 20:16:29,485 - jwst.ami.leastsqnrm - INFO - type(nanlist) <class 'tuple'>, len=1
2026-04-15 20:16:29,486 - jwst.ami.leastsqnrm - INFO - number of nanlist pixels: 40 items
2026-04-15 20:16:29,486 - jwst.ami.leastsqnrm - INFO - 40 DO_NOT_USE pixels found in data slice
2026-04-15 20:16:29,487 - jwst.ami.leastsqnrm - INFO - flatimg (4721,) after deleting 40
2026-04-15 20:16:29,488 - jwst.ami.leastsqnrm - INFO - flatmodel_nan (4761, 44)
2026-04-15 20:16:29,488 - jwst.ami.leastsqnrm - INFO - flatmodel (4721, 44)
2026-04-15 20:16:29,488 - jwst.ami.leastsqnrm - INFO - difference 40
2026-04-15 20:16:29,489 - jwst.ami.leastsqnrm - INFO - flat model dimensions (4721, 44)
2026-04-15 20:16:29,489 - jwst.ami.leastsqnrm - INFO - flat image dimensions (4721,)
2026-04-15 20:16:29,492 - jwst.ami.leastsqnrm - INFO - data flux 1.03020225e+06
2026-04-15 20:16:29,492 - jwst.ami.leastsqnrm - INFO - flat model dimensions (4721, 44)
2026-04-15 20:16:29,492 - jwst.ami.leastsqnrm - INFO - model transpose dimensions (44, 4721)
2026-04-15 20:16:29,493 - jwst.ami.leastsqnrm - INFO - flat image dimensions (4721,)
2026-04-15 20:16:29,493 - jwst.ami.leastsqnrm - INFO - transpose * image data dimensions (44,)
2026-04-15 20:16:29,494 - jwst.ami.leastsqnrm - INFO - flat img * transpose dimensions (44, 44)
2026-04-15 20:16:29,494 - jwst.ami.leastsqnrm - INFO - linearfit not attempted, no covariances saved.
2026-04-15 20:16:29,496 - jwst.ami.nrm_core - INFO - Fitting fringes for iteration 17 of 61
2026-04-15 20:16:30,550 - jwst.ami.leastsqnrm - INFO - fringefitting.leastsqnrm.matrix_operations():
2026-04-15 20:16:30,550 - jwst.ami.leastsqnrm - INFO - img (69, 69)
2026-04-15 20:16:30,551 - jwst.ami.leastsqnrm - INFO - L x W = 69 x 69 = 4761
2026-04-15 20:16:30,551 - jwst.ami.leastsqnrm - INFO - flatimg (4761,)
2026-04-15 20:16:30,552 - jwst.ami.leastsqnrm - INFO -
2026-04-15 20:16:30,552 - jwst.ami.leastsqnrm - INFO - type(dqm) <class 'numpy.ndarray'>
2026-04-15 20:16:30,553 - jwst.ami.leastsqnrm - INFO - type(nanlist) <class 'tuple'>, len=1
2026-04-15 20:16:30,553 - jwst.ami.leastsqnrm - INFO - number of nanlist pixels: 38 items
2026-04-15 20:16:30,553 - jwst.ami.leastsqnrm - INFO - 38 DO_NOT_USE pixels found in data slice
2026-04-15 20:16:30,554 - jwst.ami.leastsqnrm - INFO - flatimg (4723,) after deleting 38
2026-04-15 20:16:30,555 - jwst.ami.leastsqnrm - INFO - flatmodel_nan (4761, 44)
2026-04-15 20:16:30,555 - jwst.ami.leastsqnrm - INFO - flatmodel (4723, 44)
2026-04-15 20:16:30,555 - jwst.ami.leastsqnrm - INFO - difference 38
2026-04-15 20:16:30,556 - jwst.ami.leastsqnrm - INFO - flat model dimensions (4723, 44)
2026-04-15 20:16:30,556 - jwst.ami.leastsqnrm - INFO - flat image dimensions (4723,)
2026-04-15 20:16:30,559 - jwst.ami.leastsqnrm - INFO - data flux 1.0407069e+06
2026-04-15 20:16:30,559 - jwst.ami.leastsqnrm - INFO - flat model dimensions (4723, 44)
2026-04-15 20:16:30,560 - jwst.ami.leastsqnrm - INFO - model transpose dimensions (44, 4723)
2026-04-15 20:16:30,560 - jwst.ami.leastsqnrm - INFO - flat image dimensions (4723,)
2026-04-15 20:16:30,561 - jwst.ami.leastsqnrm - INFO - transpose * image data dimensions (44,)
2026-04-15 20:16:30,561 - jwst.ami.leastsqnrm - INFO - flat img * transpose dimensions (44, 44)
2026-04-15 20:16:30,562 - jwst.ami.leastsqnrm - INFO - linearfit not attempted, no covariances saved.
2026-04-15 20:16:30,563 - jwst.ami.nrm_core - INFO - Fitting fringes for iteration 18 of 61
2026-04-15 20:16:31,619 - jwst.ami.leastsqnrm - INFO - fringefitting.leastsqnrm.matrix_operations():
2026-04-15 20:16:31,620 - jwst.ami.leastsqnrm - INFO - img (69, 69)
2026-04-15 20:16:31,621 - jwst.ami.leastsqnrm - INFO - L x W = 69 x 69 = 4761
2026-04-15 20:16:31,621 - jwst.ami.leastsqnrm - INFO - flatimg (4761,)
2026-04-15 20:16:31,622 - jwst.ami.leastsqnrm - INFO -
2026-04-15 20:16:31,622 - jwst.ami.leastsqnrm - INFO - type(dqm) <class 'numpy.ndarray'>
2026-04-15 20:16:31,622 - jwst.ami.leastsqnrm - INFO - type(nanlist) <class 'tuple'>, len=1
2026-04-15 20:16:31,623 - jwst.ami.leastsqnrm - INFO - number of nanlist pixels: 36 items
2026-04-15 20:16:31,623 - jwst.ami.leastsqnrm - INFO - 36 DO_NOT_USE pixels found in data slice
2026-04-15 20:16:31,624 - jwst.ami.leastsqnrm - INFO - flatimg (4725,) after deleting 36
2026-04-15 20:16:31,624 - jwst.ami.leastsqnrm - INFO - flatmodel_nan (4761, 44)
2026-04-15 20:16:31,625 - jwst.ami.leastsqnrm - INFO - flatmodel (4725, 44)
2026-04-15 20:16:31,625 - jwst.ami.leastsqnrm - INFO - difference 36
2026-04-15 20:16:31,626 - jwst.ami.leastsqnrm - INFO - flat model dimensions (4725, 44)
2026-04-15 20:16:31,626 - jwst.ami.leastsqnrm - INFO - flat image dimensions (4725,)
2026-04-15 20:16:31,629 - jwst.ami.leastsqnrm - INFO - data flux 1.0374495e+06
2026-04-15 20:16:31,629 - jwst.ami.leastsqnrm - INFO - flat model dimensions (4725, 44)
2026-04-15 20:16:31,629 - jwst.ami.leastsqnrm - INFO - model transpose dimensions (44, 4725)
2026-04-15 20:16:31,630 - jwst.ami.leastsqnrm - INFO - flat image dimensions (4725,)
2026-04-15 20:16:31,630 - jwst.ami.leastsqnrm - INFO - transpose * image data dimensions (44,)
2026-04-15 20:16:31,631 - jwst.ami.leastsqnrm - INFO - flat img * transpose dimensions (44, 44)
2026-04-15 20:16:31,631 - jwst.ami.leastsqnrm - INFO - linearfit not attempted, no covariances saved.
2026-04-15 20:16:31,633 - jwst.ami.nrm_core - INFO - Fitting fringes for iteration 19 of 61
2026-04-15 20:16:32,688 - jwst.ami.leastsqnrm - INFO - fringefitting.leastsqnrm.matrix_operations():
2026-04-15 20:16:32,689 - jwst.ami.leastsqnrm - INFO - img (69, 69)
2026-04-15 20:16:32,689 - jwst.ami.leastsqnrm - INFO - L x W = 69 x 69 = 4761
2026-04-15 20:16:32,690 - jwst.ami.leastsqnrm - INFO - flatimg (4761,)
2026-04-15 20:16:32,690 - jwst.ami.leastsqnrm - INFO -
2026-04-15 20:16:32,691 - jwst.ami.leastsqnrm - INFO - type(dqm) <class 'numpy.ndarray'>
2026-04-15 20:16:32,691 - jwst.ami.leastsqnrm - INFO - type(nanlist) <class 'tuple'>, len=1
2026-04-15 20:16:32,692 - jwst.ami.leastsqnrm - INFO - number of nanlist pixels: 40 items
2026-04-15 20:16:32,692 - jwst.ami.leastsqnrm - INFO - 40 DO_NOT_USE pixels found in data slice
2026-04-15 20:16:32,693 - jwst.ami.leastsqnrm - INFO - flatimg (4721,) after deleting 40
2026-04-15 20:16:32,693 - jwst.ami.leastsqnrm - INFO - flatmodel_nan (4761, 44)
2026-04-15 20:16:32,694 - jwst.ami.leastsqnrm - INFO - flatmodel (4721, 44)
2026-04-15 20:16:32,694 - jwst.ami.leastsqnrm - INFO - difference 40
2026-04-15 20:16:32,695 - jwst.ami.leastsqnrm - INFO - flat model dimensions (4721, 44)
2026-04-15 20:16:32,695 - jwst.ami.leastsqnrm - INFO - flat image dimensions (4721,)
2026-04-15 20:16:32,698 - jwst.ami.leastsqnrm - INFO - data flux 1.0295379e+06
2026-04-15 20:16:32,698 - jwst.ami.leastsqnrm - INFO - flat model dimensions (4721, 44)
2026-04-15 20:16:32,698 - jwst.ami.leastsqnrm - INFO - model transpose dimensions (44, 4721)
2026-04-15 20:16:32,699 - jwst.ami.leastsqnrm - INFO - flat image dimensions (4721,)
2026-04-15 20:16:32,699 - jwst.ami.leastsqnrm - INFO - transpose * image data dimensions (44,)
2026-04-15 20:16:32,700 - jwst.ami.leastsqnrm - INFO - flat img * transpose dimensions (44, 44)
2026-04-15 20:16:32,700 - jwst.ami.leastsqnrm - INFO - linearfit not attempted, no covariances saved.
2026-04-15 20:16:32,702 - jwst.ami.nrm_core - INFO - Fitting fringes for iteration 20 of 61
2026-04-15 20:16:33,765 - jwst.ami.leastsqnrm - INFO - fringefitting.leastsqnrm.matrix_operations():
2026-04-15 20:16:33,766 - jwst.ami.leastsqnrm - INFO - img (69, 69)
2026-04-15 20:16:33,766 - jwst.ami.leastsqnrm - INFO - L x W = 69 x 69 = 4761
2026-04-15 20:16:33,767 - jwst.ami.leastsqnrm - INFO - flatimg (4761,)
2026-04-15 20:16:33,767 - jwst.ami.leastsqnrm - INFO -
2026-04-15 20:16:33,767 - jwst.ami.leastsqnrm - INFO - type(dqm) <class 'numpy.ndarray'>
2026-04-15 20:16:33,768 - jwst.ami.leastsqnrm - INFO - type(nanlist) <class 'tuple'>, len=1
2026-04-15 20:16:33,768 - jwst.ami.leastsqnrm - INFO - number of nanlist pixels: 44 items
2026-04-15 20:16:33,769 - jwst.ami.leastsqnrm - INFO - 44 DO_NOT_USE pixels found in data slice
2026-04-15 20:16:33,769 - jwst.ami.leastsqnrm - INFO - flatimg (4717,) after deleting 44
2026-04-15 20:16:33,770 - jwst.ami.leastsqnrm - INFO - flatmodel_nan (4761, 44)
2026-04-15 20:16:33,771 - jwst.ami.leastsqnrm - INFO - flatmodel (4717, 44)
2026-04-15 20:16:33,771 - jwst.ami.leastsqnrm - INFO - difference 44
2026-04-15 20:16:33,771 - jwst.ami.leastsqnrm - INFO - flat model dimensions (4717, 44)
2026-04-15 20:16:33,772 - jwst.ami.leastsqnrm - INFO - flat image dimensions (4717,)
2026-04-15 20:16:33,774 - jwst.ami.leastsqnrm - INFO - data flux 1.0364409e+06
2026-04-15 20:16:33,775 - jwst.ami.leastsqnrm - INFO - flat model dimensions (4717, 44)
2026-04-15 20:16:33,775 - jwst.ami.leastsqnrm - INFO - model transpose dimensions (44, 4717)
2026-04-15 20:16:33,775 - jwst.ami.leastsqnrm - INFO - flat image dimensions (4717,)
2026-04-15 20:16:33,776 - jwst.ami.leastsqnrm - INFO - transpose * image data dimensions (44,)
2026-04-15 20:16:33,776 - jwst.ami.leastsqnrm - INFO - flat img * transpose dimensions (44, 44)
2026-04-15 20:16:33,777 - jwst.ami.leastsqnrm - INFO - linearfit not attempted, no covariances saved.
2026-04-15 20:16:33,779 - jwst.ami.nrm_core - INFO - Fitting fringes for iteration 21 of 61
2026-04-15 20:16:34,831 - jwst.ami.leastsqnrm - INFO - fringefitting.leastsqnrm.matrix_operations():
2026-04-15 20:16:34,832 - jwst.ami.leastsqnrm - INFO - img (69, 69)
2026-04-15 20:16:34,832 - jwst.ami.leastsqnrm - INFO - L x W = 69 x 69 = 4761
2026-04-15 20:16:34,832 - jwst.ami.leastsqnrm - INFO - flatimg (4761,)
2026-04-15 20:16:34,833 - jwst.ami.leastsqnrm - INFO -
2026-04-15 20:16:34,833 - jwst.ami.leastsqnrm - INFO - type(dqm) <class 'numpy.ndarray'>
2026-04-15 20:16:34,834 - jwst.ami.leastsqnrm - INFO - type(nanlist) <class 'tuple'>, len=1
2026-04-15 20:16:34,834 - jwst.ami.leastsqnrm - INFO - number of nanlist pixels: 37 items
2026-04-15 20:16:34,835 - jwst.ami.leastsqnrm - INFO - 37 DO_NOT_USE pixels found in data slice
2026-04-15 20:16:34,836 - jwst.ami.leastsqnrm - INFO - flatimg (4724,) after deleting 37
2026-04-15 20:16:34,836 - jwst.ami.leastsqnrm - INFO - flatmodel_nan (4761, 44)
2026-04-15 20:16:34,837 - jwst.ami.leastsqnrm - INFO - flatmodel (4724, 44)
2026-04-15 20:16:34,837 - jwst.ami.leastsqnrm - INFO - difference 37
2026-04-15 20:16:34,838 - jwst.ami.leastsqnrm - INFO - flat model dimensions (4724, 44)
2026-04-15 20:16:34,838 - jwst.ami.leastsqnrm - INFO - flat image dimensions (4724,)
2026-04-15 20:16:34,840 - jwst.ami.leastsqnrm - INFO - data flux 1.0331165e+06
2026-04-15 20:16:34,841 - jwst.ami.leastsqnrm - INFO - flat model dimensions (4724, 44)
2026-04-15 20:16:34,841 - jwst.ami.leastsqnrm - INFO - model transpose dimensions (44, 4724)
2026-04-15 20:16:34,842 - jwst.ami.leastsqnrm - INFO - flat image dimensions (4724,)
2026-04-15 20:16:34,842 - jwst.ami.leastsqnrm - INFO - transpose * image data dimensions (44,)
2026-04-15 20:16:34,843 - jwst.ami.leastsqnrm - INFO - flat img * transpose dimensions (44, 44)
2026-04-15 20:16:34,843 - jwst.ami.leastsqnrm - INFO - linearfit not attempted, no covariances saved.
2026-04-15 20:16:34,845 - jwst.ami.nrm_core - INFO - Fitting fringes for iteration 22 of 61
2026-04-15 20:16:35,905 - jwst.ami.leastsqnrm - INFO - fringefitting.leastsqnrm.matrix_operations():
2026-04-15 20:16:35,905 - jwst.ami.leastsqnrm - INFO - img (69, 69)
2026-04-15 20:16:35,906 - jwst.ami.leastsqnrm - INFO - L x W = 69 x 69 = 4761
2026-04-15 20:16:35,906 - jwst.ami.leastsqnrm - INFO - flatimg (4761,)
2026-04-15 20:16:35,907 - jwst.ami.leastsqnrm - INFO -
2026-04-15 20:16:35,907 - jwst.ami.leastsqnrm - INFO - type(dqm) <class 'numpy.ndarray'>
2026-04-15 20:16:35,907 - jwst.ami.leastsqnrm - INFO - type(nanlist) <class 'tuple'>, len=1
2026-04-15 20:16:35,908 - jwst.ami.leastsqnrm - INFO - number of nanlist pixels: 38 items
2026-04-15 20:16:35,908 - jwst.ami.leastsqnrm - INFO - 38 DO_NOT_USE pixels found in data slice
2026-04-15 20:16:35,909 - jwst.ami.leastsqnrm - INFO - flatimg (4723,) after deleting 38
2026-04-15 20:16:35,910 - jwst.ami.leastsqnrm - INFO - flatmodel_nan (4761, 44)
2026-04-15 20:16:35,910 - jwst.ami.leastsqnrm - INFO - flatmodel (4723, 44)
2026-04-15 20:16:35,911 - jwst.ami.leastsqnrm - INFO - difference 38
2026-04-15 20:16:35,911 - jwst.ami.leastsqnrm - INFO - flat model dimensions (4723, 44)
2026-04-15 20:16:35,911 - jwst.ami.leastsqnrm - INFO - flat image dimensions (4723,)
2026-04-15 20:16:35,914 - jwst.ami.leastsqnrm - INFO - data flux 1.0351816e+06
2026-04-15 20:16:35,914 - jwst.ami.leastsqnrm - INFO - flat model dimensions (4723, 44)
2026-04-15 20:16:35,915 - jwst.ami.leastsqnrm - INFO - model transpose dimensions (44, 4723)
2026-04-15 20:16:35,915 - jwst.ami.leastsqnrm - INFO - flat image dimensions (4723,)
2026-04-15 20:16:35,915 - jwst.ami.leastsqnrm - INFO - transpose * image data dimensions (44,)
2026-04-15 20:16:35,916 - jwst.ami.leastsqnrm - INFO - flat img * transpose dimensions (44, 44)
2026-04-15 20:16:35,916 - jwst.ami.leastsqnrm - INFO - linearfit not attempted, no covariances saved.
2026-04-15 20:16:35,918 - jwst.ami.nrm_core - INFO - Fitting fringes for iteration 23 of 61
2026-04-15 20:16:36,973 - jwst.ami.leastsqnrm - INFO - fringefitting.leastsqnrm.matrix_operations():
2026-04-15 20:16:36,973 - jwst.ami.leastsqnrm - INFO - img (69, 69)
2026-04-15 20:16:36,974 - jwst.ami.leastsqnrm - INFO - L x W = 69 x 69 = 4761
2026-04-15 20:16:36,974 - jwst.ami.leastsqnrm - INFO - flatimg (4761,)
2026-04-15 20:16:36,975 - jwst.ami.leastsqnrm - INFO -
2026-04-15 20:16:36,975 - jwst.ami.leastsqnrm - INFO - type(dqm) <class 'numpy.ndarray'>
2026-04-15 20:16:36,976 - jwst.ami.leastsqnrm - INFO - type(nanlist) <class 'tuple'>, len=1
2026-04-15 20:16:36,976 - jwst.ami.leastsqnrm - INFO - number of nanlist pixels: 38 items
2026-04-15 20:16:36,976 - jwst.ami.leastsqnrm - INFO - 38 DO_NOT_USE pixels found in data slice
2026-04-15 20:16:36,977 - jwst.ami.leastsqnrm - INFO - flatimg (4723,) after deleting 38
2026-04-15 20:16:36,978 - jwst.ami.leastsqnrm - INFO - flatmodel_nan (4761, 44)
2026-04-15 20:16:36,978 - jwst.ami.leastsqnrm - INFO - flatmodel (4723, 44)
2026-04-15 20:16:36,979 - jwst.ami.leastsqnrm - INFO - difference 38
2026-04-15 20:16:36,979 - jwst.ami.leastsqnrm - INFO - flat model dimensions (4723, 44)
2026-04-15 20:16:36,979 - jwst.ami.leastsqnrm - INFO - flat image dimensions (4723,)
2026-04-15 20:16:36,982 - jwst.ami.leastsqnrm - INFO - data flux 1.0311886e+06
2026-04-15 20:16:36,982 - jwst.ami.leastsqnrm - INFO - flat model dimensions (4723, 44)
2026-04-15 20:16:36,983 - jwst.ami.leastsqnrm - INFO - model transpose dimensions (44, 4723)
2026-04-15 20:16:36,983 - jwst.ami.leastsqnrm - INFO - flat image dimensions (4723,)
2026-04-15 20:16:36,984 - jwst.ami.leastsqnrm - INFO - transpose * image data dimensions (44,)
2026-04-15 20:16:36,984 - jwst.ami.leastsqnrm - INFO - flat img * transpose dimensions (44, 44)
2026-04-15 20:16:36,985 - jwst.ami.leastsqnrm - INFO - linearfit not attempted, no covariances saved.
2026-04-15 20:16:36,986 - jwst.ami.nrm_core - INFO - Fitting fringes for iteration 24 of 61
2026-04-15 20:16:38,035 - jwst.ami.leastsqnrm - INFO - fringefitting.leastsqnrm.matrix_operations():
2026-04-15 20:16:38,036 - jwst.ami.leastsqnrm - INFO - img (69, 69)
2026-04-15 20:16:38,037 - jwst.ami.leastsqnrm - INFO - L x W = 69 x 69 = 4761
2026-04-15 20:16:38,037 - jwst.ami.leastsqnrm - INFO - flatimg (4761,)
2026-04-15 20:16:38,037 - jwst.ami.leastsqnrm - INFO -
2026-04-15 20:16:38,038 - jwst.ami.leastsqnrm - INFO - type(dqm) <class 'numpy.ndarray'>
2026-04-15 20:16:38,038 - jwst.ami.leastsqnrm - INFO - type(nanlist) <class 'tuple'>, len=1
2026-04-15 20:16:38,039 - jwst.ami.leastsqnrm - INFO - number of nanlist pixels: 44 items
2026-04-15 20:16:38,039 - jwst.ami.leastsqnrm - INFO - 44 DO_NOT_USE pixels found in data slice
2026-04-15 20:16:38,040 - jwst.ami.leastsqnrm - INFO - flatimg (4717,) after deleting 44
2026-04-15 20:16:38,040 - jwst.ami.leastsqnrm - INFO - flatmodel_nan (4761, 44)
2026-04-15 20:16:38,041 - jwst.ami.leastsqnrm - INFO - flatmodel (4717, 44)
2026-04-15 20:16:38,041 - jwst.ami.leastsqnrm - INFO - difference 44
2026-04-15 20:16:38,041 - jwst.ami.leastsqnrm - INFO - flat model dimensions (4717, 44)
2026-04-15 20:16:38,042 - jwst.ami.leastsqnrm - INFO - flat image dimensions (4717,)
2026-04-15 20:16:38,045 - jwst.ami.leastsqnrm - INFO - data flux 1.047231e+06
2026-04-15 20:16:38,045 - jwst.ami.leastsqnrm - INFO - flat model dimensions (4717, 44)
2026-04-15 20:16:38,046 - jwst.ami.leastsqnrm - INFO - model transpose dimensions (44, 4717)
2026-04-15 20:16:38,046 - jwst.ami.leastsqnrm - INFO - flat image dimensions (4717,)
2026-04-15 20:16:38,047 - jwst.ami.leastsqnrm - INFO - transpose * image data dimensions (44,)
2026-04-15 20:16:38,047 - jwst.ami.leastsqnrm - INFO - flat img * transpose dimensions (44, 44)
2026-04-15 20:16:38,047 - jwst.ami.leastsqnrm - INFO - linearfit not attempted, no covariances saved.
2026-04-15 20:16:38,049 - jwst.ami.nrm_core - INFO - Fitting fringes for iteration 25 of 61
2026-04-15 20:16:39,095 - jwst.ami.leastsqnrm - INFO - fringefitting.leastsqnrm.matrix_operations():
2026-04-15 20:16:39,096 - jwst.ami.leastsqnrm - INFO - img (69, 69)
2026-04-15 20:16:39,096 - jwst.ami.leastsqnrm - INFO - L x W = 69 x 69 = 4761
2026-04-15 20:16:39,097 - jwst.ami.leastsqnrm - INFO - flatimg (4761,)
2026-04-15 20:16:39,097 - jwst.ami.leastsqnrm - INFO -
2026-04-15 20:16:39,098 - jwst.ami.leastsqnrm - INFO - type(dqm) <class 'numpy.ndarray'>
2026-04-15 20:16:39,098 - jwst.ami.leastsqnrm - INFO - type(nanlist) <class 'tuple'>, len=1
2026-04-15 20:16:39,099 - jwst.ami.leastsqnrm - INFO - number of nanlist pixels: 37 items
2026-04-15 20:16:39,099 - jwst.ami.leastsqnrm - INFO - 37 DO_NOT_USE pixels found in data slice
2026-04-15 20:16:39,099 - jwst.ami.leastsqnrm - INFO - flatimg (4724,) after deleting 37
2026-04-15 20:16:39,100 - jwst.ami.leastsqnrm - INFO - flatmodel_nan (4761, 44)
2026-04-15 20:16:39,101 - jwst.ami.leastsqnrm - INFO - flatmodel (4724, 44)
2026-04-15 20:16:39,101 - jwst.ami.leastsqnrm - INFO - difference 37
2026-04-15 20:16:39,102 - jwst.ami.leastsqnrm - INFO - flat model dimensions (4724, 44)
2026-04-15 20:16:39,102 - jwst.ami.leastsqnrm - INFO - flat image dimensions (4724,)
2026-04-15 20:16:39,105 - jwst.ami.leastsqnrm - INFO - data flux 1.0296239e+06
2026-04-15 20:16:39,105 - jwst.ami.leastsqnrm - INFO - flat model dimensions (4724, 44)
2026-04-15 20:16:39,106 - jwst.ami.leastsqnrm - INFO - model transpose dimensions (44, 4724)
2026-04-15 20:16:39,106 - jwst.ami.leastsqnrm - INFO - flat image dimensions (4724,)
2026-04-15 20:16:39,107 - jwst.ami.leastsqnrm - INFO - transpose * image data dimensions (44,)
2026-04-15 20:16:39,107 - jwst.ami.leastsqnrm - INFO - flat img * transpose dimensions (44, 44)
2026-04-15 20:16:39,107 - jwst.ami.leastsqnrm - INFO - linearfit not attempted, no covariances saved.
2026-04-15 20:16:39,109 - jwst.ami.nrm_core - INFO - Fitting fringes for iteration 26 of 61
2026-04-15 20:16:40,157 - jwst.ami.leastsqnrm - INFO - fringefitting.leastsqnrm.matrix_operations():
2026-04-15 20:16:40,158 - jwst.ami.leastsqnrm - INFO - img (69, 69)
2026-04-15 20:16:40,159 - jwst.ami.leastsqnrm - INFO - L x W = 69 x 69 = 4761
2026-04-15 20:16:40,159 - jwst.ami.leastsqnrm - INFO - flatimg (4761,)
2026-04-15 20:16:40,159 - jwst.ami.leastsqnrm - INFO -
2026-04-15 20:16:40,160 - jwst.ami.leastsqnrm - INFO - type(dqm) <class 'numpy.ndarray'>
2026-04-15 20:16:40,160 - jwst.ami.leastsqnrm - INFO - type(nanlist) <class 'tuple'>, len=1
2026-04-15 20:16:40,161 - jwst.ami.leastsqnrm - INFO - number of nanlist pixels: 41 items
2026-04-15 20:16:40,161 - jwst.ami.leastsqnrm - INFO - 41 DO_NOT_USE pixels found in data slice
2026-04-15 20:16:40,162 - jwst.ami.leastsqnrm - INFO - flatimg (4720,) after deleting 41
2026-04-15 20:16:40,163 - jwst.ami.leastsqnrm - INFO - flatmodel_nan (4761, 44)
2026-04-15 20:16:40,163 - jwst.ami.leastsqnrm - INFO - flatmodel (4720, 44)
2026-04-15 20:16:40,163 - jwst.ami.leastsqnrm - INFO - difference 41
2026-04-15 20:16:40,164 - jwst.ami.leastsqnrm - INFO - flat model dimensions (4720, 44)
2026-04-15 20:16:40,164 - jwst.ami.leastsqnrm - INFO - flat image dimensions (4720,)
2026-04-15 20:16:40,167 - jwst.ami.leastsqnrm - INFO - data flux 1.0298719e+06
2026-04-15 20:16:40,167 - jwst.ami.leastsqnrm - INFO - flat model dimensions (4720, 44)
2026-04-15 20:16:40,168 - jwst.ami.leastsqnrm - INFO - model transpose dimensions (44, 4720)
2026-04-15 20:16:40,168 - jwst.ami.leastsqnrm - INFO - flat image dimensions (4720,)
2026-04-15 20:16:40,169 - jwst.ami.leastsqnrm - INFO - transpose * image data dimensions (44,)
2026-04-15 20:16:40,169 - jwst.ami.leastsqnrm - INFO - flat img * transpose dimensions (44, 44)
2026-04-15 20:16:40,170 - jwst.ami.leastsqnrm - INFO - linearfit not attempted, no covariances saved.
2026-04-15 20:16:40,171 - jwst.ami.nrm_core - INFO - Fitting fringes for iteration 27 of 61
2026-04-15 20:16:41,211 - jwst.ami.leastsqnrm - INFO - fringefitting.leastsqnrm.matrix_operations():
2026-04-15 20:16:41,212 - jwst.ami.leastsqnrm - INFO - img (69, 69)
2026-04-15 20:16:41,213 - jwst.ami.leastsqnrm - INFO - L x W = 69 x 69 = 4761
2026-04-15 20:16:41,213 - jwst.ami.leastsqnrm - INFO - flatimg (4761,)
2026-04-15 20:16:41,214 - jwst.ami.leastsqnrm - INFO -
2026-04-15 20:16:41,214 - jwst.ami.leastsqnrm - INFO - type(dqm) <class 'numpy.ndarray'>
2026-04-15 20:16:41,215 - jwst.ami.leastsqnrm - INFO - type(nanlist) <class 'tuple'>, len=1
2026-04-15 20:16:41,215 - jwst.ami.leastsqnrm - INFO - number of nanlist pixels: 40 items
2026-04-15 20:16:41,216 - jwst.ami.leastsqnrm - INFO - 40 DO_NOT_USE pixels found in data slice
2026-04-15 20:16:41,216 - jwst.ami.leastsqnrm - INFO - flatimg (4721,) after deleting 40
2026-04-15 20:16:41,217 - jwst.ami.leastsqnrm - INFO - flatmodel_nan (4761, 44)
2026-04-15 20:16:41,217 - jwst.ami.leastsqnrm - INFO - flatmodel (4721, 44)
2026-04-15 20:16:41,218 - jwst.ami.leastsqnrm - INFO - difference 40
2026-04-15 20:16:41,218 - jwst.ami.leastsqnrm - INFO - flat model dimensions (4721, 44)
2026-04-15 20:16:41,218 - jwst.ami.leastsqnrm - INFO - flat image dimensions (4721,)
2026-04-15 20:16:41,221 - jwst.ami.leastsqnrm - INFO - data flux 1.0285065e+06
2026-04-15 20:16:41,221 - jwst.ami.leastsqnrm - INFO - flat model dimensions (4721, 44)
2026-04-15 20:16:41,222 - jwst.ami.leastsqnrm - INFO - model transpose dimensions (44, 4721)
2026-04-15 20:16:41,222 - jwst.ami.leastsqnrm - INFO - flat image dimensions (4721,)
2026-04-15 20:16:41,223 - jwst.ami.leastsqnrm - INFO - transpose * image data dimensions (44,)
2026-04-15 20:16:41,223 - jwst.ami.leastsqnrm - INFO - flat img * transpose dimensions (44, 44)
2026-04-15 20:16:41,224 - jwst.ami.leastsqnrm - INFO - linearfit not attempted, no covariances saved.
2026-04-15 20:16:41,225 - jwst.ami.nrm_core - INFO - Fitting fringes for iteration 28 of 61
2026-04-15 20:16:42,269 - jwst.ami.leastsqnrm - INFO - fringefitting.leastsqnrm.matrix_operations():
2026-04-15 20:16:42,270 - jwst.ami.leastsqnrm - INFO - img (69, 69)
2026-04-15 20:16:42,271 - jwst.ami.leastsqnrm - INFO - L x W = 69 x 69 = 4761
2026-04-15 20:16:42,271 - jwst.ami.leastsqnrm - INFO - flatimg (4761,)
2026-04-15 20:16:42,271 - jwst.ami.leastsqnrm - INFO -
2026-04-15 20:16:42,272 - jwst.ami.leastsqnrm - INFO - type(dqm) <class 'numpy.ndarray'>
2026-04-15 20:16:42,272 - jwst.ami.leastsqnrm - INFO - type(nanlist) <class 'tuple'>, len=1
2026-04-15 20:16:42,273 - jwst.ami.leastsqnrm - INFO - number of nanlist pixels: 38 items
2026-04-15 20:16:42,273 - jwst.ami.leastsqnrm - INFO - 38 DO_NOT_USE pixels found in data slice
2026-04-15 20:16:42,274 - jwst.ami.leastsqnrm - INFO - flatimg (4723,) after deleting 38
2026-04-15 20:16:42,275 - jwst.ami.leastsqnrm - INFO - flatmodel_nan (4761, 44)
2026-04-15 20:16:42,275 - jwst.ami.leastsqnrm - INFO - flatmodel (4723, 44)
2026-04-15 20:16:42,275 - jwst.ami.leastsqnrm - INFO - difference 38
2026-04-15 20:16:42,276 - jwst.ami.leastsqnrm - INFO - flat model dimensions (4723, 44)
2026-04-15 20:16:42,276 - jwst.ami.leastsqnrm - INFO - flat image dimensions (4723,)
2026-04-15 20:16:42,279 - jwst.ami.leastsqnrm - INFO - data flux 1.0355181e+06
2026-04-15 20:16:42,279 - jwst.ami.leastsqnrm - INFO - flat model dimensions (4723, 44)
2026-04-15 20:16:42,279 - jwst.ami.leastsqnrm - INFO - model transpose dimensions (44, 4723)
2026-04-15 20:16:42,280 - jwst.ami.leastsqnrm - INFO - flat image dimensions (4723,)
2026-04-15 20:16:42,280 - jwst.ami.leastsqnrm - INFO - transpose * image data dimensions (44,)
2026-04-15 20:16:42,281 - jwst.ami.leastsqnrm - INFO - flat img * transpose dimensions (44, 44)
2026-04-15 20:16:42,281 - jwst.ami.leastsqnrm - INFO - linearfit not attempted, no covariances saved.
2026-04-15 20:16:42,283 - jwst.ami.nrm_core - INFO - Fitting fringes for iteration 29 of 61
2026-04-15 20:16:43,322 - jwst.ami.leastsqnrm - INFO - fringefitting.leastsqnrm.matrix_operations():
2026-04-15 20:16:43,322 - jwst.ami.leastsqnrm - INFO - img (69, 69)
2026-04-15 20:16:43,323 - jwst.ami.leastsqnrm - INFO - L x W = 69 x 69 = 4761
2026-04-15 20:16:43,323 - jwst.ami.leastsqnrm - INFO - flatimg (4761,)
2026-04-15 20:16:43,323 - jwst.ami.leastsqnrm - INFO -
2026-04-15 20:16:43,324 - jwst.ami.leastsqnrm - INFO - type(dqm) <class 'numpy.ndarray'>
2026-04-15 20:16:43,324 - jwst.ami.leastsqnrm - INFO - type(nanlist) <class 'tuple'>, len=1
2026-04-15 20:16:43,325 - jwst.ami.leastsqnrm - INFO - number of nanlist pixels: 41 items
2026-04-15 20:16:43,325 - jwst.ami.leastsqnrm - INFO - 41 DO_NOT_USE pixels found in data slice
2026-04-15 20:16:43,326 - jwst.ami.leastsqnrm - INFO - flatimg (4720,) after deleting 41
2026-04-15 20:16:43,327 - jwst.ami.leastsqnrm - INFO - flatmodel_nan (4761, 44)
2026-04-15 20:16:43,327 - jwst.ami.leastsqnrm - INFO - flatmodel (4720, 44)
2026-04-15 20:16:43,327 - jwst.ami.leastsqnrm - INFO - difference 41
2026-04-15 20:16:43,328 - jwst.ami.leastsqnrm - INFO - flat model dimensions (4720, 44)
2026-04-15 20:16:43,328 - jwst.ami.leastsqnrm - INFO - flat image dimensions (4720,)
2026-04-15 20:16:43,330 - jwst.ami.leastsqnrm - INFO - data flux 1.0323895e+06
2026-04-15 20:16:43,331 - jwst.ami.leastsqnrm - INFO - flat model dimensions (4720, 44)
2026-04-15 20:16:43,331 - jwst.ami.leastsqnrm - INFO - model transpose dimensions (44, 4720)
2026-04-15 20:16:43,332 - jwst.ami.leastsqnrm - INFO - flat image dimensions (4720,)
2026-04-15 20:16:43,332 - jwst.ami.leastsqnrm - INFO - transpose * image data dimensions (44,)
2026-04-15 20:16:43,333 - jwst.ami.leastsqnrm - INFO - flat img * transpose dimensions (44, 44)
2026-04-15 20:16:43,333 - jwst.ami.leastsqnrm - INFO - linearfit not attempted, no covariances saved.
2026-04-15 20:16:43,335 - jwst.ami.nrm_core - INFO - Fitting fringes for iteration 30 of 61
2026-04-15 20:16:44,386 - jwst.ami.leastsqnrm - INFO - fringefitting.leastsqnrm.matrix_operations():
2026-04-15 20:16:44,387 - jwst.ami.leastsqnrm - INFO - img (69, 69)
2026-04-15 20:16:44,388 - jwst.ami.leastsqnrm - INFO - L x W = 69 x 69 = 4761
2026-04-15 20:16:44,388 - jwst.ami.leastsqnrm - INFO - flatimg (4761,)
2026-04-15 20:16:44,389 - jwst.ami.leastsqnrm - INFO -
2026-04-15 20:16:44,389 - jwst.ami.leastsqnrm - INFO - type(dqm) <class 'numpy.ndarray'>
2026-04-15 20:16:44,389 - jwst.ami.leastsqnrm - INFO - type(nanlist) <class 'tuple'>, len=1
2026-04-15 20:16:44,390 - jwst.ami.leastsqnrm - INFO - number of nanlist pixels: 37 items
2026-04-15 20:16:44,390 - jwst.ami.leastsqnrm - INFO - 37 DO_NOT_USE pixels found in data slice
2026-04-15 20:16:44,391 - jwst.ami.leastsqnrm - INFO - flatimg (4724,) after deleting 37
2026-04-15 20:16:44,392 - jwst.ami.leastsqnrm - INFO - flatmodel_nan (4761, 44)
2026-04-15 20:16:44,392 - jwst.ami.leastsqnrm - INFO - flatmodel (4724, 44)
2026-04-15 20:16:44,392 - jwst.ami.leastsqnrm - INFO - difference 37
2026-04-15 20:16:44,393 - jwst.ami.leastsqnrm - INFO - flat model dimensions (4724, 44)
2026-04-15 20:16:44,393 - jwst.ami.leastsqnrm - INFO - flat image dimensions (4724,)
2026-04-15 20:16:44,396 - jwst.ami.leastsqnrm - INFO - data flux 1.0342506e+06
2026-04-15 20:16:44,396 - jwst.ami.leastsqnrm - INFO - flat model dimensions (4724, 44)
2026-04-15 20:16:44,397 - jwst.ami.leastsqnrm - INFO - model transpose dimensions (44, 4724)
2026-04-15 20:16:44,397 - jwst.ami.leastsqnrm - INFO - flat image dimensions (4724,)
2026-04-15 20:16:44,397 - jwst.ami.leastsqnrm - INFO - transpose * image data dimensions (44,)
2026-04-15 20:16:44,398 - jwst.ami.leastsqnrm - INFO - flat img * transpose dimensions (44, 44)
2026-04-15 20:16:44,398 - jwst.ami.leastsqnrm - INFO - linearfit not attempted, no covariances saved.
2026-04-15 20:16:44,400 - jwst.ami.nrm_core - INFO - Fitting fringes for iteration 31 of 61
2026-04-15 20:16:45,459 - jwst.ami.leastsqnrm - INFO - fringefitting.leastsqnrm.matrix_operations():
2026-04-15 20:16:45,459 - jwst.ami.leastsqnrm - INFO - img (69, 69)
2026-04-15 20:16:45,460 - jwst.ami.leastsqnrm - INFO - L x W = 69 x 69 = 4761
2026-04-15 20:16:45,460 - jwst.ami.leastsqnrm - INFO - flatimg (4761,)
2026-04-15 20:16:45,461 - jwst.ami.leastsqnrm - INFO -
2026-04-15 20:16:45,461 - jwst.ami.leastsqnrm - INFO - type(dqm) <class 'numpy.ndarray'>
2026-04-15 20:16:45,461 - jwst.ami.leastsqnrm - INFO - type(nanlist) <class 'tuple'>, len=1
2026-04-15 20:16:45,462 - jwst.ami.leastsqnrm - INFO - number of nanlist pixels: 39 items
2026-04-15 20:16:45,462 - jwst.ami.leastsqnrm - INFO - 39 DO_NOT_USE pixels found in data slice
2026-04-15 20:16:45,463 - jwst.ami.leastsqnrm - INFO - flatimg (4722,) after deleting 39
2026-04-15 20:16:45,464 - jwst.ami.leastsqnrm - INFO - flatmodel_nan (4761, 44)
2026-04-15 20:16:45,464 - jwst.ami.leastsqnrm - INFO - flatmodel (4722, 44)
2026-04-15 20:16:45,465 - jwst.ami.leastsqnrm - INFO - difference 39
2026-04-15 20:16:45,465 - jwst.ami.leastsqnrm - INFO - flat model dimensions (4722, 44)
2026-04-15 20:16:45,466 - jwst.ami.leastsqnrm - INFO - flat image dimensions (4722,)
2026-04-15 20:16:45,468 - jwst.ami.leastsqnrm - INFO - data flux 1.0370354e+06
2026-04-15 20:16:45,468 - jwst.ami.leastsqnrm - INFO - flat model dimensions (4722, 44)
2026-04-15 20:16:45,469 - jwst.ami.leastsqnrm - INFO - model transpose dimensions (44, 4722)
2026-04-15 20:16:45,469 - jwst.ami.leastsqnrm - INFO - flat image dimensions (4722,)
2026-04-15 20:16:45,469 - jwst.ami.leastsqnrm - INFO - transpose * image data dimensions (44,)
2026-04-15 20:16:45,470 - jwst.ami.leastsqnrm - INFO - flat img * transpose dimensions (44, 44)
2026-04-15 20:16:45,470 - jwst.ami.leastsqnrm - INFO - linearfit not attempted, no covariances saved.
2026-04-15 20:16:45,472 - jwst.ami.nrm_core - INFO - Fitting fringes for iteration 32 of 61
2026-04-15 20:16:46,509 - jwst.ami.leastsqnrm - INFO - fringefitting.leastsqnrm.matrix_operations():
2026-04-15 20:16:46,510 - jwst.ami.leastsqnrm - INFO - img (69, 69)
2026-04-15 20:16:46,510 - jwst.ami.leastsqnrm - INFO - L x W = 69 x 69 = 4761
2026-04-15 20:16:46,511 - jwst.ami.leastsqnrm - INFO - flatimg (4761,)
2026-04-15 20:16:46,511 - jwst.ami.leastsqnrm - INFO -
2026-04-15 20:16:46,511 - jwst.ami.leastsqnrm - INFO - type(dqm) <class 'numpy.ndarray'>
2026-04-15 20:16:46,512 - jwst.ami.leastsqnrm - INFO - type(nanlist) <class 'tuple'>, len=1
2026-04-15 20:16:46,512 - jwst.ami.leastsqnrm - INFO - number of nanlist pixels: 41 items
2026-04-15 20:16:46,513 - jwst.ami.leastsqnrm - INFO - 41 DO_NOT_USE pixels found in data slice
2026-04-15 20:16:46,513 - jwst.ami.leastsqnrm - INFO - flatimg (4720,) after deleting 41
2026-04-15 20:16:46,514 - jwst.ami.leastsqnrm - INFO - flatmodel_nan (4761, 44)
2026-04-15 20:16:46,515 - jwst.ami.leastsqnrm - INFO - flatmodel (4720, 44)
2026-04-15 20:16:46,515 - jwst.ami.leastsqnrm - INFO - difference 41
2026-04-15 20:16:46,516 - jwst.ami.leastsqnrm - INFO - flat model dimensions (4720, 44)
2026-04-15 20:16:46,516 - jwst.ami.leastsqnrm - INFO - flat image dimensions (4720,)
2026-04-15 20:16:46,518 - jwst.ami.leastsqnrm - INFO - data flux 1.03109075e+06
2026-04-15 20:16:46,519 - jwst.ami.leastsqnrm - INFO - flat model dimensions (4720, 44)
2026-04-15 20:16:46,519 - jwst.ami.leastsqnrm - INFO - model transpose dimensions (44, 4720)
2026-04-15 20:16:46,520 - jwst.ami.leastsqnrm - INFO - flat image dimensions (4720,)
2026-04-15 20:16:46,520 - jwst.ami.leastsqnrm - INFO - transpose * image data dimensions (44,)
2026-04-15 20:16:46,520 - jwst.ami.leastsqnrm - INFO - flat img * transpose dimensions (44, 44)
2026-04-15 20:16:46,521 - jwst.ami.leastsqnrm - INFO - linearfit not attempted, no covariances saved.
2026-04-15 20:16:46,522 - jwst.ami.nrm_core - INFO - Fitting fringes for iteration 33 of 61
2026-04-15 20:16:47,560 - jwst.ami.leastsqnrm - INFO - fringefitting.leastsqnrm.matrix_operations():
2026-04-15 20:16:47,561 - jwst.ami.leastsqnrm - INFO - img (69, 69)
2026-04-15 20:16:47,561 - jwst.ami.leastsqnrm - INFO - L x W = 69 x 69 = 4761
2026-04-15 20:16:47,562 - jwst.ami.leastsqnrm - INFO - flatimg (4761,)
2026-04-15 20:16:47,562 - jwst.ami.leastsqnrm - INFO -
2026-04-15 20:16:47,562 - jwst.ami.leastsqnrm - INFO - type(dqm) <class 'numpy.ndarray'>
2026-04-15 20:16:47,563 - jwst.ami.leastsqnrm - INFO - type(nanlist) <class 'tuple'>, len=1
2026-04-15 20:16:47,563 - jwst.ami.leastsqnrm - INFO - number of nanlist pixels: 38 items
2026-04-15 20:16:47,564 - jwst.ami.leastsqnrm - INFO - 38 DO_NOT_USE pixels found in data slice
2026-04-15 20:16:47,564 - jwst.ami.leastsqnrm - INFO - flatimg (4723,) after deleting 38
2026-04-15 20:16:47,565 - jwst.ami.leastsqnrm - INFO - flatmodel_nan (4761, 44)
2026-04-15 20:16:47,566 - jwst.ami.leastsqnrm - INFO - flatmodel (4723, 44)
2026-04-15 20:16:47,566 - jwst.ami.leastsqnrm - INFO - difference 38
2026-04-15 20:16:47,566 - jwst.ami.leastsqnrm - INFO - flat model dimensions (4723, 44)
2026-04-15 20:16:47,567 - jwst.ami.leastsqnrm - INFO - flat image dimensions (4723,)
2026-04-15 20:16:47,569 - jwst.ami.leastsqnrm - INFO - data flux 1.0266356e+06
2026-04-15 20:16:47,569 - jwst.ami.leastsqnrm - INFO - flat model dimensions (4723, 44)
2026-04-15 20:16:47,570 - jwst.ami.leastsqnrm - INFO - model transpose dimensions (44, 4723)
2026-04-15 20:16:47,570 - jwst.ami.leastsqnrm - INFO - flat image dimensions (4723,)
2026-04-15 20:16:47,571 - jwst.ami.leastsqnrm - INFO - transpose * image data dimensions (44,)
2026-04-15 20:16:47,571 - jwst.ami.leastsqnrm - INFO - flat img * transpose dimensions (44, 44)
2026-04-15 20:16:47,572 - jwst.ami.leastsqnrm - INFO - linearfit not attempted, no covariances saved.
2026-04-15 20:16:47,573 - jwst.ami.nrm_core - INFO - Fitting fringes for iteration 34 of 61
2026-04-15 20:16:48,618 - jwst.ami.leastsqnrm - INFO - fringefitting.leastsqnrm.matrix_operations():
2026-04-15 20:16:48,619 - jwst.ami.leastsqnrm - INFO - img (69, 69)
2026-04-15 20:16:48,619 - jwst.ami.leastsqnrm - INFO - L x W = 69 x 69 = 4761
2026-04-15 20:16:48,620 - jwst.ami.leastsqnrm - INFO - flatimg (4761,)
2026-04-15 20:16:48,620 - jwst.ami.leastsqnrm - INFO -
2026-04-15 20:16:48,621 - jwst.ami.leastsqnrm - INFO - type(dqm) <class 'numpy.ndarray'>
2026-04-15 20:16:48,621 - jwst.ami.leastsqnrm - INFO - type(nanlist) <class 'tuple'>, len=1
2026-04-15 20:16:48,622 - jwst.ami.leastsqnrm - INFO - number of nanlist pixels: 39 items
2026-04-15 20:16:48,622 - jwst.ami.leastsqnrm - INFO - 39 DO_NOT_USE pixels found in data slice
2026-04-15 20:16:48,622 - jwst.ami.leastsqnrm - INFO - flatimg (4722,) after deleting 39
2026-04-15 20:16:48,623 - jwst.ami.leastsqnrm - INFO - flatmodel_nan (4761, 44)
2026-04-15 20:16:48,624 - jwst.ami.leastsqnrm - INFO - flatmodel (4722, 44)
2026-04-15 20:16:48,624 - jwst.ami.leastsqnrm - INFO - difference 39
2026-04-15 20:16:48,624 - jwst.ami.leastsqnrm - INFO - flat model dimensions (4722, 44)
2026-04-15 20:16:48,625 - jwst.ami.leastsqnrm - INFO - flat image dimensions (4722,)
2026-04-15 20:16:48,627 - jwst.ami.leastsqnrm - INFO - data flux 1.0376419e+06
2026-04-15 20:16:48,628 - jwst.ami.leastsqnrm - INFO - flat model dimensions (4722, 44)
2026-04-15 20:16:48,628 - jwst.ami.leastsqnrm - INFO - model transpose dimensions (44, 4722)
2026-04-15 20:16:48,628 - jwst.ami.leastsqnrm - INFO - flat image dimensions (4722,)
2026-04-15 20:16:48,629 - jwst.ami.leastsqnrm - INFO - transpose * image data dimensions (44,)
2026-04-15 20:16:48,629 - jwst.ami.leastsqnrm - INFO - flat img * transpose dimensions (44, 44)
2026-04-15 20:16:48,630 - jwst.ami.leastsqnrm - INFO - linearfit not attempted, no covariances saved.
2026-04-15 20:16:48,631 - jwst.ami.nrm_core - INFO - Fitting fringes for iteration 35 of 61
2026-04-15 20:16:49,677 - jwst.ami.leastsqnrm - INFO - fringefitting.leastsqnrm.matrix_operations():
2026-04-15 20:16:49,678 - jwst.ami.leastsqnrm - INFO - img (69, 69)
2026-04-15 20:16:49,678 - jwst.ami.leastsqnrm - INFO - L x W = 69 x 69 = 4761
2026-04-15 20:16:49,679 - jwst.ami.leastsqnrm - INFO - flatimg (4761,)
2026-04-15 20:16:49,679 - jwst.ami.leastsqnrm - INFO -
2026-04-15 20:16:49,680 - jwst.ami.leastsqnrm - INFO - type(dqm) <class 'numpy.ndarray'>
2026-04-15 20:16:49,680 - jwst.ami.leastsqnrm - INFO - type(nanlist) <class 'tuple'>, len=1
2026-04-15 20:16:49,681 - jwst.ami.leastsqnrm - INFO - number of nanlist pixels: 40 items
2026-04-15 20:16:49,681 - jwst.ami.leastsqnrm - INFO - 40 DO_NOT_USE pixels found in data slice
2026-04-15 20:16:49,682 - jwst.ami.leastsqnrm - INFO - flatimg (4721,) after deleting 40
2026-04-15 20:16:49,683 - jwst.ami.leastsqnrm - INFO - flatmodel_nan (4761, 44)
2026-04-15 20:16:49,683 - jwst.ami.leastsqnrm - INFO - flatmodel (4721, 44)
2026-04-15 20:16:49,683 - jwst.ami.leastsqnrm - INFO - difference 40
2026-04-15 20:16:49,684 - jwst.ami.leastsqnrm - INFO - flat model dimensions (4721, 44)
2026-04-15 20:16:49,684 - jwst.ami.leastsqnrm - INFO - flat image dimensions (4721,)
2026-04-15 20:16:49,686 - jwst.ami.leastsqnrm - INFO - data flux 1.0377014e+06
2026-04-15 20:16:49,687 - jwst.ami.leastsqnrm - INFO - flat model dimensions (4721, 44)
2026-04-15 20:16:49,687 - jwst.ami.leastsqnrm - INFO - model transpose dimensions (44, 4721)
2026-04-15 20:16:49,688 - jwst.ami.leastsqnrm - INFO - flat image dimensions (4721,)
2026-04-15 20:16:49,688 - jwst.ami.leastsqnrm - INFO - transpose * image data dimensions (44,)
2026-04-15 20:16:49,689 - jwst.ami.leastsqnrm - INFO - flat img * transpose dimensions (44, 44)
2026-04-15 20:16:49,689 - jwst.ami.leastsqnrm - INFO - linearfit not attempted, no covariances saved.
2026-04-15 20:16:49,690 - jwst.ami.nrm_core - INFO - Fitting fringes for iteration 36 of 61
2026-04-15 20:16:50,730 - jwst.ami.leastsqnrm - INFO - fringefitting.leastsqnrm.matrix_operations():
2026-04-15 20:16:50,731 - jwst.ami.leastsqnrm - INFO - img (69, 69)
2026-04-15 20:16:50,731 - jwst.ami.leastsqnrm - INFO - L x W = 69 x 69 = 4761
2026-04-15 20:16:50,732 - jwst.ami.leastsqnrm - INFO - flatimg (4761,)
2026-04-15 20:16:50,732 - jwst.ami.leastsqnrm - INFO -
2026-04-15 20:16:50,732 - jwst.ami.leastsqnrm - INFO - type(dqm) <class 'numpy.ndarray'>
2026-04-15 20:16:50,733 - jwst.ami.leastsqnrm - INFO - type(nanlist) <class 'tuple'>, len=1
2026-04-15 20:16:50,733 - jwst.ami.leastsqnrm - INFO - number of nanlist pixels: 38 items
2026-04-15 20:16:50,734 - jwst.ami.leastsqnrm - INFO - 38 DO_NOT_USE pixels found in data slice
2026-04-15 20:16:50,734 - jwst.ami.leastsqnrm - INFO - flatimg (4723,) after deleting 38
2026-04-15 20:16:50,735 - jwst.ami.leastsqnrm - INFO - flatmodel_nan (4761, 44)
2026-04-15 20:16:50,736 - jwst.ami.leastsqnrm - INFO - flatmodel (4723, 44)
2026-04-15 20:16:50,736 - jwst.ami.leastsqnrm - INFO - difference 38
2026-04-15 20:16:50,736 - jwst.ami.leastsqnrm - INFO - flat model dimensions (4723, 44)
2026-04-15 20:16:50,737 - jwst.ami.leastsqnrm - INFO - flat image dimensions (4723,)
2026-04-15 20:16:50,739 - jwst.ami.leastsqnrm - INFO - data flux 1.04165475e+06
2026-04-15 20:16:50,739 - jwst.ami.leastsqnrm - INFO - flat model dimensions (4723, 44)
2026-04-15 20:16:50,740 - jwst.ami.leastsqnrm - INFO - model transpose dimensions (44, 4723)
2026-04-15 20:16:50,740 - jwst.ami.leastsqnrm - INFO - flat image dimensions (4723,)
2026-04-15 20:16:50,741 - jwst.ami.leastsqnrm - INFO - transpose * image data dimensions (44,)
2026-04-15 20:16:50,741 - jwst.ami.leastsqnrm - INFO - flat img * transpose dimensions (44, 44)
2026-04-15 20:16:50,742 - jwst.ami.leastsqnrm - INFO - linearfit not attempted, no covariances saved.
2026-04-15 20:16:50,743 - jwst.ami.nrm_core - INFO - Fitting fringes for iteration 37 of 61
2026-04-15 20:16:51,782 - jwst.ami.leastsqnrm - INFO - fringefitting.leastsqnrm.matrix_operations():
2026-04-15 20:16:51,783 - jwst.ami.leastsqnrm - INFO - img (69, 69)
2026-04-15 20:16:51,783 - jwst.ami.leastsqnrm - INFO - L x W = 69 x 69 = 4761
2026-04-15 20:16:51,784 - jwst.ami.leastsqnrm - INFO - flatimg (4761,)
2026-04-15 20:16:51,784 - jwst.ami.leastsqnrm - INFO -
2026-04-15 20:16:51,785 - jwst.ami.leastsqnrm - INFO - type(dqm) <class 'numpy.ndarray'>
2026-04-15 20:16:51,785 - jwst.ami.leastsqnrm - INFO - type(nanlist) <class 'tuple'>, len=1
2026-04-15 20:16:51,785 - jwst.ami.leastsqnrm - INFO - number of nanlist pixels: 39 items
2026-04-15 20:16:51,786 - jwst.ami.leastsqnrm - INFO - 39 DO_NOT_USE pixels found in data slice
2026-04-15 20:16:51,786 - jwst.ami.leastsqnrm - INFO - flatimg (4722,) after deleting 39
2026-04-15 20:16:51,787 - jwst.ami.leastsqnrm - INFO - flatmodel_nan (4761, 44)
2026-04-15 20:16:51,787 - jwst.ami.leastsqnrm - INFO - flatmodel (4722, 44)
2026-04-15 20:16:51,788 - jwst.ami.leastsqnrm - INFO - difference 39
2026-04-15 20:16:51,788 - jwst.ami.leastsqnrm - INFO - flat model dimensions (4722, 44)
2026-04-15 20:16:51,789 - jwst.ami.leastsqnrm - INFO - flat image dimensions (4722,)
2026-04-15 20:16:51,791 - jwst.ami.leastsqnrm - INFO - data flux 1.038881e+06
2026-04-15 20:16:51,792 - jwst.ami.leastsqnrm - INFO - flat model dimensions (4722, 44)
2026-04-15 20:16:51,792 - jwst.ami.leastsqnrm - INFO - model transpose dimensions (44, 4722)
2026-04-15 20:16:51,793 - jwst.ami.leastsqnrm - INFO - flat image dimensions (4722,)
2026-04-15 20:16:51,793 - jwst.ami.leastsqnrm - INFO - transpose * image data dimensions (44,)
2026-04-15 20:16:51,793 - jwst.ami.leastsqnrm - INFO - flat img * transpose dimensions (44, 44)
2026-04-15 20:16:51,794 - jwst.ami.leastsqnrm - INFO - linearfit not attempted, no covariances saved.
2026-04-15 20:16:51,795 - jwst.ami.nrm_core - INFO - Fitting fringes for iteration 38 of 61
2026-04-15 20:16:52,835 - jwst.ami.leastsqnrm - INFO - fringefitting.leastsqnrm.matrix_operations():
2026-04-15 20:16:52,835 - jwst.ami.leastsqnrm - INFO - img (69, 69)
2026-04-15 20:16:52,836 - jwst.ami.leastsqnrm - INFO - L x W = 69 x 69 = 4761
2026-04-15 20:16:52,836 - jwst.ami.leastsqnrm - INFO - flatimg (4761,)
2026-04-15 20:16:52,837 - jwst.ami.leastsqnrm - INFO -
2026-04-15 20:16:52,837 - jwst.ami.leastsqnrm - INFO - type(dqm) <class 'numpy.ndarray'>
2026-04-15 20:16:52,838 - jwst.ami.leastsqnrm - INFO - type(nanlist) <class 'tuple'>, len=1
2026-04-15 20:16:52,838 - jwst.ami.leastsqnrm - INFO - number of nanlist pixels: 37 items
2026-04-15 20:16:52,838 - jwst.ami.leastsqnrm - INFO - 37 DO_NOT_USE pixels found in data slice
2026-04-15 20:16:52,839 - jwst.ami.leastsqnrm - INFO - flatimg (4724,) after deleting 37
2026-04-15 20:16:52,840 - jwst.ami.leastsqnrm - INFO - flatmodel_nan (4761, 44)
2026-04-15 20:16:52,840 - jwst.ami.leastsqnrm - INFO - flatmodel (4724, 44)
2026-04-15 20:16:52,841 - jwst.ami.leastsqnrm - INFO - difference 37
2026-04-15 20:16:52,841 - jwst.ami.leastsqnrm - INFO - flat model dimensions (4724, 44)
2026-04-15 20:16:52,841 - jwst.ami.leastsqnrm - INFO - flat image dimensions (4724,)
2026-04-15 20:16:52,844 - jwst.ami.leastsqnrm - INFO - data flux 1.03721575e+06
2026-04-15 20:16:52,844 - jwst.ami.leastsqnrm - INFO - flat model dimensions (4724, 44)
2026-04-15 20:16:52,845 - jwst.ami.leastsqnrm - INFO - model transpose dimensions (44, 4724)
2026-04-15 20:16:52,845 - jwst.ami.leastsqnrm - INFO - flat image dimensions (4724,)
2026-04-15 20:16:52,846 - jwst.ami.leastsqnrm - INFO - transpose * image data dimensions (44,)
2026-04-15 20:16:52,846 - jwst.ami.leastsqnrm - INFO - flat img * transpose dimensions (44, 44)
2026-04-15 20:16:52,846 - jwst.ami.leastsqnrm - INFO - linearfit not attempted, no covariances saved.
2026-04-15 20:16:52,848 - jwst.ami.nrm_core - INFO - Fitting fringes for iteration 39 of 61
2026-04-15 20:16:53,886 - jwst.ami.leastsqnrm - INFO - fringefitting.leastsqnrm.matrix_operations():
2026-04-15 20:16:53,887 - jwst.ami.leastsqnrm - INFO - img (69, 69)
2026-04-15 20:16:53,887 - jwst.ami.leastsqnrm - INFO - L x W = 69 x 69 = 4761
2026-04-15 20:16:53,887 - jwst.ami.leastsqnrm - INFO - flatimg (4761,)
2026-04-15 20:16:53,888 - jwst.ami.leastsqnrm - INFO -
2026-04-15 20:16:53,888 - jwst.ami.leastsqnrm - INFO - type(dqm) <class 'numpy.ndarray'>
2026-04-15 20:16:53,889 - jwst.ami.leastsqnrm - INFO - type(nanlist) <class 'tuple'>, len=1
2026-04-15 20:16:53,889 - jwst.ami.leastsqnrm - INFO - number of nanlist pixels: 39 items
2026-04-15 20:16:53,890 - jwst.ami.leastsqnrm - INFO - 39 DO_NOT_USE pixels found in data slice
2026-04-15 20:16:53,890 - jwst.ami.leastsqnrm - INFO - flatimg (4722,) after deleting 39
2026-04-15 20:16:53,891 - jwst.ami.leastsqnrm - INFO - flatmodel_nan (4761, 44)
2026-04-15 20:16:53,891 - jwst.ami.leastsqnrm - INFO - flatmodel (4722, 44)
2026-04-15 20:16:53,892 - jwst.ami.leastsqnrm - INFO - difference 39
2026-04-15 20:16:53,892 - jwst.ami.leastsqnrm - INFO - flat model dimensions (4722, 44)
2026-04-15 20:16:53,893 - jwst.ami.leastsqnrm - INFO - flat image dimensions (4722,)
2026-04-15 20:16:53,895 - jwst.ami.leastsqnrm - INFO - data flux 1.03577844e+06
2026-04-15 20:16:53,895 - jwst.ami.leastsqnrm - INFO - flat model dimensions (4722, 44)
2026-04-15 20:16:53,896 - jwst.ami.leastsqnrm - INFO - model transpose dimensions (44, 4722)
2026-04-15 20:16:53,896 - jwst.ami.leastsqnrm - INFO - flat image dimensions (4722,)
2026-04-15 20:16:53,897 - jwst.ami.leastsqnrm - INFO - transpose * image data dimensions (44,)
2026-04-15 20:16:53,897 - jwst.ami.leastsqnrm - INFO - flat img * transpose dimensions (44, 44)
2026-04-15 20:16:53,898 - jwst.ami.leastsqnrm - INFO - linearfit not attempted, no covariances saved.
2026-04-15 20:16:53,899 - jwst.ami.nrm_core - INFO - Fitting fringes for iteration 40 of 61
2026-04-15 20:16:54,944 - jwst.ami.leastsqnrm - INFO - fringefitting.leastsqnrm.matrix_operations():
2026-04-15 20:16:54,944 - jwst.ami.leastsqnrm - INFO - img (69, 69)
2026-04-15 20:16:54,945 - jwst.ami.leastsqnrm - INFO - L x W = 69 x 69 = 4761
2026-04-15 20:16:54,945 - jwst.ami.leastsqnrm - INFO - flatimg (4761,)
2026-04-15 20:16:54,946 - jwst.ami.leastsqnrm - INFO -
2026-04-15 20:16:54,946 - jwst.ami.leastsqnrm - INFO - type(dqm) <class 'numpy.ndarray'>
2026-04-15 20:16:54,947 - jwst.ami.leastsqnrm - INFO - type(nanlist) <class 'tuple'>, len=1
2026-04-15 20:16:54,948 - jwst.ami.leastsqnrm - INFO - number of nanlist pixels: 36 items
2026-04-15 20:16:54,948 - jwst.ami.leastsqnrm - INFO - 36 DO_NOT_USE pixels found in data slice
2026-04-15 20:16:54,949 - jwst.ami.leastsqnrm - INFO - flatimg (4725,) after deleting 36
2026-04-15 20:16:54,949 - jwst.ami.leastsqnrm - INFO - flatmodel_nan (4761, 44)
2026-04-15 20:16:54,950 - jwst.ami.leastsqnrm - INFO - flatmodel (4725, 44)
2026-04-15 20:16:54,950 - jwst.ami.leastsqnrm - INFO - difference 36
2026-04-15 20:16:54,950 - jwst.ami.leastsqnrm - INFO - flat model dimensions (4725, 44)
2026-04-15 20:16:54,951 - jwst.ami.leastsqnrm - INFO - flat image dimensions (4725,)
2026-04-15 20:16:54,953 - jwst.ami.leastsqnrm - INFO - data flux 1.0213218e+06
2026-04-15 20:16:54,954 - jwst.ami.leastsqnrm - INFO - flat model dimensions (4725, 44)
2026-04-15 20:16:54,954 - jwst.ami.leastsqnrm - INFO - model transpose dimensions (44, 4725)
2026-04-15 20:16:54,954 - jwst.ami.leastsqnrm - INFO - flat image dimensions (4725,)
2026-04-15 20:16:54,955 - jwst.ami.leastsqnrm - INFO - transpose * image data dimensions (44,)
2026-04-15 20:16:54,955 - jwst.ami.leastsqnrm - INFO - flat img * transpose dimensions (44, 44)
2026-04-15 20:16:54,956 - jwst.ami.leastsqnrm - INFO - linearfit not attempted, no covariances saved.
2026-04-15 20:16:54,957 - jwst.ami.nrm_core - INFO - Fitting fringes for iteration 41 of 61
2026-04-15 20:16:55,996 - jwst.ami.leastsqnrm - INFO - fringefitting.leastsqnrm.matrix_operations():
2026-04-15 20:16:55,997 - jwst.ami.leastsqnrm - INFO - img (69, 69)
2026-04-15 20:16:55,997 - jwst.ami.leastsqnrm - INFO - L x W = 69 x 69 = 4761
2026-04-15 20:16:55,998 - jwst.ami.leastsqnrm - INFO - flatimg (4761,)
2026-04-15 20:16:55,998 - jwst.ami.leastsqnrm - INFO -
2026-04-15 20:16:55,999 - jwst.ami.leastsqnrm - INFO - type(dqm) <class 'numpy.ndarray'>
2026-04-15 20:16:55,999 - jwst.ami.leastsqnrm - INFO - type(nanlist) <class 'tuple'>, len=1
2026-04-15 20:16:56,000 - jwst.ami.leastsqnrm - INFO - number of nanlist pixels: 38 items
2026-04-15 20:16:56,000 - jwst.ami.leastsqnrm - INFO - 38 DO_NOT_USE pixels found in data slice
2026-04-15 20:16:56,001 - jwst.ami.leastsqnrm - INFO - flatimg (4723,) after deleting 38
2026-04-15 20:16:56,001 - jwst.ami.leastsqnrm - INFO - flatmodel_nan (4761, 44)
2026-04-15 20:16:56,002 - jwst.ami.leastsqnrm - INFO - flatmodel (4723, 44)
2026-04-15 20:16:56,002 - jwst.ami.leastsqnrm - INFO - difference 38
2026-04-15 20:16:56,002 - jwst.ami.leastsqnrm - INFO - flat model dimensions (4723, 44)
2026-04-15 20:16:56,003 - jwst.ami.leastsqnrm - INFO - flat image dimensions (4723,)
2026-04-15 20:16:56,005 - jwst.ami.leastsqnrm - INFO - data flux 1.0339372e+06
2026-04-15 20:16:56,006 - jwst.ami.leastsqnrm - INFO - flat model dimensions (4723, 44)
2026-04-15 20:16:56,006 - jwst.ami.leastsqnrm - INFO - model transpose dimensions (44, 4723)
2026-04-15 20:16:56,007 - jwst.ami.leastsqnrm - INFO - flat image dimensions (4723,)
2026-04-15 20:16:56,007 - jwst.ami.leastsqnrm - INFO - transpose * image data dimensions (44,)
2026-04-15 20:16:56,008 - jwst.ami.leastsqnrm - INFO - flat img * transpose dimensions (44, 44)
2026-04-15 20:16:56,008 - jwst.ami.leastsqnrm - INFO - linearfit not attempted, no covariances saved.
2026-04-15 20:16:56,009 - jwst.ami.nrm_core - INFO - Fitting fringes for iteration 42 of 61
2026-04-15 20:16:57,048 - jwst.ami.leastsqnrm - INFO - fringefitting.leastsqnrm.matrix_operations():
2026-04-15 20:16:57,048 - jwst.ami.leastsqnrm - INFO - img (69, 69)
2026-04-15 20:16:57,049 - jwst.ami.leastsqnrm - INFO - L x W = 69 x 69 = 4761
2026-04-15 20:16:57,049 - jwst.ami.leastsqnrm - INFO - flatimg (4761,)
2026-04-15 20:16:57,050 - jwst.ami.leastsqnrm - INFO -
2026-04-15 20:16:57,050 - jwst.ami.leastsqnrm - INFO - type(dqm) <class 'numpy.ndarray'>
2026-04-15 20:16:57,051 - jwst.ami.leastsqnrm - INFO - type(nanlist) <class 'tuple'>, len=1
2026-04-15 20:16:57,051 - jwst.ami.leastsqnrm - INFO - number of nanlist pixels: 38 items
2026-04-15 20:16:57,052 - jwst.ami.leastsqnrm - INFO - 38 DO_NOT_USE pixels found in data slice
2026-04-15 20:16:57,052 - jwst.ami.leastsqnrm - INFO - flatimg (4723,) after deleting 38
2026-04-15 20:16:57,053 - jwst.ami.leastsqnrm - INFO - flatmodel_nan (4761, 44)
2026-04-15 20:16:57,053 - jwst.ami.leastsqnrm - INFO - flatmodel (4723, 44)
2026-04-15 20:16:57,054 - jwst.ami.leastsqnrm - INFO - difference 38
2026-04-15 20:16:57,054 - jwst.ami.leastsqnrm - INFO - flat model dimensions (4723, 44)
2026-04-15 20:16:57,055 - jwst.ami.leastsqnrm - INFO - flat image dimensions (4723,)
2026-04-15 20:16:57,057 - jwst.ami.leastsqnrm - INFO - data flux 1.0307529e+06
2026-04-15 20:16:57,058 - jwst.ami.leastsqnrm - INFO - flat model dimensions (4723, 44)
2026-04-15 20:16:57,058 - jwst.ami.leastsqnrm - INFO - model transpose dimensions (44, 4723)
2026-04-15 20:16:57,058 - jwst.ami.leastsqnrm - INFO - flat image dimensions (4723,)
2026-04-15 20:16:57,059 - jwst.ami.leastsqnrm - INFO - transpose * image data dimensions (44,)
2026-04-15 20:16:57,059 - jwst.ami.leastsqnrm - INFO - flat img * transpose dimensions (44, 44)
2026-04-15 20:16:57,060 - jwst.ami.leastsqnrm - INFO - linearfit not attempted, no covariances saved.
2026-04-15 20:16:57,061 - jwst.ami.nrm_core - INFO - Fitting fringes for iteration 43 of 61
2026-04-15 20:16:58,099 - jwst.ami.leastsqnrm - INFO - fringefitting.leastsqnrm.matrix_operations():
2026-04-15 20:16:58,100 - jwst.ami.leastsqnrm - INFO - img (69, 69)
2026-04-15 20:16:58,100 - jwst.ami.leastsqnrm - INFO - L x W = 69 x 69 = 4761
2026-04-15 20:16:58,101 - jwst.ami.leastsqnrm - INFO - flatimg (4761,)
2026-04-15 20:16:58,101 - jwst.ami.leastsqnrm - INFO -
2026-04-15 20:16:58,102 - jwst.ami.leastsqnrm - INFO - type(dqm) <class 'numpy.ndarray'>
2026-04-15 20:16:58,102 - jwst.ami.leastsqnrm - INFO - type(nanlist) <class 'tuple'>, len=1
2026-04-15 20:16:58,102 - jwst.ami.leastsqnrm - INFO - number of nanlist pixels: 37 items
2026-04-15 20:16:58,103 - jwst.ami.leastsqnrm - INFO - 37 DO_NOT_USE pixels found in data slice
2026-04-15 20:16:58,103 - jwst.ami.leastsqnrm - INFO - flatimg (4724,) after deleting 37
2026-04-15 20:16:58,104 - jwst.ami.leastsqnrm - INFO - flatmodel_nan (4761, 44)
2026-04-15 20:16:58,105 - jwst.ami.leastsqnrm - INFO - flatmodel (4724, 44)
2026-04-15 20:16:58,105 - jwst.ami.leastsqnrm - INFO - difference 37
2026-04-15 20:16:58,106 - jwst.ami.leastsqnrm - INFO - flat model dimensions (4724, 44)
2026-04-15 20:16:58,106 - jwst.ami.leastsqnrm - INFO - flat image dimensions (4724,)
2026-04-15 20:16:58,108 - jwst.ami.leastsqnrm - INFO - data flux 1.03185806e+06
2026-04-15 20:16:58,109 - jwst.ami.leastsqnrm - INFO - flat model dimensions (4724, 44)
2026-04-15 20:16:58,109 - jwst.ami.leastsqnrm - INFO - model transpose dimensions (44, 4724)
2026-04-15 20:16:58,110 - jwst.ami.leastsqnrm - INFO - flat image dimensions (4724,)
2026-04-15 20:16:58,110 - jwst.ami.leastsqnrm - INFO - transpose * image data dimensions (44,)
2026-04-15 20:16:58,111 - jwst.ami.leastsqnrm - INFO - flat img * transpose dimensions (44, 44)
2026-04-15 20:16:58,111 - jwst.ami.leastsqnrm - INFO - linearfit not attempted, no covariances saved.
2026-04-15 20:16:58,112 - jwst.ami.nrm_core - INFO - Fitting fringes for iteration 44 of 61
2026-04-15 20:16:59,150 - jwst.ami.leastsqnrm - INFO - fringefitting.leastsqnrm.matrix_operations():
2026-04-15 20:16:59,151 - jwst.ami.leastsqnrm - INFO - img (69, 69)
2026-04-15 20:16:59,151 - jwst.ami.leastsqnrm - INFO - L x W = 69 x 69 = 4761
2026-04-15 20:16:59,151 - jwst.ami.leastsqnrm - INFO - flatimg (4761,)
2026-04-15 20:16:59,152 - jwst.ami.leastsqnrm - INFO -
2026-04-15 20:16:59,152 - jwst.ami.leastsqnrm - INFO - type(dqm) <class 'numpy.ndarray'>
2026-04-15 20:16:59,153 - jwst.ami.leastsqnrm - INFO - type(nanlist) <class 'tuple'>, len=1
2026-04-15 20:16:59,153 - jwst.ami.leastsqnrm - INFO - number of nanlist pixels: 42 items
2026-04-15 20:16:59,154 - jwst.ami.leastsqnrm - INFO - 42 DO_NOT_USE pixels found in data slice
2026-04-15 20:16:59,155 - jwst.ami.leastsqnrm - INFO - flatimg (4719,) after deleting 42
2026-04-15 20:16:59,155 - jwst.ami.leastsqnrm - INFO - flatmodel_nan (4761, 44)
2026-04-15 20:16:59,155 - jwst.ami.leastsqnrm - INFO - flatmodel (4719, 44)
2026-04-15 20:16:59,156 - jwst.ami.leastsqnrm - INFO - difference 42
2026-04-15 20:16:59,156 - jwst.ami.leastsqnrm - INFO - flat model dimensions (4719, 44)
2026-04-15 20:16:59,157 - jwst.ami.leastsqnrm - INFO - flat image dimensions (4719,)
2026-04-15 20:16:59,159 - jwst.ami.leastsqnrm - INFO - data flux 1.0332597e+06
2026-04-15 20:16:59,159 - jwst.ami.leastsqnrm - INFO - flat model dimensions (4719, 44)
2026-04-15 20:16:59,160 - jwst.ami.leastsqnrm - INFO - model transpose dimensions (44, 4719)
2026-04-15 20:16:59,160 - jwst.ami.leastsqnrm - INFO - flat image dimensions (4719,)
2026-04-15 20:16:59,161 - jwst.ami.leastsqnrm - INFO - transpose * image data dimensions (44,)
2026-04-15 20:16:59,161 - jwst.ami.leastsqnrm - INFO - flat img * transpose dimensions (44, 44)
2026-04-15 20:16:59,162 - jwst.ami.leastsqnrm - INFO - linearfit not attempted, no covariances saved.
2026-04-15 20:16:59,163 - jwst.ami.nrm_core - INFO - Fitting fringes for iteration 45 of 61
2026-04-15 20:17:00,211 - jwst.ami.leastsqnrm - INFO - fringefitting.leastsqnrm.matrix_operations():
2026-04-15 20:17:00,211 - jwst.ami.leastsqnrm - INFO - img (69, 69)
2026-04-15 20:17:00,212 - jwst.ami.leastsqnrm - INFO - L x W = 69 x 69 = 4761
2026-04-15 20:17:00,212 - jwst.ami.leastsqnrm - INFO - flatimg (4761,)
2026-04-15 20:17:00,213 - jwst.ami.leastsqnrm - INFO -
2026-04-15 20:17:00,213 - jwst.ami.leastsqnrm - INFO - type(dqm) <class 'numpy.ndarray'>
2026-04-15 20:17:00,213 - jwst.ami.leastsqnrm - INFO - type(nanlist) <class 'tuple'>, len=1
2026-04-15 20:17:00,214 - jwst.ami.leastsqnrm - INFO - number of nanlist pixels: 38 items
2026-04-15 20:17:00,214 - jwst.ami.leastsqnrm - INFO - 38 DO_NOT_USE pixels found in data slice
2026-04-15 20:17:00,215 - jwst.ami.leastsqnrm - INFO - flatimg (4723,) after deleting 38
2026-04-15 20:17:00,216 - jwst.ami.leastsqnrm - INFO - flatmodel_nan (4761, 44)
2026-04-15 20:17:00,216 - jwst.ami.leastsqnrm - INFO - flatmodel (4723, 44)
2026-04-15 20:17:00,216 - jwst.ami.leastsqnrm - INFO - difference 38
2026-04-15 20:17:00,217 - jwst.ami.leastsqnrm - INFO - flat model dimensions (4723, 44)
2026-04-15 20:17:00,217 - jwst.ami.leastsqnrm - INFO - flat image dimensions (4723,)
2026-04-15 20:17:00,220 - jwst.ami.leastsqnrm - INFO - data flux 1.0545385e+06
2026-04-15 20:17:00,220 - jwst.ami.leastsqnrm - INFO - flat model dimensions (4723, 44)
2026-04-15 20:17:00,220 - jwst.ami.leastsqnrm - INFO - model transpose dimensions (44, 4723)
2026-04-15 20:17:00,221 - jwst.ami.leastsqnrm - INFO - flat image dimensions (4723,)
2026-04-15 20:17:00,221 - jwst.ami.leastsqnrm - INFO - transpose * image data dimensions (44,)
2026-04-15 20:17:00,222 - jwst.ami.leastsqnrm - INFO - flat img * transpose dimensions (44, 44)
2026-04-15 20:17:00,222 - jwst.ami.leastsqnrm - INFO - linearfit not attempted, no covariances saved.
2026-04-15 20:17:00,224 - jwst.ami.nrm_core - INFO - Fitting fringes for iteration 46 of 61
2026-04-15 20:17:01,263 - jwst.ami.leastsqnrm - INFO - fringefitting.leastsqnrm.matrix_operations():
2026-04-15 20:17:01,263 - jwst.ami.leastsqnrm - INFO - img (69, 69)
2026-04-15 20:17:01,264 - jwst.ami.leastsqnrm - INFO - L x W = 69 x 69 = 4761
2026-04-15 20:17:01,264 - jwst.ami.leastsqnrm - INFO - flatimg (4761,)
2026-04-15 20:17:01,265 - jwst.ami.leastsqnrm - INFO -
2026-04-15 20:17:01,265 - jwst.ami.leastsqnrm - INFO - type(dqm) <class 'numpy.ndarray'>
2026-04-15 20:17:01,266 - jwst.ami.leastsqnrm - INFO - type(nanlist) <class 'tuple'>, len=1
2026-04-15 20:17:01,266 - jwst.ami.leastsqnrm - INFO - number of nanlist pixels: 36 items
2026-04-15 20:17:01,266 - jwst.ami.leastsqnrm - INFO - 36 DO_NOT_USE pixels found in data slice
2026-04-15 20:17:01,267 - jwst.ami.leastsqnrm - INFO - flatimg (4725,) after deleting 36
2026-04-15 20:17:01,268 - jwst.ami.leastsqnrm - INFO - flatmodel_nan (4761, 44)
2026-04-15 20:17:01,268 - jwst.ami.leastsqnrm - INFO - flatmodel (4725, 44)
2026-04-15 20:17:01,269 - jwst.ami.leastsqnrm - INFO - difference 36
2026-04-15 20:17:01,269 - jwst.ami.leastsqnrm - INFO - flat model dimensions (4725, 44)
2026-04-15 20:17:01,269 - jwst.ami.leastsqnrm - INFO - flat image dimensions (4725,)
2026-04-15 20:17:01,272 - jwst.ami.leastsqnrm - INFO - data flux 1.04166075e+06
2026-04-15 20:17:01,272 - jwst.ami.leastsqnrm - INFO - flat model dimensions (4725, 44)
2026-04-15 20:17:01,273 - jwst.ami.leastsqnrm - INFO - model transpose dimensions (44, 4725)
2026-04-15 20:17:01,273 - jwst.ami.leastsqnrm - INFO - flat image dimensions (4725,)
2026-04-15 20:17:01,274 - jwst.ami.leastsqnrm - INFO - transpose * image data dimensions (44,)
2026-04-15 20:17:01,274 - jwst.ami.leastsqnrm - INFO - flat img * transpose dimensions (44, 44)
2026-04-15 20:17:01,274 - jwst.ami.leastsqnrm - INFO - linearfit not attempted, no covariances saved.
2026-04-15 20:17:01,276 - jwst.ami.nrm_core - INFO - Fitting fringes for iteration 47 of 61
2026-04-15 20:17:02,313 - jwst.ami.leastsqnrm - INFO - fringefitting.leastsqnrm.matrix_operations():
2026-04-15 20:17:02,314 - jwst.ami.leastsqnrm - INFO - img (69, 69)
2026-04-15 20:17:02,315 - jwst.ami.leastsqnrm - INFO - L x W = 69 x 69 = 4761
2026-04-15 20:17:02,315 - jwst.ami.leastsqnrm - INFO - flatimg (4761,)
2026-04-15 20:17:02,315 - jwst.ami.leastsqnrm - INFO -
2026-04-15 20:17:02,316 - jwst.ami.leastsqnrm - INFO - type(dqm) <class 'numpy.ndarray'>
2026-04-15 20:17:02,316 - jwst.ami.leastsqnrm - INFO - type(nanlist) <class 'tuple'>, len=1
2026-04-15 20:17:02,317 - jwst.ami.leastsqnrm - INFO - number of nanlist pixels: 41 items
2026-04-15 20:17:02,317 - jwst.ami.leastsqnrm - INFO - 41 DO_NOT_USE pixels found in data slice
2026-04-15 20:17:02,318 - jwst.ami.leastsqnrm - INFO - flatimg (4720,) after deleting 41
2026-04-15 20:17:02,319 - jwst.ami.leastsqnrm - INFO - flatmodel_nan (4761, 44)
2026-04-15 20:17:02,319 - jwst.ami.leastsqnrm - INFO - flatmodel (4720, 44)
2026-04-15 20:17:02,320 - jwst.ami.leastsqnrm - INFO - difference 41
2026-04-15 20:17:02,320 - jwst.ami.leastsqnrm - INFO - flat model dimensions (4720, 44)
2026-04-15 20:17:02,321 - jwst.ami.leastsqnrm - INFO - flat image dimensions (4720,)
2026-04-15 20:17:02,323 - jwst.ami.leastsqnrm - INFO - data flux 1.0218811e+06
2026-04-15 20:17:02,323 - jwst.ami.leastsqnrm - INFO - flat model dimensions (4720, 44)
2026-04-15 20:17:02,324 - jwst.ami.leastsqnrm - INFO - model transpose dimensions (44, 4720)
2026-04-15 20:17:02,324 - jwst.ami.leastsqnrm - INFO - flat image dimensions (4720,)
2026-04-15 20:17:02,325 - jwst.ami.leastsqnrm - INFO - transpose * image data dimensions (44,)
2026-04-15 20:17:02,325 - jwst.ami.leastsqnrm - INFO - flat img * transpose dimensions (44, 44)
2026-04-15 20:17:02,325 - jwst.ami.leastsqnrm - INFO - linearfit not attempted, no covariances saved.
2026-04-15 20:17:02,327 - jwst.ami.nrm_core - INFO - Fitting fringes for iteration 48 of 61
2026-04-15 20:17:03,365 - jwst.ami.leastsqnrm - INFO - fringefitting.leastsqnrm.matrix_operations():
2026-04-15 20:17:03,366 - jwst.ami.leastsqnrm - INFO - img (69, 69)
2026-04-15 20:17:03,366 - jwst.ami.leastsqnrm - INFO - L x W = 69 x 69 = 4761
2026-04-15 20:17:03,367 - jwst.ami.leastsqnrm - INFO - flatimg (4761,)
2026-04-15 20:17:03,367 - jwst.ami.leastsqnrm - INFO -
2026-04-15 20:17:03,368 - jwst.ami.leastsqnrm - INFO - type(dqm) <class 'numpy.ndarray'>
2026-04-15 20:17:03,368 - jwst.ami.leastsqnrm - INFO - type(nanlist) <class 'tuple'>, len=1
2026-04-15 20:17:03,369 - jwst.ami.leastsqnrm - INFO - number of nanlist pixels: 38 items
2026-04-15 20:17:03,369 - jwst.ami.leastsqnrm - INFO - 38 DO_NOT_USE pixels found in data slice
2026-04-15 20:17:03,369 - jwst.ami.leastsqnrm - INFO - flatimg (4723,) after deleting 38
2026-04-15 20:17:03,370 - jwst.ami.leastsqnrm - INFO - flatmodel_nan (4761, 44)
2026-04-15 20:17:03,371 - jwst.ami.leastsqnrm - INFO - flatmodel (4723, 44)
2026-04-15 20:17:03,371 - jwst.ami.leastsqnrm - INFO - difference 38
2026-04-15 20:17:03,371 - jwst.ami.leastsqnrm - INFO - flat model dimensions (4723, 44)
2026-04-15 20:17:03,372 - jwst.ami.leastsqnrm - INFO - flat image dimensions (4723,)
2026-04-15 20:17:03,374 - jwst.ami.leastsqnrm - INFO - data flux 1.0324946e+06
2026-04-15 20:17:03,375 - jwst.ami.leastsqnrm - INFO - flat model dimensions (4723, 44)
2026-04-15 20:17:03,375 - jwst.ami.leastsqnrm - INFO - model transpose dimensions (44, 4723)
2026-04-15 20:17:03,375 - jwst.ami.leastsqnrm - INFO - flat image dimensions (4723,)
2026-04-15 20:17:03,376 - jwst.ami.leastsqnrm - INFO - transpose * image data dimensions (44,)
2026-04-15 20:17:03,376 - jwst.ami.leastsqnrm - INFO - flat img * transpose dimensions (44, 44)
2026-04-15 20:17:03,377 - jwst.ami.leastsqnrm - INFO - linearfit not attempted, no covariances saved.
2026-04-15 20:17:03,378 - jwst.ami.nrm_core - INFO - Fitting fringes for iteration 49 of 61
2026-04-15 20:17:04,416 - jwst.ami.leastsqnrm - INFO - fringefitting.leastsqnrm.matrix_operations():
2026-04-15 20:17:04,417 - jwst.ami.leastsqnrm - INFO - img (69, 69)
2026-04-15 20:17:04,417 - jwst.ami.leastsqnrm - INFO - L x W = 69 x 69 = 4761
2026-04-15 20:17:04,418 - jwst.ami.leastsqnrm - INFO - flatimg (4761,)
2026-04-15 20:17:04,418 - jwst.ami.leastsqnrm - INFO -
2026-04-15 20:17:04,419 - jwst.ami.leastsqnrm - INFO - type(dqm) <class 'numpy.ndarray'>
2026-04-15 20:17:04,419 - jwst.ami.leastsqnrm - INFO - type(nanlist) <class 'tuple'>, len=1
2026-04-15 20:17:04,419 - jwst.ami.leastsqnrm - INFO - number of nanlist pixels: 39 items
2026-04-15 20:17:04,420 - jwst.ami.leastsqnrm - INFO - 39 DO_NOT_USE pixels found in data slice
2026-04-15 20:17:04,420 - jwst.ami.leastsqnrm - INFO - flatimg (4722,) after deleting 39
2026-04-15 20:17:04,421 - jwst.ami.leastsqnrm - INFO - flatmodel_nan (4761, 44)
2026-04-15 20:17:04,422 - jwst.ami.leastsqnrm - INFO - flatmodel (4722, 44)
2026-04-15 20:17:04,422 - jwst.ami.leastsqnrm - INFO - difference 39
2026-04-15 20:17:04,423 - jwst.ami.leastsqnrm - INFO - flat model dimensions (4722, 44)
2026-04-15 20:17:04,423 - jwst.ami.leastsqnrm - INFO - flat image dimensions (4722,)
2026-04-15 20:17:04,425 - jwst.ami.leastsqnrm - INFO - data flux 1.0519578e+06
2026-04-15 20:17:04,426 - jwst.ami.leastsqnrm - INFO - flat model dimensions (4722, 44)
2026-04-15 20:17:04,426 - jwst.ami.leastsqnrm - INFO - model transpose dimensions (44, 4722)
2026-04-15 20:17:04,427 - jwst.ami.leastsqnrm - INFO - flat image dimensions (4722,)
2026-04-15 20:17:04,427 - jwst.ami.leastsqnrm - INFO - transpose * image data dimensions (44,)
2026-04-15 20:17:04,427 - jwst.ami.leastsqnrm - INFO - flat img * transpose dimensions (44, 44)
2026-04-15 20:17:04,428 - jwst.ami.leastsqnrm - INFO - linearfit not attempted, no covariances saved.
2026-04-15 20:17:04,430 - jwst.ami.nrm_core - INFO - Fitting fringes for iteration 50 of 61
2026-04-15 20:17:05,476 - jwst.ami.leastsqnrm - INFO - fringefitting.leastsqnrm.matrix_operations():
2026-04-15 20:17:05,477 - jwst.ami.leastsqnrm - INFO - img (69, 69)
2026-04-15 20:17:05,477 - jwst.ami.leastsqnrm - INFO - L x W = 69 x 69 = 4761
2026-04-15 20:17:05,477 - jwst.ami.leastsqnrm - INFO - flatimg (4761,)
2026-04-15 20:17:05,478 - jwst.ami.leastsqnrm - INFO -
2026-04-15 20:17:05,478 - jwst.ami.leastsqnrm - INFO - type(dqm) <class 'numpy.ndarray'>
2026-04-15 20:17:05,479 - jwst.ami.leastsqnrm - INFO - type(nanlist) <class 'tuple'>, len=1
2026-04-15 20:17:05,479 - jwst.ami.leastsqnrm - INFO - number of nanlist pixels: 36 items
2026-04-15 20:17:05,480 - jwst.ami.leastsqnrm - INFO - 36 DO_NOT_USE pixels found in data slice
2026-04-15 20:17:05,480 - jwst.ami.leastsqnrm - INFO - flatimg (4725,) after deleting 36
2026-04-15 20:17:05,481 - jwst.ami.leastsqnrm - INFO - flatmodel_nan (4761, 44)
2026-04-15 20:17:05,481 - jwst.ami.leastsqnrm - INFO - flatmodel (4725, 44)
2026-04-15 20:17:05,481 - jwst.ami.leastsqnrm - INFO - difference 36
2026-04-15 20:17:05,482 - jwst.ami.leastsqnrm - INFO - flat model dimensions (4725, 44)
2026-04-15 20:17:05,482 - jwst.ami.leastsqnrm - INFO - flat image dimensions (4725,)
2026-04-15 20:17:05,485 - jwst.ami.leastsqnrm - INFO - data flux 1.0338516e+06
2026-04-15 20:17:05,486 - jwst.ami.leastsqnrm - INFO - flat model dimensions (4725, 44)
2026-04-15 20:17:05,486 - jwst.ami.leastsqnrm - INFO - model transpose dimensions (44, 4725)
2026-04-15 20:17:05,487 - jwst.ami.leastsqnrm - INFO - flat image dimensions (4725,)
2026-04-15 20:17:05,487 - jwst.ami.leastsqnrm - INFO - transpose * image data dimensions (44,)
2026-04-15 20:17:05,488 - jwst.ami.leastsqnrm - INFO - flat img * transpose dimensions (44, 44)
2026-04-15 20:17:05,488 - jwst.ami.leastsqnrm - INFO - linearfit not attempted, no covariances saved.
2026-04-15 20:17:05,489 - jwst.ami.nrm_core - INFO - Fitting fringes for iteration 51 of 61
2026-04-15 20:17:06,528 - jwst.ami.leastsqnrm - INFO - fringefitting.leastsqnrm.matrix_operations():
2026-04-15 20:17:06,529 - jwst.ami.leastsqnrm - INFO - img (69, 69)
2026-04-15 20:17:06,529 - jwst.ami.leastsqnrm - INFO - L x W = 69 x 69 = 4761
2026-04-15 20:17:06,530 - jwst.ami.leastsqnrm - INFO - flatimg (4761,)
2026-04-15 20:17:06,530 - jwst.ami.leastsqnrm - INFO -
2026-04-15 20:17:06,531 - jwst.ami.leastsqnrm - INFO - type(dqm) <class 'numpy.ndarray'>
2026-04-15 20:17:06,531 - jwst.ami.leastsqnrm - INFO - type(nanlist) <class 'tuple'>, len=1
2026-04-15 20:17:06,531 - jwst.ami.leastsqnrm - INFO - number of nanlist pixels: 36 items
2026-04-15 20:17:06,532 - jwst.ami.leastsqnrm - INFO - 36 DO_NOT_USE pixels found in data slice
2026-04-15 20:17:06,532 - jwst.ami.leastsqnrm - INFO - flatimg (4725,) after deleting 36
2026-04-15 20:17:06,533 - jwst.ami.leastsqnrm - INFO - flatmodel_nan (4761, 44)
2026-04-15 20:17:06,534 - jwst.ami.leastsqnrm - INFO - flatmodel (4725, 44)
2026-04-15 20:17:06,534 - jwst.ami.leastsqnrm - INFO - difference 36
2026-04-15 20:17:06,534 - jwst.ami.leastsqnrm - INFO - flat model dimensions (4725, 44)
2026-04-15 20:17:06,535 - jwst.ami.leastsqnrm - INFO - flat image dimensions (4725,)
2026-04-15 20:17:06,537 - jwst.ami.leastsqnrm - INFO - data flux 1.0293141e+06
2026-04-15 20:17:06,537 - jwst.ami.leastsqnrm - INFO - flat model dimensions (4725, 44)
2026-04-15 20:17:06,538 - jwst.ami.leastsqnrm - INFO - model transpose dimensions (44, 4725)
2026-04-15 20:17:06,538 - jwst.ami.leastsqnrm - INFO - flat image dimensions (4725,)
2026-04-15 20:17:06,539 - jwst.ami.leastsqnrm - INFO - transpose * image data dimensions (44,)
2026-04-15 20:17:06,539 - jwst.ami.leastsqnrm - INFO - flat img * transpose dimensions (44, 44)
2026-04-15 20:17:06,540 - jwst.ami.leastsqnrm - INFO - linearfit not attempted, no covariances saved.
2026-04-15 20:17:06,541 - jwst.ami.nrm_core - INFO - Fitting fringes for iteration 52 of 61
2026-04-15 20:17:07,580 - jwst.ami.leastsqnrm - INFO - fringefitting.leastsqnrm.matrix_operations():
2026-04-15 20:17:07,581 - jwst.ami.leastsqnrm - INFO - img (69, 69)
2026-04-15 20:17:07,581 - jwst.ami.leastsqnrm - INFO - L x W = 69 x 69 = 4761
2026-04-15 20:17:07,582 - jwst.ami.leastsqnrm - INFO - flatimg (4761,)
2026-04-15 20:17:07,582 - jwst.ami.leastsqnrm - INFO -
2026-04-15 20:17:07,582 - jwst.ami.leastsqnrm - INFO - type(dqm) <class 'numpy.ndarray'>
2026-04-15 20:17:07,583 - jwst.ami.leastsqnrm - INFO - type(nanlist) <class 'tuple'>, len=1
2026-04-15 20:17:07,583 - jwst.ami.leastsqnrm - INFO - number of nanlist pixels: 39 items
2026-04-15 20:17:07,584 - jwst.ami.leastsqnrm - INFO - 39 DO_NOT_USE pixels found in data slice
2026-04-15 20:17:07,584 - jwst.ami.leastsqnrm - INFO - flatimg (4722,) after deleting 39
2026-04-15 20:17:07,585 - jwst.ami.leastsqnrm - INFO - flatmodel_nan (4761, 44)
2026-04-15 20:17:07,585 - jwst.ami.leastsqnrm - INFO - flatmodel (4722, 44)
2026-04-15 20:17:07,586 - jwst.ami.leastsqnrm - INFO - difference 39
2026-04-15 20:17:07,586 - jwst.ami.leastsqnrm - INFO - flat model dimensions (4722, 44)
2026-04-15 20:17:07,587 - jwst.ami.leastsqnrm - INFO - flat image dimensions (4722,)
2026-04-15 20:17:07,589 - jwst.ami.leastsqnrm - INFO - data flux 1.02933775e+06
2026-04-15 20:17:07,590 - jwst.ami.leastsqnrm - INFO - flat model dimensions (4722, 44)
2026-04-15 20:17:07,590 - jwst.ami.leastsqnrm - INFO - model transpose dimensions (44, 4722)
2026-04-15 20:17:07,591 - jwst.ami.leastsqnrm - INFO - flat image dimensions (4722,)
2026-04-15 20:17:07,591 - jwst.ami.leastsqnrm - INFO - transpose * image data dimensions (44,)
2026-04-15 20:17:07,591 - jwst.ami.leastsqnrm - INFO - flat img * transpose dimensions (44, 44)
2026-04-15 20:17:07,592 - jwst.ami.leastsqnrm - INFO - linearfit not attempted, no covariances saved.
2026-04-15 20:17:07,593 - jwst.ami.nrm_core - INFO - Fitting fringes for iteration 53 of 61
2026-04-15 20:17:08,633 - jwst.ami.leastsqnrm - INFO - fringefitting.leastsqnrm.matrix_operations():
2026-04-15 20:17:08,633 - jwst.ami.leastsqnrm - INFO - img (69, 69)
2026-04-15 20:17:08,634 - jwst.ami.leastsqnrm - INFO - L x W = 69 x 69 = 4761
2026-04-15 20:17:08,634 - jwst.ami.leastsqnrm - INFO - flatimg (4761,)
2026-04-15 20:17:08,635 - jwst.ami.leastsqnrm - INFO -
2026-04-15 20:17:08,635 - jwst.ami.leastsqnrm - INFO - type(dqm) <class 'numpy.ndarray'>
2026-04-15 20:17:08,636 - jwst.ami.leastsqnrm - INFO - type(nanlist) <class 'tuple'>, len=1
2026-04-15 20:17:08,636 - jwst.ami.leastsqnrm - INFO - number of nanlist pixels: 42 items
2026-04-15 20:17:08,636 - jwst.ami.leastsqnrm - INFO - 42 DO_NOT_USE pixels found in data slice
2026-04-15 20:17:08,637 - jwst.ami.leastsqnrm - INFO - flatimg (4719,) after deleting 42
2026-04-15 20:17:08,637 - jwst.ami.leastsqnrm - INFO - flatmodel_nan (4761, 44)
2026-04-15 20:17:08,638 - jwst.ami.leastsqnrm - INFO - flatmodel (4719, 44)
2026-04-15 20:17:08,638 - jwst.ami.leastsqnrm - INFO - difference 42
2026-04-15 20:17:08,639 - jwst.ami.leastsqnrm - INFO - flat model dimensions (4719, 44)
2026-04-15 20:17:08,640 - jwst.ami.leastsqnrm - INFO - flat image dimensions (4719,)
2026-04-15 20:17:08,642 - jwst.ami.leastsqnrm - INFO - data flux 1.0244375e+06
2026-04-15 20:17:08,642 - jwst.ami.leastsqnrm - INFO - flat model dimensions (4719, 44)
2026-04-15 20:17:08,643 - jwst.ami.leastsqnrm - INFO - model transpose dimensions (44, 4719)
2026-04-15 20:17:08,643 - jwst.ami.leastsqnrm - INFO - flat image dimensions (4719,)
2026-04-15 20:17:08,643 - jwst.ami.leastsqnrm - INFO - transpose * image data dimensions (44,)
2026-04-15 20:17:08,644 - jwst.ami.leastsqnrm - INFO - flat img * transpose dimensions (44, 44)
2026-04-15 20:17:08,644 - jwst.ami.leastsqnrm - INFO - linearfit not attempted, no covariances saved.
2026-04-15 20:17:08,646 - jwst.ami.nrm_core - INFO - Fitting fringes for iteration 54 of 61
2026-04-15 20:17:09,684 - jwst.ami.leastsqnrm - INFO - fringefitting.leastsqnrm.matrix_operations():
2026-04-15 20:17:09,685 - jwst.ami.leastsqnrm - INFO - img (69, 69)
2026-04-15 20:17:09,685 - jwst.ami.leastsqnrm - INFO - L x W = 69 x 69 = 4761
2026-04-15 20:17:09,686 - jwst.ami.leastsqnrm - INFO - flatimg (4761,)
2026-04-15 20:17:09,686 - jwst.ami.leastsqnrm - INFO -
2026-04-15 20:17:09,686 - jwst.ami.leastsqnrm - INFO - type(dqm) <class 'numpy.ndarray'>
2026-04-15 20:17:09,687 - jwst.ami.leastsqnrm - INFO - type(nanlist) <class 'tuple'>, len=1
2026-04-15 20:17:09,687 - jwst.ami.leastsqnrm - INFO - number of nanlist pixels: 38 items
2026-04-15 20:17:09,688 - jwst.ami.leastsqnrm - INFO - 38 DO_NOT_USE pixels found in data slice
2026-04-15 20:17:09,688 - jwst.ami.leastsqnrm - INFO - flatimg (4723,) after deleting 38
2026-04-15 20:17:09,689 - jwst.ami.leastsqnrm - INFO - flatmodel_nan (4761, 44)
2026-04-15 20:17:09,690 - jwst.ami.leastsqnrm - INFO - flatmodel (4723, 44)
2026-04-15 20:17:09,690 - jwst.ami.leastsqnrm - INFO - difference 38
2026-04-15 20:17:09,691 - jwst.ami.leastsqnrm - INFO - flat model dimensions (4723, 44)
2026-04-15 20:17:09,691 - jwst.ami.leastsqnrm - INFO - flat image dimensions (4723,)
2026-04-15 20:17:09,693 - jwst.ami.leastsqnrm - INFO - data flux 1.0363159e+06
2026-04-15 20:17:09,694 - jwst.ami.leastsqnrm - INFO - flat model dimensions (4723, 44)
2026-04-15 20:17:09,694 - jwst.ami.leastsqnrm - INFO - model transpose dimensions (44, 4723)
2026-04-15 20:17:09,695 - jwst.ami.leastsqnrm - INFO - flat image dimensions (4723,)
2026-04-15 20:17:09,695 - jwst.ami.leastsqnrm - INFO - transpose * image data dimensions (44,)
2026-04-15 20:17:09,695 - jwst.ami.leastsqnrm - INFO - flat img * transpose dimensions (44, 44)
2026-04-15 20:17:09,696 - jwst.ami.leastsqnrm - INFO - linearfit not attempted, no covariances saved.
2026-04-15 20:17:09,697 - jwst.ami.nrm_core - INFO - Fitting fringes for iteration 55 of 61
2026-04-15 20:17:10,746 - jwst.ami.leastsqnrm - INFO - fringefitting.leastsqnrm.matrix_operations():
2026-04-15 20:17:10,747 - jwst.ami.leastsqnrm - INFO - img (69, 69)
2026-04-15 20:17:10,747 - jwst.ami.leastsqnrm - INFO - L x W = 69 x 69 = 4761
2026-04-15 20:17:10,747 - jwst.ami.leastsqnrm - INFO - flatimg (4761,)
2026-04-15 20:17:10,748 - jwst.ami.leastsqnrm - INFO -
2026-04-15 20:17:10,748 - jwst.ami.leastsqnrm - INFO - type(dqm) <class 'numpy.ndarray'>
2026-04-15 20:17:10,749 - jwst.ami.leastsqnrm - INFO - type(nanlist) <class 'tuple'>, len=1
2026-04-15 20:17:10,749 - jwst.ami.leastsqnrm - INFO - number of nanlist pixels: 39 items
2026-04-15 20:17:10,750 - jwst.ami.leastsqnrm - INFO - 39 DO_NOT_USE pixels found in data slice
2026-04-15 20:17:10,750 - jwst.ami.leastsqnrm - INFO - flatimg (4722,) after deleting 39
2026-04-15 20:17:10,751 - jwst.ami.leastsqnrm - INFO - flatmodel_nan (4761, 44)
2026-04-15 20:17:10,751 - jwst.ami.leastsqnrm - INFO - flatmodel (4722, 44)
2026-04-15 20:17:10,752 - jwst.ami.leastsqnrm - INFO - difference 39
2026-04-15 20:17:10,752 - jwst.ami.leastsqnrm - INFO - flat model dimensions (4722, 44)
2026-04-15 20:17:10,752 - jwst.ami.leastsqnrm - INFO - flat image dimensions (4722,)
2026-04-15 20:17:10,755 - jwst.ami.leastsqnrm - INFO - data flux 1.0373521e+06
2026-04-15 20:17:10,756 - jwst.ami.leastsqnrm - INFO - flat model dimensions (4722, 44)
2026-04-15 20:17:10,756 - jwst.ami.leastsqnrm - INFO - model transpose dimensions (44, 4722)
2026-04-15 20:17:10,756 - jwst.ami.leastsqnrm - INFO - flat image dimensions (4722,)
2026-04-15 20:17:10,757 - jwst.ami.leastsqnrm - INFO - transpose * image data dimensions (44,)
2026-04-15 20:17:10,757 - jwst.ami.leastsqnrm - INFO - flat img * transpose dimensions (44, 44)
2026-04-15 20:17:10,758 - jwst.ami.leastsqnrm - INFO - linearfit not attempted, no covariances saved.
2026-04-15 20:17:10,759 - jwst.ami.nrm_core - INFO - Fitting fringes for iteration 56 of 61
2026-04-15 20:17:11,800 - jwst.ami.leastsqnrm - INFO - fringefitting.leastsqnrm.matrix_operations():
2026-04-15 20:17:11,801 - jwst.ami.leastsqnrm - INFO - img (69, 69)
2026-04-15 20:17:11,801 - jwst.ami.leastsqnrm - INFO - L x W = 69 x 69 = 4761
2026-04-15 20:17:11,802 - jwst.ami.leastsqnrm - INFO - flatimg (4761,)
2026-04-15 20:17:11,802 - jwst.ami.leastsqnrm - INFO -
2026-04-15 20:17:11,803 - jwst.ami.leastsqnrm - INFO - type(dqm) <class 'numpy.ndarray'>
2026-04-15 20:17:11,803 - jwst.ami.leastsqnrm - INFO - type(nanlist) <class 'tuple'>, len=1
2026-04-15 20:17:11,804 - jwst.ami.leastsqnrm - INFO - number of nanlist pixels: 44 items
2026-04-15 20:17:11,804 - jwst.ami.leastsqnrm - INFO - 44 DO_NOT_USE pixels found in data slice
2026-04-15 20:17:11,805 - jwst.ami.leastsqnrm - INFO - flatimg (4717,) after deleting 44
2026-04-15 20:17:11,805 - jwst.ami.leastsqnrm - INFO - flatmodel_nan (4761, 44)
2026-04-15 20:17:11,806 - jwst.ami.leastsqnrm - INFO - flatmodel (4717, 44)
2026-04-15 20:17:11,806 - jwst.ami.leastsqnrm - INFO - difference 44
2026-04-15 20:17:11,807 - jwst.ami.leastsqnrm - INFO - flat model dimensions (4717, 44)
2026-04-15 20:17:11,807 - jwst.ami.leastsqnrm - INFO - flat image dimensions (4717,)
2026-04-15 20:17:11,809 - jwst.ami.leastsqnrm - INFO - data flux 1.02981275e+06
2026-04-15 20:17:11,810 - jwst.ami.leastsqnrm - INFO - flat model dimensions (4717, 44)
2026-04-15 20:17:11,810 - jwst.ami.leastsqnrm - INFO - model transpose dimensions (44, 4717)
2026-04-15 20:17:11,811 - jwst.ami.leastsqnrm - INFO - flat image dimensions (4717,)
2026-04-15 20:17:11,811 - jwst.ami.leastsqnrm - INFO - transpose * image data dimensions (44,)
2026-04-15 20:17:11,812 - jwst.ami.leastsqnrm - INFO - flat img * transpose dimensions (44, 44)
2026-04-15 20:17:11,812 - jwst.ami.leastsqnrm - INFO - linearfit not attempted, no covariances saved.
2026-04-15 20:17:11,813 - jwst.ami.nrm_core - INFO - Fitting fringes for iteration 57 of 61
2026-04-15 20:17:12,853 - jwst.ami.leastsqnrm - INFO - fringefitting.leastsqnrm.matrix_operations():
2026-04-15 20:17:12,853 - jwst.ami.leastsqnrm - INFO - img (69, 69)
2026-04-15 20:17:12,854 - jwst.ami.leastsqnrm - INFO - L x W = 69 x 69 = 4761
2026-04-15 20:17:12,855 - jwst.ami.leastsqnrm - INFO - flatimg (4761,)
2026-04-15 20:17:12,855 - jwst.ami.leastsqnrm - INFO -
2026-04-15 20:17:12,855 - jwst.ami.leastsqnrm - INFO - type(dqm) <class 'numpy.ndarray'>
2026-04-15 20:17:12,856 - jwst.ami.leastsqnrm - INFO - type(nanlist) <class 'tuple'>, len=1
2026-04-15 20:17:12,856 - jwst.ami.leastsqnrm - INFO - number of nanlist pixels: 39 items
2026-04-15 20:17:12,857 - jwst.ami.leastsqnrm - INFO - 39 DO_NOT_USE pixels found in data slice
2026-04-15 20:17:12,857 - jwst.ami.leastsqnrm - INFO - flatimg (4722,) after deleting 39
2026-04-15 20:17:12,858 - jwst.ami.leastsqnrm - INFO - flatmodel_nan (4761, 44)
2026-04-15 20:17:12,858 - jwst.ami.leastsqnrm - INFO - flatmodel (4722, 44)
2026-04-15 20:17:12,859 - jwst.ami.leastsqnrm - INFO - difference 39
2026-04-15 20:17:12,859 - jwst.ami.leastsqnrm - INFO - flat model dimensions (4722, 44)
2026-04-15 20:17:12,860 - jwst.ami.leastsqnrm - INFO - flat image dimensions (4722,)
2026-04-15 20:17:12,862 - jwst.ami.leastsqnrm - INFO - data flux 1.0505064e+06
2026-04-15 20:17:12,862 - jwst.ami.leastsqnrm - INFO - flat model dimensions (4722, 44)
2026-04-15 20:17:12,863 - jwst.ami.leastsqnrm - INFO - model transpose dimensions (44, 4722)
2026-04-15 20:17:12,863 - jwst.ami.leastsqnrm - INFO - flat image dimensions (4722,)
2026-04-15 20:17:12,864 - jwst.ami.leastsqnrm - INFO - transpose * image data dimensions (44,)
2026-04-15 20:17:12,864 - jwst.ami.leastsqnrm - INFO - flat img * transpose dimensions (44, 44)
2026-04-15 20:17:12,865 - jwst.ami.leastsqnrm - INFO - linearfit not attempted, no covariances saved.
2026-04-15 20:17:12,866 - jwst.ami.nrm_core - INFO - Fitting fringes for iteration 58 of 61
2026-04-15 20:17:13,912 - jwst.ami.leastsqnrm - INFO - fringefitting.leastsqnrm.matrix_operations():
2026-04-15 20:17:13,913 - jwst.ami.leastsqnrm - INFO - img (69, 69)
2026-04-15 20:17:13,913 - jwst.ami.leastsqnrm - INFO - L x W = 69 x 69 = 4761
2026-04-15 20:17:13,914 - jwst.ami.leastsqnrm - INFO - flatimg (4761,)
2026-04-15 20:17:13,914 - jwst.ami.leastsqnrm - INFO -
2026-04-15 20:17:13,915 - jwst.ami.leastsqnrm - INFO - type(dqm) <class 'numpy.ndarray'>
2026-04-15 20:17:13,915 - jwst.ami.leastsqnrm - INFO - type(nanlist) <class 'tuple'>, len=1
2026-04-15 20:17:13,915 - jwst.ami.leastsqnrm - INFO - number of nanlist pixels: 40 items
2026-04-15 20:17:13,916 - jwst.ami.leastsqnrm - INFO - 40 DO_NOT_USE pixels found in data slice
2026-04-15 20:17:13,916 - jwst.ami.leastsqnrm - INFO - flatimg (4721,) after deleting 40
2026-04-15 20:17:13,917 - jwst.ami.leastsqnrm - INFO - flatmodel_nan (4761, 44)
2026-04-15 20:17:13,918 - jwst.ami.leastsqnrm - INFO - flatmodel (4721, 44)
2026-04-15 20:17:13,918 - jwst.ami.leastsqnrm - INFO - difference 40
2026-04-15 20:17:13,919 - jwst.ami.leastsqnrm - INFO - flat model dimensions (4721, 44)
2026-04-15 20:17:13,919 - jwst.ami.leastsqnrm - INFO - flat image dimensions (4721,)
2026-04-15 20:17:13,921 - jwst.ami.leastsqnrm - INFO - data flux 1.0292666e+06
2026-04-15 20:17:13,922 - jwst.ami.leastsqnrm - INFO - flat model dimensions (4721, 44)
2026-04-15 20:17:13,922 - jwst.ami.leastsqnrm - INFO - model transpose dimensions (44, 4721)
2026-04-15 20:17:13,922 - jwst.ami.leastsqnrm - INFO - flat image dimensions (4721,)
2026-04-15 20:17:13,923 - jwst.ami.leastsqnrm - INFO - transpose * image data dimensions (44,)
2026-04-15 20:17:13,923 - jwst.ami.leastsqnrm - INFO - flat img * transpose dimensions (44, 44)
2026-04-15 20:17:13,924 - jwst.ami.leastsqnrm - INFO - linearfit not attempted, no covariances saved.
2026-04-15 20:17:13,925 - jwst.ami.nrm_core - INFO - Fitting fringes for iteration 59 of 61
2026-04-15 20:17:14,965 - jwst.ami.leastsqnrm - INFO - fringefitting.leastsqnrm.matrix_operations():
2026-04-15 20:17:14,966 - jwst.ami.leastsqnrm - INFO - img (69, 69)
2026-04-15 20:17:14,966 - jwst.ami.leastsqnrm - INFO - L x W = 69 x 69 = 4761
2026-04-15 20:17:14,966 - jwst.ami.leastsqnrm - INFO - flatimg (4761,)
2026-04-15 20:17:14,967 - jwst.ami.leastsqnrm - INFO -
2026-04-15 20:17:14,967 - jwst.ami.leastsqnrm - INFO - type(dqm) <class 'numpy.ndarray'>
2026-04-15 20:17:14,968 - jwst.ami.leastsqnrm - INFO - type(nanlist) <class 'tuple'>, len=1
2026-04-15 20:17:14,968 - jwst.ami.leastsqnrm - INFO - number of nanlist pixels: 38 items
2026-04-15 20:17:14,969 - jwst.ami.leastsqnrm - INFO - 38 DO_NOT_USE pixels found in data slice
2026-04-15 20:17:14,969 - jwst.ami.leastsqnrm - INFO - flatimg (4723,) after deleting 38
2026-04-15 20:17:14,970 - jwst.ami.leastsqnrm - INFO - flatmodel_nan (4761, 44)
2026-04-15 20:17:14,970 - jwst.ami.leastsqnrm - INFO - flatmodel (4723, 44)
2026-04-15 20:17:14,971 - jwst.ami.leastsqnrm - INFO - difference 38
2026-04-15 20:17:14,971 - jwst.ami.leastsqnrm - INFO - flat model dimensions (4723, 44)
2026-04-15 20:17:14,972 - jwst.ami.leastsqnrm - INFO - flat image dimensions (4723,)
2026-04-15 20:17:14,974 - jwst.ami.leastsqnrm - INFO - data flux 1.0451156e+06
2026-04-15 20:17:14,974 - jwst.ami.leastsqnrm - INFO - flat model dimensions (4723, 44)
2026-04-15 20:17:14,975 - jwst.ami.leastsqnrm - INFO - model transpose dimensions (44, 4723)
2026-04-15 20:17:14,975 - jwst.ami.leastsqnrm - INFO - flat image dimensions (4723,)
2026-04-15 20:17:14,976 - jwst.ami.leastsqnrm - INFO - transpose * image data dimensions (44,)
2026-04-15 20:17:14,976 - jwst.ami.leastsqnrm - INFO - flat img * transpose dimensions (44, 44)
2026-04-15 20:17:14,977 - jwst.ami.leastsqnrm - INFO - linearfit not attempted, no covariances saved.
2026-04-15 20:17:14,978 - jwst.ami.nrm_core - INFO - Fitting fringes for iteration 60 of 61
2026-04-15 20:17:16,026 - jwst.ami.leastsqnrm - INFO - fringefitting.leastsqnrm.matrix_operations():
2026-04-15 20:17:16,026 - jwst.ami.leastsqnrm - INFO - img (69, 69)
2026-04-15 20:17:16,027 - jwst.ami.leastsqnrm - INFO - L x W = 69 x 69 = 4761
2026-04-15 20:17:16,027 - jwst.ami.leastsqnrm - INFO - flatimg (4761,)
2026-04-15 20:17:16,028 - jwst.ami.leastsqnrm - INFO -
2026-04-15 20:17:16,028 - jwst.ami.leastsqnrm - INFO - type(dqm) <class 'numpy.ndarray'>
2026-04-15 20:17:16,028 - jwst.ami.leastsqnrm - INFO - type(nanlist) <class 'tuple'>, len=1
2026-04-15 20:17:16,029 - jwst.ami.leastsqnrm - INFO - number of nanlist pixels: 39 items
2026-04-15 20:17:16,029 - jwst.ami.leastsqnrm - INFO - 39 DO_NOT_USE pixels found in data slice
2026-04-15 20:17:16,030 - jwst.ami.leastsqnrm - INFO - flatimg (4722,) after deleting 39
2026-04-15 20:17:16,031 - jwst.ami.leastsqnrm - INFO - flatmodel_nan (4761, 44)
2026-04-15 20:17:16,031 - jwst.ami.leastsqnrm - INFO - flatmodel (4722, 44)
2026-04-15 20:17:16,032 - jwst.ami.leastsqnrm - INFO - difference 39
2026-04-15 20:17:16,032 - jwst.ami.leastsqnrm - INFO - flat model dimensions (4722, 44)
2026-04-15 20:17:16,033 - jwst.ami.leastsqnrm - INFO - flat image dimensions (4722,)
2026-04-15 20:17:16,035 - jwst.ami.leastsqnrm - INFO - data flux 1.03374444e+06
2026-04-15 20:17:16,035 - jwst.ami.leastsqnrm - INFO - flat model dimensions (4722, 44)
2026-04-15 20:17:16,036 - jwst.ami.leastsqnrm - INFO - model transpose dimensions (44, 4722)
2026-04-15 20:17:16,036 - jwst.ami.leastsqnrm - INFO - flat image dimensions (4722,)
2026-04-15 20:17:16,036 - jwst.ami.leastsqnrm - INFO - transpose * image data dimensions (44,)
2026-04-15 20:17:16,037 - jwst.ami.leastsqnrm - INFO - flat img * transpose dimensions (44, 44)
2026-04-15 20:17:16,037 - jwst.ami.leastsqnrm - INFO - linearfit not attempted, no covariances saved.
2026-04-15 20:17:16,454 - stpipe.step - INFO - Saved model in ./nis_ami_demo_data/PID_1093/stage3/ami3_AB-DOR_F480M_02_ami-oi.fits
2026-04-15 20:17:16,585 - stpipe.step - INFO - Saved model in ./nis_ami_demo_data/PID_1093/stage3/ami3_AB-DOR_F480M_02_amimulti-oi.fits
2026-04-15 20:17:16,689 - stpipe.step - INFO - Saved model in ./nis_ami_demo_data/PID_1093/stage3/ami3_AB-DOR_F480M_02_amilg.fits
2026-04-15 20:17:16,690 - stpipe.step - INFO - Step ami_analyze done
2026-04-15 20:17:16,820 - stpipe.step - INFO - Saved model in ./nis_ami_demo_data/PID_1093/stage3/jw01093015001_03102_00001_nis_a3001_psf-ami-oi.fits
2026-04-15 20:17:17,000 - stpipe.step - INFO - Step ami_normalize running with args (<AmiOIModel(35,) from jw01093012001_03102_00001_nis_a3001_ami-oi.fits>, <AmiOIModel(35,) from jw01093015001_03102_00001_nis_a3001_psf-ami-oi.fits>).
2026-04-15 20:17:17,047 - stpipe.step - INFO - Step ami_normalize done
2026-04-15 20:17:17,176 - stpipe.step - INFO - Saved model in ./nis_ami_demo_data/PID_1093/stage3/ami3_AB-DOR_F480M_02_aminorm-oi.fits
2026-04-15 20:17:17,176 - jwst.pipeline.calwebb_ami3 - INFO - ... ending calwebb_ami3
2026-04-15 20:17:17,179 - stpipe.step - INFO - Step Ami3Pipeline done
2026-04-15 20:17:17,179 - jwst.stpipe.core - INFO - Results used jwst version: 2.0.0
# Print out the time benchmark
time1 = time.perf_counter()
print(f"Runtime so far: {time1 - time0:0.0f} seconds")
print(f"Runtime for AMI3: {time1 - time_ami3:0.0f} seconds")
Runtime so far: 229 seconds
Runtime for AMI3: 149 seconds
Verify which pipeline steps were run#
if doami3:
# Identify *ami-oi.fits file and open as datamodel
ami_oi = glob.glob(os.path.join(ami3_dir, "*_ami-oi.fits"))[0]
with datamodels.open(ami_oi) as oi_f:
# Check which steps were run
for step, status in oi_f.meta.cal_step.instance.items():
print(f"{step}: {status}")
ami_analyze: COMPLETE
assign_wcs: COMPLETE
charge_migration: COMPLETE
clean_flicker_noise: SKIPPED
dq_init: COMPLETE
flat_field: COMPLETE
gain_scale: SKIPPED
group_scale: SKIPPED
ipc: SKIPPED
jump: COMPLETE
linearity: COMPLETE
persistence: SKIPPED
photom: SKIPPED
picture_frame: SKIPPED
ramp_fit: COMPLETE
refpix: COMPLETE
saturation: COMPLETE
superbias: COMPLETE
Check which reference files were used to calibrate the dataset
if doami3:
for key, val in oi_f.meta.ref_file.instance.items():
print(f"{key}:")
for param in oi_f.meta.ref_file.instance[key]:
print(f"\t{oi_f.meta.ref_file.instance[key][param]}")
camera:
N/A
collimator:
N/A
crds:
jwst_1535.pmap
13.1.13
dflat:
N/A
disperser:
N/A
distortion:
crds://jwst_niriss_distortion_0023.asdf
fflat:
N/A
filteroffset:
crds://jwst_niriss_filteroffset_0006.asdf
flat:
crds://jwst_niriss_flat_0277.fits
fore:
N/A
fpa:
N/A
gain:
crds://jwst_niriss_gain_0006.fits
ifufore:
N/A
ifupost:
N/A
ifuslicer:
N/A
linearity:
crds://jwst_niriss_linearity_0017.fits
mask:
crds://jwst_niriss_mask_0016.fits
msa:
N/A
nrm:
crds://jwst_niriss_nrm_0004.fits
ote:
N/A
readnoise:
crds://jwst_niriss_readnoise_0005.fits
regions:
N/A
saturation:
crds://jwst_niriss_saturation_0015.fits
sflat:
N/A
specwcs:
N/A
superbias:
crds://jwst_niriss_superbias_0182.fits
throughput:
crds://jwst_niriss_throughput_0012.fits
wavelengthrange:
N/A
8. Visualize the results#
Plot interferometric observables#
We will now plot the interferometric observables for the target, reference star, and normalized target.
# Define a function for plotting observables
def plot_observables(ami_oimodel):
# Read the observables from the datamodel
# Squared visibilities and uncertainties
vis2 = ami_oimodel.vis2["VIS2DATA"]
vis2_err = ami_oimodel.vis2["VIS2ERR"]
# Closure phases and uncertainties
t3phi = ami_oimodel.t3["T3PHI"]
t3phi_err = ami_oimodel.t3["T3PHIERR"]
# Construct baselines between the U and V coordinates of sub-apertures
baselines = (ami_oimodel.vis2['UCOORD']**2 + ami_oimodel.vis2['VCOORD']**2)**0.5
# Construct baselines between combinations of three sub-apertures
u1 = ami_oimodel.t3['U1COORD']
u2 = ami_oimodel.t3['U2COORD']
v1 = ami_oimodel.t3['V1COORD']
v2 = ami_oimodel.t3['V2COORD']
u3 = -(u1 + u2)
v3 = -(v1 + v2)
baselines_t3 = []
for k in range(len(u1)):
B1 = np.sqrt(u1[k]**2 + v1[k]**2)
B2 = np.sqrt(u2[k]**2 + v2[k]**2)
B3 = np.sqrt(u3[k]**2 + v3[k]**2)
# Use longest baseline of the three for plotting
baselines_t3.append(np.max([B1, B2, B3]))
baselines_t3 = np.array(baselines_t3)
# Plot closure phases, squared visibilities against their baselines
fig, (ax1, ax2) = plt.subplots(1, 2, figsize=(15, 5))
ax1.errorbar(baselines_t3, t3phi, yerr=t3phi_err, fmt="go")
ax2.errorbar(baselines, vis2, yerr=vis2_err, fmt="go")
ax1.set_xlabel(r"$B_{max}$ [m]", size=12)
ax1.set_ylabel("Closure phase [deg]", size=12)
ax1.set_title("Closure Phase", size=14)
ax2.set_title("Squared Visibility", size=14)
ax2.set_xlabel(r"$B_{max}$ [m]", size=12)
ax2.set_ylabel("Squared Visibility", size=12)
plt.suptitle(ami_oimodel.meta.filename, fontsize=16)
ax1.set_ylim([-3.5, 3.5])
ax2.set_ylim([0.5, 1.1])
First we’ll look at the target and reference star’s squared visibilities and closure phases. We plot the squared visibilities against their corresponding baselines (units of meters projected back to the primary meter). We plot the closure phases against the longest of the three baselines that forms the “closure triangle” whose phases were summed to calculate the closure phase.
if doviz:
# Get the first target ami-oi.fits file
oi_scifile = sorted(glob.glob(os.path.join(ami3_dir, "jw*_ami-oi.fits")))
if isinstance(oi_scifile, list):
oi_scifile = oi_scifile[0]
# Get the first PSF reference ami-oi fits file
oi_psffile = sorted(glob.glob(os.path.join(ami3_dir, "jw*psf-ami-oi.fits")))
if isinstance(oi_psffile, list):
oi_psffile = oi_psffile[0]
# Open them as datamodels
amioi_targ = datamodels.open(oi_scifile)
amioi_ref = datamodels.open(oi_psffile)
# Plot the observables
plot_observables(amioi_targ)
plot_observables(amioi_ref)
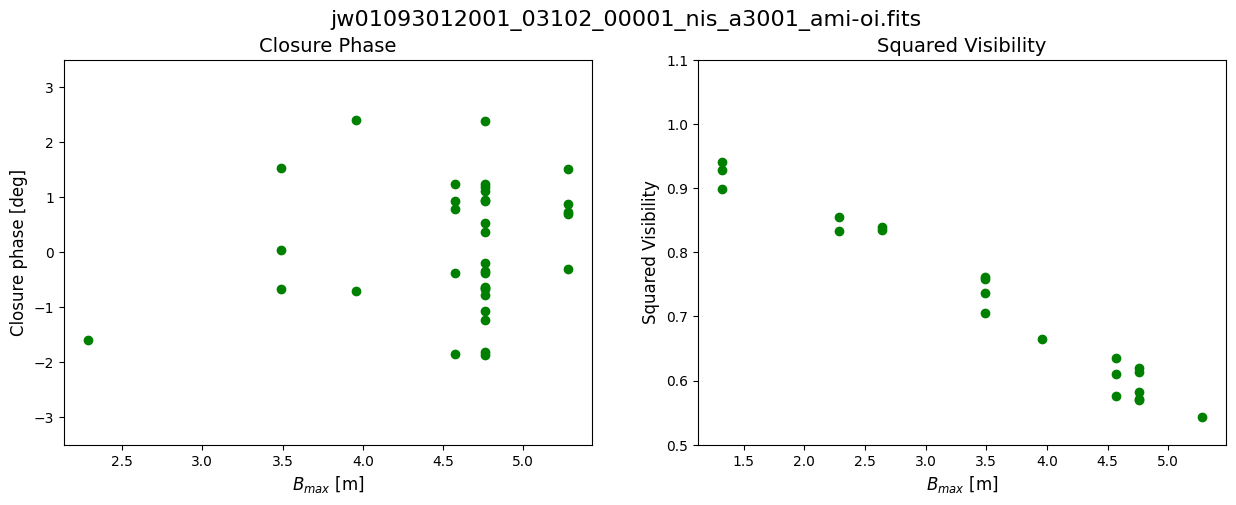
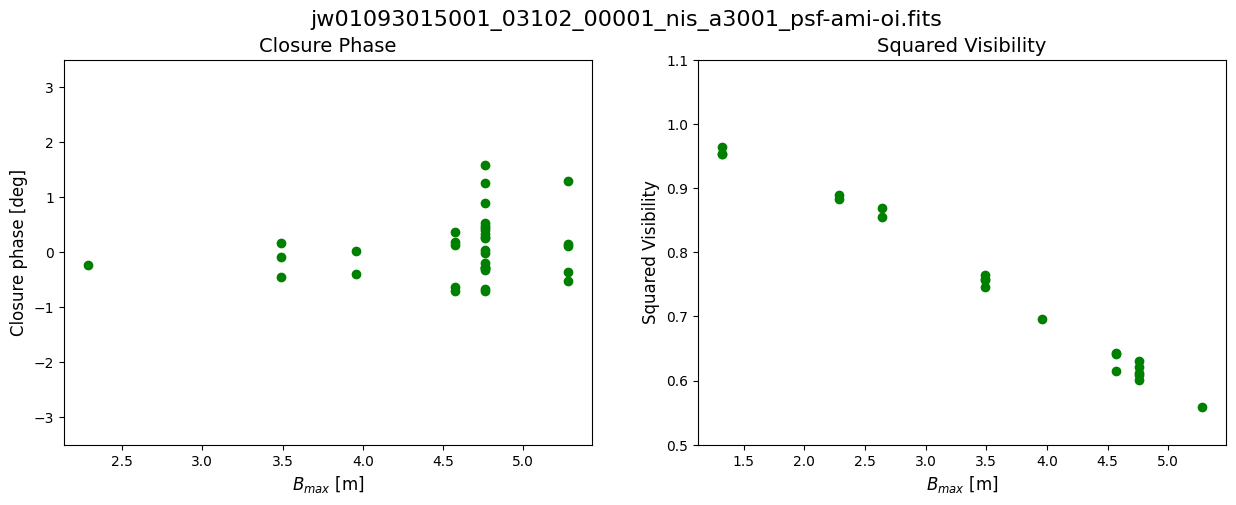
The top two scatter plots show the observables from the target observation, and the lower two show the observables from the reference star. For a perfect point source observation at single wavelength, we would expect to recover closure phases of zero and squared visibilites of unity.
Since the closure phases are sensitive to asymmetries in the source brightness distribution, we can tell from the larger scatter of the target that it is likely not a point source; i.e, there is a faint companion. On the other hand, the reference star has closure phases with a much smaller scatter around zero. The squared visibilities of both decrease at longer wavelengths due to an effect called bandpass smearing. We expect that calibrating the target by the reference star should correct for this, as well as other systematics.
Now we will plot the final calibrated data product; the target normalized by the reference star. The reference star closure phases are subtracted from the target closure phases, and the target squared visibilities are divided by the reference star squared visibilities.
Further scientific analysis on these calibrated OIFITS files can be done with community-developed analysis software like CANDID (Gallenne et al. 2015) or Fouriever to extract binary parameters, or an image reconstruction code like SQUEEZE (Baron et al. 2010) or BSMEM (Skilling & Bryan 1984, Buscher 1994, Baron & Young 2008).
if doviz:
# Identify calibrated *_aminorm-oi.fits file and open as datamodel
abdor_oifits = glob.glob(os.path.join(ami3_dir, "*_aminorm-oi.fits"))[0]
amioi_norm = datamodels.open(abdor_oifits)
# Plot the observables
plot_observables(amioi_norm)
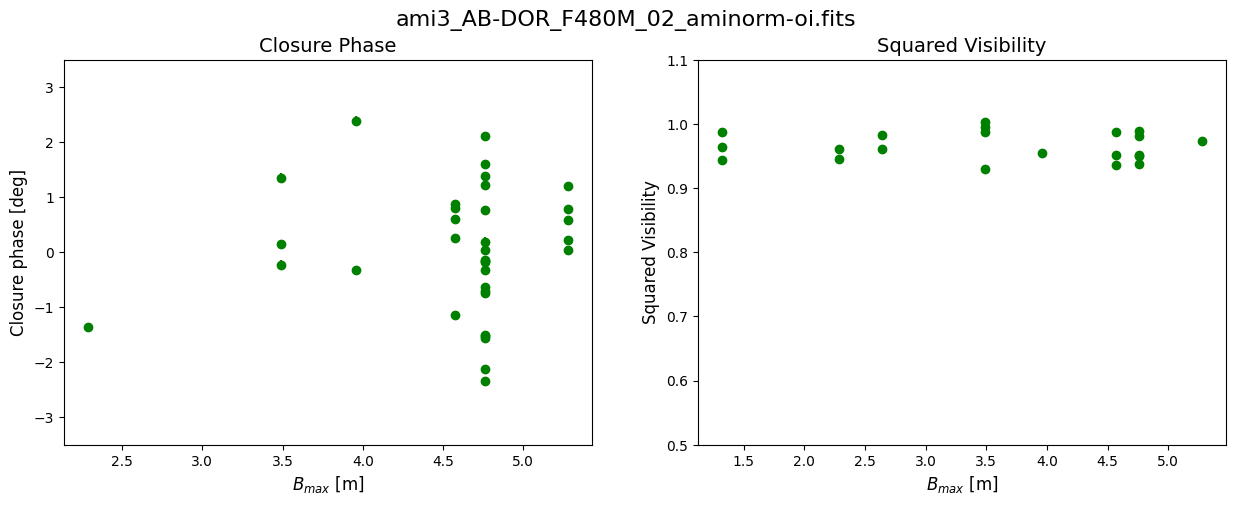
Display the best-fit model#
We can also look at the cleaned data, model, and residual images that are saved in the auxiliary *amilg.fits data products:
if doviz:
# Find the data files
amilg = sorted(glob.glob(os.path.join(ami3_dir, '*amilg.fits')))
# Open the first one as an AmiLGModel
firstfile = amilg[0]
amilgmodel = datamodels.open(firstfile)
# Plot the data, model, residual
norm = ImageNormalize(amilgmodel.norm_centered_image[0],
interval=MinMaxInterval(),
stretch=SqrtStretch())
fig, axs = plt.subplots(1, 3, figsize=(12, 5))
axs[0].set_title('Normalized Data')
im1 = axs[0].imshow(amilgmodel.norm_centered_image[0], norm=norm)
axs[1].set_title('Normalized Model')
im2 = axs[1].imshow(amilgmodel.norm_fit_image[0], norm=norm)
axs[2].set_title('Normalized Residual (Data-Model)')
im3 = axs[2].imshow(amilgmodel.norm_resid_image[0])
for im in [im1, im2, im3]:
plt.colorbar(im, shrink=.95, location='bottom', pad=.05)
for ax in axs:
ax.axis('off')
plt.suptitle(os.path.basename(firstfile))
plt.tight_layout()
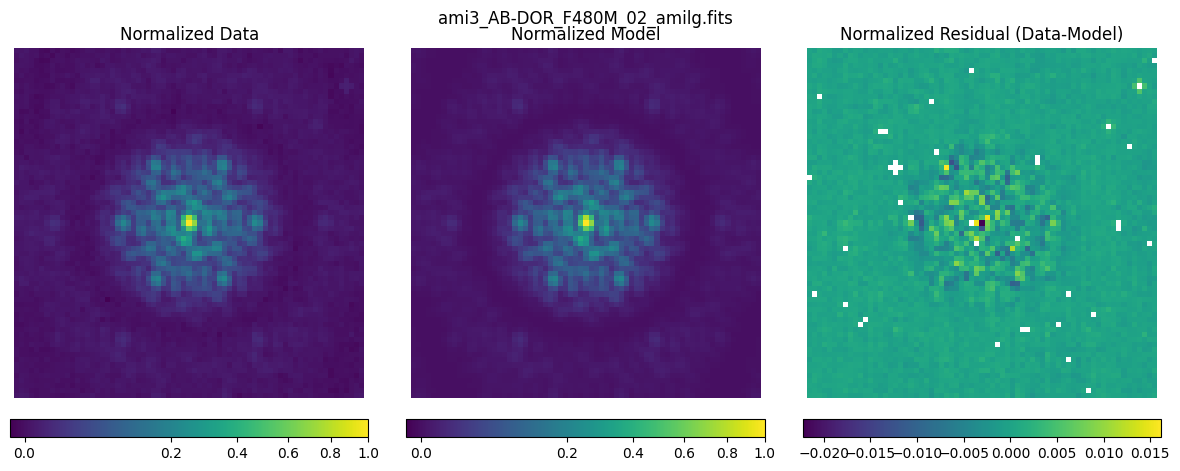
Each image has been normalized by the peak pixel value of the data, and the data and model are displayed on a square root stretch to emphasize the fainter features. By looking at the residual (data - model) image, we can see that the model is a good fit to the data. This model achieves better contrast than ground-based NRM, but has not reached the binary contrast science requirements of AMI. The faint vertical striping in the background of the residual image is 1/f noise (flicker noise), which is an active area of improvement for the NIRISS/AMI team, as is the best method of correcting for charge migration.
