Cleaning Residual 1/f Noise in NIRSpec MOS Products with NSClean#
Notebook Goal#
The goal of this notebook is to generate cleaned MOS (_rate.fits) files by removing residual 1/f noise. These cleaned files will be used as input for the level 3 (Spec3Pipeline) pipeline.
Table of Contents#
1. Introduction #
The JWST NIRSpec instrument has a number of features and characteristics that observers should be aware of when planning observations and interpreting data. One notable feature seen in NIRSpec pipeline products is negative and/or surplus flux in the extracted 1-D spectrum, typically with an irregular wavelength-dependent undulation. The cause of this artifact is correlated noise, known as 1/f noise, from low-level detector thermal instabilities, seen as vertical banding in 2-D count rate images, particularly in exposures of the NRS2 detector. While the IRS2 readout mode reduces this effect, it is not completely eliminated.
To address this issue, the JWST Science Calibration Pipeline has integrated an external package developed by Bernard Rauscher, known as NSClean, within the Spec2Pipeline under NSCleanStep. This algorithm uses dark areas of the detector to fit a background model to the data in Fourier space. It requires an input mask to identify all dark areas of the detector. The more thorough and complete this mask is, the better the background fit.
In this notebook, we will use the NSClean algorithm integrated into the pipeline, utilizing a mask generated on-the-fly with default parameters to remove 1/f noise. In some cases, this mask may not be complete enough/too restrictive for the best possible noise removal. To address this, we demonstrate how one can manually modify the default mask, as well as how to create an alternative mask by adjusting the NSCleanStep parameters. If needed, see the NSClean documentation for some suggestions on manually creating a custom mask.
This notebook utilizes a MOS observation from the CEERS program with grating/filter G395M/F290LP, which is part of the JWST Early Release Science program ERS-1345 observation 61, as an example.
The NSClean step has been removed in JWST pipeline version 2.0.0 and replaced with the CleanFlickerNoiseStep, which is available in both the Detector1Pipeline and Spec2Pipeline. The latest supported version of the JWST pipeline that includes the NSClean step is version 1.20.2. For information on how to run the CleanFlickerNoiseStep for MOS data, see the MOS Pipeline Notebook.
2. Import Library #
# ---------- Set CRDS environment variables ----------
import os
import jwst
# Set the CRDS context if you'd like something different from the default
# os.environ['CRDS_CONTEXT'] = 'jwst_1210.pmap'
os.environ['CRDS_PATH'] = os.environ['HOME']+'/crds_cache'
os.environ['CRDS_SERVER_URL'] = 'https://jwst-crds.stsci.edu'
print(f'CRDS cache location: {os.environ["CRDS_PATH"]}')
print("JWST Calibration Pipeline Version={}".format(jwst.__version__))
# print("Current Operational CRDS Context = {}".format(crds.get_default_context()))
CRDS cache location: /home/runner/crds_cache
JWST Calibration Pipeline Version=1.20.2
# ------ General Imports ------
import numpy as np
import time as tt
import logging
import warnings
# ------ JWST Calibration Pipeline Imports ------
from jwst.pipeline.calwebb_spec2 import Spec2Pipeline
# ------ Plotting/Stats Imports ------
from matplotlib import pyplot as plt
from astropy.io import fits
from utils import get_jwst_file, plot_dark_data, plot_cleaned_data, plot_spectra
# Hide all log and warning messages.
logging.disable(logging.ERROR)
warnings.simplefilter("ignore", RuntimeWarning)
3. Download the Data #
The input data for this notebook features a MOS observation from the CEERS program with grating/filter G395H/F290LP. The dataset is part of the JWST Early Release Science program ERS-1345, specifically observation 61. It consists of 3 integrations (3 dither points; 3-SHUTTER-SLITLET) with 9 groups each. This notebook focuses on the third dithered exposure (00003) as an example. However, it’s important to note that before proceeding to the Spec3Pipeline, all exposures must first be processed through the Spec2Pipeline.
# Define a downloads directory.
mast_products_dir = "./mast_products/"
# Check if the directory exists.
if not os.path.exists(mast_products_dir):
# Create the directory if it doesn't exist.
os.makedirs(mast_products_dir)
# This notebook focuses on the third dithered exposure.
obs_ids = ["jw01345061001_07101_00003"]
detectors = [1, 2] # Both Detectors NRS1 and NRS2.
# Specify countrate products
rate_names = []
for obs_id in obs_ids:
for detector in detectors:
rate_names.append(f"{obs_id}_nrs{detector}_rate.fits")
# Download all the FITS files and associated MSA files.
msa_names = []
for name in rate_names:
print(f"Downloading {name}")
get_jwst_file(
name,
mast_api_token="75f915f251544013bb127b7f6f6edc80",
save_directory=mast_products_dir,
)
# Retrieve the MSA file from the header in the downloaded file.
msa_name = fits.getval(mast_products_dir + name, "MSAMETFL")
if not os.path.isfile(msa_name):
print(f"Downloading {msa_name}")
get_jwst_file(
msa_name,
mast_api_token=None,
save_directory=mast_products_dir,
)
msa_names.append(msa_name)
Downloading jw01345061001_07101_00003_nrs1_rate.fits
Downloading jw01345061001_01_msa.fits
Downloading jw01345061001_07101_00003_nrs2_rate.fits
Downloading jw01345061001_01_msa.fits
The file jw01345061001_01_msa.fits already exists in the directory. Skipping download.
4. Running Spec2Pipeline without NSClean (Original Data) #
The cell below executes the Spec2Pipeline, explicitly skipping the NSClean step during processing. The level 2 products generated will serve as a reference point to illustrate how the countrate images and final extracted spectra appear without the removal of 1/f noise.
# Set up directory for running the pipeline without NSClean.
stage2_nsclean_skipped_dir = "./stage2_nsclean_skipped/"
if not os.path.exists(stage2_nsclean_skipped_dir):
os.makedirs(stage2_nsclean_skipped_dir) # Create the directory if it doesn't exist.
# Original data (no NSClean Applied).
# Estimated run-time: 1-2 minutes.
start = tt.time()
for i in rate_names:
print(f"Processing {i}...")
if "nrs1" in i:
slit_name = "80"
else:
slit_name = "11"
Spec2Pipeline.call(
mast_products_dir + i,
save_results=True,
steps={"nsclean": {"skip": True}, "extract_2d": {"slit_names": slit_name}},
output_dir=stage2_nsclean_skipped_dir,
)
print(f"Saved {i[:-9]}" + "cal.fits")
print(f"Saved {i[:-9]}" + "x1d.fits")
end = tt.time()
print("Run time: ", round(end - start, 1) / 60.0, " min")
Processing jw01345061001_07101_00003_nrs1_rate.fits...
Saved jw01345061001_07101_00003_nrs1_cal.fits
Saved jw01345061001_07101_00003_nrs1_x1d.fits
Processing jw01345061001_07101_00003_nrs2_rate.fits...
Saved jw01345061001_07101_00003_nrs2_cal.fits
Saved jw01345061001_07101_00003_nrs2_x1d.fits
Run time: 1.4483333333333335 min
5. Clean up 1/f Noise with NSClean (Default Pipeline Mask) #
If a user-supplied mask file is not provided to the NSClean step in the Spec2Pipeline, the pipeline will generate a mask based on default parameters. This mask will identify any pixel that is unilluminated. That is, the mask must contain True and False values, where True indicates that the pixel is dark, and False indicates that the pixel is illuminated (not dark).
By default, the pipeline marks the following detector areas as illuminated, non-dark areas (False):
Pixels designated as open slits for this MOS observation.
Traces from failed-open MSA shutters.
5-sigma outliers (default value).
Any pixel set to NaN in the rate data.
To tune the outlier detection in the mask, try modifying the n_sigma parameter (explored in the next section). A higher value will identify fewer outliers. A lower value will identify more.
The default generated mask is saved and analyzed below.
# Set up directory for running NSClean with default parameters.
stage2_nsclean_default_dir = "./stage2_nsclean_default/"
if not os.path.exists(stage2_nsclean_default_dir):
os.makedirs(stage2_nsclean_default_dir) # Create the directory if it doesn't exist.
# 1/f noise cleaned data (default NSClean pipeline mask).
# Estimated run time: 6 minutes.
start = tt.time()
for i in rate_names:
print(f"Processing {i}...")
if "nrs1" in i:
slit_name = "80"
else:
slit_name = "11"
Spec2Pipeline.call(
mast_products_dir + i,
save_results=True,
steps={
"nsclean": {"skip": False, "save_mask": True, "save_results": True},
"extract_2d": {"slit_names": slit_name},
},
output_dir=stage2_nsclean_default_dir,
)
print(f"Saved {i[:-9]}" + "mask.fits")
print(f"Saved {i[:-9]}" + "nsclean.fits")
print(f"Saved {i[:-9]}" + "cal.fits")
print(f"Saved {i[:-9]}" + "x1d.fits")
end = tt.time()
print("Run time: ", round(end - start, 1) / 60.0, " min")
Processing jw01345061001_07101_00003_nrs1_rate.fits...
2026-04-22 19:09:07,232 - jwst.clean_flicker_noise.clean_flicker_noise - INFO - Creating mask
2026-04-22 19:09:07,233 - jwst.clean_flicker_noise.clean_flicker_noise - INFO - Finding slit/slitlet pixels
2026-04-22 19:09:10,534 - jwst.clean_flicker_noise.clean_flicker_noise - INFO - Masking the fixed slit region for MOS data.
2026-04-22 19:09:10,855 - jwst.clean_flicker_noise.clean_flicker_noise - INFO - Cleaning image jw01345061001_07101_00003_nrs1_rate.fits
2026-04-22 19:09:12,775 - jwst.nsclean.nsclean_step - INFO - Saving mask file ./stage2_nsclean_default/jw01345061001_07101_00003_nrs1_mask.fits
2026-04-22 19:09:14,673 - stpipe.step - INFO - Saved model in ./stage2_nsclean_default/jw01345061001_07101_00003_nrs1_nsclean.fits
2026-04-22 19:09:14,674 - stpipe.step - INFO - Step nsclean done
2026-04-22 19:09:15,058 - stpipe.step - INFO - Step imprint_subtract running with args (<ImageModel(2048, 2048) from jw01345061001_07101_00003_nrs1_nsclean.fits>, []).
2026-04-22 19:09:15,059 - stpipe.step - INFO - Step skipped.
2026-04-22 19:09:15,363 - stpipe.step - INFO - Step bkg_subtract running with args (<ImageModel(2048, 2048) from jw01345061001_07101_00003_nrs1_nsclean.fits>, []).
2026-04-22 19:09:15,364 - stpipe.step - INFO - Step skipped.
2026-04-22 19:09:15,672 - stpipe.step - INFO - Step extract_2d running with args (<ImageModel(2048, 2048) from jw01345061001_07101_00003_nrs1_nsclean.fits>,).
2026-04-22 19:09:15,678 - jwst.extract_2d.extract_2d - INFO - EXP_TYPE is NRS_MSASPEC
2026-04-22 19:09:15,679 - jwst.extract_2d.nirspec - INFO - Slits selected:
2026-04-22 19:09:15,680 - jwst.extract_2d.nirspec - INFO - Name: 80, source_id: 1509
2026-04-22 19:09:15,739 - jwst.extract_2d.nirspec - INFO - Name of subarray extracted: 80
2026-04-22 19:09:15,740 - jwst.extract_2d.nirspec - INFO - Subarray x-extents are: 423 1777
2026-04-22 19:09:15,740 - jwst.extract_2d.nirspec - INFO - Subarray y-extents are: 262 295
2026-04-22 19:09:15,993 - jwst.extract_2d.nirspec - INFO - set slit_attributes completed
2026-04-22 19:09:16,000 - stcal.alignment.util - INFO - Update S_REGION to POLYGON ICRS 214.817179331 52.830822659 214.816253456 52.830818677 214.816255004 52.830763514 214.817180881 52.830767490
2026-04-22 19:09:16,002 - jwst.extract_2d.nirspec - INFO - Updated S_REGION to POLYGON ICRS 214.817179331 52.830822659 214.816253456 52.830818677 214.816255004 52.830763514 214.817180881 52.830767490
2026-04-22 19:09:16,065 - stpipe.step - INFO - Step extract_2d done
2026-04-22 19:09:16,375 - stpipe.step - INFO - Step srctype running with args (<MultiSlitModel from jw01345061001_07101_00003_nrs1_nsclean.fits>,).
2026-04-22 19:09:16,529 - jwst.srctype.srctype - INFO - Input EXP_TYPE is NRS_MSASPEC
2026-04-22 19:09:16,530 - jwst.srctype.srctype - INFO - source_id=1509, stellarity=1.0000, type=POINT
2026-04-22 19:09:16,532 - stpipe.step - INFO - Step srctype done
2026-04-22 19:09:17,006 - stpipe.step - INFO - Step master_background_mos running with args (<MultiSlitModel from jw01345061001_07101_00003_nrs1_nsclean.fits>,).
2026-04-22 19:09:17,013 - jwst.master_background.master_background_mos_step - WARNING - No background slits available for creating master background. Skipping
2026-04-22 19:09:17,178 - jwst.stpipe.core - INFO - Results used CRDS context: jwst_1464.pmap
2026-04-22 19:09:17,179 - stpipe.step - INFO - Step master_background_mos done
2026-04-22 19:09:17,503 - stpipe.step - INFO - Step wavecorr running with args (<MultiSlitModel from jw01345061001_07101_00003_nrs1_nsclean.fits>,).
2026-04-22 19:09:17,704 - jwst.wavecorr.wavecorr_step - INFO - Using WAVECORR reference file /home/runner/crds_cache/references/jwst/nirspec/jwst_nirspec_wavecorr_0004.asdf
2026-04-22 19:09:17,705 - jwst.wavecorr.wavecorr - INFO - Detected a POINT source type in slit 80
2026-04-22 19:09:17,783 - jwst.wavecorr.wavecorr - INFO - Using wavelength zero-point correction for aperture MOS
2026-04-22 19:09:17,825 - stpipe.step - INFO - Step wavecorr done
2026-04-22 19:09:18,165 - stpipe.step - INFO - Step flat_field running with args (<MultiSlitModel from jw01345061001_07101_00003_nrs1_nsclean.fits>,).
2026-04-22 19:09:18,191 - jwst.flatfield.flat_field_step - INFO - No reference found for type FLAT
2026-04-22 19:09:18,343 - jwst.flatfield.flat_field_step - INFO - Using FFLAT reference file: /home/runner/crds_cache/references/jwst/nirspec/jwst_nirspec_fflat_0167.fits
2026-04-22 19:09:18,827 - jwst.flatfield.flat_field_step - INFO - Using SFLAT reference file: /home/runner/crds_cache/references/jwst/nirspec/jwst_nirspec_sflat_0225.fits
2026-04-22 19:09:18,968 - jwst.flatfield.flat_field_step - INFO - Using DFLAT reference file: /home/runner/crds_cache/references/jwst/nirspec/jwst_nirspec_dflat_0001.fits
2026-04-22 19:09:19,117 - jwst.flatfield.flat_field - INFO - Working on slit 80
2026-04-22 19:09:19,496 - stpipe.step - INFO - Step flat_field done
2026-04-22 19:09:19,843 - stpipe.step - INFO - Step pathloss running with args (<MultiSlitModel from jw01345061001_07101_00003_nrs1_nsclean.fits>,).
2026-04-22 19:09:19,858 - jwst.pathloss.pathloss_step - INFO - Using PATHLOSS reference file /home/runner/crds_cache/references/jwst/nirspec/jwst_nirspec_pathloss_0010.fits
2026-04-22 19:09:19,918 - jwst.pathloss.pathloss - INFO - Input exposure type is NRS_MSASPEC
2026-04-22 19:09:20,075 - jwst.pathloss.pathloss - INFO - Working on slit 0
2026-04-22 19:09:20,076 - jwst.pathloss.pathloss - INFO - Shutter state = 11x, using MOS1x3 entry in ref file
2026-04-22 19:09:20,077 - jwst.pathloss.pathloss - INFO - Shutter above fiducial is closed, using upper region of pathloss array
2026-04-22 19:09:20,147 - stpipe.step - INFO - Step pathloss done
2026-04-22 19:09:20,487 - stpipe.step - INFO - Step barshadow running with args (<MultiSlitModel from jw01345061001_07101_00003_nrs1_nsclean.fits>,).
2026-04-22 19:09:20,502 - jwst.barshadow.barshadow_step - INFO - Using BARSHADOW reference file /home/runner/crds_cache/references/jwst/nirspec/jwst_nirspec_barshadow_0008.fits
2026-04-22 19:09:20,691 - jwst.barshadow.bar_shadow - INFO - Working on slitlet 80
2026-04-22 19:09:20,692 - jwst.barshadow.bar_shadow - INFO - Bar shadow correction skipped for slitlet 80 (source not uniform)
2026-04-22 19:09:20,700 - stpipe.step - INFO - Step barshadow done
2026-04-22 19:09:21,048 - stpipe.step - INFO - Step photom running with args (<MultiSlitModel from jw01345061001_07101_00003_nrs1_nsclean.fits>,).
2026-04-22 19:09:21,066 - jwst.photom.photom_step - INFO - Using photom reference file: /home/runner/crds_cache/references/jwst/nirspec/jwst_nirspec_photom_0015.fits
2026-04-22 19:09:21,066 - jwst.photom.photom_step - INFO - Using area reference file: /home/runner/crds_cache/references/jwst/nirspec/jwst_nirspec_area_0051.fits
2026-04-22 19:09:21,238 - jwst.photom.photom - INFO - Using instrument: NIRSPEC
2026-04-22 19:09:21,239 - jwst.photom.photom - INFO - detector: NRS1
2026-04-22 19:09:21,239 - jwst.photom.photom - INFO - exp_type: NRS_MSASPEC
2026-04-22 19:09:21,240 - jwst.photom.photom - INFO - filter: F290LP
2026-04-22 19:09:21,240 - jwst.photom.photom - INFO - grating: G395M
2026-04-22 19:09:21,284 - jwst.photom.photom - INFO - Working on slit 80
2026-04-22 19:09:21,285 - jwst.photom.photom - INFO - PHOTMJSR value: 1
2026-04-22 19:09:21,314 - stpipe.step - INFO - Step photom done
2026-04-22 19:09:21,827 - stpipe.step - INFO - Step pixel_replace running with args (<MultiSlitModel from ./stage2_nsclean_default/jw01345061001_07101_00003_nrs1_cal.fits>,).
2026-04-22 19:09:21,828 - stpipe.step - INFO - Step skipped.
2026-04-22 19:09:22,097 - stpipe.step - INFO - Step resample_spec running with args (<MultiSlitModel from ./stage2_nsclean_default/jw01345061001_07101_00003_nrs1_cal.fits>,).
2026-04-22 19:09:22,377 - jwst.exp_to_source.exp_to_source - INFO - Reorganizing data from exposure ./stage2_nsclean_default/jw01345061001_07101_00003_nrs1_cal.fits
2026-04-22 19:09:22,750 - jwst.resample.resample_spec - INFO - Specified output pixel scale ratio: 1.0.
2026-04-22 19:09:22,760 - jwst.resample.resample_spec - INFO - Computed output pixel scale: 0.1036 arcsec.
2026-04-22 19:09:22,762 - stcal.resample.resample - INFO - Output pixel scale: 0.10360056702018924 arcsec.
2026-04-22 19:09:22,763 - stcal.resample.resample - INFO - Driz parameter kernel: square
2026-04-22 19:09:22,763 - stcal.resample.resample - INFO - Driz parameter pixfrac: 1.0
2026-04-22 19:09:22,764 - stcal.resample.resample - INFO - Driz parameter fillval: NaN
2026-04-22 19:09:22,765 - stcal.resample.resample - INFO - Driz parameter weight_type: exptime
2026-04-22 19:09:22,766 - jwst.resample.resample - INFO - Resampling science and variance data
2026-04-22 19:09:22,820 - stcal.resample.resample - INFO - Resampling science and variance data
2026-04-22 19:09:22,825 - stcal.resample.resample - INFO - Drizzling (33, 1354) --> (21, 1354)
2026-04-22 19:09:22,829 - stcal.resample.resample - INFO - Drizzling (33, 1354) --> (21, 1354)
2026-04-22 19:09:22,833 - stcal.resample.resample - INFO - Drizzling (33, 1354) --> (21, 1354)
2026-04-22 19:09:22,966 - stcal.alignment.util - INFO - Update S_REGION to POLYGON ICRS 214.816217049 52.830790936 214.817169667 52.830790936 214.817169667 52.830795030 214.816217049 52.830795030
2026-04-22 19:09:23,106 - stpipe.step - INFO - Saved model in ./stage2_nsclean_default/jw01345061001_07101_00003_nrs1_s2d.fits
2026-04-22 19:09:23,107 - stpipe.step - INFO - Step resample_spec done
2026-04-22 19:09:23,191 - jwst.pipeline.calwebb_spec2 - INFO - Extracting 1 MSA slitlets
2026-04-22 19:09:23,487 - stpipe.step - INFO - Step extract_1d running with args (<MultiSlitModel from jw01345061001_07101_00003_nrs1_s2d.fits>,).
2026-04-22 19:09:23,656 - jwst.extract_1d.extract_1d_step - INFO - Using EXTRACT1D reference file /home/runner/crds_cache/references/jwst/nirspec/jwst_nirspec_extract1d_0009.json
2026-04-22 19:09:23,661 - jwst.extract_1d.extract_1d_step - INFO - Using APCORR file /home/runner/crds_cache/references/jwst/nirspec/jwst_nirspec_apcorr_0004.fits
2026-04-22 19:09:23,701 - jwst.extract_1d.extract - INFO - Working on slit 80
2026-04-22 19:09:23,702 - jwst.lib.pipe_utils - WARNING - Mismatched data shapes; skipping invalid data updates for extension 'dq'
2026-04-22 19:09:23,703 - jwst.extract_1d.extract - INFO - Turning on source position correction for exp_type = NRS_MSASPEC
2026-04-22 19:09:23,706 - jwst.extract_1d.source_location - INFO - Using source_xpos and source_ypos to center extraction.
2026-04-22 19:09:23,710 - jwst.extract_1d.extract - INFO - Computed source location is 4.78, at pixel 676, wavelength 4.07
2026-04-22 19:09:23,711 - jwst.extract_1d.extract - INFO - Nominal aperture start/stop: 7.50 -> 12.50 (inclusive)
2026-04-22 19:09:23,712 - jwst.extract_1d.extract - INFO - Nominal location is 10.00, so offset is -5.22 pixels
2026-04-22 19:09:23,713 - jwst.extract_1d.extract - INFO - Mean aperture start/stop from trace: 2.28 -> 7.28 (inclusive)
2026-04-22 19:09:23,716 - jwst.extract_1d.extract - INFO - Creating aperture correction.
2026-04-22 19:09:24,692 - stpipe.step - INFO - Step extract_1d done
2026-04-22 19:09:24,752 - stpipe.step - INFO - Saved model in ./stage2_nsclean_default/jw01345061001_07101_00003_nrs1_x1d.fits
2026-04-22 19:09:24,753 - jwst.pipeline.calwebb_spec2 - INFO - Finished processing product mast_products/jw01345061001_07101_00003_nrs1
2026-04-22 19:09:24,755 - jwst.pipeline.calwebb_spec2 - INFO - Ending calwebb_spec2
2026-04-22 19:09:24,755 - jwst.stpipe.core - INFO - Results used CRDS context: jwst_1464.pmap
2026-04-22 19:09:25,015 - stpipe.step - INFO - Saved model in ./stage2_nsclean_default/jw01345061001_07101_00003_nrs1_cal.fits
2026-04-22 19:09:25,015 - stpipe.step - INFO - Step Spec2Pipeline done
2026-04-22 19:09:25,016 - jwst.stpipe.core - INFO - Results used jwst version: 1.20.2
2026-04-22 19:09:25,044 - stpipe.step - INFO - PARS-RESAMPLESPECSTEP parameters found: /home/runner/crds_cache/references/jwst/nirspec/jwst_nirspec_pars-resamplespecstep_0001.asdf
2026-04-22 19:09:25,060 - stpipe.step - INFO - PARS-RESAMPLESPECSTEP parameters found: /home/runner/crds_cache/references/jwst/nirspec/jwst_nirspec_pars-resamplespecstep_0001.asdf
2026-04-22 19:09:25,082 - stpipe.step - INFO - Spec2Pipeline instance created.
2026-04-22 19:09:25,083 - stpipe.step - INFO - AssignWcsStep instance created.
2026-04-22 19:09:25,084 - stpipe.step - INFO - BadpixSelfcalStep instance created.
2026-04-22 19:09:25,085 - stpipe.step - INFO - MSAFlagOpenStep instance created.
2026-04-22 19:09:25,086 - stpipe.step - INFO - NSCleanStep instance created.
2026-04-22 19:09:25,087 - stpipe.step - INFO - BackgroundStep instance created.
2026-04-22 19:09:25,088 - stpipe.step - INFO - ImprintStep instance created.
2026-04-22 19:09:25,089 - stpipe.step - INFO - Extract2dStep instance created.
2026-04-22 19:09:25,093 - stpipe.step - INFO - MasterBackgroundMosStep instance created.
2026-04-22 19:09:25,094 - stpipe.step - INFO - FlatFieldStep instance created.
2026-04-22 19:09:25,095 - stpipe.step - INFO - PathLossStep instance created.
2026-04-22 19:09:25,096 - stpipe.step - INFO - BarShadowStep instance created.
2026-04-22 19:09:25,097 - stpipe.step - INFO - PhotomStep instance created.
2026-04-22 19:09:25,097 - stpipe.step - INFO - PixelReplaceStep instance created.
2026-04-22 19:09:25,098 - stpipe.step - INFO - ResampleSpecStep instance created.
2026-04-22 19:09:25,100 - stpipe.step - INFO - Extract1dStep instance created.
2026-04-22 19:09:25,101 - stpipe.step - INFO - WavecorrStep instance created.
2026-04-22 19:09:25,102 - stpipe.step - INFO - FlatFieldStep instance created.
2026-04-22 19:09:25,103 - stpipe.step - INFO - SourceTypeStep instance created.
2026-04-22 19:09:25,104 - stpipe.step - INFO - StraylightStep instance created.
2026-04-22 19:09:25,104 - stpipe.step - INFO - FringeStep instance created.
2026-04-22 19:09:25,105 - stpipe.step - INFO - ResidualFringeStep instance created.
2026-04-22 19:09:25,107 - stpipe.step - INFO - PathLossStep instance created.
2026-04-22 19:09:25,108 - stpipe.step - INFO - BarShadowStep instance created.
2026-04-22 19:09:25,109 - stpipe.step - INFO - WfssContamStep instance created.
2026-04-22 19:09:25,110 - stpipe.step - INFO - PhotomStep instance created.
2026-04-22 19:09:25,110 - stpipe.step - INFO - PixelReplaceStep instance created.
2026-04-22 19:09:25,111 - stpipe.step - INFO - ResampleSpecStep instance created.
2026-04-22 19:09:25,113 - stpipe.step - INFO - CubeBuildStep instance created.
2026-04-22 19:09:25,114 - stpipe.step - INFO - Extract1dStep instance created.
2026-04-22 19:09:25,482 - stpipe.step - INFO - Step Spec2Pipeline running with args ('./mast_products/jw01345061001_07101_00003_nrs2_rate.fits',).
Saved jw01345061001_07101_00003_nrs1_mask.fits
Saved jw01345061001_07101_00003_nrs1_nsclean.fits
Saved jw01345061001_07101_00003_nrs1_cal.fits
Saved jw01345061001_07101_00003_nrs1_x1d.fits
Processing jw01345061001_07101_00003_nrs2_rate.fits...
2026-04-22 19:09:25,511 - stpipe.step - INFO - Step Spec2Pipeline parameters are:
pre_hooks: []
post_hooks: []
output_file: None
output_dir: ./stage2_nsclean_default/
output_ext: .fits
output_use_model: False
output_use_index: True
save_results: True
skip: False
suffix: None
search_output_file: True
input_dir: ''
save_bsub: False
fail_on_exception: True
save_wfss_esec: False
steps:
assign_wcs:
pre_hooks: []
post_hooks: []
output_file: None
output_dir: None
output_ext: .fits
output_use_model: False
output_use_index: True
save_results: False
skip: False
suffix: None
search_output_file: True
input_dir: ''
sip_approx: True
sip_max_pix_error: 0.01
sip_degree: None
sip_max_inv_pix_error: 0.01
sip_inv_degree: None
sip_npoints: 12
slit_y_low: -0.55
slit_y_high: 0.55
nrs_ifu_slice_wcs: False
badpix_selfcal:
pre_hooks: []
post_hooks: []
output_file: None
output_dir: None
output_ext: .fits
output_use_model: False
output_use_index: True
save_results: False
skip: True
suffix: None
search_output_file: True
input_dir: ''
flagfrac_lower: 0.001
flagfrac_upper: 0.001
kernel_size: 15
force_single: False
save_flagged_bkg: False
msa_flagging:
pre_hooks: []
post_hooks: []
output_file: None
output_dir: None
output_ext: .fits
output_use_model: False
output_use_index: True
save_results: False
skip: False
suffix: None
search_output_file: True
input_dir: ''
nsclean:
pre_hooks: []
post_hooks: []
output_file: None
output_dir: None
output_ext: .fits
output_use_model: False
output_use_index: True
save_results: True
skip: False
suffix: None
search_output_file: True
input_dir: ''
fit_method: fft
fit_by_channel: False
background_method: None
background_box_size: None
mask_spectral_regions: True
n_sigma: 5.0
fit_histogram: False
single_mask: False
user_mask: None
save_mask: True
save_background: False
save_noise: False
bkg_subtract:
pre_hooks: []
post_hooks: []
output_file: None
output_dir: None
output_ext: .fits
output_use_model: False
output_use_index: True
save_results: False
skip: False
suffix: None
search_output_file: True
input_dir: ''
bkg_list: None
save_combined_background: False
sigma: 3.0
maxiters: None
soss_source_percentile: 35.0
soss_bkg_percentile: None
wfss_mmag_extract: None
wfss_maxiter: 5
wfss_rms_stop: 0.0
wfss_outlier_percent: 1.0
imprint_subtract:
pre_hooks: []
post_hooks: []
output_file: None
output_dir: None
output_ext: .fits
output_use_model: False
output_use_index: True
save_results: False
skip: False
suffix: None
search_output_file: True
input_dir: ''
extract_2d:
pre_hooks: []
post_hooks: []
output_file: None
output_dir: None
output_ext: .fits
output_use_model: False
output_use_index: True
save_results: False
skip: False
suffix: None
search_output_file: True
input_dir: ''
slit_names:
- '11'
source_ids: None
extract_orders: None
grism_objects: None
tsgrism_extract_height: None
wfss_extract_half_height: 5
wfss_mmag_extract: None
wfss_nbright: 1000
master_background_mos:
pre_hooks: []
post_hooks: []
output_file: None
output_dir: None
output_ext: .fits
output_use_model: True
output_use_index: True
save_results: False
skip: False
suffix: None
search_output_file: True
input_dir: ''
sigma_clip: 3.0
median_kernel: 1
force_subtract: False
save_background: False
user_background: None
inverse: False
steps:
flat_field:
pre_hooks: []
post_hooks: []
output_file: None
output_dir: None
output_ext: .fits
output_use_model: False
output_use_index: True
save_results: False
skip: False
suffix: None
search_output_file: True
input_dir: ''
save_interpolated_flat: False
user_supplied_flat: None
inverse: False
pathloss:
pre_hooks: []
post_hooks: []
output_file: None
output_dir: None
output_ext: .fits
output_use_model: False
output_use_index: True
save_results: False
skip: False
suffix: None
search_output_file: True
input_dir: ''
inverse: False
source_type: None
user_slit_loc: None
barshadow:
pre_hooks: []
post_hooks: []
output_file: None
output_dir: None
output_ext: .fits
output_use_model: False
output_use_index: True
save_results: False
skip: False
suffix: None
search_output_file: True
input_dir: ''
inverse: False
source_type: None
photom:
pre_hooks: []
post_hooks: []
output_file: None
output_dir: None
output_ext: .fits
output_use_model: False
output_use_index: True
save_results: False
skip: False
suffix: None
search_output_file: True
input_dir: ''
inverse: False
source_type: None
apply_time_correction: True
pixel_replace:
pre_hooks: []
post_hooks: []
output_file: None
output_dir: None
output_ext: .fits
output_use_model: True
output_use_index: True
save_results: False
skip: True
suffix: None
search_output_file: True
input_dir: ''
algorithm: fit_profile
n_adjacent_cols: 3
resample_spec:
pre_hooks: []
post_hooks: []
output_file: None
output_dir: None
output_ext: .fits
output_use_model: False
output_use_index: True
save_results: False
skip: False
suffix: None
search_output_file: True
input_dir: ''
pixfrac: 1.0
kernel: square
fillval: NaN
weight_type: exptime
output_shape: None
pixel_scale_ratio: 1.0
pixel_scale: None
output_wcs: ''
single: False
blendheaders: True
in_memory: True
extract_1d:
pre_hooks: []
post_hooks: []
output_file: None
output_dir: None
output_ext: .fits
output_use_model: False
output_use_index: True
save_results: False
skip: False
suffix: None
search_output_file: True
input_dir: ''
subtract_background: None
apply_apcorr: True
extraction_type: box
use_source_posn: None
position_offset: 0.0
model_nod_pair: True
optimize_psf_location: True
smoothing_length: None
bkg_fit: None
bkg_order: None
log_increment: 50
save_profile: False
save_scene_model: False
save_residual_image: False
center_xy: None
ifu_autocen: False
bkg_sigma_clip: 3.0
ifu_rfcorr: True
ifu_set_srctype: None
ifu_rscale: None
ifu_covar_scale: 1.0
soss_atoca: True
soss_threshold: 0.01
soss_n_os: 2
soss_wave_grid_in: None
soss_wave_grid_out: None
soss_estimate: None
soss_rtol: 0.0001
soss_max_grid_size: 20000
soss_tikfac: None
soss_width: 40.0
soss_bad_pix: masking
soss_modelname: None
soss_order_3: True
wavecorr:
pre_hooks: []
post_hooks: []
output_file: None
output_dir: None
output_ext: .fits
output_use_model: False
output_use_index: True
save_results: False
skip: False
suffix: None
search_output_file: True
input_dir: ''
flat_field:
pre_hooks: []
post_hooks: []
output_file: None
output_dir: None
output_ext: .fits
output_use_model: False
output_use_index: True
save_results: False
skip: False
suffix: None
search_output_file: True
input_dir: ''
save_interpolated_flat: False
user_supplied_flat: None
inverse: False
srctype:
pre_hooks: []
post_hooks: []
output_file: None
output_dir: None
output_ext: .fits
output_use_model: False
output_use_index: True
save_results: False
skip: False
suffix: None
search_output_file: True
input_dir: ''
source_type: None
straylight:
pre_hooks: []
post_hooks: []
output_file: None
output_dir: None
output_ext: .fits
output_use_model: False
output_use_index: True
save_results: False
skip: False
suffix: None
search_output_file: True
input_dir: ''
clean_showers: False
shower_plane: 3
shower_x_stddev: 18.0
shower_y_stddev: 5.0
shower_low_reject: 0.1
shower_high_reject: 99.9
save_shower_model: False
fringe:
pre_hooks: []
post_hooks: []
output_file: None
output_dir: None
output_ext: .fits
output_use_model: False
output_use_index: True
save_results: False
skip: False
suffix: None
search_output_file: True
input_dir: ''
residual_fringe:
pre_hooks: []
post_hooks: []
output_file: None
output_dir: None
output_ext: .fits
output_use_model: False
output_use_index: True
save_results: False
skip: True
suffix: residual_fringe
search_output_file: False
input_dir: ''
save_intermediate_results: False
ignore_region_min: None
ignore_region_max: None
pathloss:
pre_hooks: []
post_hooks: []
output_file: None
output_dir: None
output_ext: .fits
output_use_model: False
output_use_index: True
save_results: False
skip: False
suffix: None
search_output_file: True
input_dir: ''
inverse: False
source_type: None
user_slit_loc: None
barshadow:
pre_hooks: []
post_hooks: []
output_file: None
output_dir: None
output_ext: .fits
output_use_model: False
output_use_index: True
save_results: False
skip: False
suffix: None
search_output_file: True
input_dir: ''
inverse: False
source_type: None
wfss_contam:
pre_hooks: []
post_hooks: []
output_file: None
output_dir: None
output_ext: .fits
output_use_model: False
output_use_index: True
save_results: False
skip: True
suffix: None
search_output_file: True
input_dir: ''
save_simulated_image: False
save_contam_images: False
maximum_cores: none
orders: None
magnitude_limit: None
wl_oversample: 2
max_pixels_per_chunk: 50000
photom:
pre_hooks: []
post_hooks: []
output_file: None
output_dir: None
output_ext: .fits
output_use_model: False
output_use_index: True
save_results: False
skip: False
suffix: None
search_output_file: True
input_dir: ''
inverse: False
source_type: None
apply_time_correction: True
pixel_replace:
pre_hooks: []
post_hooks: []
output_file: None
output_dir: None
output_ext: .fits
output_use_model: True
output_use_index: True
save_results: False
skip: True
suffix: None
search_output_file: True
input_dir: ''
algorithm: fit_profile
n_adjacent_cols: 3
resample_spec:
pre_hooks: []
post_hooks: []
output_file: None
output_dir: None
output_ext: .fits
output_use_model: False
output_use_index: True
save_results: False
skip: False
suffix: None
search_output_file: True
input_dir: ''
pixfrac: 1.0
kernel: square
fillval: NaN
weight_type: exptime
output_shape: None
pixel_scale_ratio: 1.0
pixel_scale: None
output_wcs: ''
single: False
blendheaders: True
in_memory: True
cube_build:
pre_hooks: []
post_hooks: []
output_file: None
output_dir: None
output_ext: .fits
output_use_model: True
output_use_index: True
save_results: False
skip: False
suffix: s3d
search_output_file: False
input_dir: ''
pipeline: 3
channel: all
band: all
grating: all
filter: all
output_type: None
scalexy: 0.0
scalew: 0.0
weighting: drizzle
coord_system: skyalign
ra_center: None
dec_center: None
cube_pa: None
nspax_x: None
nspax_y: None
rois: 0.0
roiw: 0.0
weight_power: 2.0
wavemin: None
wavemax: None
single: False
skip_dqflagging: False
offset_file: None
debug_spaxel: -1 -1 -1
extract_1d:
pre_hooks: []
post_hooks: []
output_file: None
output_dir: None
output_ext: .fits
output_use_model: False
output_use_index: True
save_results: False
skip: False
suffix: None
search_output_file: True
input_dir: ''
subtract_background: None
apply_apcorr: True
extraction_type: box
use_source_posn: None
position_offset: 0.0
model_nod_pair: True
optimize_psf_location: True
smoothing_length: None
bkg_fit: None
bkg_order: None
log_increment: 50
save_profile: False
save_scene_model: False
save_residual_image: False
center_xy: None
ifu_autocen: False
bkg_sigma_clip: 3.0
ifu_rfcorr: True
ifu_set_srctype: None
ifu_rscale: None
ifu_covar_scale: 1.0
soss_atoca: True
soss_threshold: 0.01
soss_n_os: 2
soss_wave_grid_in: None
soss_wave_grid_out: None
soss_estimate: None
soss_rtol: 0.0001
soss_max_grid_size: 20000
soss_tikfac: None
soss_width: 40.0
soss_bad_pix: masking
soss_modelname: None
soss_order_3: True
2026-04-22 19:09:25,542 - stpipe.pipeline - INFO - Prefetching reference files for dataset: 'jw01345061001_07101_00003_nrs2_rate.fits' reftypes = ['apcorr', 'area', 'barshadow', 'bkg', 'camera', 'collimator', 'cubepar', 'dflat', 'disperser', 'distortion', 'extract1d', 'fflat', 'filteroffset', 'flat', 'fore', 'fpa', 'fringe', 'ifufore', 'ifupost', 'ifuslicer', 'mrsxartcorr', 'msa', 'msaoper', 'ote', 'pastasoss', 'pathloss', 'photom', 'psf', 'regions', 'sflat', 'speckernel', 'specprofile', 'specwcs', 'wavecorr', 'wavelengthrange']
2026-04-22 19:09:25,547 - stpipe.pipeline - INFO - Prefetch for APCORR reference file is '/home/runner/crds_cache/references/jwst/nirspec/jwst_nirspec_apcorr_0004.fits'.
2026-04-22 19:09:25,548 - stpipe.pipeline - INFO - Prefetch for AREA reference file is '/home/runner/crds_cache/references/jwst/nirspec/jwst_nirspec_area_0051.fits'.
2026-04-22 19:09:25,548 - stpipe.pipeline - INFO - Prefetch for BARSHADOW reference file is '/home/runner/crds_cache/references/jwst/nirspec/jwst_nirspec_barshadow_0008.fits'.
2026-04-22 19:09:25,549 - stpipe.pipeline - INFO - Prefetch for BKG reference file is 'N/A'.
2026-04-22 19:09:25,549 - stpipe.pipeline - INFO - Prefetch for CAMERA reference file is '/home/runner/crds_cache/references/jwst/nirspec/jwst_nirspec_camera_0008.asdf'.
2026-04-22 19:09:25,550 - stpipe.pipeline - INFO - Prefetch for COLLIMATOR reference file is '/home/runner/crds_cache/references/jwst/nirspec/jwst_nirspec_collimator_0008.asdf'.
2026-04-22 19:09:25,551 - stpipe.pipeline - INFO - Prefetch for CUBEPAR reference file is 'N/A'.
2026-04-22 19:09:25,551 - stpipe.pipeline - INFO - Prefetch for DFLAT reference file is '/home/runner/crds_cache/references/jwst/nirspec/jwst_nirspec_dflat_0002.fits'.
2026-04-22 19:09:25,552 - stpipe.pipeline - INFO - Prefetch for DISPERSER reference file is '/home/runner/crds_cache/references/jwst/nirspec/jwst_nirspec_disperser_0068.asdf'.
2026-04-22 19:09:25,552 - stpipe.pipeline - INFO - Prefetch for DISTORTION reference file is 'N/A'.
2026-04-22 19:09:25,553 - stpipe.pipeline - INFO - Prefetch for EXTRACT1D reference file is '/home/runner/crds_cache/references/jwst/nirspec/jwst_nirspec_extract1d_0009.json'.
2026-04-22 19:09:25,554 - stpipe.pipeline - INFO - Prefetch for FFLAT reference file is '/home/runner/crds_cache/references/jwst/nirspec/jwst_nirspec_fflat_0167.fits'.
2026-04-22 19:09:25,554 - stpipe.pipeline - INFO - Prefetch for FILTEROFFSET reference file is 'N/A'.
2026-04-22 19:09:25,555 - stpipe.pipeline - INFO - Prefetch for FLAT reference file is 'N/A'.
2026-04-22 19:09:25,555 - stpipe.pipeline - INFO - Prefetch for FORE reference file is '/home/runner/crds_cache/references/jwst/nirspec/jwst_nirspec_fore_0051.asdf'.
2026-04-22 19:09:25,556 - stpipe.pipeline - INFO - Prefetch for FPA reference file is '/home/runner/crds_cache/references/jwst/nirspec/jwst_nirspec_fpa_0009.asdf'.
2026-04-22 19:09:25,556 - stpipe.pipeline - INFO - Prefetch for FRINGE reference file is 'N/A'.
2026-04-22 19:09:25,557 - stpipe.pipeline - INFO - Prefetch for IFUFORE reference file is 'N/A'.
2026-04-22 19:09:25,557 - stpipe.pipeline - INFO - Prefetch for IFUPOST reference file is 'N/A'.
2026-04-22 19:09:25,558 - stpipe.pipeline - INFO - Prefetch for IFUSLICER reference file is 'N/A'.
2026-04-22 19:09:25,558 - stpipe.pipeline - INFO - Prefetch for MRSXARTCORR reference file is 'N/A'.
2026-04-22 19:09:25,559 - stpipe.pipeline - INFO - Prefetch for MSA reference file is '/home/runner/crds_cache/references/jwst/nirspec/jwst_nirspec_msa_0009.asdf'.
2026-04-22 19:09:25,559 - stpipe.pipeline - INFO - Prefetch for MSAOPER reference file is '/home/runner/crds_cache/references/jwst/nirspec/jwst_nirspec_msaoper_0006.json'.
2026-04-22 19:09:25,560 - stpipe.pipeline - INFO - Prefetch for OTE reference file is '/home/runner/crds_cache/references/jwst/nirspec/jwst_nirspec_ote_0011.asdf'.
2026-04-22 19:09:25,561 - stpipe.pipeline - INFO - Prefetch for PASTASOSS reference file is 'N/A'.
2026-04-22 19:09:25,561 - stpipe.pipeline - INFO - Prefetch for PATHLOSS reference file is '/home/runner/crds_cache/references/jwst/nirspec/jwst_nirspec_pathloss_0010.fits'.
2026-04-22 19:09:25,562 - stpipe.pipeline - INFO - Prefetch for PHOTOM reference file is '/home/runner/crds_cache/references/jwst/nirspec/jwst_nirspec_photom_0015.fits'.
2026-04-22 19:09:25,562 - stpipe.pipeline - INFO - Prefetch for PSF reference file is 'N/A'.
2026-04-22 19:09:25,563 - stpipe.pipeline - INFO - Prefetch for REGIONS reference file is 'N/A'.
2026-04-22 19:09:25,563 - stpipe.pipeline - INFO - Prefetch for SFLAT reference file is '/home/runner/crds_cache/references/jwst/nirspec/jwst_nirspec_sflat_0232.fits'.
2026-04-22 19:09:25,564 - stpipe.pipeline - INFO - Prefetch for SPECKERNEL reference file is 'N/A'.
2026-04-22 19:09:25,564 - stpipe.pipeline - INFO - Prefetch for SPECPROFILE reference file is 'N/A'.
2026-04-22 19:09:25,565 - stpipe.pipeline - INFO - Prefetch for SPECWCS reference file is 'N/A'.
2026-04-22 19:09:25,565 - stpipe.pipeline - INFO - Prefetch for WAVECORR reference file is '/home/runner/crds_cache/references/jwst/nirspec/jwst_nirspec_wavecorr_0004.asdf'.
2026-04-22 19:09:25,566 - stpipe.pipeline - INFO - Prefetch for WAVELENGTHRANGE reference file is '/home/runner/crds_cache/references/jwst/nirspec/jwst_nirspec_wavelengthrange_0006.asdf'.
2026-04-22 19:09:25,567 - jwst.pipeline.calwebb_spec2 - INFO - Starting calwebb_spec2 ...
2026-04-22 19:09:25,567 - jwst.pipeline.calwebb_spec2 - INFO - Processing product mast_products/jw01345061001_07101_00003_nrs2
2026-04-22 19:09:25,568 - jwst.pipeline.calwebb_spec2 - INFO - Working on input ./mast_products/jw01345061001_07101_00003_nrs2_rate.fits ...
2026-04-22 19:09:25,796 - stpipe.step - INFO - Step assign_wcs running with args (<ImageModel(2048, 2048) from jw01345061001_07101_00003_nrs2_rate.fits>,).
2026-04-22 19:09:25,890 - jwst.assign_wcs.nirspec - INFO - Retrieving open MSA slitlets for msa_metadata_id = 83 and dither_index = 3
2026-04-22 19:09:25,899 - jwst.assign_wcs.nirspec - INFO - Slitlet 3 is background only; assigned source_id=3
2026-04-22 19:09:25,900 - jwst.assign_wcs.nirspec - INFO - Slitlet 4 is background only; assigned source_id=4
2026-04-22 19:09:25,900 - jwst.assign_wcs.nirspec - INFO - Slitlet 5 is background only; assigned source_id=5
2026-04-22 19:09:25,908 - jwst.assign_wcs.nirspec - INFO - Slitlet 9 is background only; assigned source_id=9
2026-04-22 19:09:25,910 - jwst.assign_wcs.nirspec - INFO - Slitlet 10 contains virtual source, with source_id=-59
2026-04-22 19:09:25,913 - jwst.assign_wcs.nirspec - INFO - Slitlet 12 is background only; assigned source_id=12
2026-04-22 19:09:25,914 - jwst.assign_wcs.nirspec - INFO - Slitlet 13 is background only; assigned source_id=13
2026-04-22 19:09:25,915 - jwst.assign_wcs.nirspec - INFO - Slitlet 14 is background only; assigned source_id=14
2026-04-22 19:09:25,918 - jwst.assign_wcs.nirspec - INFO - Slitlet 15 contains virtual source, with source_id=-63
2026-04-22 19:09:25,923 - jwst.assign_wcs.nirspec - INFO - Slitlet 18 is background only; assigned source_id=18
2026-04-22 19:09:25,924 - jwst.assign_wcs.nirspec - INFO - Slitlet 19 is background only; assigned source_id=19
2026-04-22 19:09:25,931 - jwst.assign_wcs.nirspec - INFO - Slitlet 23 is background only; assigned source_id=23
2026-04-22 19:09:25,939 - jwst.assign_wcs.nirspec - INFO - Slitlet 27 is background only; assigned source_id=27
2026-04-22 19:09:25,939 - jwst.assign_wcs.nirspec - INFO - Slitlet 28 is background only; assigned source_id=28
2026-04-22 19:09:25,951 - jwst.assign_wcs.nirspec - INFO - Slitlet 34 is background only; assigned source_id=34
2026-04-22 19:09:25,979 - jwst.assign_wcs.nirspec - INFO - Slitlet 48 is background only; assigned source_id=48
2026-04-22 19:09:25,992 - jwst.assign_wcs.nirspec - INFO - Slitlet 55 is background only; assigned source_id=55
2026-04-22 19:09:25,997 - jwst.assign_wcs.nirspec - INFO - Slitlet 57 contains virtual source, with source_id=-72
2026-04-22 19:09:26,006 - jwst.assign_wcs.nirspec - INFO - Slitlet 62 is background only; assigned source_id=62
2026-04-22 19:09:26,011 - jwst.assign_wcs.nirspec - INFO - Slitlet 64 contains virtual source, with source_id=-74
2026-04-22 19:09:26,016 - jwst.assign_wcs.nirspec - INFO - Slitlet 67 is background only; assigned source_id=67
2026-04-22 19:09:26,017 - jwst.assign_wcs.nirspec - INFO - Slitlet 68 is background only; assigned source_id=68
2026-04-22 19:09:26,020 - jwst.assign_wcs.nirspec - INFO - Slitlet 69 contains virtual source, with source_id=-77
2026-04-22 19:09:26,021 - jwst.assign_wcs.nirspec - INFO - Slitlet 70 is background only; assigned source_id=70
2026-04-22 19:09:26,022 - jwst.assign_wcs.nirspec - INFO - Slitlet 71 is background only; assigned source_id=71
2026-04-22 19:09:26,027 - jwst.assign_wcs.nirspec - INFO - Slitlet 74 is background only; assigned source_id=74
2026-04-22 19:09:26,034 - jwst.assign_wcs.nirspec - INFO - Slitlet 78 is background only; assigned source_id=78
2026-04-22 19:09:26,066 - jwst.assign_wcs.nirspec - INFO - gwa_ytilt is 0.177384809 deg
2026-04-22 19:09:26,066 - jwst.assign_wcs.nirspec - INFO - gwa_xtilt is 0.278486848 deg
2026-04-22 19:09:26,067 - jwst.assign_wcs.nirspec - INFO - theta_y correction: 0.0057073669713260085 deg
2026-04-22 19:09:26,068 - jwst.assign_wcs.nirspec - INFO - theta_x correction: 7.258633810078802e-05 deg
2026-04-22 19:09:27,012 - jwst.assign_wcs.nirspec - INFO - Removing slit 58 from the list of open slits because the WCS bounding_box is completely outside the detector.
2026-04-22 19:09:27,029 - jwst.assign_wcs.nirspec - INFO - Removing slit 59 from the list of open slits because the WCS bounding_box is completely outside the detector.
2026-04-22 19:09:27,045 - jwst.assign_wcs.nirspec - INFO - Removing slit 60 from the list of open slits because the WCS bounding_box is completely outside the detector.
2026-04-22 19:09:27,061 - jwst.assign_wcs.nirspec - INFO - Removing slit 61 from the list of open slits because the WCS bounding_box is completely outside the detector.
2026-04-22 19:09:27,076 - jwst.assign_wcs.nirspec - INFO - Removing slit 62 from the list of open slits because the WCS bounding_box is completely outside the detector.
2026-04-22 19:09:27,092 - jwst.assign_wcs.nirspec - INFO - Removing slit 65 from the list of open slits because the WCS bounding_box is completely outside the detector.
2026-04-22 19:09:27,108 - jwst.assign_wcs.nirspec - INFO - Removing slit 66 from the list of open slits because the WCS bounding_box is completely outside the detector.
2026-04-22 19:09:27,125 - jwst.assign_wcs.nirspec - INFO - Removing slit 68 from the list of open slits because the WCS bounding_box is completely outside the detector.
2026-04-22 19:09:27,140 - jwst.assign_wcs.nirspec - INFO - Removing slit 69 from the list of open slits because the WCS bounding_box is completely outside the detector.
2026-04-22 19:09:27,156 - jwst.assign_wcs.nirspec - INFO - Removing slit 70 from the list of open slits because the WCS bounding_box is completely outside the detector.
2026-04-22 19:09:27,172 - jwst.assign_wcs.nirspec - INFO - Removing slit 76 from the list of open slits because the WCS bounding_box is completely outside the detector.
2026-04-22 19:09:27,189 - jwst.assign_wcs.nirspec - INFO - Removing slit 78 from the list of open slits because the WCS bounding_box is completely outside the detector.
2026-04-22 19:09:27,250 - jwst.assign_wcs.nirspec - INFO - Removing slit 57 from the list of open slits because the WCS bounding_box is completely outside the detector.
2026-04-22 19:09:27,266 - jwst.assign_wcs.nirspec - INFO - Removing slit 63 from the list of open slits because the WCS bounding_box is completely outside the detector.
2026-04-22 19:09:27,282 - jwst.assign_wcs.nirspec - INFO - Removing slit 64 from the list of open slits because the WCS bounding_box is completely outside the detector.
2026-04-22 19:09:27,298 - jwst.assign_wcs.nirspec - INFO - Removing slit 67 from the list of open slits because the WCS bounding_box is completely outside the detector.
2026-04-22 19:09:27,314 - jwst.assign_wcs.nirspec - INFO - Removing slit 71 from the list of open slits because the WCS bounding_box is completely outside the detector.
2026-04-22 19:09:27,330 - jwst.assign_wcs.nirspec - INFO - Removing slit 72 from the list of open slits because the WCS bounding_box is completely outside the detector.
2026-04-22 19:09:27,346 - jwst.assign_wcs.nirspec - INFO - Removing slit 73 from the list of open slits because the WCS bounding_box is completely outside the detector.
2026-04-22 19:09:27,362 - jwst.assign_wcs.nirspec - INFO - Removing slit 74 from the list of open slits because the WCS bounding_box is completely outside the detector.
2026-04-22 19:09:27,379 - jwst.assign_wcs.nirspec - INFO - Removing slit 75 from the list of open slits because the WCS bounding_box is completely outside the detector.
2026-04-22 19:09:27,395 - jwst.assign_wcs.nirspec - INFO - Removing slit 77 from the list of open slits because the WCS bounding_box is completely outside the detector.
2026-04-22 19:09:27,411 - jwst.assign_wcs.nirspec - INFO - Removing slit 79 from the list of open slits because the WCS bounding_box is completely outside the detector.
2026-04-22 19:09:27,427 - jwst.assign_wcs.nirspec - INFO - Removing slit 80 from the list of open slits because the WCS bounding_box is completely outside the detector.
2026-04-22 19:09:27,445 - jwst.assign_wcs.nirspec - INFO - Removing slit 81 from the list of open slits because the WCS bounding_box is completely outside the detector.
2026-04-22 19:09:27,446 - jwst.assign_wcs.nirspec - INFO - Slits projected on detector NRS2: ['2', '3', '4', '5', '6', '7', '8', '9', '10', '11', '12', '13', '14', '15', '16', '17', '18', '19', '20', '21', '22', '23', '24', '25', '26', '27', '28', '29', '30', '31', '32', '33', '34', '35', '36', '37', '38', '39', '40', '41', '42', '43', '44', '45', '46', '47', '48', '49', '50', '51', '52', '53', '54', '55', '56']
2026-04-22 19:09:27,447 - jwst.assign_wcs.nirspec - INFO - Computing WCS for 55 open slitlets
2026-04-22 19:09:27,469 - jwst.assign_wcs.nirspec - INFO - gwa_ytilt is 0.177384809 deg
2026-04-22 19:09:27,470 - jwst.assign_wcs.nirspec - INFO - gwa_xtilt is 0.278486848 deg
2026-04-22 19:09:27,471 - jwst.assign_wcs.nirspec - INFO - theta_y correction: 0.0057073669713260085 deg
2026-04-22 19:09:27,472 - jwst.assign_wcs.nirspec - INFO - theta_x correction: 7.258633810078802e-05 deg
2026-04-22 19:09:27,482 - jwst.assign_wcs.nirspec - INFO - SPORDER= -1, wrange=[2.87e-06, 5.27e-06]
2026-04-22 19:09:27,572 - jwst.assign_wcs.nirspec - INFO - Applied Barycentric velocity correction : 1.000049924895689
2026-04-22 19:09:27,599 - jwst.assign_wcs.nirspec - INFO - There are 18 open slits in quadrant 1
2026-04-22 19:09:27,705 - jwst.assign_wcs.nirspec - INFO - There are 26 open slits in quadrant 2
2026-04-22 19:09:28,086 - jwst.assign_wcs.nirspec - INFO - There are 8 open slits in quadrant 3
2026-04-22 19:09:28,133 - jwst.assign_wcs.nirspec - INFO - There are 3 open slits in quadrant 4
2026-04-22 19:09:28,152 - jwst.assign_wcs.nirspec - INFO - There are 0 open slits in quadrant 5
2026-04-22 19:09:28,304 - jwst.assign_wcs.nirspec - INFO - Created a NIRSPEC nrs_msaspec pipeline with references {'distortion': None, 'filteroffset': None, 'specwcs': None, 'regions': None, 'wavelengthrange': '/home/runner/crds_cache/references/jwst/nirspec/jwst_nirspec_wavelengthrange_0006.asdf', 'camera': '/home/runner/crds_cache/references/jwst/nirspec/jwst_nirspec_camera_0008.asdf', 'collimator': '/home/runner/crds_cache/references/jwst/nirspec/jwst_nirspec_collimator_0008.asdf', 'disperser': '/home/runner/crds_cache/references/jwst/nirspec/jwst_nirspec_disperser_0068.asdf', 'fore': '/home/runner/crds_cache/references/jwst/nirspec/jwst_nirspec_fore_0051.asdf', 'fpa': '/home/runner/crds_cache/references/jwst/nirspec/jwst_nirspec_fpa_0009.asdf', 'msa': '/home/runner/crds_cache/references/jwst/nirspec/jwst_nirspec_msa_0009.asdf', 'ote': '/home/runner/crds_cache/references/jwst/nirspec/jwst_nirspec_ote_0011.asdf', 'ifupost': None, 'ifufore': None, 'ifuslicer': None, 'msametafile': './mast_products/jw01345061001_01_msa.fits'}
2026-04-22 19:09:31,099 - jwst.assign_wcs.assign_wcs - INFO - COMPLETED assign_wcs
2026-04-22 19:09:31,106 - stpipe.step - INFO - Step assign_wcs done
2026-04-22 19:09:31,379 - stpipe.step - INFO - Step badpix_selfcal running with args (<ImageModel(2048, 2048) from jw01345061001_07101_00003_nrs2_rate.fits>, [], []).
2026-04-22 19:09:31,381 - stpipe.step - INFO - Step skipped.
2026-04-22 19:09:31,626 - stpipe.step - INFO - Step msa_flagging running with args (<ImageModel(2048, 2048) from jw01345061001_07101_00003_nrs2_rate.fits>,).
2026-04-22 19:09:32,916 - jwst.msaflagopen.msaflagopen_step - INFO - Using reference file /home/runner/crds_cache/references/jwst/nirspec/jwst_nirspec_msaoper_0006.json
2026-04-22 19:09:32,988 - jwst.msaflagopen.msaflag_open - INFO - 24 failed open shutters
2026-04-22 19:09:37,581 - stpipe.step - INFO - Step msa_flagging done
2026-04-22 19:09:37,987 - stpipe.step - INFO - Step nsclean running with args (<ImageModel(2048, 2048) from jw01345061001_07101_00003_nrs2_rate.fits>,).
2026-04-22 19:09:37,989 - jwst.nsclean.nsclean_step - WARNING - The 'nsclean' step is a deprecated alias to 'clean_flicker_noise' and will be removed in future builds.
2026-04-22 19:09:37,995 - jwst.clean_flicker_noise.clean_flicker_noise - INFO - Input exposure type is NRS_MSASPEC, detector=NRS2
2026-04-22 19:09:39,044 - jwst.clean_flicker_noise.clean_flicker_noise - INFO - Flagging failed-open MSA shutters for scene masking
2026-04-22 19:09:39,045 - stpipe.step - INFO - MSAFlagOpenStep instance created.
2026-04-22 19:09:45,577 - jwst.clean_flicker_noise.clean_flicker_noise - INFO - Creating mask
2026-04-22 19:09:45,578 - jwst.clean_flicker_noise.clean_flicker_noise - INFO - Finding slit/slitlet pixels
2026-04-22 19:09:49,130 - jwst.clean_flicker_noise.clean_flicker_noise - INFO - Masking the fixed slit region for MOS data.
2026-04-22 19:09:49,440 - jwst.clean_flicker_noise.clean_flicker_noise - INFO - Cleaning image jw01345061001_07101_00003_nrs2_rate.fits
2026-04-22 19:09:51,347 - jwst.nsclean.nsclean_step - INFO - Saving mask file ./stage2_nsclean_default/jw01345061001_07101_00003_nrs2_mask.fits
2026-04-22 19:09:52,624 - stpipe.step - INFO - Saved model in ./stage2_nsclean_default/jw01345061001_07101_00003_nrs2_nsclean.fits
2026-04-22 19:09:52,625 - stpipe.step - INFO - Step nsclean done
2026-04-22 19:09:53,171 - stpipe.step - INFO - Step imprint_subtract running with args (<ImageModel(2048, 2048) from jw01345061001_07101_00003_nrs2_nsclean.fits>, []).
2026-04-22 19:09:53,172 - stpipe.step - INFO - Step skipped.
2026-04-22 19:09:53,486 - stpipe.step - INFO - Step bkg_subtract running with args (<ImageModel(2048, 2048) from jw01345061001_07101_00003_nrs2_nsclean.fits>, []).
2026-04-22 19:09:53,487 - stpipe.step - INFO - Step skipped.
2026-04-22 19:09:53,802 - stpipe.step - INFO - Step extract_2d running with args (<ImageModel(2048, 2048) from jw01345061001_07101_00003_nrs2_nsclean.fits>,).
2026-04-22 19:09:53,808 - jwst.extract_2d.extract_2d - INFO - EXP_TYPE is NRS_MSASPEC
2026-04-22 19:09:53,809 - jwst.extract_2d.nirspec - INFO - Slits selected:
2026-04-22 19:09:53,809 - jwst.extract_2d.nirspec - INFO - Name: 11, source_id: 386
2026-04-22 19:09:53,873 - jwst.extract_2d.nirspec - INFO - Name of subarray extracted: 11
2026-04-22 19:09:53,874 - jwst.extract_2d.nirspec - INFO - Subarray x-extents are: 141 1507
2026-04-22 19:09:53,874 - jwst.extract_2d.nirspec - INFO - Subarray y-extents are: 616 648
2026-04-22 19:09:54,132 - jwst.extract_2d.nirspec - INFO - set slit_attributes completed
2026-04-22 19:09:54,140 - stcal.alignment.util - INFO - Update S_REGION to POLYGON ICRS 214.832940199 52.885103324 214.832013460 52.885093088 214.832014161 52.885038573 214.832940897 52.885048802
2026-04-22 19:09:54,141 - jwst.extract_2d.nirspec - INFO - Updated S_REGION to POLYGON ICRS 214.832940199 52.885103324 214.832013460 52.885093088 214.832014161 52.885038573 214.832940897 52.885048802
2026-04-22 19:09:54,208 - stpipe.step - INFO - Step extract_2d done
2026-04-22 19:09:54,536 - stpipe.step - INFO - Step srctype running with args (<MultiSlitModel from jw01345061001_07101_00003_nrs2_nsclean.fits>,).
2026-04-22 19:09:54,695 - jwst.srctype.srctype - INFO - Input EXP_TYPE is NRS_MSASPEC
2026-04-22 19:09:54,696 - jwst.srctype.srctype - INFO - source_id=386, stellarity=1.0000, type=POINT
2026-04-22 19:09:54,698 - stpipe.step - INFO - Step srctype done
2026-04-22 19:09:55,188 - stpipe.step - INFO - Step master_background_mos running with args (<MultiSlitModel from jw01345061001_07101_00003_nrs2_nsclean.fits>,).
2026-04-22 19:09:55,194 - jwst.master_background.master_background_mos_step - WARNING - No background slits available for creating master background. Skipping
2026-04-22 19:09:55,369 - jwst.stpipe.core - INFO - Results used CRDS context: jwst_1464.pmap
2026-04-22 19:09:55,370 - stpipe.step - INFO - Step master_background_mos done
2026-04-22 19:09:55,719 - stpipe.step - INFO - Step wavecorr running with args (<MultiSlitModel from jw01345061001_07101_00003_nrs2_nsclean.fits>,).
2026-04-22 19:09:55,935 - jwst.wavecorr.wavecorr_step - INFO - Using WAVECORR reference file /home/runner/crds_cache/references/jwst/nirspec/jwst_nirspec_wavecorr_0004.asdf
2026-04-22 19:09:55,936 - jwst.wavecorr.wavecorr - INFO - Detected a POINT source type in slit 11
2026-04-22 19:09:56,015 - jwst.wavecorr.wavecorr - INFO - Using wavelength zero-point correction for aperture MOS
2026-04-22 19:09:56,057 - stpipe.step - INFO - Step wavecorr done
2026-04-22 19:09:56,409 - stpipe.step - INFO - Step flat_field running with args (<MultiSlitModel from jw01345061001_07101_00003_nrs2_nsclean.fits>,).
2026-04-22 19:09:56,436 - jwst.flatfield.flat_field_step - INFO - No reference found for type FLAT
2026-04-22 19:09:56,589 - jwst.flatfield.flat_field_step - INFO - Using FFLAT reference file: /home/runner/crds_cache/references/jwst/nirspec/jwst_nirspec_fflat_0167.fits
2026-04-22 19:09:57,066 - jwst.flatfield.flat_field_step - INFO - Using SFLAT reference file: /home/runner/crds_cache/references/jwst/nirspec/jwst_nirspec_sflat_0232.fits
2026-04-22 19:09:57,207 - jwst.flatfield.flat_field_step - INFO - Using DFLAT reference file: /home/runner/crds_cache/references/jwst/nirspec/jwst_nirspec_dflat_0002.fits
2026-04-22 19:09:57,359 - jwst.flatfield.flat_field - INFO - Working on slit 11
2026-04-22 19:09:57,744 - stpipe.step - INFO - Step flat_field done
2026-04-22 19:09:58,098 - stpipe.step - INFO - Step pathloss running with args (<MultiSlitModel from jw01345061001_07101_00003_nrs2_nsclean.fits>,).
2026-04-22 19:09:58,111 - jwst.pathloss.pathloss_step - INFO - Using PATHLOSS reference file /home/runner/crds_cache/references/jwst/nirspec/jwst_nirspec_pathloss_0010.fits
2026-04-22 19:09:58,171 - jwst.pathloss.pathloss - INFO - Input exposure type is NRS_MSASPEC
2026-04-22 19:09:58,331 - jwst.pathloss.pathloss - INFO - Working on slit 0
2026-04-22 19:09:58,332 - jwst.pathloss.pathloss - INFO - Shutter state = 11x, using MOS1x3 entry in ref file
2026-04-22 19:09:58,332 - jwst.pathloss.pathloss - INFO - Shutter above fiducial is closed, using upper region of pathloss array
2026-04-22 19:09:58,401 - stpipe.step - INFO - Step pathloss done
2026-04-22 19:09:58,753 - stpipe.step - INFO - Step barshadow running with args (<MultiSlitModel from jw01345061001_07101_00003_nrs2_nsclean.fits>,).
2026-04-22 19:09:58,766 - jwst.barshadow.barshadow_step - INFO - Using BARSHADOW reference file /home/runner/crds_cache/references/jwst/nirspec/jwst_nirspec_barshadow_0008.fits
2026-04-22 19:09:58,957 - jwst.barshadow.bar_shadow - INFO - Working on slitlet 11
2026-04-22 19:09:58,958 - jwst.barshadow.bar_shadow - INFO - Bar shadow correction skipped for slitlet 11 (source not uniform)
2026-04-22 19:09:58,966 - stpipe.step - INFO - Step barshadow done
2026-04-22 19:09:59,324 - stpipe.step - INFO - Step photom running with args (<MultiSlitModel from jw01345061001_07101_00003_nrs2_nsclean.fits>,).
2026-04-22 19:09:59,341 - jwst.photom.photom_step - INFO - Using photom reference file: /home/runner/crds_cache/references/jwst/nirspec/jwst_nirspec_photom_0015.fits
2026-04-22 19:09:59,342 - jwst.photom.photom_step - INFO - Using area reference file: /home/runner/crds_cache/references/jwst/nirspec/jwst_nirspec_area_0051.fits
2026-04-22 19:09:59,518 - jwst.photom.photom - INFO - Using instrument: NIRSPEC
2026-04-22 19:09:59,519 - jwst.photom.photom - INFO - detector: NRS2
2026-04-22 19:09:59,519 - jwst.photom.photom - INFO - exp_type: NRS_MSASPEC
2026-04-22 19:09:59,520 - jwst.photom.photom - INFO - filter: F290LP
2026-04-22 19:09:59,520 - jwst.photom.photom - INFO - grating: G395M
2026-04-22 19:09:59,565 - jwst.photom.photom - INFO - Working on slit 11
2026-04-22 19:09:59,566 - jwst.photom.photom - INFO - PHOTMJSR value: 1
2026-04-22 19:09:59,594 - stpipe.step - INFO - Step photom done
2026-04-22 19:10:00,122 - stpipe.step - INFO - Step pixel_replace running with args (<MultiSlitModel from ./stage2_nsclean_default/jw01345061001_07101_00003_nrs2_cal.fits>,).
2026-04-22 19:10:00,124 - stpipe.step - INFO - Step skipped.
2026-04-22 19:10:00,400 - stpipe.step - INFO - Step resample_spec running with args (<MultiSlitModel from ./stage2_nsclean_default/jw01345061001_07101_00003_nrs2_cal.fits>,).
2026-04-22 19:10:00,689 - jwst.exp_to_source.exp_to_source - INFO - Reorganizing data from exposure ./stage2_nsclean_default/jw01345061001_07101_00003_nrs2_cal.fits
2026-04-22 19:10:01,077 - jwst.resample.resample_spec - INFO - Specified output pixel scale ratio: 1.0.
2026-04-22 19:10:01,086 - jwst.resample.resample_spec - INFO - Computed output pixel scale: 0.10447 arcsec.
2026-04-22 19:10:01,088 - stcal.resample.resample - INFO - Output pixel scale: 0.10447274011512764 arcsec.
2026-04-22 19:10:01,088 - stcal.resample.resample - INFO - Driz parameter kernel: square
2026-04-22 19:10:01,089 - stcal.resample.resample - INFO - Driz parameter pixfrac: 1.0
2026-04-22 19:10:01,090 - stcal.resample.resample - INFO - Driz parameter fillval: NaN
2026-04-22 19:10:01,090 - stcal.resample.resample - INFO - Driz parameter weight_type: exptime
2026-04-22 19:10:01,092 - jwst.resample.resample - INFO - Resampling science and variance data
2026-04-22 19:10:01,145 - stcal.resample.resample - INFO - Resampling science and variance data
2026-04-22 19:10:01,150 - stcal.resample.resample - INFO - Drizzling (32, 1366) --> (21, 1366)
2026-04-22 19:10:01,154 - stcal.resample.resample - INFO - Drizzling (32, 1366) --> (21, 1366)
2026-04-22 19:10:01,158 - stcal.resample.resample - INFO - Drizzling (32, 1366) --> (21, 1366)
2026-04-22 19:10:01,292 - stcal.alignment.util - INFO - Update S_REGION to POLYGON ICRS 214.831972292 52.885065372 214.832933995 52.885065372 214.832933995 52.885075990 214.831972292 52.885075990
2026-04-22 19:10:01,438 - stpipe.step - INFO - Saved model in ./stage2_nsclean_default/jw01345061001_07101_00003_nrs2_s2d.fits
2026-04-22 19:10:01,439 - stpipe.step - INFO - Step resample_spec done
2026-04-22 19:10:01,529 - jwst.pipeline.calwebb_spec2 - INFO - Extracting 1 MSA slitlets
2026-04-22 19:10:01,837 - stpipe.step - INFO - Step extract_1d running with args (<MultiSlitModel from jw01345061001_07101_00003_nrs2_s2d.fits>,).
2026-04-22 19:10:01,994 - jwst.extract_1d.extract_1d_step - INFO - Using EXTRACT1D reference file /home/runner/crds_cache/references/jwst/nirspec/jwst_nirspec_extract1d_0009.json
2026-04-22 19:10:02,000 - jwst.extract_1d.extract_1d_step - INFO - Using APCORR file /home/runner/crds_cache/references/jwst/nirspec/jwst_nirspec_apcorr_0004.fits
2026-04-22 19:10:02,043 - jwst.extract_1d.extract - INFO - Working on slit 11
2026-04-22 19:10:02,044 - jwst.lib.pipe_utils - WARNING - Mismatched data shapes; skipping invalid data updates for extension 'dq'
2026-04-22 19:10:02,045 - jwst.extract_1d.extract - INFO - Turning on source position correction for exp_type = NRS_MSASPEC
2026-04-22 19:10:02,048 - jwst.extract_1d.source_location - INFO - Using source_xpos and source_ypos to center extraction.
2026-04-22 19:10:02,052 - jwst.extract_1d.extract - INFO - Computed source location is 4.49, at pixel 682, wavelength 4.07
2026-04-22 19:10:02,053 - jwst.extract_1d.extract - INFO - Nominal aperture start/stop: 7.50 -> 12.50 (inclusive)
2026-04-22 19:10:02,054 - jwst.extract_1d.extract - INFO - Nominal location is 10.00, so offset is -5.51 pixels
2026-04-22 19:10:02,055 - jwst.extract_1d.extract - INFO - Mean aperture start/stop from trace: 1.99 -> 6.99 (inclusive)
2026-04-22 19:10:02,058 - jwst.extract_1d.extract - INFO - Creating aperture correction.
2026-04-22 19:10:02,990 - stpipe.step - INFO - Step extract_1d done
2026-04-22 19:10:03,051 - stpipe.step - INFO - Saved model in ./stage2_nsclean_default/jw01345061001_07101_00003_nrs2_x1d.fits
2026-04-22 19:10:03,052 - jwst.pipeline.calwebb_spec2 - INFO - Finished processing product mast_products/jw01345061001_07101_00003_nrs2
2026-04-22 19:10:03,054 - jwst.pipeline.calwebb_spec2 - INFO - Ending calwebb_spec2
2026-04-22 19:10:03,054 - jwst.stpipe.core - INFO - Results used CRDS context: jwst_1464.pmap
2026-04-22 19:10:03,288 - stpipe.step - INFO - Saved model in ./stage2_nsclean_default/jw01345061001_07101_00003_nrs2_cal.fits
2026-04-22 19:10:03,288 - stpipe.step - INFO - Step Spec2Pipeline done
2026-04-22 19:10:03,289 - jwst.stpipe.core - INFO - Results used jwst version: 1.20.2
Saved jw01345061001_07101_00003_nrs2_mask.fits
Saved jw01345061001_07101_00003_nrs2_nsclean.fits
Saved jw01345061001_07101_00003_nrs2_cal.fits
Saved jw01345061001_07101_00003_nrs2_x1d.fits
Run time: 1.2633333333333332 min
In some situations, the NSClean step may fail to find a fit to the background noise. This failure may occur if the mask does not contain enough dark data (marked True). In particular, every column in the mask except for the first and last 4 columns must contain some pixels marked True. The background fitting procedure considers each column, one at a time, so it will crash if there is no data in a column to fit. If failure occurs, check that your mask in the image below has at least some True values in every column.
5.1 Verify the Mask (Default Pipeline Mask) #
Check the mask against the rate data to make sure it keeps only dark areas of the detector.
Note that there are still some remaining illuminated areas, primarily due to transient artifacts like cosmic rays and snowballs.
# Plot the rate data with masked areas blocked.
# List of on-the-fly built masks from the pipeline.
nsclean_default_masks = [
stage2_nsclean_default_dir + "jw01345061001_07101_00003_nrs1_mask.fits",
stage2_nsclean_default_dir + "jw01345061001_07101_00003_nrs2_mask.fits",
]
# Plot each associated set of rateint data and mask file.
for rate_file, mask_file in zip(rate_names, nsclean_default_masks):
plot_dark_data(mast_products_dir + rate_file, mask_file, layout="columns", scale=9)
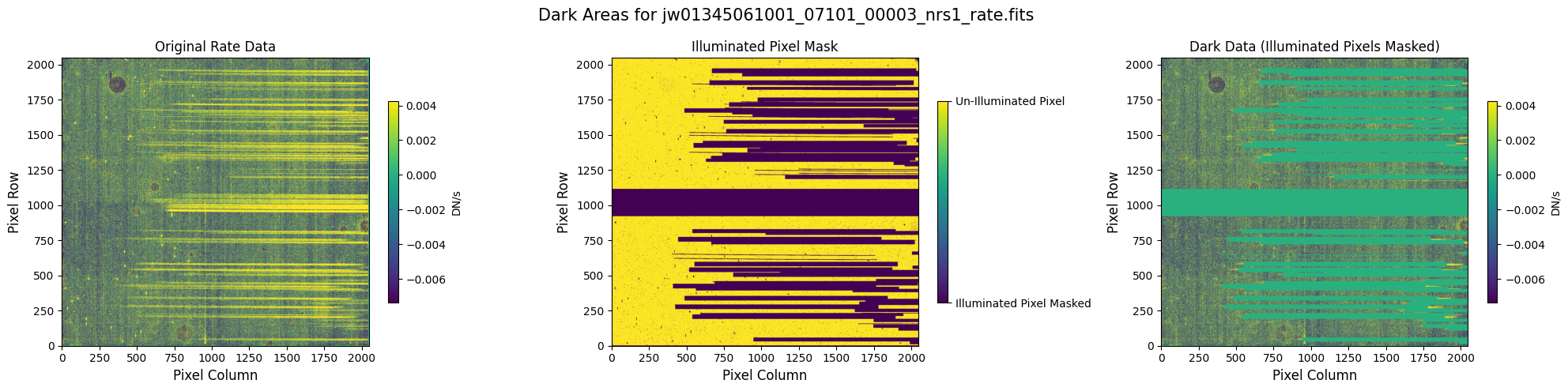
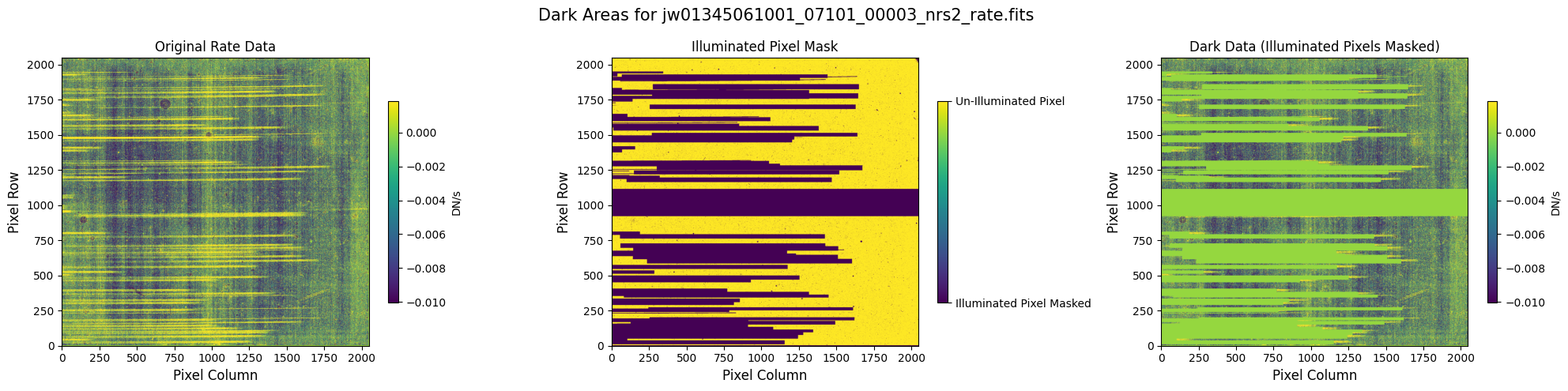
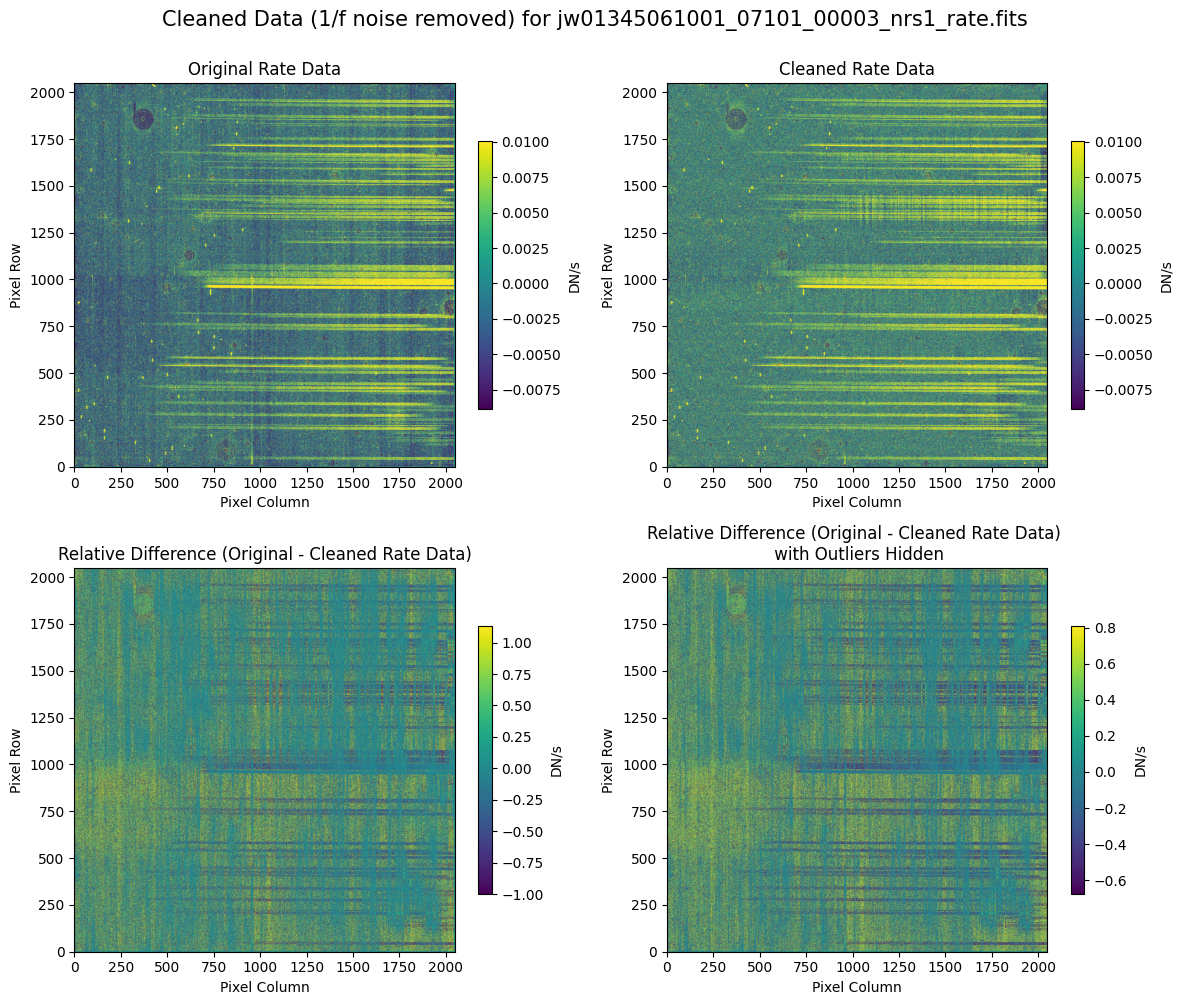
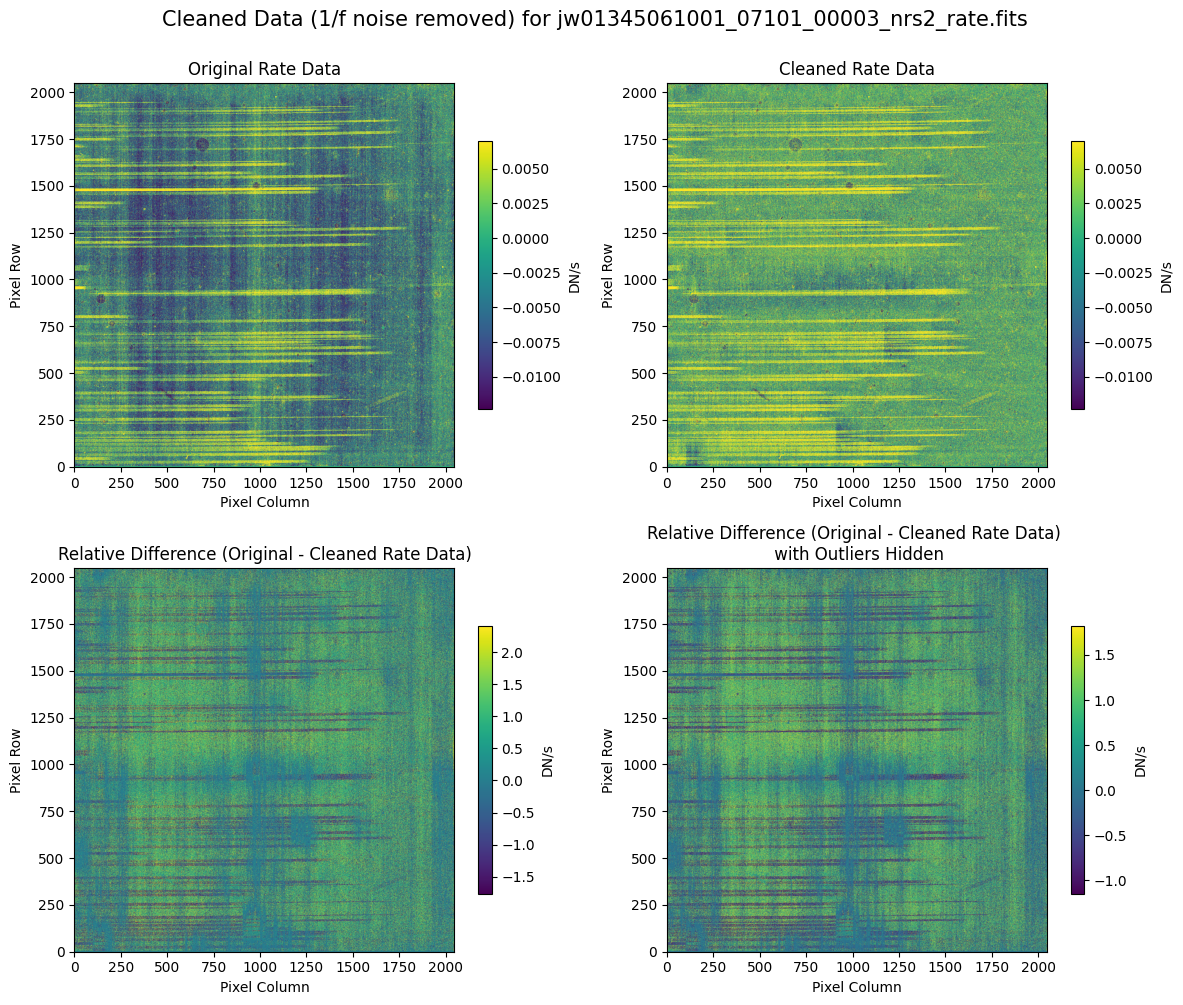
5.2 Comparing Original vs. Cleaned Data (Default Pipeline Mask) #
We can now compare the cleaned data (with the default pipeline mask) to the original rate file and verify that the 1/f noise has been reduced.
In many cases, the cleaning process introduces new artifacts to the rate file. These should be carefully examined and weighed against the benefits of noise reduction. If transient artifacts, like snowballs, are interfering with the cleaning process, it may be beneficial to manually edit the mask to remove these areas from consideration in the background fit. To do so, try varying the outlier detection threshold or editing specific pixels in the mask array directly (explored in the next few sections). Otherwise, refer to the NSClean documentation for additional suggestions on manual editing.
Note that in the images below, there are scattered values with large relative differences from the original rate file (shown in the relative difference image below). These are artifacts of the cleaning process.
There are also broader low-level residual background effects (shown in the relative difference image on the right, below, with scattered outliers, identified with sigma clipping, hidden by masking). These include the background patterns we are trying to remove: the 1/f noise variations in the dispersion direction and the picture frame effect at the top and bottom of the frame (for full-frame data). However, there may also be low-level artifacts introduced by over-fitting the dark data in the cleaning process.
Check both residual images carefully to understand the impact of the cleaning process on your data.
# Plot the original and cleaned data, as well as a residual map.
cleaned_default_masks = [
stage2_nsclean_default_dir + "jw01345061001_07101_00003_nrs1_nsclean.fits",
stage2_nsclean_default_dir + "jw01345061001_07101_00003_nrs2_nsclean.fits",
]
# Plot each associated set of rateint data and cleaned file.
for rate_file, cleaned_file in zip(rate_names, cleaned_default_masks):
plot_cleaned_data(
mast_products_dir + rate_file, cleaned_file, layout="columns", scale=9
)
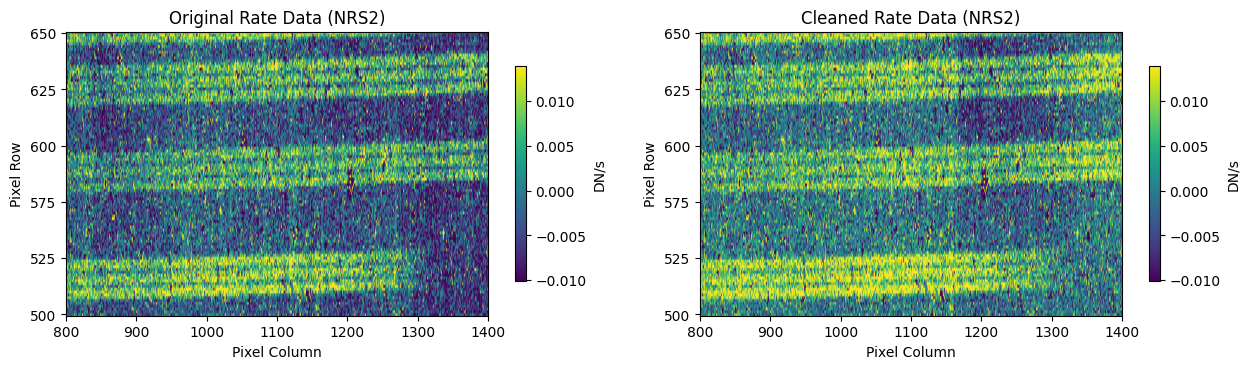
# Plot heavily masked region around x=1000, y=600 NRS2
# Masking can introduce some high frequency noise in the cleaning process that
# appears as vertical striping over the spectral traces
rate_file = mast_products_dir + rate_names[1] # NRS2
original_rate_data = fits.open(rate_file)[1].data[550:651, 800:1401]
cleaned_rate_data = fits.open(cleaned_default_masks[1])[1].data[550:651, 800:1401]
# For plotting vizualization
original_rate_data[np.isnan(original_rate_data)] = 0
cleaned_rate_data[np.isnan(cleaned_rate_data)] = 0
vmin = np.nanpercentile(cleaned_rate_data, 5)
vmax = np.nanpercentile(cleaned_rate_data, 100-9)
# Original vs. cleaned data (with default mask)
fig, axs = plt.subplots(1, 2, figsize=(15, 4))
fig.colorbar(
axs[0].imshow(
original_rate_data,
cmap="viridis",
aspect=4,
origin="lower",
clim=(vmin, vmax),
),
ax=axs[0],
pad=0.05,
shrink=0.7,
label="DN/s",
)
fig.colorbar(
axs[1].imshow(
cleaned_rate_data,
cmap="viridis",
aspect=4,
origin="lower",
clim=(vmin, vmax),
),
ax=axs[1],
pad=0.05,
shrink=0.7,
label="DN/s",
)
# Set titles, tick values, xlabel, and ylabel for subplots
for ax, title in zip(axs, ["Original Rate Data (NRS2)", "Cleaned Rate Data (NRS2)"]):
ax.set(title=title, xlabel="Pixel Column", ylabel="Pixel Row")
ax.set_xticklabels([700, 800, 900, 1000, 1100, 1200, 1300, 1400])
ax.set_yticklabels([475, 500, 525, 575, 600, 625, 650])
/tmp/ipykernel_3057/1065472836.py:48: UserWarning: set_ticklabels() should only be used with a fixed number of ticks, i.e. after set_ticks() or using a FixedLocator.
ax.set_xticklabels([700, 800, 900, 1000, 1100, 1200, 1300, 1400])
/tmp/ipykernel_3057/1065472836.py:49: UserWarning: set_ticklabels() should only be used with a fixed number of ticks, i.e. after set_ticks() or using a FixedLocator.
ax.set_yticklabels([475, 500, 525, 575, 600, 625, 650])
/tmp/ipykernel_3057/1065472836.py:48: UserWarning: set_ticklabels() should only be used with a fixed number of ticks, i.e. after set_ticks() or using a FixedLocator.
ax.set_xticklabels([700, 800, 900, 1000, 1100, 1200, 1300, 1400])
/tmp/ipykernel_3057/1065472836.py:49: UserWarning: set_ticklabels() should only be used with a fixed number of ticks, i.e. after set_ticks() or using a FixedLocator.
ax.set_yticklabels([475, 500, 525, 575, 600, 625, 650])
Compare the extracted spectrum from the cleaned data to the spectrum extracted from the original rate file.
# 1D extracted spectra.
x1d_nsclean_skipped = [
stage2_nsclean_skipped_dir + "jw01345061001_07101_00003_nrs1_x1d.fits",
stage2_nsclean_skipped_dir + "jw01345061001_07101_00003_nrs2_x1d.fits",
]
x1d_nsclean_default = [
stage2_nsclean_default_dir + "jw01345061001_07101_00003_nrs1_x1d.fits",
stage2_nsclean_default_dir + "jw01345061001_07101_00003_nrs2_x1d.fits",
]
# Wavelength region of interest.
for original, cleaned in zip(x1d_nsclean_skipped, x1d_nsclean_default):
plot_spectra([original, cleaned], scale_percent=9)
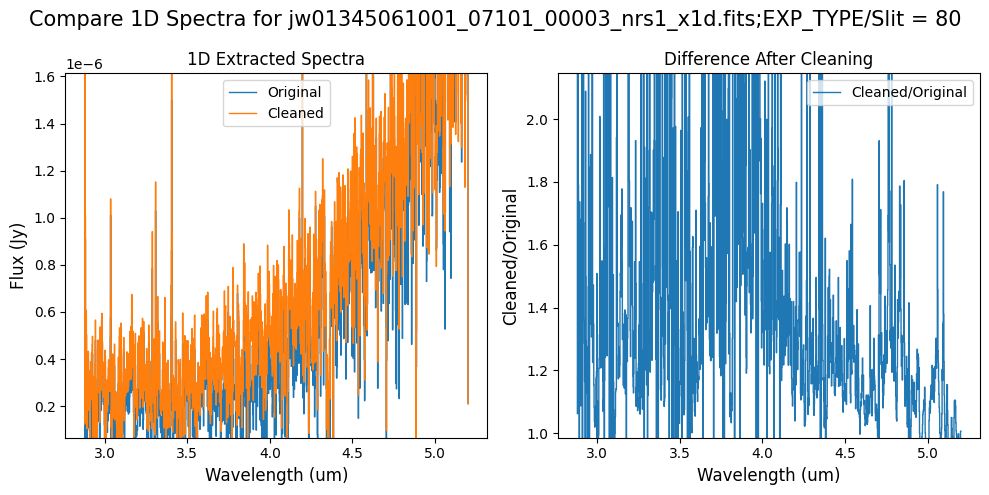
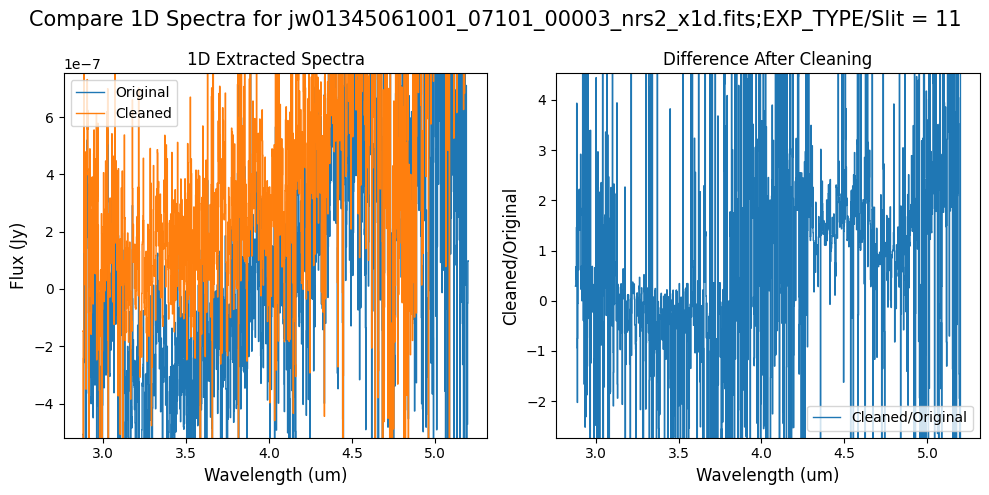
Notes:
In slit 80 on NRS1 and in slit 11 on NRS2, the overall continuum level has been slightly altered by the cleaning process.
In slit 11 on NRS2, some of the negative flux in the original spectrum has been corrected. However, excessive masking in the default mask has introduced high-frequency noise, particularly affecting slit 11 between 4.5 - 5.0 um. This results in a noticeable dip in the spectrum extracted from the cleaned data compared to the original raw data (above).
6. Clean up 1/f Noise with NSClean (Alternate Mask) #
For this data set, note that some regions of the detector are heavily masked, due to overlapping slit regions. For example, see the cleaned rate data for NRS2 above, around x=1000, y=600.
In this region, the cleaning process introduces some high frequency noise that appears as vertical striping over the spectral traces. Slit 11 is extracted from this region, and shows a noticeable dip in the spectrum extracted from the cleaned data, compared to the original rate data (above).
Also note that for MOS data, there may be several illuminated regions of the detector that are not masked by the slitlet bounding boxes. For the M gratings, zeroth-order spectra may appear on the detector, and are not easily located. For the long-pass filters, there is still some light past the red cutoff of the slitlet bounding box.
In this case, it may be beneficial to build the mask with an alternate algorithm. Here, we do not use slitlet bounding boxes and instead iteratively mask any data more than 1 sigma above the background. This leaves more dark data between the spectral traces and improves the background fit in the problematic area.
Note, however, that excessive cleaning may impact the continuum level for the spectra, if too much or too little illuminated data is included in the mask. Again, the generated mask and output spectra should be carefully examined to weigh the benefits of cleaning against the impact on the spectra.
To tune the illumination detection in this mask, try modifying the n_sigma parameter below. A higher value will identify less illumination. A lower value will identify more.
# Set up directory for running NSClean with alternate parameters.
stage2_nsclean_alternate_dir = "./stage2_nsclean_alternate/"
if not os.path.exists(stage2_nsclean_alternate_dir):
os.makedirs(
stage2_nsclean_alternate_dir
) # Create the directory if it doesn't exist.
# 1/f noise cleaned data (alternate NSClean pipeline mask).
# Estimated run time: 7 minutes.
start = tt.time()
for indx, i in enumerate(rate_names):
print(f"Processing {i}...")
if "nrs1" in i:
slit_name = "80"
else:
slit_name = "11"
Spec2Pipeline.call(
mast_products_dir + i,
save_results=True,
steps={
"nsclean": {
"skip": False,
"save_mask": True,
"save_results": True,
"n_sigma": 1,
"mask_spectral_regions": False,
},
"extract_2d": {"slit_names": slit_name},
},
output_dir=stage2_nsclean_alternate_dir,
)
print(f"Saved {i[:-9]}" + "mask.fits")
print(f"Saved {i[:-9]}" + "nsclean.fits")
print(f"Saved {i[:-9]}" + "cal.fits")
print(f"Saved {i[:-9]}" + "x1d.fits")
end = tt.time()
print("Run time: ", round(end - start, 1) / 60.0, " min")
2026-04-22 19:10:15,277 - stpipe.step - INFO - PARS-RESAMPLESPECSTEP parameters found: /home/runner/crds_cache/references/jwst/nirspec/jwst_nirspec_pars-resamplespecstep_0001.asdf
2026-04-22 19:10:15,294 - stpipe.step - INFO - PARS-RESAMPLESPECSTEP parameters found: /home/runner/crds_cache/references/jwst/nirspec/jwst_nirspec_pars-resamplespecstep_0001.asdf
Processing jw01345061001_07101_00003_nrs1_rate.fits...
2026-04-22 19:10:15,753 - stpipe.step - INFO - Spec2Pipeline instance created.
2026-04-22 19:10:15,754 - stpipe.step - INFO - AssignWcsStep instance created.
2026-04-22 19:10:15,755 - stpipe.step - INFO - BadpixSelfcalStep instance created.
2026-04-22 19:10:15,756 - stpipe.step - INFO - MSAFlagOpenStep instance created.
2026-04-22 19:10:15,757 - stpipe.step - INFO - NSCleanStep instance created.
2026-04-22 19:10:15,758 - stpipe.step - INFO - BackgroundStep instance created.
2026-04-22 19:10:15,759 - stpipe.step - INFO - ImprintStep instance created.
2026-04-22 19:10:15,760 - stpipe.step - INFO - Extract2dStep instance created.
2026-04-22 19:10:15,764 - stpipe.step - INFO - MasterBackgroundMosStep instance created.
2026-04-22 19:10:15,765 - stpipe.step - INFO - FlatFieldStep instance created.
2026-04-22 19:10:15,766 - stpipe.step - INFO - PathLossStep instance created.
2026-04-22 19:10:15,767 - stpipe.step - INFO - BarShadowStep instance created.
2026-04-22 19:10:15,767 - stpipe.step - INFO - PhotomStep instance created.
2026-04-22 19:10:15,768 - stpipe.step - INFO - PixelReplaceStep instance created.
2026-04-22 19:10:15,769 - stpipe.step - INFO - ResampleSpecStep instance created.
2026-04-22 19:10:15,771 - stpipe.step - INFO - Extract1dStep instance created.
2026-04-22 19:10:15,772 - stpipe.step - INFO - WavecorrStep instance created.
2026-04-22 19:10:15,773 - stpipe.step - INFO - FlatFieldStep instance created.
2026-04-22 19:10:15,774 - stpipe.step - INFO - SourceTypeStep instance created.
2026-04-22 19:10:15,775 - stpipe.step - INFO - StraylightStep instance created.
2026-04-22 19:10:15,776 - stpipe.step - INFO - FringeStep instance created.
2026-04-22 19:10:15,777 - stpipe.step - INFO - ResidualFringeStep instance created.
2026-04-22 19:10:15,778 - stpipe.step - INFO - PathLossStep instance created.
2026-04-22 19:10:15,778 - stpipe.step - INFO - BarShadowStep instance created.
2026-04-22 19:10:15,779 - stpipe.step - INFO - WfssContamStep instance created.
2026-04-22 19:10:15,780 - stpipe.step - INFO - PhotomStep instance created.
2026-04-22 19:10:15,781 - stpipe.step - INFO - PixelReplaceStep instance created.
2026-04-22 19:10:15,782 - stpipe.step - INFO - ResampleSpecStep instance created.
2026-04-22 19:10:15,784 - stpipe.step - INFO - CubeBuildStep instance created.
2026-04-22 19:10:15,785 - stpipe.step - INFO - Extract1dStep instance created.
2026-04-22 19:10:15,954 - stpipe.step - INFO - Step Spec2Pipeline running with args ('./mast_products/jw01345061001_07101_00003_nrs1_rate.fits',).
2026-04-22 19:10:15,982 - stpipe.step - INFO - Step Spec2Pipeline parameters are:
pre_hooks: []
post_hooks: []
output_file: None
output_dir: ./stage2_nsclean_alternate/
output_ext: .fits
output_use_model: False
output_use_index: True
save_results: True
skip: False
suffix: None
search_output_file: True
input_dir: ''
save_bsub: False
fail_on_exception: True
save_wfss_esec: False
steps:
assign_wcs:
pre_hooks: []
post_hooks: []
output_file: None
output_dir: None
output_ext: .fits
output_use_model: False
output_use_index: True
save_results: False
skip: False
suffix: None
search_output_file: True
input_dir: ''
sip_approx: True
sip_max_pix_error: 0.01
sip_degree: None
sip_max_inv_pix_error: 0.01
sip_inv_degree: None
sip_npoints: 12
slit_y_low: -0.55
slit_y_high: 0.55
nrs_ifu_slice_wcs: False
badpix_selfcal:
pre_hooks: []
post_hooks: []
output_file: None
output_dir: None
output_ext: .fits
output_use_model: False
output_use_index: True
save_results: False
skip: True
suffix: None
search_output_file: True
input_dir: ''
flagfrac_lower: 0.001
flagfrac_upper: 0.001
kernel_size: 15
force_single: False
save_flagged_bkg: False
msa_flagging:
pre_hooks: []
post_hooks: []
output_file: None
output_dir: None
output_ext: .fits
output_use_model: False
output_use_index: True
save_results: False
skip: False
suffix: None
search_output_file: True
input_dir: ''
nsclean:
pre_hooks: []
post_hooks: []
output_file: None
output_dir: None
output_ext: .fits
output_use_model: False
output_use_index: True
save_results: True
skip: False
suffix: None
search_output_file: True
input_dir: ''
fit_method: fft
fit_by_channel: False
background_method: None
background_box_size: None
mask_spectral_regions: False
n_sigma: 1
fit_histogram: False
single_mask: False
user_mask: None
save_mask: True
save_background: False
save_noise: False
bkg_subtract:
pre_hooks: []
post_hooks: []
output_file: None
output_dir: None
output_ext: .fits
output_use_model: False
output_use_index: True
save_results: False
skip: False
suffix: None
search_output_file: True
input_dir: ''
bkg_list: None
save_combined_background: False
sigma: 3.0
maxiters: None
soss_source_percentile: 35.0
soss_bkg_percentile: None
wfss_mmag_extract: None
wfss_maxiter: 5
wfss_rms_stop: 0.0
wfss_outlier_percent: 1.0
imprint_subtract:
pre_hooks: []
post_hooks: []
output_file: None
output_dir: None
output_ext: .fits
output_use_model: False
output_use_index: True
save_results: False
skip: False
suffix: None
search_output_file: True
input_dir: ''
extract_2d:
pre_hooks: []
post_hooks: []
output_file: None
output_dir: None
output_ext: .fits
output_use_model: False
output_use_index: True
save_results: False
skip: False
suffix: None
search_output_file: True
input_dir: ''
slit_names:
- '80'
source_ids: None
extract_orders: None
grism_objects: None
tsgrism_extract_height: None
wfss_extract_half_height: 5
wfss_mmag_extract: None
wfss_nbright: 1000
master_background_mos:
pre_hooks: []
post_hooks: []
output_file: None
output_dir: None
output_ext: .fits
output_use_model: True
output_use_index: True
save_results: False
skip: False
suffix: None
search_output_file: True
input_dir: ''
sigma_clip: 3.0
median_kernel: 1
force_subtract: False
save_background: False
user_background: None
inverse: False
steps:
flat_field:
pre_hooks: []
post_hooks: []
output_file: None
output_dir: None
output_ext: .fits
output_use_model: False
output_use_index: True
save_results: False
skip: False
suffix: None
search_output_file: True
input_dir: ''
save_interpolated_flat: False
user_supplied_flat: None
inverse: False
pathloss:
pre_hooks: []
post_hooks: []
output_file: None
output_dir: None
output_ext: .fits
output_use_model: False
output_use_index: True
save_results: False
skip: False
suffix: None
search_output_file: True
input_dir: ''
inverse: False
source_type: None
user_slit_loc: None
barshadow:
pre_hooks: []
post_hooks: []
output_file: None
output_dir: None
output_ext: .fits
output_use_model: False
output_use_index: True
save_results: False
skip: False
suffix: None
search_output_file: True
input_dir: ''
inverse: False
source_type: None
photom:
pre_hooks: []
post_hooks: []
output_file: None
output_dir: None
output_ext: .fits
output_use_model: False
output_use_index: True
save_results: False
skip: False
suffix: None
search_output_file: True
input_dir: ''
inverse: False
source_type: None
apply_time_correction: True
pixel_replace:
pre_hooks: []
post_hooks: []
output_file: None
output_dir: None
output_ext: .fits
output_use_model: True
output_use_index: True
save_results: False
skip: True
suffix: None
search_output_file: True
input_dir: ''
algorithm: fit_profile
n_adjacent_cols: 3
resample_spec:
pre_hooks: []
post_hooks: []
output_file: None
output_dir: None
output_ext: .fits
output_use_model: False
output_use_index: True
save_results: False
skip: False
suffix: None
search_output_file: True
input_dir: ''
pixfrac: 1.0
kernel: square
fillval: NaN
weight_type: exptime
output_shape: None
pixel_scale_ratio: 1.0
pixel_scale: None
output_wcs: ''
single: False
blendheaders: True
in_memory: True
extract_1d:
pre_hooks: []
post_hooks: []
output_file: None
output_dir: None
output_ext: .fits
output_use_model: False
output_use_index: True
save_results: False
skip: False
suffix: None
search_output_file: True
input_dir: ''
subtract_background: None
apply_apcorr: True
extraction_type: box
use_source_posn: None
position_offset: 0.0
model_nod_pair: True
optimize_psf_location: True
smoothing_length: None
bkg_fit: None
bkg_order: None
log_increment: 50
save_profile: False
save_scene_model: False
save_residual_image: False
center_xy: None
ifu_autocen: False
bkg_sigma_clip: 3.0
ifu_rfcorr: True
ifu_set_srctype: None
ifu_rscale: None
ifu_covar_scale: 1.0
soss_atoca: True
soss_threshold: 0.01
soss_n_os: 2
soss_wave_grid_in: None
soss_wave_grid_out: None
soss_estimate: None
soss_rtol: 0.0001
soss_max_grid_size: 20000
soss_tikfac: None
soss_width: 40.0
soss_bad_pix: masking
soss_modelname: None
soss_order_3: True
wavecorr:
pre_hooks: []
post_hooks: []
output_file: None
output_dir: None
output_ext: .fits
output_use_model: False
output_use_index: True
save_results: False
skip: False
suffix: None
search_output_file: True
input_dir: ''
flat_field:
pre_hooks: []
post_hooks: []
output_file: None
output_dir: None
output_ext: .fits
output_use_model: False
output_use_index: True
save_results: False
skip: False
suffix: None
search_output_file: True
input_dir: ''
save_interpolated_flat: False
user_supplied_flat: None
inverse: False
srctype:
pre_hooks: []
post_hooks: []
output_file: None
output_dir: None
output_ext: .fits
output_use_model: False
output_use_index: True
save_results: False
skip: False
suffix: None
search_output_file: True
input_dir: ''
source_type: None
straylight:
pre_hooks: []
post_hooks: []
output_file: None
output_dir: None
output_ext: .fits
output_use_model: False
output_use_index: True
save_results: False
skip: False
suffix: None
search_output_file: True
input_dir: ''
clean_showers: False
shower_plane: 3
shower_x_stddev: 18.0
shower_y_stddev: 5.0
shower_low_reject: 0.1
shower_high_reject: 99.9
save_shower_model: False
fringe:
pre_hooks: []
post_hooks: []
output_file: None
output_dir: None
output_ext: .fits
output_use_model: False
output_use_index: True
save_results: False
skip: False
suffix: None
search_output_file: True
input_dir: ''
residual_fringe:
pre_hooks: []
post_hooks: []
output_file: None
output_dir: None
output_ext: .fits
output_use_model: False
output_use_index: True
save_results: False
skip: True
suffix: residual_fringe
search_output_file: False
input_dir: ''
save_intermediate_results: False
ignore_region_min: None
ignore_region_max: None
pathloss:
pre_hooks: []
post_hooks: []
output_file: None
output_dir: None
output_ext: .fits
output_use_model: False
output_use_index: True
save_results: False
skip: False
suffix: None
search_output_file: True
input_dir: ''
inverse: False
source_type: None
user_slit_loc: None
barshadow:
pre_hooks: []
post_hooks: []
output_file: None
output_dir: None
output_ext: .fits
output_use_model: False
output_use_index: True
save_results: False
skip: False
suffix: None
search_output_file: True
input_dir: ''
inverse: False
source_type: None
wfss_contam:
pre_hooks: []
post_hooks: []
output_file: None
output_dir: None
output_ext: .fits
output_use_model: False
output_use_index: True
save_results: False
skip: True
suffix: None
search_output_file: True
input_dir: ''
save_simulated_image: False
save_contam_images: False
maximum_cores: none
orders: None
magnitude_limit: None
wl_oversample: 2
max_pixels_per_chunk: 50000
photom:
pre_hooks: []
post_hooks: []
output_file: None
output_dir: None
output_ext: .fits
output_use_model: False
output_use_index: True
save_results: False
skip: False
suffix: None
search_output_file: True
input_dir: ''
inverse: False
source_type: None
apply_time_correction: True
pixel_replace:
pre_hooks: []
post_hooks: []
output_file: None
output_dir: None
output_ext: .fits
output_use_model: True
output_use_index: True
save_results: False
skip: True
suffix: None
search_output_file: True
input_dir: ''
algorithm: fit_profile
n_adjacent_cols: 3
resample_spec:
pre_hooks: []
post_hooks: []
output_file: None
output_dir: None
output_ext: .fits
output_use_model: False
output_use_index: True
save_results: False
skip: False
suffix: None
search_output_file: True
input_dir: ''
pixfrac: 1.0
kernel: square
fillval: NaN
weight_type: exptime
output_shape: None
pixel_scale_ratio: 1.0
pixel_scale: None
output_wcs: ''
single: False
blendheaders: True
in_memory: True
cube_build:
pre_hooks: []
post_hooks: []
output_file: None
output_dir: None
output_ext: .fits
output_use_model: True
output_use_index: True
save_results: False
skip: False
suffix: s3d
search_output_file: False
input_dir: ''
pipeline: 3
channel: all
band: all
grating: all
filter: all
output_type: None
scalexy: 0.0
scalew: 0.0
weighting: drizzle
coord_system: skyalign
ra_center: None
dec_center: None
cube_pa: None
nspax_x: None
nspax_y: None
rois: 0.0
roiw: 0.0
weight_power: 2.0
wavemin: None
wavemax: None
single: False
skip_dqflagging: False
offset_file: None
debug_spaxel: -1 -1 -1
extract_1d:
pre_hooks: []
post_hooks: []
output_file: None
output_dir: None
output_ext: .fits
output_use_model: False
output_use_index: True
save_results: False
skip: False
suffix: None
search_output_file: True
input_dir: ''
subtract_background: None
apply_apcorr: True
extraction_type: box
use_source_posn: None
position_offset: 0.0
model_nod_pair: True
optimize_psf_location: True
smoothing_length: None
bkg_fit: None
bkg_order: None
log_increment: 50
save_profile: False
save_scene_model: False
save_residual_image: False
center_xy: None
ifu_autocen: False
bkg_sigma_clip: 3.0
ifu_rfcorr: True
ifu_set_srctype: None
ifu_rscale: None
ifu_covar_scale: 1.0
soss_atoca: True
soss_threshold: 0.01
soss_n_os: 2
soss_wave_grid_in: None
soss_wave_grid_out: None
soss_estimate: None
soss_rtol: 0.0001
soss_max_grid_size: 20000
soss_tikfac: None
soss_width: 40.0
soss_bad_pix: masking
soss_modelname: None
soss_order_3: True
2026-04-22 19:10:16,014 - stpipe.pipeline - INFO - Prefetching reference files for dataset: 'jw01345061001_07101_00003_nrs1_rate.fits' reftypes = ['apcorr', 'area', 'barshadow', 'bkg', 'camera', 'collimator', 'cubepar', 'dflat', 'disperser', 'distortion', 'extract1d', 'fflat', 'filteroffset', 'flat', 'fore', 'fpa', 'fringe', 'ifufore', 'ifupost', 'ifuslicer', 'mrsxartcorr', 'msa', 'msaoper', 'ote', 'pastasoss', 'pathloss', 'photom', 'psf', 'regions', 'sflat', 'speckernel', 'specprofile', 'specwcs', 'wavecorr', 'wavelengthrange']
2026-04-22 19:10:16,018 - stpipe.pipeline - INFO - Prefetch for APCORR reference file is '/home/runner/crds_cache/references/jwst/nirspec/jwst_nirspec_apcorr_0004.fits'.
2026-04-22 19:10:16,019 - stpipe.pipeline - INFO - Prefetch for AREA reference file is '/home/runner/crds_cache/references/jwst/nirspec/jwst_nirspec_area_0051.fits'.
2026-04-22 19:10:16,019 - stpipe.pipeline - INFO - Prefetch for BARSHADOW reference file is '/home/runner/crds_cache/references/jwst/nirspec/jwst_nirspec_barshadow_0008.fits'.
2026-04-22 19:10:16,020 - stpipe.pipeline - INFO - Prefetch for BKG reference file is 'N/A'.
2026-04-22 19:10:16,020 - stpipe.pipeline - INFO - Prefetch for CAMERA reference file is '/home/runner/crds_cache/references/jwst/nirspec/jwst_nirspec_camera_0008.asdf'.
2026-04-22 19:10:16,021 - stpipe.pipeline - INFO - Prefetch for COLLIMATOR reference file is '/home/runner/crds_cache/references/jwst/nirspec/jwst_nirspec_collimator_0008.asdf'.
2026-04-22 19:10:16,022 - stpipe.pipeline - INFO - Prefetch for CUBEPAR reference file is 'N/A'.
2026-04-22 19:10:16,022 - stpipe.pipeline - INFO - Prefetch for DFLAT reference file is '/home/runner/crds_cache/references/jwst/nirspec/jwst_nirspec_dflat_0001.fits'.
2026-04-22 19:10:16,023 - stpipe.pipeline - INFO - Prefetch for DISPERSER reference file is '/home/runner/crds_cache/references/jwst/nirspec/jwst_nirspec_disperser_0068.asdf'.
2026-04-22 19:10:16,024 - stpipe.pipeline - INFO - Prefetch for DISTORTION reference file is 'N/A'.
2026-04-22 19:10:16,024 - stpipe.pipeline - INFO - Prefetch for EXTRACT1D reference file is '/home/runner/crds_cache/references/jwst/nirspec/jwst_nirspec_extract1d_0009.json'.
2026-04-22 19:10:16,025 - stpipe.pipeline - INFO - Prefetch for FFLAT reference file is '/home/runner/crds_cache/references/jwst/nirspec/jwst_nirspec_fflat_0167.fits'.
2026-04-22 19:10:16,026 - stpipe.pipeline - INFO - Prefetch for FILTEROFFSET reference file is 'N/A'.
2026-04-22 19:10:16,026 - stpipe.pipeline - INFO - Prefetch for FLAT reference file is 'N/A'.
2026-04-22 19:10:16,027 - stpipe.pipeline - INFO - Prefetch for FORE reference file is '/home/runner/crds_cache/references/jwst/nirspec/jwst_nirspec_fore_0051.asdf'.
2026-04-22 19:10:16,027 - stpipe.pipeline - INFO - Prefetch for FPA reference file is '/home/runner/crds_cache/references/jwst/nirspec/jwst_nirspec_fpa_0009.asdf'.
2026-04-22 19:10:16,028 - stpipe.pipeline - INFO - Prefetch for FRINGE reference file is 'N/A'.
2026-04-22 19:10:16,028 - stpipe.pipeline - INFO - Prefetch for IFUFORE reference file is 'N/A'.
2026-04-22 19:10:16,029 - stpipe.pipeline - INFO - Prefetch for IFUPOST reference file is 'N/A'.
2026-04-22 19:10:16,029 - stpipe.pipeline - INFO - Prefetch for IFUSLICER reference file is 'N/A'.
2026-04-22 19:10:16,030 - stpipe.pipeline - INFO - Prefetch for MRSXARTCORR reference file is 'N/A'.
2026-04-22 19:10:16,030 - stpipe.pipeline - INFO - Prefetch for MSA reference file is '/home/runner/crds_cache/references/jwst/nirspec/jwst_nirspec_msa_0009.asdf'.
2026-04-22 19:10:16,031 - stpipe.pipeline - INFO - Prefetch for MSAOPER reference file is '/home/runner/crds_cache/references/jwst/nirspec/jwst_nirspec_msaoper_0006.json'.
2026-04-22 19:10:16,031 - stpipe.pipeline - INFO - Prefetch for OTE reference file is '/home/runner/crds_cache/references/jwst/nirspec/jwst_nirspec_ote_0011.asdf'.
2026-04-22 19:10:16,032 - stpipe.pipeline - INFO - Prefetch for PASTASOSS reference file is 'N/A'.
2026-04-22 19:10:16,032 - stpipe.pipeline - INFO - Prefetch for PATHLOSS reference file is '/home/runner/crds_cache/references/jwst/nirspec/jwst_nirspec_pathloss_0010.fits'.
2026-04-22 19:10:16,033 - stpipe.pipeline - INFO - Prefetch for PHOTOM reference file is '/home/runner/crds_cache/references/jwst/nirspec/jwst_nirspec_photom_0015.fits'.
2026-04-22 19:10:16,034 - stpipe.pipeline - INFO - Prefetch for PSF reference file is 'N/A'.
2026-04-22 19:10:16,035 - stpipe.pipeline - INFO - Prefetch for REGIONS reference file is 'N/A'.
2026-04-22 19:10:16,035 - stpipe.pipeline - INFO - Prefetch for SFLAT reference file is '/home/runner/crds_cache/references/jwst/nirspec/jwst_nirspec_sflat_0225.fits'.
2026-04-22 19:10:16,036 - stpipe.pipeline - INFO - Prefetch for SPECKERNEL reference file is 'N/A'.
2026-04-22 19:10:16,036 - stpipe.pipeline - INFO - Prefetch for SPECPROFILE reference file is 'N/A'.
2026-04-22 19:10:16,037 - stpipe.pipeline - INFO - Prefetch for SPECWCS reference file is 'N/A'.
2026-04-22 19:10:16,037 - stpipe.pipeline - INFO - Prefetch for WAVECORR reference file is '/home/runner/crds_cache/references/jwst/nirspec/jwst_nirspec_wavecorr_0004.asdf'.
2026-04-22 19:10:16,039 - stpipe.pipeline - INFO - Prefetch for WAVELENGTHRANGE reference file is '/home/runner/crds_cache/references/jwst/nirspec/jwst_nirspec_wavelengthrange_0006.asdf'.
2026-04-22 19:10:16,039 - jwst.pipeline.calwebb_spec2 - INFO - Starting calwebb_spec2 ...
2026-04-22 19:10:16,040 - jwst.pipeline.calwebb_spec2 - INFO - Processing product mast_products/jw01345061001_07101_00003_nrs1
2026-04-22 19:10:16,040 - jwst.pipeline.calwebb_spec2 - INFO - Working on input ./mast_products/jw01345061001_07101_00003_nrs1_rate.fits ...
2026-04-22 19:10:16,252 - stpipe.step - INFO - Step assign_wcs running with args (<ImageModel(2048, 2048) from jw01345061001_07101_00003_nrs1_rate.fits>,).
2026-04-22 19:10:16,349 - jwst.assign_wcs.nirspec - INFO - Retrieving open MSA slitlets for msa_metadata_id = 83 and dither_index = 3
2026-04-22 19:10:16,357 - jwst.assign_wcs.nirspec - INFO - Slitlet 3 is background only; assigned source_id=3
2026-04-22 19:10:16,358 - jwst.assign_wcs.nirspec - INFO - Slitlet 4 is background only; assigned source_id=4
2026-04-22 19:10:16,359 - jwst.assign_wcs.nirspec - INFO - Slitlet 5 is background only; assigned source_id=5
2026-04-22 19:10:16,366 - jwst.assign_wcs.nirspec - INFO - Slitlet 9 is background only; assigned source_id=9
2026-04-22 19:10:16,369 - jwst.assign_wcs.nirspec - INFO - Slitlet 10 contains virtual source, with source_id=-59
2026-04-22 19:10:16,372 - jwst.assign_wcs.nirspec - INFO - Slitlet 12 is background only; assigned source_id=12
2026-04-22 19:10:16,373 - jwst.assign_wcs.nirspec - INFO - Slitlet 13 is background only; assigned source_id=13
2026-04-22 19:10:16,374 - jwst.assign_wcs.nirspec - INFO - Slitlet 14 is background only; assigned source_id=14
2026-04-22 19:10:16,376 - jwst.assign_wcs.nirspec - INFO - Slitlet 15 contains virtual source, with source_id=-63
2026-04-22 19:10:16,381 - jwst.assign_wcs.nirspec - INFO - Slitlet 18 is background only; assigned source_id=18
2026-04-22 19:10:16,382 - jwst.assign_wcs.nirspec - INFO - Slitlet 19 is background only; assigned source_id=19
2026-04-22 19:10:16,390 - jwst.assign_wcs.nirspec - INFO - Slitlet 23 is background only; assigned source_id=23
2026-04-22 19:10:16,397 - jwst.assign_wcs.nirspec - INFO - Slitlet 27 is background only; assigned source_id=27
2026-04-22 19:10:16,398 - jwst.assign_wcs.nirspec - INFO - Slitlet 28 is background only; assigned source_id=28
2026-04-22 19:10:16,410 - jwst.assign_wcs.nirspec - INFO - Slitlet 34 is background only; assigned source_id=34
2026-04-22 19:10:16,438 - jwst.assign_wcs.nirspec - INFO - Slitlet 48 is background only; assigned source_id=48
2026-04-22 19:10:16,452 - jwst.assign_wcs.nirspec - INFO - Slitlet 55 is background only; assigned source_id=55
2026-04-22 19:10:16,457 - jwst.assign_wcs.nirspec - INFO - Slitlet 57 contains virtual source, with source_id=-72
2026-04-22 19:10:16,467 - jwst.assign_wcs.nirspec - INFO - Slitlet 62 is background only; assigned source_id=62
2026-04-22 19:10:16,472 - jwst.assign_wcs.nirspec - INFO - Slitlet 64 contains virtual source, with source_id=-74
2026-04-22 19:10:16,477 - jwst.assign_wcs.nirspec - INFO - Slitlet 67 is background only; assigned source_id=67
2026-04-22 19:10:16,478 - jwst.assign_wcs.nirspec - INFO - Slitlet 68 is background only; assigned source_id=68
2026-04-22 19:10:16,481 - jwst.assign_wcs.nirspec - INFO - Slitlet 69 contains virtual source, with source_id=-77
2026-04-22 19:10:16,481 - jwst.assign_wcs.nirspec - INFO - Slitlet 70 is background only; assigned source_id=70
2026-04-22 19:10:16,482 - jwst.assign_wcs.nirspec - INFO - Slitlet 71 is background only; assigned source_id=71
2026-04-22 19:10:16,487 - jwst.assign_wcs.nirspec - INFO - Slitlet 74 is background only; assigned source_id=74
2026-04-22 19:10:16,495 - jwst.assign_wcs.nirspec - INFO - Slitlet 78 is background only; assigned source_id=78
2026-04-22 19:10:16,532 - jwst.assign_wcs.nirspec - INFO - gwa_ytilt is 0.177384809 deg
2026-04-22 19:10:16,532 - jwst.assign_wcs.nirspec - INFO - gwa_xtilt is 0.278486848 deg
2026-04-22 19:10:16,533 - jwst.assign_wcs.nirspec - INFO - theta_y correction: 0.0057073669713260085 deg
2026-04-22 19:10:16,534 - jwst.assign_wcs.nirspec - INFO - theta_x correction: 7.258633810078802e-05 deg
2026-04-22 19:10:16,710 - jwst.assign_wcs.nirspec - INFO - Removing slit 2 from the list of open slits because the WCS bounding_box is completely outside the detector.
2026-04-22 19:10:16,726 - jwst.assign_wcs.nirspec - INFO - Removing slit 5 from the list of open slits because the WCS bounding_box is completely outside the detector.
2026-04-22 19:10:16,742 - jwst.assign_wcs.nirspec - INFO - Removing slit 6 from the list of open slits because the WCS bounding_box is completely outside the detector.
2026-04-22 19:10:16,757 - jwst.assign_wcs.nirspec - INFO - Removing slit 8 from the list of open slits because the WCS bounding_box is completely outside the detector.
2026-04-22 19:10:16,773 - jwst.assign_wcs.nirspec - INFO - Removing slit 9 from the list of open slits because the WCS bounding_box is completely outside the detector.
2026-04-22 19:10:16,788 - jwst.assign_wcs.nirspec - INFO - Removing slit 13 from the list of open slits because the WCS bounding_box is completely outside the detector.
2026-04-22 19:10:16,804 - jwst.assign_wcs.nirspec - INFO - Removing slit 15 from the list of open slits because the WCS bounding_box is completely outside the detector.
2026-04-22 19:10:16,819 - jwst.assign_wcs.nirspec - INFO - Removing slit 18 from the list of open slits because the WCS bounding_box is completely outside the detector.
2026-04-22 19:10:16,835 - jwst.assign_wcs.nirspec - INFO - Removing slit 20 from the list of open slits because the WCS bounding_box is completely outside the detector.
2026-04-22 19:10:16,850 - jwst.assign_wcs.nirspec - INFO - Removing slit 23 from the list of open slits because the WCS bounding_box is completely outside the detector.
2026-04-22 19:10:16,866 - jwst.assign_wcs.nirspec - INFO - Removing slit 24 from the list of open slits because the WCS bounding_box is completely outside the detector.
2026-04-22 19:10:16,881 - jwst.assign_wcs.nirspec - INFO - Removing slit 28 from the list of open slits because the WCS bounding_box is completely outside the detector.
2026-04-22 19:10:16,984 - jwst.assign_wcs.nirspec - INFO - Removing slit 3 from the list of open slits because the WCS bounding_box is completely outside the detector.
2026-04-22 19:10:17,000 - jwst.assign_wcs.nirspec - INFO - Removing slit 4 from the list of open slits because the WCS bounding_box is completely outside the detector.
2026-04-22 19:10:17,017 - jwst.assign_wcs.nirspec - INFO - Removing slit 7 from the list of open slits because the WCS bounding_box is completely outside the detector.
2026-04-22 19:10:17,032 - jwst.assign_wcs.nirspec - INFO - Removing slit 10 from the list of open slits because the WCS bounding_box is completely outside the detector.
2026-04-22 19:10:17,048 - jwst.assign_wcs.nirspec - INFO - Removing slit 11 from the list of open slits because the WCS bounding_box is completely outside the detector.
2026-04-22 19:10:17,064 - jwst.assign_wcs.nirspec - INFO - Removing slit 12 from the list of open slits because the WCS bounding_box is completely outside the detector.
2026-04-22 19:10:17,079 - jwst.assign_wcs.nirspec - INFO - Removing slit 14 from the list of open slits because the WCS bounding_box is completely outside the detector.
2026-04-22 19:10:17,095 - jwst.assign_wcs.nirspec - INFO - Removing slit 16 from the list of open slits because the WCS bounding_box is completely outside the detector.
2026-04-22 19:10:17,110 - jwst.assign_wcs.nirspec - INFO - Removing slit 17 from the list of open slits because the WCS bounding_box is completely outside the detector.
2026-04-22 19:10:17,126 - jwst.assign_wcs.nirspec - INFO - Removing slit 19 from the list of open slits because the WCS bounding_box is completely outside the detector.
2026-04-22 19:10:17,141 - jwst.assign_wcs.nirspec - INFO - Removing slit 21 from the list of open slits because the WCS bounding_box is completely outside the detector.
2026-04-22 19:10:17,157 - jwst.assign_wcs.nirspec - INFO - Removing slit 22 from the list of open slits because the WCS bounding_box is completely outside the detector.
2026-04-22 19:10:17,173 - jwst.assign_wcs.nirspec - INFO - Removing slit 25 from the list of open slits because the WCS bounding_box is completely outside the detector.
2026-04-22 19:10:17,188 - jwst.assign_wcs.nirspec - INFO - Removing slit 26 from the list of open slits because the WCS bounding_box is completely outside the detector.
2026-04-22 19:10:17,204 - jwst.assign_wcs.nirspec - INFO - Removing slit 27 from the list of open slits because the WCS bounding_box is completely outside the detector.
2026-04-22 19:10:17,889 - jwst.assign_wcs.nirspec - INFO - Slits projected on detector NRS1: ['29', '30', '31', '32', '33', '34', '35', '36', '37', '38', '39', '40', '41', '42', '43', '44', '45', '46', '47', '48', '49', '50', '51', '52', '53', '54', '55', '56', '57', '58', '59', '60', '61', '62', '63', '64', '65', '66', '67', '68', '69', '70', '71', '72', '73', '74', '75', '76', '77', '78', '79', '80', '81']
2026-04-22 19:10:17,890 - jwst.assign_wcs.nirspec - INFO - Computing WCS for 53 open slitlets
2026-04-22 19:10:17,914 - jwst.assign_wcs.nirspec - INFO - gwa_ytilt is 0.177384809 deg
2026-04-22 19:10:17,914 - jwst.assign_wcs.nirspec - INFO - gwa_xtilt is 0.278486848 deg
2026-04-22 19:10:17,915 - jwst.assign_wcs.nirspec - INFO - theta_y correction: 0.0057073669713260085 deg
2026-04-22 19:10:17,916 - jwst.assign_wcs.nirspec - INFO - theta_x correction: 7.258633810078802e-05 deg
2026-04-22 19:10:17,926 - jwst.assign_wcs.nirspec - INFO - SPORDER= -1, wrange=[2.87e-06, 5.27e-06]
2026-04-22 19:10:18,016 - jwst.assign_wcs.nirspec - INFO - Applied Barycentric velocity correction : 1.000049924895689
2026-04-22 19:10:18,043 - jwst.assign_wcs.nirspec - INFO - There are 6 open slits in quadrant 1
2026-04-22 19:10:18,078 - jwst.assign_wcs.nirspec - INFO - There are 11 open slits in quadrant 2
2026-04-22 19:10:18,144 - jwst.assign_wcs.nirspec - INFO - There are 20 open slits in quadrant 3
2026-04-22 19:10:18,260 - jwst.assign_wcs.nirspec - INFO - There are 16 open slits in quadrant 4
2026-04-22 19:10:18,581 - jwst.assign_wcs.nirspec - INFO - There are 0 open slits in quadrant 5
2026-04-22 19:10:18,717 - jwst.assign_wcs.nirspec - INFO - Created a NIRSPEC nrs_msaspec pipeline with references {'distortion': None, 'filteroffset': None, 'specwcs': None, 'regions': None, 'wavelengthrange': '/home/runner/crds_cache/references/jwst/nirspec/jwst_nirspec_wavelengthrange_0006.asdf', 'camera': '/home/runner/crds_cache/references/jwst/nirspec/jwst_nirspec_camera_0008.asdf', 'collimator': '/home/runner/crds_cache/references/jwst/nirspec/jwst_nirspec_collimator_0008.asdf', 'disperser': '/home/runner/crds_cache/references/jwst/nirspec/jwst_nirspec_disperser_0068.asdf', 'fore': '/home/runner/crds_cache/references/jwst/nirspec/jwst_nirspec_fore_0051.asdf', 'fpa': '/home/runner/crds_cache/references/jwst/nirspec/jwst_nirspec_fpa_0009.asdf', 'msa': '/home/runner/crds_cache/references/jwst/nirspec/jwst_nirspec_msa_0009.asdf', 'ote': '/home/runner/crds_cache/references/jwst/nirspec/jwst_nirspec_ote_0011.asdf', 'ifupost': None, 'ifufore': None, 'ifuslicer': None, 'msametafile': './mast_products/jw01345061001_01_msa.fits'}
2026-04-22 19:10:21,411 - jwst.assign_wcs.assign_wcs - INFO - COMPLETED assign_wcs
2026-04-22 19:10:21,416 - stpipe.step - INFO - Step assign_wcs done
2026-04-22 19:10:21,702 - stpipe.step - INFO - Step badpix_selfcal running with args (<ImageModel(2048, 2048) from jw01345061001_07101_00003_nrs1_rate.fits>, [], []).
2026-04-22 19:10:21,703 - stpipe.step - INFO - Step skipped.
2026-04-22 19:10:21,951 - stpipe.step - INFO - Step msa_flagging running with args (<ImageModel(2048, 2048) from jw01345061001_07101_00003_nrs1_rate.fits>,).
2026-04-22 19:10:22,899 - jwst.msaflagopen.msaflagopen_step - INFO - Using reference file /home/runner/crds_cache/references/jwst/nirspec/jwst_nirspec_msaoper_0006.json
2026-04-22 19:10:22,969 - jwst.msaflagopen.msaflag_open - INFO - 24 failed open shutters
2026-04-22 19:10:27,981 - stpipe.step - INFO - Step msa_flagging done
2026-04-22 19:10:28,390 - stpipe.step - INFO - Step nsclean running with args (<ImageModel(2048, 2048) from jw01345061001_07101_00003_nrs1_rate.fits>,).
2026-04-22 19:10:28,391 - jwst.nsclean.nsclean_step - WARNING - The 'nsclean' step is a deprecated alias to 'clean_flicker_noise' and will be removed in future builds.
2026-04-22 19:10:28,397 - jwst.clean_flicker_noise.clean_flicker_noise - INFO - Input exposure type is NRS_MSASPEC, detector=NRS1
2026-04-22 19:10:29,477 - jwst.clean_flicker_noise.clean_flicker_noise - INFO - Creating mask
2026-04-22 19:10:29,987 - jwst.clean_flicker_noise.clean_flicker_noise - INFO - Cleaning image jw01345061001_07101_00003_nrs1_rate.fits
2026-04-22 19:10:32,634 - jwst.nsclean.nsclean_step - INFO - Saving mask file ./stage2_nsclean_alternate/jw01345061001_07101_00003_nrs1_mask.fits
2026-04-22 19:10:34,282 - stpipe.step - INFO - Saved model in ./stage2_nsclean_alternate/jw01345061001_07101_00003_nrs1_nsclean.fits
2026-04-22 19:10:34,283 - stpipe.step - INFO - Step nsclean done
2026-04-22 19:10:34,692 - stpipe.step - INFO - Step imprint_subtract running with args (<ImageModel(2048, 2048) from jw01345061001_07101_00003_nrs1_nsclean.fits>, []).
2026-04-22 19:10:34,693 - stpipe.step - INFO - Step skipped.
2026-04-22 19:10:35,005 - stpipe.step - INFO - Step bkg_subtract running with args (<ImageModel(2048, 2048) from jw01345061001_07101_00003_nrs1_nsclean.fits>, []).
2026-04-22 19:10:35,006 - stpipe.step - INFO - Step skipped.
2026-04-22 19:10:35,320 - stpipe.step - INFO - Step extract_2d running with args (<ImageModel(2048, 2048) from jw01345061001_07101_00003_nrs1_nsclean.fits>,).
2026-04-22 19:10:35,327 - jwst.extract_2d.extract_2d - INFO - EXP_TYPE is NRS_MSASPEC
2026-04-22 19:10:35,328 - jwst.extract_2d.nirspec - INFO - Slits selected:
2026-04-22 19:10:35,329 - jwst.extract_2d.nirspec - INFO - Name: 80, source_id: 1509
2026-04-22 19:10:35,390 - jwst.extract_2d.nirspec - INFO - Name of subarray extracted: 80
2026-04-22 19:10:35,391 - jwst.extract_2d.nirspec - INFO - Subarray x-extents are: 423 1777
2026-04-22 19:10:35,392 - jwst.extract_2d.nirspec - INFO - Subarray y-extents are: 262 295
2026-04-22 19:10:35,650 - jwst.extract_2d.nirspec - INFO - set slit_attributes completed
2026-04-22 19:10:35,658 - stcal.alignment.util - INFO - Update S_REGION to POLYGON ICRS 214.817179331 52.830822659 214.816253456 52.830818677 214.816255004 52.830763514 214.817180881 52.830767490
2026-04-22 19:10:35,660 - jwst.extract_2d.nirspec - INFO - Updated S_REGION to POLYGON ICRS 214.817179331 52.830822659 214.816253456 52.830818677 214.816255004 52.830763514 214.817180881 52.830767490
2026-04-22 19:10:35,726 - stpipe.step - INFO - Step extract_2d done
2026-04-22 19:10:36,048 - stpipe.step - INFO - Step srctype running with args (<MultiSlitModel from jw01345061001_07101_00003_nrs1_nsclean.fits>,).
2026-04-22 19:10:36,229 - jwst.srctype.srctype - INFO - Input EXP_TYPE is NRS_MSASPEC
2026-04-22 19:10:36,230 - jwst.srctype.srctype - INFO - source_id=1509, stellarity=1.0000, type=POINT
2026-04-22 19:10:36,231 - stpipe.step - INFO - Step srctype done
2026-04-22 19:10:36,718 - stpipe.step - INFO - Step master_background_mos running with args (<MultiSlitModel from jw01345061001_07101_00003_nrs1_nsclean.fits>,).
2026-04-22 19:10:36,725 - jwst.master_background.master_background_mos_step - WARNING - No background slits available for creating master background. Skipping
2026-04-22 19:10:36,898 - jwst.stpipe.core - INFO - Results used CRDS context: jwst_1464.pmap
2026-04-22 19:10:36,900 - stpipe.step - INFO - Step master_background_mos done
2026-04-22 19:10:37,233 - stpipe.step - INFO - Step wavecorr running with args (<MultiSlitModel from jw01345061001_07101_00003_nrs1_nsclean.fits>,).
2026-04-22 19:10:37,425 - jwst.wavecorr.wavecorr_step - INFO - Using WAVECORR reference file /home/runner/crds_cache/references/jwst/nirspec/jwst_nirspec_wavecorr_0004.asdf
2026-04-22 19:10:37,425 - jwst.wavecorr.wavecorr - INFO - Detected a POINT source type in slit 80
2026-04-22 19:10:37,505 - jwst.wavecorr.wavecorr - INFO - Using wavelength zero-point correction for aperture MOS
2026-04-22 19:10:37,547 - stpipe.step - INFO - Step wavecorr done
2026-04-22 19:10:37,897 - stpipe.step - INFO - Step flat_field running with args (<MultiSlitModel from jw01345061001_07101_00003_nrs1_nsclean.fits>,).
2026-04-22 19:10:37,923 - jwst.flatfield.flat_field_step - INFO - No reference found for type FLAT
2026-04-22 19:10:38,077 - jwst.flatfield.flat_field_step - INFO - Using FFLAT reference file: /home/runner/crds_cache/references/jwst/nirspec/jwst_nirspec_fflat_0167.fits
2026-04-22 19:10:38,550 - jwst.flatfield.flat_field_step - INFO - Using SFLAT reference file: /home/runner/crds_cache/references/jwst/nirspec/jwst_nirspec_sflat_0225.fits
2026-04-22 19:10:38,691 - jwst.flatfield.flat_field_step - INFO - Using DFLAT reference file: /home/runner/crds_cache/references/jwst/nirspec/jwst_nirspec_dflat_0001.fits
2026-04-22 19:10:38,849 - jwst.flatfield.flat_field - INFO - Working on slit 80
2026-04-22 19:10:39,233 - stpipe.step - INFO - Step flat_field done
2026-04-22 19:10:39,589 - stpipe.step - INFO - Step pathloss running with args (<MultiSlitModel from jw01345061001_07101_00003_nrs1_nsclean.fits>,).
2026-04-22 19:10:39,601 - jwst.pathloss.pathloss_step - INFO - Using PATHLOSS reference file /home/runner/crds_cache/references/jwst/nirspec/jwst_nirspec_pathloss_0010.fits
2026-04-22 19:10:39,662 - jwst.pathloss.pathloss - INFO - Input exposure type is NRS_MSASPEC
2026-04-22 19:10:39,825 - jwst.pathloss.pathloss - INFO - Working on slit 0
2026-04-22 19:10:39,826 - jwst.pathloss.pathloss - INFO - Shutter state = 11x, using MOS1x3 entry in ref file
2026-04-22 19:10:39,826 - jwst.pathloss.pathloss - INFO - Shutter above fiducial is closed, using upper region of pathloss array
2026-04-22 19:10:39,896 - stpipe.step - INFO - Step pathloss done
2026-04-22 19:10:40,250 - stpipe.step - INFO - Step barshadow running with args (<MultiSlitModel from jw01345061001_07101_00003_nrs1_nsclean.fits>,).
2026-04-22 19:10:40,263 - jwst.barshadow.barshadow_step - INFO - Using BARSHADOW reference file /home/runner/crds_cache/references/jwst/nirspec/jwst_nirspec_barshadow_0008.fits
2026-04-22 19:10:40,458 - jwst.barshadow.bar_shadow - INFO - Working on slitlet 80
2026-04-22 19:10:40,459 - jwst.barshadow.bar_shadow - INFO - Bar shadow correction skipped for slitlet 80 (source not uniform)
2026-04-22 19:10:40,467 - stpipe.step - INFO - Step barshadow done
2026-04-22 19:10:40,826 - stpipe.step - INFO - Step photom running with args (<MultiSlitModel from jw01345061001_07101_00003_nrs1_nsclean.fits>,).
2026-04-22 19:10:40,844 - jwst.photom.photom_step - INFO - Using photom reference file: /home/runner/crds_cache/references/jwst/nirspec/jwst_nirspec_photom_0015.fits
2026-04-22 19:10:40,845 - jwst.photom.photom_step - INFO - Using area reference file: /home/runner/crds_cache/references/jwst/nirspec/jwst_nirspec_area_0051.fits
2026-04-22 19:10:41,026 - jwst.photom.photom - INFO - Using instrument: NIRSPEC
2026-04-22 19:10:41,027 - jwst.photom.photom - INFO - detector: NRS1
2026-04-22 19:10:41,028 - jwst.photom.photom - INFO - exp_type: NRS_MSASPEC
2026-04-22 19:10:41,028 - jwst.photom.photom - INFO - filter: F290LP
2026-04-22 19:10:41,029 - jwst.photom.photom - INFO - grating: G395M
2026-04-22 19:10:41,073 - jwst.photom.photom - INFO - Working on slit 80
2026-04-22 19:10:41,074 - jwst.photom.photom - INFO - PHOTMJSR value: 1
2026-04-22 19:10:41,103 - stpipe.step - INFO - Step photom done
2026-04-22 19:10:41,663 - stpipe.step - INFO - Step pixel_replace running with args (<MultiSlitModel from ./stage2_nsclean_alternate/jw01345061001_07101_00003_nrs1_cal.fits>,).
2026-04-22 19:10:41,664 - stpipe.step - INFO - Step skipped.
2026-04-22 19:10:41,955 - stpipe.step - INFO - Step resample_spec running with args (<MultiSlitModel from ./stage2_nsclean_alternate/jw01345061001_07101_00003_nrs1_cal.fits>,).
2026-04-22 19:10:42,242 - jwst.exp_to_source.exp_to_source - INFO - Reorganizing data from exposure ./stage2_nsclean_alternate/jw01345061001_07101_00003_nrs1_cal.fits
2026-04-22 19:10:42,633 - jwst.resample.resample_spec - INFO - Specified output pixel scale ratio: 1.0.
2026-04-22 19:10:42,644 - jwst.resample.resample_spec - INFO - Computed output pixel scale: 0.1036 arcsec.
2026-04-22 19:10:42,646 - stcal.resample.resample - INFO - Output pixel scale: 0.10360056695821028 arcsec.
2026-04-22 19:10:42,647 - stcal.resample.resample - INFO - Driz parameter kernel: square
2026-04-22 19:10:42,648 - stcal.resample.resample - INFO - Driz parameter pixfrac: 1.0
2026-04-22 19:10:42,648 - stcal.resample.resample - INFO - Driz parameter fillval: NaN
2026-04-22 19:10:42,649 - stcal.resample.resample - INFO - Driz parameter weight_type: exptime
2026-04-22 19:10:42,650 - jwst.resample.resample - INFO - Resampling science and variance data
2026-04-22 19:10:42,705 - stcal.resample.resample - INFO - Resampling science and variance data
2026-04-22 19:10:42,709 - stcal.resample.resample - INFO - Drizzling (33, 1354) --> (21, 1354)
2026-04-22 19:10:42,713 - stcal.resample.resample - INFO - Drizzling (33, 1354) --> (21, 1354)
2026-04-22 19:10:42,718 - stcal.resample.resample - INFO - Drizzling (33, 1354) --> (21, 1354)
2026-04-22 19:10:42,857 - stcal.alignment.util - INFO - Update S_REGION to POLYGON ICRS 214.816217049 52.830790936 214.817169667 52.830790936 214.817169667 52.830795030 214.816217049 52.830795030
2026-04-22 19:10:43,001 - stpipe.step - INFO - Saved model in ./stage2_nsclean_alternate/jw01345061001_07101_00003_nrs1_s2d.fits
2026-04-22 19:10:43,002 - stpipe.step - INFO - Step resample_spec done
2026-04-22 19:10:43,092 - jwst.pipeline.calwebb_spec2 - INFO - Extracting 1 MSA slitlets
2026-04-22 19:10:43,393 - stpipe.step - INFO - Step extract_1d running with args (<MultiSlitModel from jw01345061001_07101_00003_nrs1_s2d.fits>,).
2026-04-22 19:10:43,548 - jwst.extract_1d.extract_1d_step - INFO - Using EXTRACT1D reference file /home/runner/crds_cache/references/jwst/nirspec/jwst_nirspec_extract1d_0009.json
2026-04-22 19:10:43,555 - jwst.extract_1d.extract_1d_step - INFO - Using APCORR file /home/runner/crds_cache/references/jwst/nirspec/jwst_nirspec_apcorr_0004.fits
2026-04-22 19:10:43,597 - jwst.extract_1d.extract - INFO - Working on slit 80
2026-04-22 19:10:43,598 - jwst.lib.pipe_utils - WARNING - Mismatched data shapes; skipping invalid data updates for extension 'dq'
2026-04-22 19:10:43,599 - jwst.extract_1d.extract - INFO - Turning on source position correction for exp_type = NRS_MSASPEC
2026-04-22 19:10:43,602 - jwst.extract_1d.source_location - INFO - Using source_xpos and source_ypos to center extraction.
2026-04-22 19:10:43,606 - jwst.extract_1d.extract - INFO - Computed source location is 4.78, at pixel 676, wavelength 4.07
2026-04-22 19:10:43,607 - jwst.extract_1d.extract - INFO - Nominal aperture start/stop: 7.50 -> 12.50 (inclusive)
2026-04-22 19:10:43,608 - jwst.extract_1d.extract - INFO - Nominal location is 10.00, so offset is -5.22 pixels
2026-04-22 19:10:43,609 - jwst.extract_1d.extract - INFO - Mean aperture start/stop from trace: 2.28 -> 7.28 (inclusive)
2026-04-22 19:10:43,612 - jwst.extract_1d.extract - INFO - Creating aperture correction.
2026-04-22 19:10:44,537 - stpipe.step - INFO - Step extract_1d done
2026-04-22 19:10:44,598 - stpipe.step - INFO - Saved model in ./stage2_nsclean_alternate/jw01345061001_07101_00003_nrs1_x1d.fits
2026-04-22 19:10:44,599 - jwst.pipeline.calwebb_spec2 - INFO - Finished processing product mast_products/jw01345061001_07101_00003_nrs1
2026-04-22 19:10:44,601 - jwst.pipeline.calwebb_spec2 - INFO - Ending calwebb_spec2
2026-04-22 19:10:44,601 - jwst.stpipe.core - INFO - Results used CRDS context: jwst_1464.pmap
2026-04-22 19:10:44,832 - stpipe.step - INFO - Saved model in ./stage2_nsclean_alternate/jw01345061001_07101_00003_nrs1_cal.fits
2026-04-22 19:10:44,833 - stpipe.step - INFO - Step Spec2Pipeline done
2026-04-22 19:10:44,834 - jwst.stpipe.core - INFO - Results used jwst version: 1.20.2
2026-04-22 19:10:44,861 - stpipe.step - INFO - PARS-RESAMPLESPECSTEP parameters found: /home/runner/crds_cache/references/jwst/nirspec/jwst_nirspec_pars-resamplespecstep_0001.asdf
2026-04-22 19:10:44,878 - stpipe.step - INFO - PARS-RESAMPLESPECSTEP parameters found: /home/runner/crds_cache/references/jwst/nirspec/jwst_nirspec_pars-resamplespecstep_0001.asdf
2026-04-22 19:10:44,899 - stpipe.step - INFO - Spec2Pipeline instance created.
2026-04-22 19:10:44,900 - stpipe.step - INFO - AssignWcsStep instance created.
2026-04-22 19:10:44,901 - stpipe.step - INFO - BadpixSelfcalStep instance created.
2026-04-22 19:10:44,902 - stpipe.step - INFO - MSAFlagOpenStep instance created.
2026-04-22 19:10:44,903 - stpipe.step - INFO - NSCleanStep instance created.
2026-04-22 19:10:44,904 - stpipe.step - INFO - BackgroundStep instance created.
2026-04-22 19:10:44,904 - stpipe.step - INFO - ImprintStep instance created.
2026-04-22 19:10:44,906 - stpipe.step - INFO - Extract2dStep instance created.
2026-04-22 19:10:44,910 - stpipe.step - INFO - MasterBackgroundMosStep instance created.
2026-04-22 19:10:44,911 - stpipe.step - INFO - FlatFieldStep instance created.
2026-04-22 19:10:44,912 - stpipe.step - INFO - PathLossStep instance created.
2026-04-22 19:10:44,913 - stpipe.step - INFO - BarShadowStep instance created.
2026-04-22 19:10:44,913 - stpipe.step - INFO - PhotomStep instance created.
2026-04-22 19:10:44,914 - stpipe.step - INFO - PixelReplaceStep instance created.
2026-04-22 19:10:44,915 - stpipe.step - INFO - ResampleSpecStep instance created.
2026-04-22 19:10:44,917 - stpipe.step - INFO - Extract1dStep instance created.
2026-04-22 19:10:44,918 - stpipe.step - INFO - WavecorrStep instance created.
2026-04-22 19:10:44,919 - stpipe.step - INFO - FlatFieldStep instance created.
2026-04-22 19:10:44,919 - stpipe.step - INFO - SourceTypeStep instance created.
2026-04-22 19:10:44,920 - stpipe.step - INFO - StraylightStep instance created.
2026-04-22 19:10:44,921 - stpipe.step - INFO - FringeStep instance created.
2026-04-22 19:10:44,922 - stpipe.step - INFO - ResidualFringeStep instance created.
2026-04-22 19:10:44,923 - stpipe.step - INFO - PathLossStep instance created.
2026-04-22 19:10:44,924 - stpipe.step - INFO - BarShadowStep instance created.
2026-04-22 19:10:44,925 - stpipe.step - INFO - WfssContamStep instance created.
2026-04-22 19:10:44,926 - stpipe.step - INFO - PhotomStep instance created.
2026-04-22 19:10:44,927 - stpipe.step - INFO - PixelReplaceStep instance created.
2026-04-22 19:10:44,928 - stpipe.step - INFO - ResampleSpecStep instance created.
2026-04-22 19:10:44,929 - stpipe.step - INFO - CubeBuildStep instance created.
2026-04-22 19:10:44,931 - stpipe.step - INFO - Extract1dStep instance created.
Saved jw01345061001_07101_00003_nrs1_mask.fits
Saved jw01345061001_07101_00003_nrs1_nsclean.fits
Saved jw01345061001_07101_00003_nrs1_cal.fits
Saved jw01345061001_07101_00003_nrs1_x1d.fits
Processing jw01345061001_07101_00003_nrs2_rate.fits...
2026-04-22 19:10:45,261 - stpipe.step - INFO - Step Spec2Pipeline running with args ('./mast_products/jw01345061001_07101_00003_nrs2_rate.fits',).
2026-04-22 19:10:45,289 - stpipe.step - INFO - Step Spec2Pipeline parameters are:
pre_hooks: []
post_hooks: []
output_file: None
output_dir: ./stage2_nsclean_alternate/
output_ext: .fits
output_use_model: False
output_use_index: True
save_results: True
skip: False
suffix: None
search_output_file: True
input_dir: ''
save_bsub: False
fail_on_exception: True
save_wfss_esec: False
steps:
assign_wcs:
pre_hooks: []
post_hooks: []
output_file: None
output_dir: None
output_ext: .fits
output_use_model: False
output_use_index: True
save_results: False
skip: False
suffix: None
search_output_file: True
input_dir: ''
sip_approx: True
sip_max_pix_error: 0.01
sip_degree: None
sip_max_inv_pix_error: 0.01
sip_inv_degree: None
sip_npoints: 12
slit_y_low: -0.55
slit_y_high: 0.55
nrs_ifu_slice_wcs: False
badpix_selfcal:
pre_hooks: []
post_hooks: []
output_file: None
output_dir: None
output_ext: .fits
output_use_model: False
output_use_index: True
save_results: False
skip: True
suffix: None
search_output_file: True
input_dir: ''
flagfrac_lower: 0.001
flagfrac_upper: 0.001
kernel_size: 15
force_single: False
save_flagged_bkg: False
msa_flagging:
pre_hooks: []
post_hooks: []
output_file: None
output_dir: None
output_ext: .fits
output_use_model: False
output_use_index: True
save_results: False
skip: False
suffix: None
search_output_file: True
input_dir: ''
nsclean:
pre_hooks: []
post_hooks: []
output_file: None
output_dir: None
output_ext: .fits
output_use_model: False
output_use_index: True
save_results: True
skip: False
suffix: None
search_output_file: True
input_dir: ''
fit_method: fft
fit_by_channel: False
background_method: None
background_box_size: None
mask_spectral_regions: False
n_sigma: 1
fit_histogram: False
single_mask: False
user_mask: None
save_mask: True
save_background: False
save_noise: False
bkg_subtract:
pre_hooks: []
post_hooks: []
output_file: None
output_dir: None
output_ext: .fits
output_use_model: False
output_use_index: True
save_results: False
skip: False
suffix: None
search_output_file: True
input_dir: ''
bkg_list: None
save_combined_background: False
sigma: 3.0
maxiters: None
soss_source_percentile: 35.0
soss_bkg_percentile: None
wfss_mmag_extract: None
wfss_maxiter: 5
wfss_rms_stop: 0.0
wfss_outlier_percent: 1.0
imprint_subtract:
pre_hooks: []
post_hooks: []
output_file: None
output_dir: None
output_ext: .fits
output_use_model: False
output_use_index: True
save_results: False
skip: False
suffix: None
search_output_file: True
input_dir: ''
extract_2d:
pre_hooks: []
post_hooks: []
output_file: None
output_dir: None
output_ext: .fits
output_use_model: False
output_use_index: True
save_results: False
skip: False
suffix: None
search_output_file: True
input_dir: ''
slit_names:
- '11'
source_ids: None
extract_orders: None
grism_objects: None
tsgrism_extract_height: None
wfss_extract_half_height: 5
wfss_mmag_extract: None
wfss_nbright: 1000
master_background_mos:
pre_hooks: []
post_hooks: []
output_file: None
output_dir: None
output_ext: .fits
output_use_model: True
output_use_index: True
save_results: False
skip: False
suffix: None
search_output_file: True
input_dir: ''
sigma_clip: 3.0
median_kernel: 1
force_subtract: False
save_background: False
user_background: None
inverse: False
steps:
flat_field:
pre_hooks: []
post_hooks: []
output_file: None
output_dir: None
output_ext: .fits
output_use_model: False
output_use_index: True
save_results: False
skip: False
suffix: None
search_output_file: True
input_dir: ''
save_interpolated_flat: False
user_supplied_flat: None
inverse: False
pathloss:
pre_hooks: []
post_hooks: []
output_file: None
output_dir: None
output_ext: .fits
output_use_model: False
output_use_index: True
save_results: False
skip: False
suffix: None
search_output_file: True
input_dir: ''
inverse: False
source_type: None
user_slit_loc: None
barshadow:
pre_hooks: []
post_hooks: []
output_file: None
output_dir: None
output_ext: .fits
output_use_model: False
output_use_index: True
save_results: False
skip: False
suffix: None
search_output_file: True
input_dir: ''
inverse: False
source_type: None
photom:
pre_hooks: []
post_hooks: []
output_file: None
output_dir: None
output_ext: .fits
output_use_model: False
output_use_index: True
save_results: False
skip: False
suffix: None
search_output_file: True
input_dir: ''
inverse: False
source_type: None
apply_time_correction: True
pixel_replace:
pre_hooks: []
post_hooks: []
output_file: None
output_dir: None
output_ext: .fits
output_use_model: True
output_use_index: True
save_results: False
skip: True
suffix: None
search_output_file: True
input_dir: ''
algorithm: fit_profile
n_adjacent_cols: 3
resample_spec:
pre_hooks: []
post_hooks: []
output_file: None
output_dir: None
output_ext: .fits
output_use_model: False
output_use_index: True
save_results: False
skip: False
suffix: None
search_output_file: True
input_dir: ''
pixfrac: 1.0
kernel: square
fillval: NaN
weight_type: exptime
output_shape: None
pixel_scale_ratio: 1.0
pixel_scale: None
output_wcs: ''
single: False
blendheaders: True
in_memory: True
extract_1d:
pre_hooks: []
post_hooks: []
output_file: None
output_dir: None
output_ext: .fits
output_use_model: False
output_use_index: True
save_results: False
skip: False
suffix: None
search_output_file: True
input_dir: ''
subtract_background: None
apply_apcorr: True
extraction_type: box
use_source_posn: None
position_offset: 0.0
model_nod_pair: True
optimize_psf_location: True
smoothing_length: None
bkg_fit: None
bkg_order: None
log_increment: 50
save_profile: False
save_scene_model: False
save_residual_image: False
center_xy: None
ifu_autocen: False
bkg_sigma_clip: 3.0
ifu_rfcorr: True
ifu_set_srctype: None
ifu_rscale: None
ifu_covar_scale: 1.0
soss_atoca: True
soss_threshold: 0.01
soss_n_os: 2
soss_wave_grid_in: None
soss_wave_grid_out: None
soss_estimate: None
soss_rtol: 0.0001
soss_max_grid_size: 20000
soss_tikfac: None
soss_width: 40.0
soss_bad_pix: masking
soss_modelname: None
soss_order_3: True
wavecorr:
pre_hooks: []
post_hooks: []
output_file: None
output_dir: None
output_ext: .fits
output_use_model: False
output_use_index: True
save_results: False
skip: False
suffix: None
search_output_file: True
input_dir: ''
flat_field:
pre_hooks: []
post_hooks: []
output_file: None
output_dir: None
output_ext: .fits
output_use_model: False
output_use_index: True
save_results: False
skip: False
suffix: None
search_output_file: True
input_dir: ''
save_interpolated_flat: False
user_supplied_flat: None
inverse: False
srctype:
pre_hooks: []
post_hooks: []
output_file: None
output_dir: None
output_ext: .fits
output_use_model: False
output_use_index: True
save_results: False
skip: False
suffix: None
search_output_file: True
input_dir: ''
source_type: None
straylight:
pre_hooks: []
post_hooks: []
output_file: None
output_dir: None
output_ext: .fits
output_use_model: False
output_use_index: True
save_results: False
skip: False
suffix: None
search_output_file: True
input_dir: ''
clean_showers: False
shower_plane: 3
shower_x_stddev: 18.0
shower_y_stddev: 5.0
shower_low_reject: 0.1
shower_high_reject: 99.9
save_shower_model: False
fringe:
pre_hooks: []
post_hooks: []
output_file: None
output_dir: None
output_ext: .fits
output_use_model: False
output_use_index: True
save_results: False
skip: False
suffix: None
search_output_file: True
input_dir: ''
residual_fringe:
pre_hooks: []
post_hooks: []
output_file: None
output_dir: None
output_ext: .fits
output_use_model: False
output_use_index: True
save_results: False
skip: True
suffix: residual_fringe
search_output_file: False
input_dir: ''
save_intermediate_results: False
ignore_region_min: None
ignore_region_max: None
pathloss:
pre_hooks: []
post_hooks: []
output_file: None
output_dir: None
output_ext: .fits
output_use_model: False
output_use_index: True
save_results: False
skip: False
suffix: None
search_output_file: True
input_dir: ''
inverse: False
source_type: None
user_slit_loc: None
barshadow:
pre_hooks: []
post_hooks: []
output_file: None
output_dir: None
output_ext: .fits
output_use_model: False
output_use_index: True
save_results: False
skip: False
suffix: None
search_output_file: True
input_dir: ''
inverse: False
source_type: None
wfss_contam:
pre_hooks: []
post_hooks: []
output_file: None
output_dir: None
output_ext: .fits
output_use_model: False
output_use_index: True
save_results: False
skip: True
suffix: None
search_output_file: True
input_dir: ''
save_simulated_image: False
save_contam_images: False
maximum_cores: none
orders: None
magnitude_limit: None
wl_oversample: 2
max_pixels_per_chunk: 50000
photom:
pre_hooks: []
post_hooks: []
output_file: None
output_dir: None
output_ext: .fits
output_use_model: False
output_use_index: True
save_results: False
skip: False
suffix: None
search_output_file: True
input_dir: ''
inverse: False
source_type: None
apply_time_correction: True
pixel_replace:
pre_hooks: []
post_hooks: []
output_file: None
output_dir: None
output_ext: .fits
output_use_model: True
output_use_index: True
save_results: False
skip: True
suffix: None
search_output_file: True
input_dir: ''
algorithm: fit_profile
n_adjacent_cols: 3
resample_spec:
pre_hooks: []
post_hooks: []
output_file: None
output_dir: None
output_ext: .fits
output_use_model: False
output_use_index: True
save_results: False
skip: False
suffix: None
search_output_file: True
input_dir: ''
pixfrac: 1.0
kernel: square
fillval: NaN
weight_type: exptime
output_shape: None
pixel_scale_ratio: 1.0
pixel_scale: None
output_wcs: ''
single: False
blendheaders: True
in_memory: True
cube_build:
pre_hooks: []
post_hooks: []
output_file: None
output_dir: None
output_ext: .fits
output_use_model: True
output_use_index: True
save_results: False
skip: False
suffix: s3d
search_output_file: False
input_dir: ''
pipeline: 3
channel: all
band: all
grating: all
filter: all
output_type: None
scalexy: 0.0
scalew: 0.0
weighting: drizzle
coord_system: skyalign
ra_center: None
dec_center: None
cube_pa: None
nspax_x: None
nspax_y: None
rois: 0.0
roiw: 0.0
weight_power: 2.0
wavemin: None
wavemax: None
single: False
skip_dqflagging: False
offset_file: None
debug_spaxel: -1 -1 -1
extract_1d:
pre_hooks: []
post_hooks: []
output_file: None
output_dir: None
output_ext: .fits
output_use_model: False
output_use_index: True
save_results: False
skip: False
suffix: None
search_output_file: True
input_dir: ''
subtract_background: None
apply_apcorr: True
extraction_type: box
use_source_posn: None
position_offset: 0.0
model_nod_pair: True
optimize_psf_location: True
smoothing_length: None
bkg_fit: None
bkg_order: None
log_increment: 50
save_profile: False
save_scene_model: False
save_residual_image: False
center_xy: None
ifu_autocen: False
bkg_sigma_clip: 3.0
ifu_rfcorr: True
ifu_set_srctype: None
ifu_rscale: None
ifu_covar_scale: 1.0
soss_atoca: True
soss_threshold: 0.01
soss_n_os: 2
soss_wave_grid_in: None
soss_wave_grid_out: None
soss_estimate: None
soss_rtol: 0.0001
soss_max_grid_size: 20000
soss_tikfac: None
soss_width: 40.0
soss_bad_pix: masking
soss_modelname: None
soss_order_3: True
2026-04-22 19:10:45,320 - stpipe.pipeline - INFO - Prefetching reference files for dataset: 'jw01345061001_07101_00003_nrs2_rate.fits' reftypes = ['apcorr', 'area', 'barshadow', 'bkg', 'camera', 'collimator', 'cubepar', 'dflat', 'disperser', 'distortion', 'extract1d', 'fflat', 'filteroffset', 'flat', 'fore', 'fpa', 'fringe', 'ifufore', 'ifupost', 'ifuslicer', 'mrsxartcorr', 'msa', 'msaoper', 'ote', 'pastasoss', 'pathloss', 'photom', 'psf', 'regions', 'sflat', 'speckernel', 'specprofile', 'specwcs', 'wavecorr', 'wavelengthrange']
2026-04-22 19:10:45,325 - stpipe.pipeline - INFO - Prefetch for APCORR reference file is '/home/runner/crds_cache/references/jwst/nirspec/jwst_nirspec_apcorr_0004.fits'.
2026-04-22 19:10:45,326 - stpipe.pipeline - INFO - Prefetch for AREA reference file is '/home/runner/crds_cache/references/jwst/nirspec/jwst_nirspec_area_0051.fits'.
2026-04-22 19:10:45,326 - stpipe.pipeline - INFO - Prefetch for BARSHADOW reference file is '/home/runner/crds_cache/references/jwst/nirspec/jwst_nirspec_barshadow_0008.fits'.
2026-04-22 19:10:45,327 - stpipe.pipeline - INFO - Prefetch for BKG reference file is 'N/A'.
2026-04-22 19:10:45,327 - stpipe.pipeline - INFO - Prefetch for CAMERA reference file is '/home/runner/crds_cache/references/jwst/nirspec/jwst_nirspec_camera_0008.asdf'.
2026-04-22 19:10:45,328 - stpipe.pipeline - INFO - Prefetch for COLLIMATOR reference file is '/home/runner/crds_cache/references/jwst/nirspec/jwst_nirspec_collimator_0008.asdf'.
2026-04-22 19:10:45,329 - stpipe.pipeline - INFO - Prefetch for CUBEPAR reference file is 'N/A'.
2026-04-22 19:10:45,329 - stpipe.pipeline - INFO - Prefetch for DFLAT reference file is '/home/runner/crds_cache/references/jwst/nirspec/jwst_nirspec_dflat_0002.fits'.
2026-04-22 19:10:45,330 - stpipe.pipeline - INFO - Prefetch for DISPERSER reference file is '/home/runner/crds_cache/references/jwst/nirspec/jwst_nirspec_disperser_0068.asdf'.
2026-04-22 19:10:45,330 - stpipe.pipeline - INFO - Prefetch for DISTORTION reference file is 'N/A'.
2026-04-22 19:10:45,331 - stpipe.pipeline - INFO - Prefetch for EXTRACT1D reference file is '/home/runner/crds_cache/references/jwst/nirspec/jwst_nirspec_extract1d_0009.json'.
2026-04-22 19:10:45,332 - stpipe.pipeline - INFO - Prefetch for FFLAT reference file is '/home/runner/crds_cache/references/jwst/nirspec/jwst_nirspec_fflat_0167.fits'.
2026-04-22 19:10:45,332 - stpipe.pipeline - INFO - Prefetch for FILTEROFFSET reference file is 'N/A'.
2026-04-22 19:10:45,333 - stpipe.pipeline - INFO - Prefetch for FLAT reference file is 'N/A'.
2026-04-22 19:10:45,333 - stpipe.pipeline - INFO - Prefetch for FORE reference file is '/home/runner/crds_cache/references/jwst/nirspec/jwst_nirspec_fore_0051.asdf'.
2026-04-22 19:10:45,334 - stpipe.pipeline - INFO - Prefetch for FPA reference file is '/home/runner/crds_cache/references/jwst/nirspec/jwst_nirspec_fpa_0009.asdf'.
2026-04-22 19:10:45,335 - stpipe.pipeline - INFO - Prefetch for FRINGE reference file is 'N/A'.
2026-04-22 19:10:45,335 - stpipe.pipeline - INFO - Prefetch for IFUFORE reference file is 'N/A'.
2026-04-22 19:10:45,336 - stpipe.pipeline - INFO - Prefetch for IFUPOST reference file is 'N/A'.
2026-04-22 19:10:45,336 - stpipe.pipeline - INFO - Prefetch for IFUSLICER reference file is 'N/A'.
2026-04-22 19:10:45,337 - stpipe.pipeline - INFO - Prefetch for MRSXARTCORR reference file is 'N/A'.
2026-04-22 19:10:45,337 - stpipe.pipeline - INFO - Prefetch for MSA reference file is '/home/runner/crds_cache/references/jwst/nirspec/jwst_nirspec_msa_0009.asdf'.
2026-04-22 19:10:45,338 - stpipe.pipeline - INFO - Prefetch for MSAOPER reference file is '/home/runner/crds_cache/references/jwst/nirspec/jwst_nirspec_msaoper_0006.json'.
2026-04-22 19:10:45,338 - stpipe.pipeline - INFO - Prefetch for OTE reference file is '/home/runner/crds_cache/references/jwst/nirspec/jwst_nirspec_ote_0011.asdf'.
2026-04-22 19:10:45,339 - stpipe.pipeline - INFO - Prefetch for PASTASOSS reference file is 'N/A'.
2026-04-22 19:10:45,340 - stpipe.pipeline - INFO - Prefetch for PATHLOSS reference file is '/home/runner/crds_cache/references/jwst/nirspec/jwst_nirspec_pathloss_0010.fits'.
2026-04-22 19:10:45,340 - stpipe.pipeline - INFO - Prefetch for PHOTOM reference file is '/home/runner/crds_cache/references/jwst/nirspec/jwst_nirspec_photom_0015.fits'.
2026-04-22 19:10:45,341 - stpipe.pipeline - INFO - Prefetch for PSF reference file is 'N/A'.
2026-04-22 19:10:45,341 - stpipe.pipeline - INFO - Prefetch for REGIONS reference file is 'N/A'.
2026-04-22 19:10:45,342 - stpipe.pipeline - INFO - Prefetch for SFLAT reference file is '/home/runner/crds_cache/references/jwst/nirspec/jwst_nirspec_sflat_0232.fits'.
2026-04-22 19:10:45,342 - stpipe.pipeline - INFO - Prefetch for SPECKERNEL reference file is 'N/A'.
2026-04-22 19:10:45,343 - stpipe.pipeline - INFO - Prefetch for SPECPROFILE reference file is 'N/A'.
2026-04-22 19:10:45,344 - stpipe.pipeline - INFO - Prefetch for SPECWCS reference file is 'N/A'.
2026-04-22 19:10:45,344 - stpipe.pipeline - INFO - Prefetch for WAVECORR reference file is '/home/runner/crds_cache/references/jwst/nirspec/jwst_nirspec_wavecorr_0004.asdf'.
2026-04-22 19:10:45,345 - stpipe.pipeline - INFO - Prefetch for WAVELENGTHRANGE reference file is '/home/runner/crds_cache/references/jwst/nirspec/jwst_nirspec_wavelengthrange_0006.asdf'.
2026-04-22 19:10:45,345 - jwst.pipeline.calwebb_spec2 - INFO - Starting calwebb_spec2 ...
2026-04-22 19:10:45,346 - jwst.pipeline.calwebb_spec2 - INFO - Processing product mast_products/jw01345061001_07101_00003_nrs2
2026-04-22 19:10:45,347 - jwst.pipeline.calwebb_spec2 - INFO - Working on input ./mast_products/jw01345061001_07101_00003_nrs2_rate.fits ...
2026-04-22 19:10:45,561 - stpipe.step - INFO - Step assign_wcs running with args (<ImageModel(2048, 2048) from jw01345061001_07101_00003_nrs2_rate.fits>,).
2026-04-22 19:10:45,653 - jwst.assign_wcs.nirspec - INFO - Retrieving open MSA slitlets for msa_metadata_id = 83 and dither_index = 3
2026-04-22 19:10:45,662 - jwst.assign_wcs.nirspec - INFO - Slitlet 3 is background only; assigned source_id=3
2026-04-22 19:10:45,663 - jwst.assign_wcs.nirspec - INFO - Slitlet 4 is background only; assigned source_id=4
2026-04-22 19:10:45,664 - jwst.assign_wcs.nirspec - INFO - Slitlet 5 is background only; assigned source_id=5
2026-04-22 19:10:45,671 - jwst.assign_wcs.nirspec - INFO - Slitlet 9 is background only; assigned source_id=9
2026-04-22 19:10:45,674 - jwst.assign_wcs.nirspec - INFO - Slitlet 10 contains virtual source, with source_id=-59
2026-04-22 19:10:45,677 - jwst.assign_wcs.nirspec - INFO - Slitlet 12 is background only; assigned source_id=12
2026-04-22 19:10:45,678 - jwst.assign_wcs.nirspec - INFO - Slitlet 13 is background only; assigned source_id=13
2026-04-22 19:10:45,679 - jwst.assign_wcs.nirspec - INFO - Slitlet 14 is background only; assigned source_id=14
2026-04-22 19:10:45,681 - jwst.assign_wcs.nirspec - INFO - Slitlet 15 contains virtual source, with source_id=-63
2026-04-22 19:10:45,686 - jwst.assign_wcs.nirspec - INFO - Slitlet 18 is background only; assigned source_id=18
2026-04-22 19:10:45,687 - jwst.assign_wcs.nirspec - INFO - Slitlet 19 is background only; assigned source_id=19
2026-04-22 19:10:45,694 - jwst.assign_wcs.nirspec - INFO - Slitlet 23 is background only; assigned source_id=23
2026-04-22 19:10:45,701 - jwst.assign_wcs.nirspec - INFO - Slitlet 27 is background only; assigned source_id=27
2026-04-22 19:10:45,702 - jwst.assign_wcs.nirspec - INFO - Slitlet 28 is background only; assigned source_id=28
2026-04-22 19:10:45,713 - jwst.assign_wcs.nirspec - INFO - Slitlet 34 is background only; assigned source_id=34
2026-04-22 19:10:45,742 - jwst.assign_wcs.nirspec - INFO - Slitlet 48 is background only; assigned source_id=48
2026-04-22 19:10:45,755 - jwst.assign_wcs.nirspec - INFO - Slitlet 55 is background only; assigned source_id=55
2026-04-22 19:10:45,761 - jwst.assign_wcs.nirspec - INFO - Slitlet 57 contains virtual source, with source_id=-72
2026-04-22 19:10:45,770 - jwst.assign_wcs.nirspec - INFO - Slitlet 62 is background only; assigned source_id=62
2026-04-22 19:10:45,775 - jwst.assign_wcs.nirspec - INFO - Slitlet 64 contains virtual source, with source_id=-74
2026-04-22 19:10:45,780 - jwst.assign_wcs.nirspec - INFO - Slitlet 67 is background only; assigned source_id=67
2026-04-22 19:10:45,781 - jwst.assign_wcs.nirspec - INFO - Slitlet 68 is background only; assigned source_id=68
2026-04-22 19:10:45,784 - jwst.assign_wcs.nirspec - INFO - Slitlet 69 contains virtual source, with source_id=-77
2026-04-22 19:10:45,785 - jwst.assign_wcs.nirspec - INFO - Slitlet 70 is background only; assigned source_id=70
2026-04-22 19:10:45,786 - jwst.assign_wcs.nirspec - INFO - Slitlet 71 is background only; assigned source_id=71
2026-04-22 19:10:45,791 - jwst.assign_wcs.nirspec - INFO - Slitlet 74 is background only; assigned source_id=74
2026-04-22 19:10:45,798 - jwst.assign_wcs.nirspec - INFO - Slitlet 78 is background only; assigned source_id=78
2026-04-22 19:10:45,829 - jwst.assign_wcs.nirspec - INFO - gwa_ytilt is 0.177384809 deg
2026-04-22 19:10:45,830 - jwst.assign_wcs.nirspec - INFO - gwa_xtilt is 0.278486848 deg
2026-04-22 19:10:45,831 - jwst.assign_wcs.nirspec - INFO - theta_y correction: 0.0057073669713260085 deg
2026-04-22 19:10:45,832 - jwst.assign_wcs.nirspec - INFO - theta_x correction: 7.258633810078802e-05 deg
2026-04-22 19:10:46,784 - jwst.assign_wcs.nirspec - INFO - Removing slit 58 from the list of open slits because the WCS bounding_box is completely outside the detector.
2026-04-22 19:10:46,800 - jwst.assign_wcs.nirspec - INFO - Removing slit 59 from the list of open slits because the WCS bounding_box is completely outside the detector.
2026-04-22 19:10:46,816 - jwst.assign_wcs.nirspec - INFO - Removing slit 60 from the list of open slits because the WCS bounding_box is completely outside the detector.
2026-04-22 19:10:46,833 - jwst.assign_wcs.nirspec - INFO - Removing slit 61 from the list of open slits because the WCS bounding_box is completely outside the detector.
2026-04-22 19:10:46,849 - jwst.assign_wcs.nirspec - INFO - Removing slit 62 from the list of open slits because the WCS bounding_box is completely outside the detector.
2026-04-22 19:10:46,865 - jwst.assign_wcs.nirspec - INFO - Removing slit 65 from the list of open slits because the WCS bounding_box is completely outside the detector.
2026-04-22 19:10:46,881 - jwst.assign_wcs.nirspec - INFO - Removing slit 66 from the list of open slits because the WCS bounding_box is completely outside the detector.
2026-04-22 19:10:46,897 - jwst.assign_wcs.nirspec - INFO - Removing slit 68 from the list of open slits because the WCS bounding_box is completely outside the detector.
2026-04-22 19:10:46,913 - jwst.assign_wcs.nirspec - INFO - Removing slit 69 from the list of open slits because the WCS bounding_box is completely outside the detector.
2026-04-22 19:10:46,929 - jwst.assign_wcs.nirspec - INFO - Removing slit 70 from the list of open slits because the WCS bounding_box is completely outside the detector.
2026-04-22 19:10:46,946 - jwst.assign_wcs.nirspec - INFO - Removing slit 76 from the list of open slits because the WCS bounding_box is completely outside the detector.
2026-04-22 19:10:46,963 - jwst.assign_wcs.nirspec - INFO - Removing slit 78 from the list of open slits because the WCS bounding_box is completely outside the detector.
2026-04-22 19:10:47,025 - jwst.assign_wcs.nirspec - INFO - Removing slit 57 from the list of open slits because the WCS bounding_box is completely outside the detector.
2026-04-22 19:10:47,042 - jwst.assign_wcs.nirspec - INFO - Removing slit 63 from the list of open slits because the WCS bounding_box is completely outside the detector.
2026-04-22 19:10:47,058 - jwst.assign_wcs.nirspec - INFO - Removing slit 64 from the list of open slits because the WCS bounding_box is completely outside the detector.
2026-04-22 19:10:47,074 - jwst.assign_wcs.nirspec - INFO - Removing slit 67 from the list of open slits because the WCS bounding_box is completely outside the detector.
2026-04-22 19:10:47,090 - jwst.assign_wcs.nirspec - INFO - Removing slit 71 from the list of open slits because the WCS bounding_box is completely outside the detector.
2026-04-22 19:10:47,106 - jwst.assign_wcs.nirspec - INFO - Removing slit 72 from the list of open slits because the WCS bounding_box is completely outside the detector.
2026-04-22 19:10:47,123 - jwst.assign_wcs.nirspec - INFO - Removing slit 73 from the list of open slits because the WCS bounding_box is completely outside the detector.
2026-04-22 19:10:47,139 - jwst.assign_wcs.nirspec - INFO - Removing slit 74 from the list of open slits because the WCS bounding_box is completely outside the detector.
2026-04-22 19:10:47,156 - jwst.assign_wcs.nirspec - INFO - Removing slit 75 from the list of open slits because the WCS bounding_box is completely outside the detector.
2026-04-22 19:10:47,172 - jwst.assign_wcs.nirspec - INFO - Removing slit 77 from the list of open slits because the WCS bounding_box is completely outside the detector.
2026-04-22 19:10:47,188 - jwst.assign_wcs.nirspec - INFO - Removing slit 79 from the list of open slits because the WCS bounding_box is completely outside the detector.
2026-04-22 19:10:47,204 - jwst.assign_wcs.nirspec - INFO - Removing slit 80 from the list of open slits because the WCS bounding_box is completely outside the detector.
2026-04-22 19:10:47,221 - jwst.assign_wcs.nirspec - INFO - Removing slit 81 from the list of open slits because the WCS bounding_box is completely outside the detector.
2026-04-22 19:10:47,222 - jwst.assign_wcs.nirspec - INFO - Slits projected on detector NRS2: ['2', '3', '4', '5', '6', '7', '8', '9', '10', '11', '12', '13', '14', '15', '16', '17', '18', '19', '20', '21', '22', '23', '24', '25', '26', '27', '28', '29', '30', '31', '32', '33', '34', '35', '36', '37', '38', '39', '40', '41', '42', '43', '44', '45', '46', '47', '48', '49', '50', '51', '52', '53', '54', '55', '56']
2026-04-22 19:10:47,224 - jwst.assign_wcs.nirspec - INFO - Computing WCS for 55 open slitlets
2026-04-22 19:10:47,246 - jwst.assign_wcs.nirspec - INFO - gwa_ytilt is 0.177384809 deg
2026-04-22 19:10:47,247 - jwst.assign_wcs.nirspec - INFO - gwa_xtilt is 0.278486848 deg
2026-04-22 19:10:47,248 - jwst.assign_wcs.nirspec - INFO - theta_y correction: 0.0057073669713260085 deg
2026-04-22 19:10:47,249 - jwst.assign_wcs.nirspec - INFO - theta_x correction: 7.258633810078802e-05 deg
2026-04-22 19:10:47,259 - jwst.assign_wcs.nirspec - INFO - SPORDER= -1, wrange=[2.87e-06, 5.27e-06]
2026-04-22 19:10:47,349 - jwst.assign_wcs.nirspec - INFO - Applied Barycentric velocity correction : 1.000049924895689
2026-04-22 19:10:47,376 - jwst.assign_wcs.nirspec - INFO - There are 18 open slits in quadrant 1
2026-04-22 19:10:47,483 - jwst.assign_wcs.nirspec - INFO - There are 26 open slits in quadrant 2
2026-04-22 19:10:47,870 - jwst.assign_wcs.nirspec - INFO - There are 8 open slits in quadrant 3
2026-04-22 19:10:47,920 - jwst.assign_wcs.nirspec - INFO - There are 3 open slits in quadrant 4
2026-04-22 19:10:47,939 - jwst.assign_wcs.nirspec - INFO - There are 0 open slits in quadrant 5
2026-04-22 19:10:48,078 - jwst.assign_wcs.nirspec - INFO - Created a NIRSPEC nrs_msaspec pipeline with references {'distortion': None, 'filteroffset': None, 'specwcs': None, 'regions': None, 'wavelengthrange': '/home/runner/crds_cache/references/jwst/nirspec/jwst_nirspec_wavelengthrange_0006.asdf', 'camera': '/home/runner/crds_cache/references/jwst/nirspec/jwst_nirspec_camera_0008.asdf', 'collimator': '/home/runner/crds_cache/references/jwst/nirspec/jwst_nirspec_collimator_0008.asdf', 'disperser': '/home/runner/crds_cache/references/jwst/nirspec/jwst_nirspec_disperser_0068.asdf', 'fore': '/home/runner/crds_cache/references/jwst/nirspec/jwst_nirspec_fore_0051.asdf', 'fpa': '/home/runner/crds_cache/references/jwst/nirspec/jwst_nirspec_fpa_0009.asdf', 'msa': '/home/runner/crds_cache/references/jwst/nirspec/jwst_nirspec_msa_0009.asdf', 'ote': '/home/runner/crds_cache/references/jwst/nirspec/jwst_nirspec_ote_0011.asdf', 'ifupost': None, 'ifufore': None, 'ifuslicer': None, 'msametafile': './mast_products/jw01345061001_01_msa.fits'}
2026-04-22 19:10:50,942 - jwst.assign_wcs.assign_wcs - INFO - COMPLETED assign_wcs
2026-04-22 19:10:50,950 - stpipe.step - INFO - Step assign_wcs done
2026-04-22 19:10:51,238 - stpipe.step - INFO - Step badpix_selfcal running with args (<ImageModel(2048, 2048) from jw01345061001_07101_00003_nrs2_rate.fits>, [], []).
2026-04-22 19:10:51,239 - stpipe.step - INFO - Step skipped.
2026-04-22 19:10:51,498 - stpipe.step - INFO - Step msa_flagging running with args (<ImageModel(2048, 2048) from jw01345061001_07101_00003_nrs2_rate.fits>,).
2026-04-22 19:10:52,476 - jwst.msaflagopen.msaflagopen_step - INFO - Using reference file /home/runner/crds_cache/references/jwst/nirspec/jwst_nirspec_msaoper_0006.json
2026-04-22 19:10:52,890 - jwst.msaflagopen.msaflag_open - INFO - 24 failed open shutters
2026-04-22 19:10:57,551 - stpipe.step - INFO - Step msa_flagging done
2026-04-22 19:10:57,960 - stpipe.step - INFO - Step nsclean running with args (<ImageModel(2048, 2048) from jw01345061001_07101_00003_nrs2_rate.fits>,).
2026-04-22 19:10:57,961 - jwst.nsclean.nsclean_step - WARNING - The 'nsclean' step is a deprecated alias to 'clean_flicker_noise' and will be removed in future builds.
2026-04-22 19:10:57,967 - jwst.clean_flicker_noise.clean_flicker_noise - INFO - Input exposure type is NRS_MSASPEC, detector=NRS2
2026-04-22 19:10:59,098 - jwst.clean_flicker_noise.clean_flicker_noise - INFO - Creating mask
2026-04-22 19:10:59,620 - jwst.clean_flicker_noise.clean_flicker_noise - INFO - Cleaning image jw01345061001_07101_00003_nrs2_rate.fits
2026-04-22 19:11:02,333 - jwst.nsclean.nsclean_step - INFO - Saving mask file ./stage2_nsclean_alternate/jw01345061001_07101_00003_nrs2_mask.fits
2026-04-22 19:11:04,053 - stpipe.step - INFO - Saved model in ./stage2_nsclean_alternate/jw01345061001_07101_00003_nrs2_nsclean.fits
2026-04-22 19:11:04,054 - stpipe.step - INFO - Step nsclean done
2026-04-22 19:11:04,472 - stpipe.step - INFO - Step imprint_subtract running with args (<ImageModel(2048, 2048) from jw01345061001_07101_00003_nrs2_nsclean.fits>, []).
2026-04-22 19:11:04,473 - stpipe.step - INFO - Step skipped.
2026-04-22 19:11:04,794 - stpipe.step - INFO - Step bkg_subtract running with args (<ImageModel(2048, 2048) from jw01345061001_07101_00003_nrs2_nsclean.fits>, []).
2026-04-22 19:11:04,795 - stpipe.step - INFO - Step skipped.
2026-04-22 19:11:05,118 - stpipe.step - INFO - Step extract_2d running with args (<ImageModel(2048, 2048) from jw01345061001_07101_00003_nrs2_nsclean.fits>,).
2026-04-22 19:11:05,125 - jwst.extract_2d.extract_2d - INFO - EXP_TYPE is NRS_MSASPEC
2026-04-22 19:11:05,126 - jwst.extract_2d.nirspec - INFO - Slits selected:
2026-04-22 19:11:05,126 - jwst.extract_2d.nirspec - INFO - Name: 11, source_id: 386
2026-04-22 19:11:05,190 - jwst.extract_2d.nirspec - INFO - Name of subarray extracted: 11
2026-04-22 19:11:05,191 - jwst.extract_2d.nirspec - INFO - Subarray x-extents are: 141 1507
2026-04-22 19:11:05,192 - jwst.extract_2d.nirspec - INFO - Subarray y-extents are: 616 648
2026-04-22 19:11:05,451 - jwst.extract_2d.nirspec - INFO - set slit_attributes completed
2026-04-22 19:11:05,460 - stcal.alignment.util - INFO - Update S_REGION to POLYGON ICRS 214.832940199 52.885103324 214.832013460 52.885093088 214.832014161 52.885038573 214.832940897 52.885048802
2026-04-22 19:11:05,462 - jwst.extract_2d.nirspec - INFO - Updated S_REGION to POLYGON ICRS 214.832940199 52.885103324 214.832013460 52.885093088 214.832014161 52.885038573 214.832940897 52.885048802
2026-04-22 19:11:05,531 - stpipe.step - INFO - Step extract_2d done
2026-04-22 19:11:05,862 - stpipe.step - INFO - Step srctype running with args (<MultiSlitModel from jw01345061001_07101_00003_nrs2_nsclean.fits>,).
2026-04-22 19:11:06,048 - jwst.srctype.srctype - INFO - Input EXP_TYPE is NRS_MSASPEC
2026-04-22 19:11:06,049 - jwst.srctype.srctype - INFO - source_id=386, stellarity=1.0000, type=POINT
2026-04-22 19:11:06,050 - stpipe.step - INFO - Step srctype done
2026-04-22 19:11:06,556 - stpipe.step - INFO - Step master_background_mos running with args (<MultiSlitModel from jw01345061001_07101_00003_nrs2_nsclean.fits>,).
2026-04-22 19:11:06,563 - jwst.master_background.master_background_mos_step - WARNING - No background slits available for creating master background. Skipping
2026-04-22 19:11:06,737 - jwst.stpipe.core - INFO - Results used CRDS context: jwst_1464.pmap
2026-04-22 19:11:06,739 - stpipe.step - INFO - Step master_background_mos done
2026-04-22 19:11:07,085 - stpipe.step - INFO - Step wavecorr running with args (<MultiSlitModel from jw01345061001_07101_00003_nrs2_nsclean.fits>,).
2026-04-22 19:11:07,276 - jwst.wavecorr.wavecorr_step - INFO - Using WAVECORR reference file /home/runner/crds_cache/references/jwst/nirspec/jwst_nirspec_wavecorr_0004.asdf
2026-04-22 19:11:07,277 - jwst.wavecorr.wavecorr - INFO - Detected a POINT source type in slit 11
2026-04-22 19:11:07,357 - jwst.wavecorr.wavecorr - INFO - Using wavelength zero-point correction for aperture MOS
2026-04-22 19:11:07,400 - stpipe.step - INFO - Step wavecorr done
2026-04-22 19:11:07,760 - stpipe.step - INFO - Step flat_field running with args (<MultiSlitModel from jw01345061001_07101_00003_nrs2_nsclean.fits>,).
2026-04-22 19:11:07,787 - jwst.flatfield.flat_field_step - INFO - No reference found for type FLAT
2026-04-22 19:11:07,941 - jwst.flatfield.flat_field_step - INFO - Using FFLAT reference file: /home/runner/crds_cache/references/jwst/nirspec/jwst_nirspec_fflat_0167.fits
2026-04-22 19:11:08,419 - jwst.flatfield.flat_field_step - INFO - Using SFLAT reference file: /home/runner/crds_cache/references/jwst/nirspec/jwst_nirspec_sflat_0232.fits
2026-04-22 19:11:08,560 - jwst.flatfield.flat_field_step - INFO - Using DFLAT reference file: /home/runner/crds_cache/references/jwst/nirspec/jwst_nirspec_dflat_0002.fits
2026-04-22 19:11:08,720 - jwst.flatfield.flat_field - INFO - Working on slit 11
2026-04-22 19:11:09,114 - stpipe.step - INFO - Step flat_field done
2026-04-22 19:11:09,485 - stpipe.step - INFO - Step pathloss running with args (<MultiSlitModel from jw01345061001_07101_00003_nrs2_nsclean.fits>,).
2026-04-22 19:11:09,497 - jwst.pathloss.pathloss_step - INFO - Using PATHLOSS reference file /home/runner/crds_cache/references/jwst/nirspec/jwst_nirspec_pathloss_0010.fits
2026-04-22 19:11:09,557 - jwst.pathloss.pathloss - INFO - Input exposure type is NRS_MSASPEC
2026-04-22 19:11:09,726 - jwst.pathloss.pathloss - INFO - Working on slit 0
2026-04-22 19:11:09,727 - jwst.pathloss.pathloss - INFO - Shutter state = 11x, using MOS1x3 entry in ref file
2026-04-22 19:11:09,728 - jwst.pathloss.pathloss - INFO - Shutter above fiducial is closed, using upper region of pathloss array
2026-04-22 19:11:09,797 - stpipe.step - INFO - Step pathloss done
2026-04-22 19:11:10,160 - stpipe.step - INFO - Step barshadow running with args (<MultiSlitModel from jw01345061001_07101_00003_nrs2_nsclean.fits>,).
2026-04-22 19:11:10,173 - jwst.barshadow.barshadow_step - INFO - Using BARSHADOW reference file /home/runner/crds_cache/references/jwst/nirspec/jwst_nirspec_barshadow_0008.fits
2026-04-22 19:11:10,373 - jwst.barshadow.bar_shadow - INFO - Working on slitlet 11
2026-04-22 19:11:10,373 - jwst.barshadow.bar_shadow - INFO - Bar shadow correction skipped for slitlet 11 (source not uniform)
2026-04-22 19:11:10,381 - stpipe.step - INFO - Step barshadow done
2026-04-22 19:11:10,752 - stpipe.step - INFO - Step photom running with args (<MultiSlitModel from jw01345061001_07101_00003_nrs2_nsclean.fits>,).
2026-04-22 19:11:10,769 - jwst.photom.photom_step - INFO - Using photom reference file: /home/runner/crds_cache/references/jwst/nirspec/jwst_nirspec_photom_0015.fits
2026-04-22 19:11:10,770 - jwst.photom.photom_step - INFO - Using area reference file: /home/runner/crds_cache/references/jwst/nirspec/jwst_nirspec_area_0051.fits
2026-04-22 19:11:10,957 - jwst.photom.photom - INFO - Using instrument: NIRSPEC
2026-04-22 19:11:10,958 - jwst.photom.photom - INFO - detector: NRS2
2026-04-22 19:11:10,959 - jwst.photom.photom - INFO - exp_type: NRS_MSASPEC
2026-04-22 19:11:10,959 - jwst.photom.photom - INFO - filter: F290LP
2026-04-22 19:11:10,960 - jwst.photom.photom - INFO - grating: G395M
2026-04-22 19:11:11,004 - jwst.photom.photom - INFO - Working on slit 11
2026-04-22 19:11:11,005 - jwst.photom.photom - INFO - PHOTMJSR value: 1
2026-04-22 19:11:11,034 - stpipe.step - INFO - Step photom done
2026-04-22 19:11:11,600 - stpipe.step - INFO - Step pixel_replace running with args (<MultiSlitModel from ./stage2_nsclean_alternate/jw01345061001_07101_00003_nrs2_cal.fits>,).
2026-04-22 19:11:11,602 - stpipe.step - INFO - Step skipped.
2026-04-22 19:11:11,897 - stpipe.step - INFO - Step resample_spec running with args (<MultiSlitModel from ./stage2_nsclean_alternate/jw01345061001_07101_00003_nrs2_cal.fits>,).
2026-04-22 19:11:12,186 - jwst.exp_to_source.exp_to_source - INFO - Reorganizing data from exposure ./stage2_nsclean_alternate/jw01345061001_07101_00003_nrs2_cal.fits
2026-04-22 19:11:12,581 - jwst.resample.resample_spec - INFO - Specified output pixel scale ratio: 1.0.
2026-04-22 19:11:12,590 - jwst.resample.resample_spec - INFO - Computed output pixel scale: 0.10447 arcsec.
2026-04-22 19:11:12,591 - stcal.resample.resample - INFO - Output pixel scale: 0.1044727401149182 arcsec.
2026-04-22 19:11:12,592 - stcal.resample.resample - INFO - Driz parameter kernel: square
2026-04-22 19:11:12,592 - stcal.resample.resample - INFO - Driz parameter pixfrac: 1.0
2026-04-22 19:11:12,593 - stcal.resample.resample - INFO - Driz parameter fillval: NaN
2026-04-22 19:11:12,594 - stcal.resample.resample - INFO - Driz parameter weight_type: exptime
2026-04-22 19:11:12,595 - jwst.resample.resample - INFO - Resampling science and variance data
2026-04-22 19:11:12,648 - stcal.resample.resample - INFO - Resampling science and variance data
2026-04-22 19:11:12,653 - stcal.resample.resample - INFO - Drizzling (32, 1366) --> (21, 1366)
2026-04-22 19:11:12,657 - stcal.resample.resample - INFO - Drizzling (32, 1366) --> (21, 1366)
2026-04-22 19:11:12,661 - stcal.resample.resample - INFO - Drizzling (32, 1366) --> (21, 1366)
2026-04-22 19:11:12,795 - stcal.alignment.util - INFO - Update S_REGION to POLYGON ICRS 214.831972292 52.885065372 214.832933995 52.885065372 214.832933995 52.885075990 214.831972292 52.885075990
2026-04-22 19:11:12,937 - stpipe.step - INFO - Saved model in ./stage2_nsclean_alternate/jw01345061001_07101_00003_nrs2_s2d.fits
2026-04-22 19:11:12,938 - stpipe.step - INFO - Step resample_spec done
2026-04-22 19:11:13,028 - jwst.pipeline.calwebb_spec2 - INFO - Extracting 1 MSA slitlets
2026-04-22 19:11:13,337 - stpipe.step - INFO - Step extract_1d running with args (<MultiSlitModel from jw01345061001_07101_00003_nrs2_s2d.fits>,).
2026-04-22 19:11:13,493 - jwst.extract_1d.extract_1d_step - INFO - Using EXTRACT1D reference file /home/runner/crds_cache/references/jwst/nirspec/jwst_nirspec_extract1d_0009.json
2026-04-22 19:11:13,499 - jwst.extract_1d.extract_1d_step - INFO - Using APCORR file /home/runner/crds_cache/references/jwst/nirspec/jwst_nirspec_apcorr_0004.fits
2026-04-22 19:11:13,541 - jwst.extract_1d.extract - INFO - Working on slit 11
2026-04-22 19:11:13,542 - jwst.lib.pipe_utils - WARNING - Mismatched data shapes; skipping invalid data updates for extension 'dq'
2026-04-22 19:11:13,543 - jwst.extract_1d.extract - INFO - Turning on source position correction for exp_type = NRS_MSASPEC
2026-04-22 19:11:13,545 - jwst.extract_1d.source_location - INFO - Using source_xpos and source_ypos to center extraction.
2026-04-22 19:11:13,550 - jwst.extract_1d.extract - INFO - Computed source location is 4.49, at pixel 682, wavelength 4.07
2026-04-22 19:11:13,551 - jwst.extract_1d.extract - INFO - Nominal aperture start/stop: 7.50 -> 12.50 (inclusive)
2026-04-22 19:11:13,552 - jwst.extract_1d.extract - INFO - Nominal location is 10.00, so offset is -5.51 pixels
2026-04-22 19:11:13,553 - jwst.extract_1d.extract - INFO - Mean aperture start/stop from trace: 1.99 -> 6.99 (inclusive)
2026-04-22 19:11:13,556 - jwst.extract_1d.extract - INFO - Creating aperture correction.
2026-04-22 19:11:14,513 - stpipe.step - INFO - Step extract_1d done
2026-04-22 19:11:14,574 - stpipe.step - INFO - Saved model in ./stage2_nsclean_alternate/jw01345061001_07101_00003_nrs2_x1d.fits
2026-04-22 19:11:14,575 - jwst.pipeline.calwebb_spec2 - INFO - Finished processing product mast_products/jw01345061001_07101_00003_nrs2
2026-04-22 19:11:14,576 - jwst.pipeline.calwebb_spec2 - INFO - Ending calwebb_spec2
2026-04-22 19:11:14,577 - jwst.stpipe.core - INFO - Results used CRDS context: jwst_1464.pmap
2026-04-22 19:11:14,813 - stpipe.step - INFO - Saved model in ./stage2_nsclean_alternate/jw01345061001_07101_00003_nrs2_cal.fits
2026-04-22 19:11:14,813 - stpipe.step - INFO - Step Spec2Pipeline done
2026-04-22 19:11:14,814 - jwst.stpipe.core - INFO - Results used jwst version: 1.20.2
Saved jw01345061001_07101_00003_nrs2_mask.fits
Saved jw01345061001_07101_00003_nrs2_nsclean.fits
Saved jw01345061001_07101_00003_nrs2_cal.fits
Saved jw01345061001_07101_00003_nrs2_x1d.fits
Run time: 0.9933333333333334 min
6.1 Verify the Mask (Alternate Mask) #
Check the mask against the rate data to make sure it keeps only dark areas of the detector.
# Plot the rate data with masked areas blocked.
# List of on-the-fly built masks from the pipeline.
nsclean_alternate_masks = [
stage2_nsclean_alternate_dir + "jw01345061001_07101_00003_nrs1_mask.fits",
stage2_nsclean_alternate_dir + "jw01345061001_07101_00003_nrs2_mask.fits",
]
# Plot each associated set of rateint data and mask file.
for rate_file, mask_file in zip(rate_names, nsclean_alternate_masks):
plot_dark_data(mast_products_dir + rate_file, mask_file, layout="columns", scale=9)
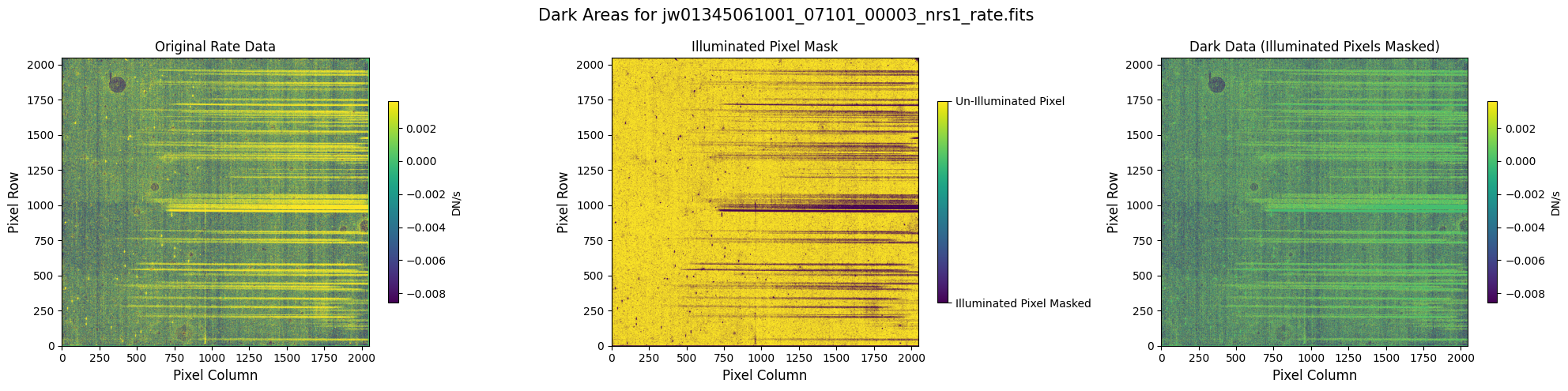
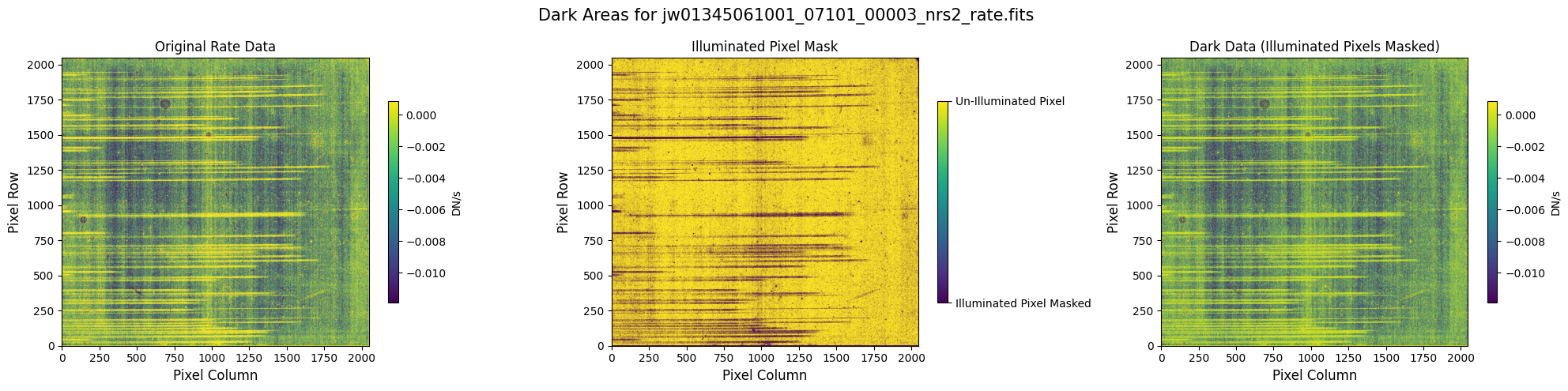
6.2 Comparing Original vs. Cleaned Data (Alternate Mask) #
# Plot the original and cleaned data, as well as a residual map.
cleaned_alternate_masks = [
stage2_nsclean_alternate_dir + "jw01345061001_07101_00003_nrs1_nsclean.fits",
stage2_nsclean_alternate_dir + "jw01345061001_07101_00003_nrs2_nsclean.fits",
]
# Plot each associated set of rateint data and cleaned file.
for rate_file, cleaned_file in zip(rate_names, cleaned_alternate_masks):
plot_cleaned_data(
mast_products_dir + rate_file, cleaned_file, layout="columns", scale=9
)
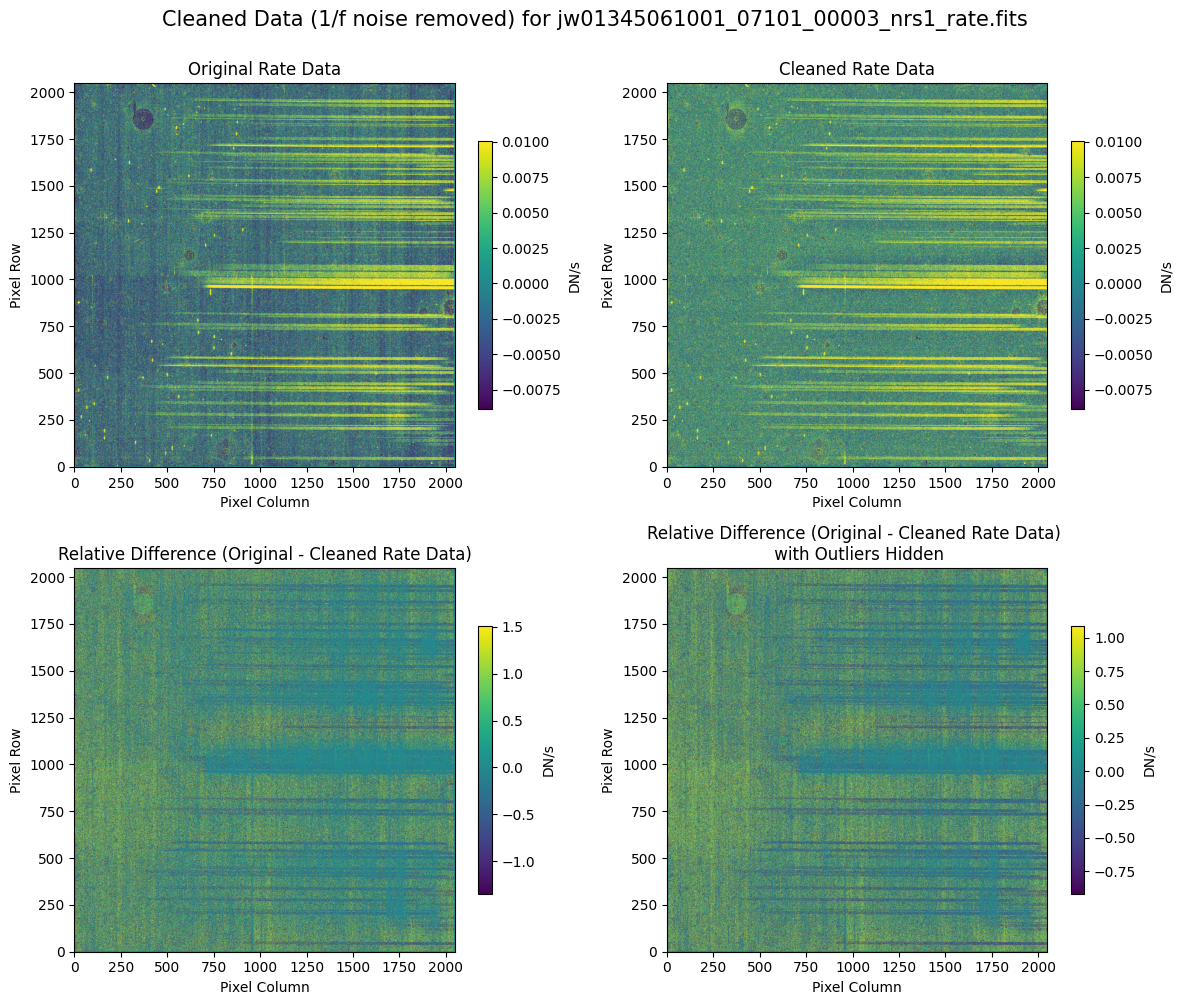
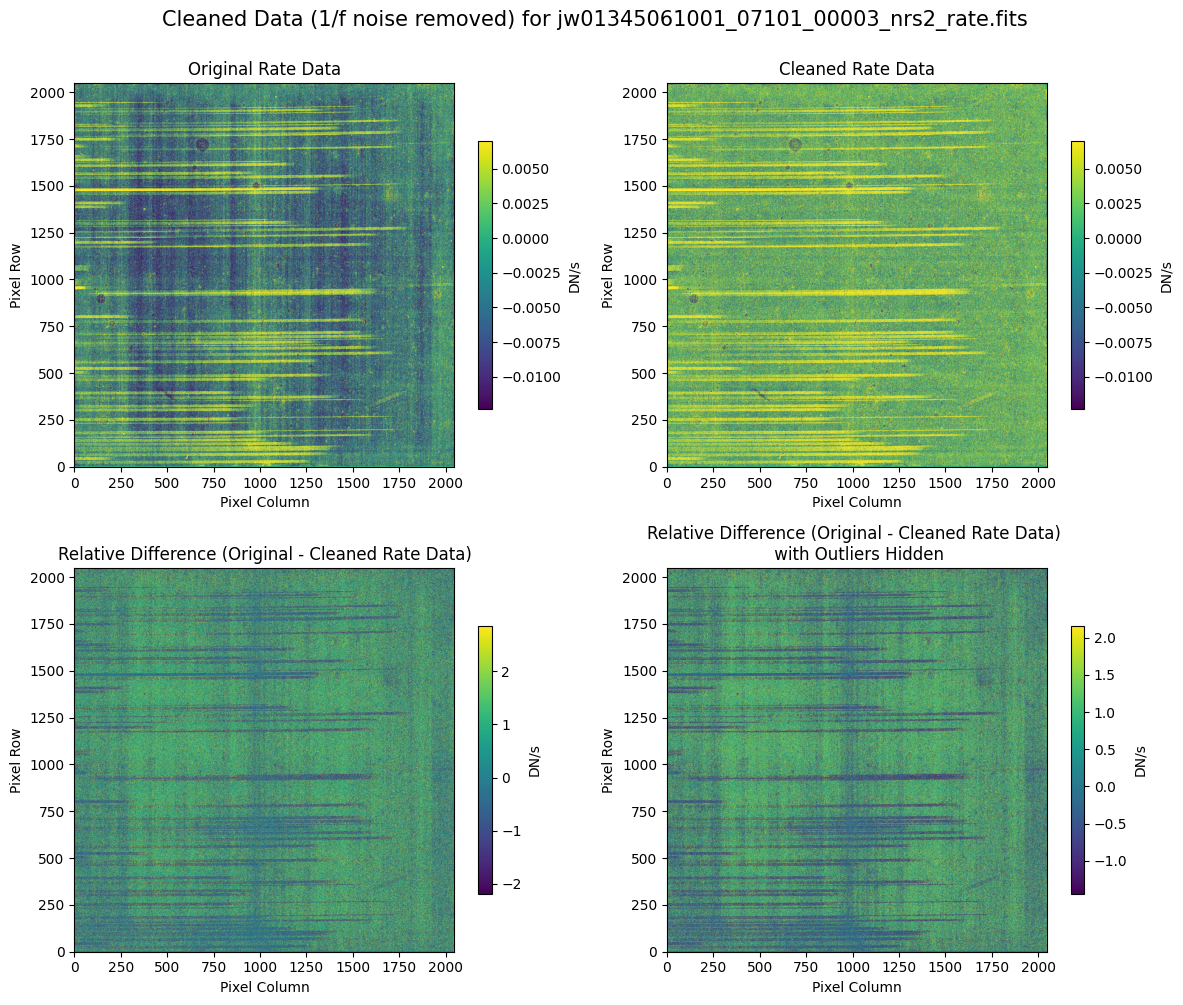
Compare the extracted spectrum from the cleaned data to the spectrum extracted from the original rate file.
x1d_nsclean_alternate = [
stage2_nsclean_alternate_dir + "jw01345061001_07101_00003_nrs1_x1d.fits",
stage2_nsclean_alternate_dir + "jw01345061001_07101_00003_nrs2_x1d.fits",
]
for original, cleaned in zip(x1d_nsclean_skipped, x1d_nsclean_alternate):
plot_spectra([original, cleaned], scale_percent=9)
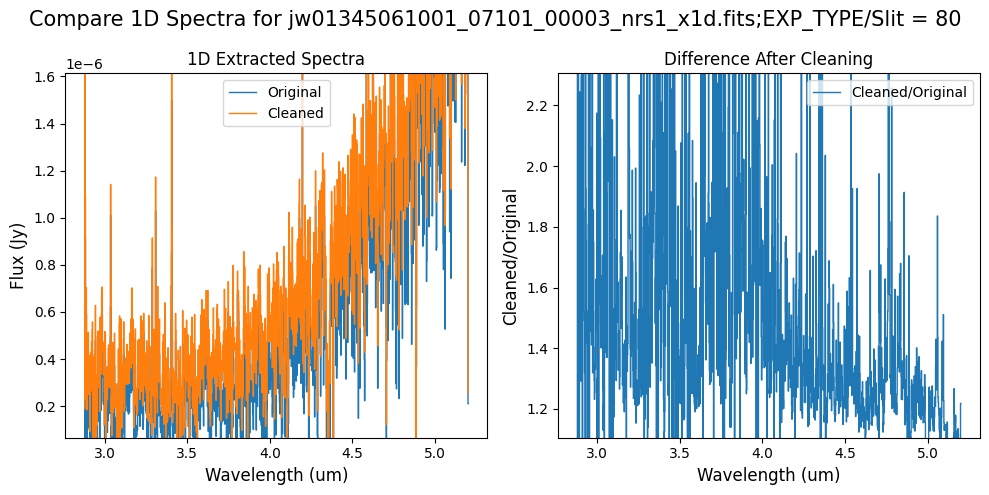
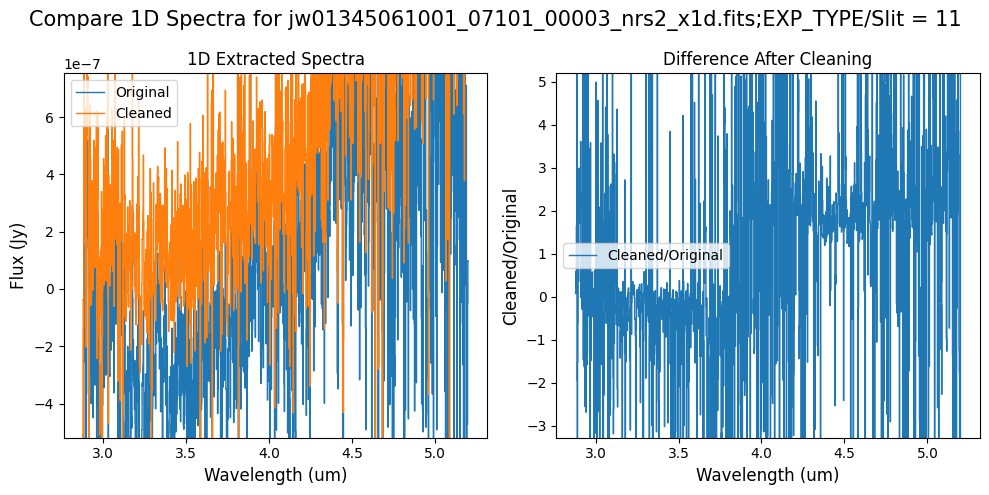
Notes:
In slit 80 on NRS1 and in slit 11 on NRS2, the overall continuum level has been slightly altered by the cleaning process (similar to the default masking).
In slit 11 on NRS2, some of the negative flux in the original spectrum has been corrected. The high-frequency noise introduced by the default masking, which affected slit 11 between 4.5 - 5.0 um (resulting in a negative dip in the spectrum), is improved with the alternate masking.
7. Clean up 1/f Noise with NSClean (Hand-Modified Mask) #
In certain scenarios, manual generation of a mask may be required. Here, we present **one** approach to manually modify the mask (editing an overly masked region in NRS2 around x=1000, y=600 to include more background; excluding some large snowballs in NRS1), starting with the default mask output from the pipeline. It is worth noting that the mask modified using this method may not necessarily outperform the two previous options.
# Set up directory for running NSClean with user-supplied mask.
stage2_nsclean_modified_dir = "./stage2_nsclean_modified/"
if not os.path.exists(stage2_nsclean_modified_dir):
# Create the directory if it doesn't exist.
os.makedirs(stage2_nsclean_modified_dir)
# Hand-modify certain mask regions.
# Specifically modifying the region in NRS2 around x=1000, y=600.
# Define the list to store paths of modified masks.
nsclean_modified_masks = []
# Iterate through the list of original masks.
for mask in nsclean_default_masks:
# New mask file name.
output_file = os.path.basename(mask)[:-5] + "_modified.fits"
# Open the FITS file.
with fits.open(mask) as hdul:
# Extract the mask data from the science extension.
mask_data = hdul["SCI"].data.copy() # Make a copy.
if "nrs2" in mask:
# Step 1: Set the default masked regions back to True.
mask_data[550:651, :1300] = True
# Step 2: Re-define masked regions by hand.
mask_data[550:575, :1300] = False # Crowded region NRS2.
mask_data[590:615, 150:1720] = False
mask_data[622:647, 100:1620] = False
else:
mask_data[50:130, 780:850] = False # Snowballs
mask_data[110:140, 920:945] = False
mask_data[820:940, 2000:2040] = False
mask_data[1650:1700, 1900:1960] = False
mask_data[1800:1900, 330:410] = False
# Update the data within the science extension.
hdul["SCI"].data = mask_data
# Save the modified FITS file
output_path = os.path.join(stage2_nsclean_modified_dir, output_file)
hdul_modified = hdul.copy() # Make a copy.
hdul_modified.writeto(output_path, overwrite=True)
nsclean_modified_masks.append(output_path)
print(f"Saved modified mask as: {output_path}")
Saved modified mask as: ./stage2_nsclean_modified/jw01345061001_07101_00003_nrs1_mask_modified.fits
Saved modified mask as: ./stage2_nsclean_modified/jw01345061001_07101_00003_nrs2_mask_modified.fits
7.1 Verify the Mask (Hand-Modified Mask) #
Check the mask against the rate data to make sure it keeps only dark areas of the detector.
# Plot the rate data with masked areas blocked.
# List of modified masks for the pipeline.
nsclean_modified_masks = [
stage2_nsclean_modified_dir + "jw01345061001_07101_00003_nrs1_mask_modified.fits",
stage2_nsclean_modified_dir + "jw01345061001_07101_00003_nrs2_mask_modified.fits",
]
# Plot each associated set of rateint data and mask file.
for rate_file, mask_file in zip(rate_names, nsclean_modified_masks):
plot_dark_data(mast_products_dir + rate_file, mask_file, layout="columns", scale=9)
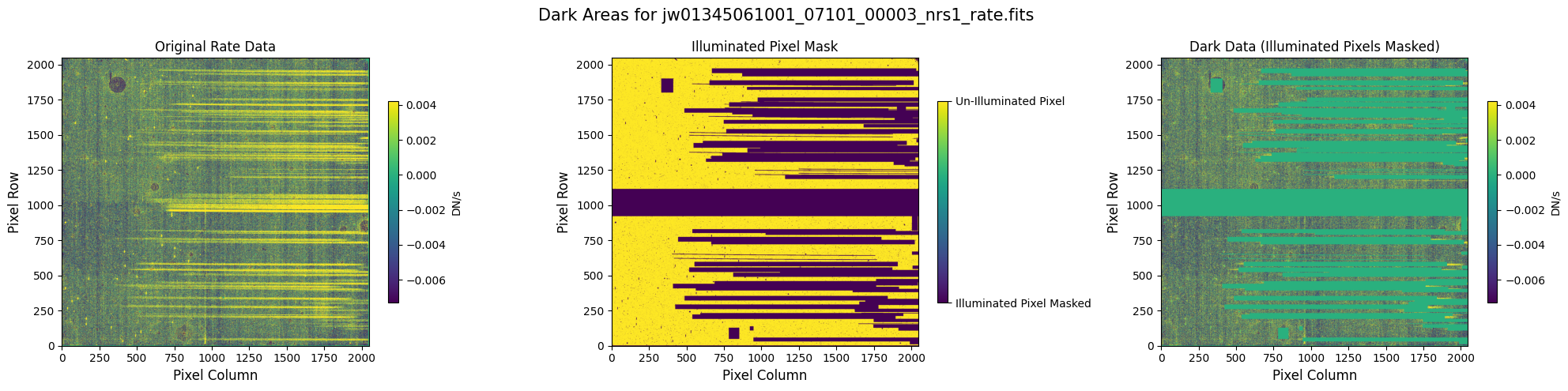
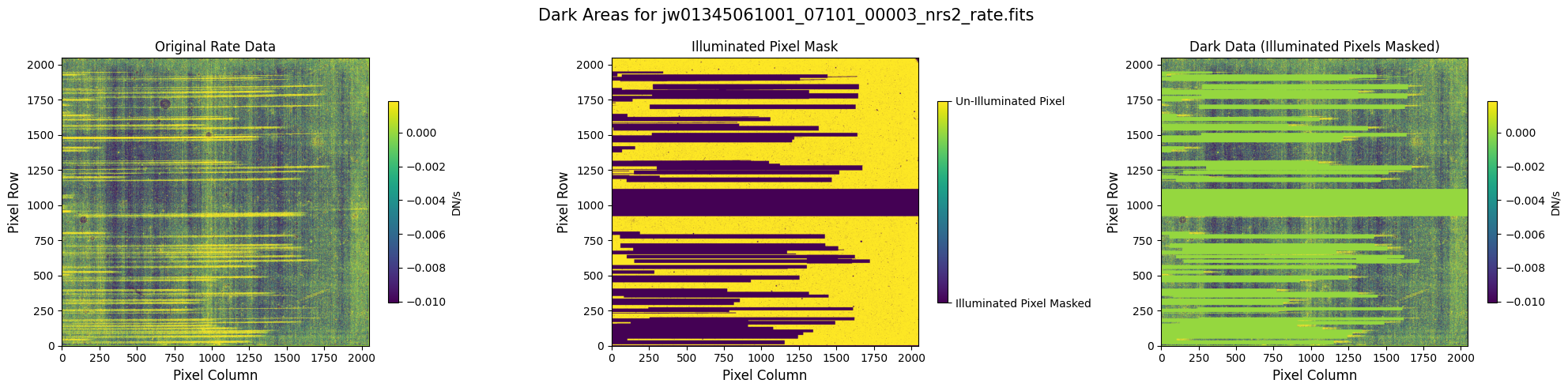
# 1/f noise cleaned data (user-supplied mask).
# Estimated run time: 5 minutes.
start = tt.time()
for indx, i in enumerate(rate_names):
print(f"Processing {i}...")
if "nrs1" in i:
slit_name = "80"
else:
slit_name = "11"
Spec2Pipeline.call(
mast_products_dir + i,
save_results=True,
steps={
"nsclean": {
"skip": False,
"save_mask": True,
"save_results": True,
"user_mask": nsclean_modified_masks[indx],
},
"extract_2d": {"slit_names": slit_name},
},
output_dir=stage2_nsclean_modified_dir,
)
print(f"Saved {i[:-9]}" + "mask.fits")
print(f"Saved {i[:-9]}" + "nsclean.fits")
print(f"Saved {i[:-9]}" + "cal.fits")
print(f"Saved {i[:-9]}" + "x1d.fits")
end = tt.time()
print("Run time: ", round(end - start, 1) / 60.0, " min")
2026-04-22 19:11:31,134 - stpipe.step - INFO - PARS-RESAMPLESPECSTEP parameters found: /home/runner/crds_cache/references/jwst/nirspec/jwst_nirspec_pars-resamplespecstep_0001.asdf
2026-04-22 19:11:31,150 - stpipe.step - INFO - PARS-RESAMPLESPECSTEP parameters found: /home/runner/crds_cache/references/jwst/nirspec/jwst_nirspec_pars-resamplespecstep_0001.asdf
2026-04-22 19:11:31,171 - stpipe.step - INFO - Spec2Pipeline instance created.
2026-04-22 19:11:31,173 - stpipe.step - INFO - AssignWcsStep instance created.
2026-04-22 19:11:31,174 - stpipe.step - INFO - BadpixSelfcalStep instance created.
2026-04-22 19:11:31,174 - stpipe.step - INFO - MSAFlagOpenStep instance created.
2026-04-22 19:11:31,176 - stpipe.step - INFO - NSCleanStep instance created.
2026-04-22 19:11:31,177 - stpipe.step - INFO - BackgroundStep instance created.
2026-04-22 19:11:31,177 - stpipe.step - INFO - ImprintStep instance created.
2026-04-22 19:11:31,178 - stpipe.step - INFO - Extract2dStep instance created.
2026-04-22 19:11:31,182 - stpipe.step - INFO - MasterBackgroundMosStep instance created.
2026-04-22 19:11:31,183 - stpipe.step - INFO - FlatFieldStep instance created.
2026-04-22 19:11:31,184 - stpipe.step - INFO - PathLossStep instance created.
2026-04-22 19:11:31,186 - stpipe.step - INFO - BarShadowStep instance created.
2026-04-22 19:11:31,186 - stpipe.step - INFO - PhotomStep instance created.
2026-04-22 19:11:31,187 - stpipe.step - INFO - PixelReplaceStep instance created.
2026-04-22 19:11:31,189 - stpipe.step - INFO - ResampleSpecStep instance created.
2026-04-22 19:11:31,190 - stpipe.step - INFO - Extract1dStep instance created.
2026-04-22 19:11:31,191 - stpipe.step - INFO - WavecorrStep instance created.
2026-04-22 19:11:31,192 - stpipe.step - INFO - FlatFieldStep instance created.
2026-04-22 19:11:31,192 - stpipe.step - INFO - SourceTypeStep instance created.
2026-04-22 19:11:31,193 - stpipe.step - INFO - StraylightStep instance created.
2026-04-22 19:11:31,194 - stpipe.step - INFO - FringeStep instance created.
2026-04-22 19:11:31,195 - stpipe.step - INFO - ResidualFringeStep instance created.
2026-04-22 19:11:31,196 - stpipe.step - INFO - PathLossStep instance created.
2026-04-22 19:11:31,197 - stpipe.step - INFO - BarShadowStep instance created.
2026-04-22 19:11:31,198 - stpipe.step - INFO - WfssContamStep instance created.
2026-04-22 19:11:31,199 - stpipe.step - INFO - PhotomStep instance created.
2026-04-22 19:11:31,200 - stpipe.step - INFO - PixelReplaceStep instance created.
2026-04-22 19:11:31,201 - stpipe.step - INFO - ResampleSpecStep instance created.
2026-04-22 19:11:31,202 - stpipe.step - INFO - CubeBuildStep instance created.
2026-04-22 19:11:31,204 - stpipe.step - INFO - Extract1dStep instance created.
2026-04-22 19:11:31,414 - stpipe.step - INFO - Step Spec2Pipeline running with args ('./mast_products/jw01345061001_07101_00003_nrs1_rate.fits',).
Processing jw01345061001_07101_00003_nrs1_rate.fits...
2026-04-22 19:11:31,443 - stpipe.step - INFO - Step Spec2Pipeline parameters are:
pre_hooks: []
post_hooks: []
output_file: None
output_dir: ./stage2_nsclean_modified/
output_ext: .fits
output_use_model: False
output_use_index: True
save_results: True
skip: False
suffix: None
search_output_file: True
input_dir: ''
save_bsub: False
fail_on_exception: True
save_wfss_esec: False
steps:
assign_wcs:
pre_hooks: []
post_hooks: []
output_file: None
output_dir: None
output_ext: .fits
output_use_model: False
output_use_index: True
save_results: False
skip: False
suffix: None
search_output_file: True
input_dir: ''
sip_approx: True
sip_max_pix_error: 0.01
sip_degree: None
sip_max_inv_pix_error: 0.01
sip_inv_degree: None
sip_npoints: 12
slit_y_low: -0.55
slit_y_high: 0.55
nrs_ifu_slice_wcs: False
badpix_selfcal:
pre_hooks: []
post_hooks: []
output_file: None
output_dir: None
output_ext: .fits
output_use_model: False
output_use_index: True
save_results: False
skip: True
suffix: None
search_output_file: True
input_dir: ''
flagfrac_lower: 0.001
flagfrac_upper: 0.001
kernel_size: 15
force_single: False
save_flagged_bkg: False
msa_flagging:
pre_hooks: []
post_hooks: []
output_file: None
output_dir: None
output_ext: .fits
output_use_model: False
output_use_index: True
save_results: False
skip: False
suffix: None
search_output_file: True
input_dir: ''
nsclean:
pre_hooks: []
post_hooks: []
output_file: None
output_dir: None
output_ext: .fits
output_use_model: False
output_use_index: True
save_results: True
skip: False
suffix: None
search_output_file: True
input_dir: ''
fit_method: fft
fit_by_channel: False
background_method: None
background_box_size: None
mask_spectral_regions: True
n_sigma: 5.0
fit_histogram: False
single_mask: False
user_mask: ./stage2_nsclean_modified/jw01345061001_07101_00003_nrs1_mask_modified.fits
save_mask: True
save_background: False
save_noise: False
bkg_subtract:
pre_hooks: []
post_hooks: []
output_file: None
output_dir: None
output_ext: .fits
output_use_model: False
output_use_index: True
save_results: False
skip: False
suffix: None
search_output_file: True
input_dir: ''
bkg_list: None
save_combined_background: False
sigma: 3.0
maxiters: None
soss_source_percentile: 35.0
soss_bkg_percentile: None
wfss_mmag_extract: None
wfss_maxiter: 5
wfss_rms_stop: 0.0
wfss_outlier_percent: 1.0
imprint_subtract:
pre_hooks: []
post_hooks: []
output_file: None
output_dir: None
output_ext: .fits
output_use_model: False
output_use_index: True
save_results: False
skip: False
suffix: None
search_output_file: True
input_dir: ''
extract_2d:
pre_hooks: []
post_hooks: []
output_file: None
output_dir: None
output_ext: .fits
output_use_model: False
output_use_index: True
save_results: False
skip: False
suffix: None
search_output_file: True
input_dir: ''
slit_names:
- '80'
source_ids: None
extract_orders: None
grism_objects: None
tsgrism_extract_height: None
wfss_extract_half_height: 5
wfss_mmag_extract: None
wfss_nbright: 1000
master_background_mos:
pre_hooks: []
post_hooks: []
output_file: None
output_dir: None
output_ext: .fits
output_use_model: True
output_use_index: True
save_results: False
skip: False
suffix: None
search_output_file: True
input_dir: ''
sigma_clip: 3.0
median_kernel: 1
force_subtract: False
save_background: False
user_background: None
inverse: False
steps:
flat_field:
pre_hooks: []
post_hooks: []
output_file: None
output_dir: None
output_ext: .fits
output_use_model: False
output_use_index: True
save_results: False
skip: False
suffix: None
search_output_file: True
input_dir: ''
save_interpolated_flat: False
user_supplied_flat: None
inverse: False
pathloss:
pre_hooks: []
post_hooks: []
output_file: None
output_dir: None
output_ext: .fits
output_use_model: False
output_use_index: True
save_results: False
skip: False
suffix: None
search_output_file: True
input_dir: ''
inverse: False
source_type: None
user_slit_loc: None
barshadow:
pre_hooks: []
post_hooks: []
output_file: None
output_dir: None
output_ext: .fits
output_use_model: False
output_use_index: True
save_results: False
skip: False
suffix: None
search_output_file: True
input_dir: ''
inverse: False
source_type: None
photom:
pre_hooks: []
post_hooks: []
output_file: None
output_dir: None
output_ext: .fits
output_use_model: False
output_use_index: True
save_results: False
skip: False
suffix: None
search_output_file: True
input_dir: ''
inverse: False
source_type: None
apply_time_correction: True
pixel_replace:
pre_hooks: []
post_hooks: []
output_file: None
output_dir: None
output_ext: .fits
output_use_model: True
output_use_index: True
save_results: False
skip: True
suffix: None
search_output_file: True
input_dir: ''
algorithm: fit_profile
n_adjacent_cols: 3
resample_spec:
pre_hooks: []
post_hooks: []
output_file: None
output_dir: None
output_ext: .fits
output_use_model: False
output_use_index: True
save_results: False
skip: False
suffix: None
search_output_file: True
input_dir: ''
pixfrac: 1.0
kernel: square
fillval: NaN
weight_type: exptime
output_shape: None
pixel_scale_ratio: 1.0
pixel_scale: None
output_wcs: ''
single: False
blendheaders: True
in_memory: True
extract_1d:
pre_hooks: []
post_hooks: []
output_file: None
output_dir: None
output_ext: .fits
output_use_model: False
output_use_index: True
save_results: False
skip: False
suffix: None
search_output_file: True
input_dir: ''
subtract_background: None
apply_apcorr: True
extraction_type: box
use_source_posn: None
position_offset: 0.0
model_nod_pair: True
optimize_psf_location: True
smoothing_length: None
bkg_fit: None
bkg_order: None
log_increment: 50
save_profile: False
save_scene_model: False
save_residual_image: False
center_xy: None
ifu_autocen: False
bkg_sigma_clip: 3.0
ifu_rfcorr: True
ifu_set_srctype: None
ifu_rscale: None
ifu_covar_scale: 1.0
soss_atoca: True
soss_threshold: 0.01
soss_n_os: 2
soss_wave_grid_in: None
soss_wave_grid_out: None
soss_estimate: None
soss_rtol: 0.0001
soss_max_grid_size: 20000
soss_tikfac: None
soss_width: 40.0
soss_bad_pix: masking
soss_modelname: None
soss_order_3: True
wavecorr:
pre_hooks: []
post_hooks: []
output_file: None
output_dir: None
output_ext: .fits
output_use_model: False
output_use_index: True
save_results: False
skip: False
suffix: None
search_output_file: True
input_dir: ''
flat_field:
pre_hooks: []
post_hooks: []
output_file: None
output_dir: None
output_ext: .fits
output_use_model: False
output_use_index: True
save_results: False
skip: False
suffix: None
search_output_file: True
input_dir: ''
save_interpolated_flat: False
user_supplied_flat: None
inverse: False
srctype:
pre_hooks: []
post_hooks: []
output_file: None
output_dir: None
output_ext: .fits
output_use_model: False
output_use_index: True
save_results: False
skip: False
suffix: None
search_output_file: True
input_dir: ''
source_type: None
straylight:
pre_hooks: []
post_hooks: []
output_file: None
output_dir: None
output_ext: .fits
output_use_model: False
output_use_index: True
save_results: False
skip: False
suffix: None
search_output_file: True
input_dir: ''
clean_showers: False
shower_plane: 3
shower_x_stddev: 18.0
shower_y_stddev: 5.0
shower_low_reject: 0.1
shower_high_reject: 99.9
save_shower_model: False
fringe:
pre_hooks: []
post_hooks: []
output_file: None
output_dir: None
output_ext: .fits
output_use_model: False
output_use_index: True
save_results: False
skip: False
suffix: None
search_output_file: True
input_dir: ''
residual_fringe:
pre_hooks: []
post_hooks: []
output_file: None
output_dir: None
output_ext: .fits
output_use_model: False
output_use_index: True
save_results: False
skip: True
suffix: residual_fringe
search_output_file: False
input_dir: ''
save_intermediate_results: False
ignore_region_min: None
ignore_region_max: None
pathloss:
pre_hooks: []
post_hooks: []
output_file: None
output_dir: None
output_ext: .fits
output_use_model: False
output_use_index: True
save_results: False
skip: False
suffix: None
search_output_file: True
input_dir: ''
inverse: False
source_type: None
user_slit_loc: None
barshadow:
pre_hooks: []
post_hooks: []
output_file: None
output_dir: None
output_ext: .fits
output_use_model: False
output_use_index: True
save_results: False
skip: False
suffix: None
search_output_file: True
input_dir: ''
inverse: False
source_type: None
wfss_contam:
pre_hooks: []
post_hooks: []
output_file: None
output_dir: None
output_ext: .fits
output_use_model: False
output_use_index: True
save_results: False
skip: True
suffix: None
search_output_file: True
input_dir: ''
save_simulated_image: False
save_contam_images: False
maximum_cores: none
orders: None
magnitude_limit: None
wl_oversample: 2
max_pixels_per_chunk: 50000
photom:
pre_hooks: []
post_hooks: []
output_file: None
output_dir: None
output_ext: .fits
output_use_model: False
output_use_index: True
save_results: False
skip: False
suffix: None
search_output_file: True
input_dir: ''
inverse: False
source_type: None
apply_time_correction: True
pixel_replace:
pre_hooks: []
post_hooks: []
output_file: None
output_dir: None
output_ext: .fits
output_use_model: True
output_use_index: True
save_results: False
skip: True
suffix: None
search_output_file: True
input_dir: ''
algorithm: fit_profile
n_adjacent_cols: 3
resample_spec:
pre_hooks: []
post_hooks: []
output_file: None
output_dir: None
output_ext: .fits
output_use_model: False
output_use_index: True
save_results: False
skip: False
suffix: None
search_output_file: True
input_dir: ''
pixfrac: 1.0
kernel: square
fillval: NaN
weight_type: exptime
output_shape: None
pixel_scale_ratio: 1.0
pixel_scale: None
output_wcs: ''
single: False
blendheaders: True
in_memory: True
cube_build:
pre_hooks: []
post_hooks: []
output_file: None
output_dir: None
output_ext: .fits
output_use_model: True
output_use_index: True
save_results: False
skip: False
suffix: s3d
search_output_file: False
input_dir: ''
pipeline: 3
channel: all
band: all
grating: all
filter: all
output_type: None
scalexy: 0.0
scalew: 0.0
weighting: drizzle
coord_system: skyalign
ra_center: None
dec_center: None
cube_pa: None
nspax_x: None
nspax_y: None
rois: 0.0
roiw: 0.0
weight_power: 2.0
wavemin: None
wavemax: None
single: False
skip_dqflagging: False
offset_file: None
debug_spaxel: -1 -1 -1
extract_1d:
pre_hooks: []
post_hooks: []
output_file: None
output_dir: None
output_ext: .fits
output_use_model: False
output_use_index: True
save_results: False
skip: False
suffix: None
search_output_file: True
input_dir: ''
subtract_background: None
apply_apcorr: True
extraction_type: box
use_source_posn: None
position_offset: 0.0
model_nod_pair: True
optimize_psf_location: True
smoothing_length: None
bkg_fit: None
bkg_order: None
log_increment: 50
save_profile: False
save_scene_model: False
save_residual_image: False
center_xy: None
ifu_autocen: False
bkg_sigma_clip: 3.0
ifu_rfcorr: True
ifu_set_srctype: None
ifu_rscale: None
ifu_covar_scale: 1.0
soss_atoca: True
soss_threshold: 0.01
soss_n_os: 2
soss_wave_grid_in: None
soss_wave_grid_out: None
soss_estimate: None
soss_rtol: 0.0001
soss_max_grid_size: 20000
soss_tikfac: None
soss_width: 40.0
soss_bad_pix: masking
soss_modelname: None
soss_order_3: True
2026-04-22 19:11:31,475 - stpipe.pipeline - INFO - Prefetching reference files for dataset: 'jw01345061001_07101_00003_nrs1_rate.fits' reftypes = ['apcorr', 'area', 'barshadow', 'bkg', 'camera', 'collimator', 'cubepar', 'dflat', 'disperser', 'distortion', 'extract1d', 'fflat', 'filteroffset', 'flat', 'fore', 'fpa', 'fringe', 'ifufore', 'ifupost', 'ifuslicer', 'mrsxartcorr', 'msa', 'msaoper', 'ote', 'pastasoss', 'pathloss', 'photom', 'psf', 'regions', 'sflat', 'speckernel', 'specprofile', 'specwcs', 'wavecorr', 'wavelengthrange']
2026-04-22 19:11:31,479 - stpipe.pipeline - INFO - Prefetch for APCORR reference file is '/home/runner/crds_cache/references/jwst/nirspec/jwst_nirspec_apcorr_0004.fits'.
2026-04-22 19:11:31,480 - stpipe.pipeline - INFO - Prefetch for AREA reference file is '/home/runner/crds_cache/references/jwst/nirspec/jwst_nirspec_area_0051.fits'.
2026-04-22 19:11:31,481 - stpipe.pipeline - INFO - Prefetch for BARSHADOW reference file is '/home/runner/crds_cache/references/jwst/nirspec/jwst_nirspec_barshadow_0008.fits'.
2026-04-22 19:11:31,481 - stpipe.pipeline - INFO - Prefetch for BKG reference file is 'N/A'.
2026-04-22 19:11:31,482 - stpipe.pipeline - INFO - Prefetch for CAMERA reference file is '/home/runner/crds_cache/references/jwst/nirspec/jwst_nirspec_camera_0008.asdf'.
2026-04-22 19:11:31,483 - stpipe.pipeline - INFO - Prefetch for COLLIMATOR reference file is '/home/runner/crds_cache/references/jwst/nirspec/jwst_nirspec_collimator_0008.asdf'.
2026-04-22 19:11:31,483 - stpipe.pipeline - INFO - Prefetch for CUBEPAR reference file is 'N/A'.
2026-04-22 19:11:31,484 - stpipe.pipeline - INFO - Prefetch for DFLAT reference file is '/home/runner/crds_cache/references/jwst/nirspec/jwst_nirspec_dflat_0001.fits'.
2026-04-22 19:11:31,484 - stpipe.pipeline - INFO - Prefetch for DISPERSER reference file is '/home/runner/crds_cache/references/jwst/nirspec/jwst_nirspec_disperser_0068.asdf'.
2026-04-22 19:11:31,485 - stpipe.pipeline - INFO - Prefetch for DISTORTION reference file is 'N/A'.
2026-04-22 19:11:31,486 - stpipe.pipeline - INFO - Prefetch for EXTRACT1D reference file is '/home/runner/crds_cache/references/jwst/nirspec/jwst_nirspec_extract1d_0009.json'.
2026-04-22 19:11:31,486 - stpipe.pipeline - INFO - Prefetch for FFLAT reference file is '/home/runner/crds_cache/references/jwst/nirspec/jwst_nirspec_fflat_0167.fits'.
2026-04-22 19:11:31,487 - stpipe.pipeline - INFO - Prefetch for FILTEROFFSET reference file is 'N/A'.
2026-04-22 19:11:31,487 - stpipe.pipeline - INFO - Prefetch for FLAT reference file is 'N/A'.
2026-04-22 19:11:31,488 - stpipe.pipeline - INFO - Prefetch for FORE reference file is '/home/runner/crds_cache/references/jwst/nirspec/jwst_nirspec_fore_0051.asdf'.
2026-04-22 19:11:31,489 - stpipe.pipeline - INFO - Prefetch for FPA reference file is '/home/runner/crds_cache/references/jwst/nirspec/jwst_nirspec_fpa_0009.asdf'.
2026-04-22 19:11:31,489 - stpipe.pipeline - INFO - Prefetch for FRINGE reference file is 'N/A'.
2026-04-22 19:11:31,490 - stpipe.pipeline - INFO - Prefetch for IFUFORE reference file is 'N/A'.
2026-04-22 19:11:31,490 - stpipe.pipeline - INFO - Prefetch for IFUPOST reference file is 'N/A'.
2026-04-22 19:11:31,490 - stpipe.pipeline - INFO - Prefetch for IFUSLICER reference file is 'N/A'.
2026-04-22 19:11:31,491 - stpipe.pipeline - INFO - Prefetch for MRSXARTCORR reference file is 'N/A'.
2026-04-22 19:11:31,492 - stpipe.pipeline - INFO - Prefetch for MSA reference file is '/home/runner/crds_cache/references/jwst/nirspec/jwst_nirspec_msa_0009.asdf'.
2026-04-22 19:11:31,492 - stpipe.pipeline - INFO - Prefetch for MSAOPER reference file is '/home/runner/crds_cache/references/jwst/nirspec/jwst_nirspec_msaoper_0006.json'.
2026-04-22 19:11:31,493 - stpipe.pipeline - INFO - Prefetch for OTE reference file is '/home/runner/crds_cache/references/jwst/nirspec/jwst_nirspec_ote_0011.asdf'.
2026-04-22 19:11:31,494 - stpipe.pipeline - INFO - Prefetch for PASTASOSS reference file is 'N/A'.
2026-04-22 19:11:31,494 - stpipe.pipeline - INFO - Prefetch for PATHLOSS reference file is '/home/runner/crds_cache/references/jwst/nirspec/jwst_nirspec_pathloss_0010.fits'.
2026-04-22 19:11:31,495 - stpipe.pipeline - INFO - Prefetch for PHOTOM reference file is '/home/runner/crds_cache/references/jwst/nirspec/jwst_nirspec_photom_0015.fits'.
2026-04-22 19:11:31,495 - stpipe.pipeline - INFO - Prefetch for PSF reference file is 'N/A'.
2026-04-22 19:11:31,496 - stpipe.pipeline - INFO - Prefetch for REGIONS reference file is 'N/A'.
2026-04-22 19:11:31,496 - stpipe.pipeline - INFO - Prefetch for SFLAT reference file is '/home/runner/crds_cache/references/jwst/nirspec/jwst_nirspec_sflat_0225.fits'.
2026-04-22 19:11:31,497 - stpipe.pipeline - INFO - Prefetch for SPECKERNEL reference file is 'N/A'.
2026-04-22 19:11:31,498 - stpipe.pipeline - INFO - Prefetch for SPECPROFILE reference file is 'N/A'.
2026-04-22 19:11:31,498 - stpipe.pipeline - INFO - Prefetch for SPECWCS reference file is 'N/A'.
2026-04-22 19:11:31,499 - stpipe.pipeline - INFO - Prefetch for WAVECORR reference file is '/home/runner/crds_cache/references/jwst/nirspec/jwst_nirspec_wavecorr_0004.asdf'.
2026-04-22 19:11:31,499 - stpipe.pipeline - INFO - Prefetch for WAVELENGTHRANGE reference file is '/home/runner/crds_cache/references/jwst/nirspec/jwst_nirspec_wavelengthrange_0006.asdf'.
2026-04-22 19:11:31,500 - jwst.pipeline.calwebb_spec2 - INFO - Starting calwebb_spec2 ...
2026-04-22 19:11:31,501 - jwst.pipeline.calwebb_spec2 - INFO - Processing product mast_products/jw01345061001_07101_00003_nrs1
2026-04-22 19:11:31,501 - jwst.pipeline.calwebb_spec2 - INFO - Working on input ./mast_products/jw01345061001_07101_00003_nrs1_rate.fits ...
2026-04-22 19:11:31,727 - stpipe.step - INFO - Step assign_wcs running with args (<ImageModel(2048, 2048) from jw01345061001_07101_00003_nrs1_rate.fits>,).
2026-04-22 19:11:31,821 - jwst.assign_wcs.nirspec - INFO - Retrieving open MSA slitlets for msa_metadata_id = 83 and dither_index = 3
2026-04-22 19:11:31,829 - jwst.assign_wcs.nirspec - INFO - Slitlet 3 is background only; assigned source_id=3
2026-04-22 19:11:31,830 - jwst.assign_wcs.nirspec - INFO - Slitlet 4 is background only; assigned source_id=4
2026-04-22 19:11:31,831 - jwst.assign_wcs.nirspec - INFO - Slitlet 5 is background only; assigned source_id=5
2026-04-22 19:11:31,839 - jwst.assign_wcs.nirspec - INFO - Slitlet 9 is background only; assigned source_id=9
2026-04-22 19:11:31,841 - jwst.assign_wcs.nirspec - INFO - Slitlet 10 contains virtual source, with source_id=-59
2026-04-22 19:11:31,844 - jwst.assign_wcs.nirspec - INFO - Slitlet 12 is background only; assigned source_id=12
2026-04-22 19:11:31,845 - jwst.assign_wcs.nirspec - INFO - Slitlet 13 is background only; assigned source_id=13
2026-04-22 19:11:31,846 - jwst.assign_wcs.nirspec - INFO - Slitlet 14 is background only; assigned source_id=14
2026-04-22 19:11:31,849 - jwst.assign_wcs.nirspec - INFO - Slitlet 15 contains virtual source, with source_id=-63
2026-04-22 19:11:31,854 - jwst.assign_wcs.nirspec - INFO - Slitlet 18 is background only; assigned source_id=18
2026-04-22 19:11:31,855 - jwst.assign_wcs.nirspec - INFO - Slitlet 19 is background only; assigned source_id=19
2026-04-22 19:11:31,862 - jwst.assign_wcs.nirspec - INFO - Slitlet 23 is background only; assigned source_id=23
2026-04-22 19:11:31,870 - jwst.assign_wcs.nirspec - INFO - Slitlet 27 is background only; assigned source_id=27
2026-04-22 19:11:31,871 - jwst.assign_wcs.nirspec - INFO - Slitlet 28 is background only; assigned source_id=28
2026-04-22 19:11:31,882 - jwst.assign_wcs.nirspec - INFO - Slitlet 34 is background only; assigned source_id=34
2026-04-22 19:11:31,911 - jwst.assign_wcs.nirspec - INFO - Slitlet 48 is background only; assigned source_id=48
2026-04-22 19:11:31,924 - jwst.assign_wcs.nirspec - INFO - Slitlet 55 is background only; assigned source_id=55
2026-04-22 19:11:31,929 - jwst.assign_wcs.nirspec - INFO - Slitlet 57 contains virtual source, with source_id=-72
2026-04-22 19:11:31,939 - jwst.assign_wcs.nirspec - INFO - Slitlet 62 is background only; assigned source_id=62
2026-04-22 19:11:31,944 - jwst.assign_wcs.nirspec - INFO - Slitlet 64 contains virtual source, with source_id=-74
2026-04-22 19:11:31,948 - jwst.assign_wcs.nirspec - INFO - Slitlet 67 is background only; assigned source_id=67
2026-04-22 19:11:31,950 - jwst.assign_wcs.nirspec - INFO - Slitlet 68 is background only; assigned source_id=68
2026-04-22 19:11:31,953 - jwst.assign_wcs.nirspec - INFO - Slitlet 69 contains virtual source, with source_id=-77
2026-04-22 19:11:31,953 - jwst.assign_wcs.nirspec - INFO - Slitlet 70 is background only; assigned source_id=70
2026-04-22 19:11:31,954 - jwst.assign_wcs.nirspec - INFO - Slitlet 71 is background only; assigned source_id=71
2026-04-22 19:11:31,960 - jwst.assign_wcs.nirspec - INFO - Slitlet 74 is background only; assigned source_id=74
2026-04-22 19:11:31,968 - jwst.assign_wcs.nirspec - INFO - Slitlet 78 is background only; assigned source_id=78
2026-04-22 19:11:31,999 - jwst.assign_wcs.nirspec - INFO - gwa_ytilt is 0.177384809 deg
2026-04-22 19:11:31,999 - jwst.assign_wcs.nirspec - INFO - gwa_xtilt is 0.278486848 deg
2026-04-22 19:11:32,000 - jwst.assign_wcs.nirspec - INFO - theta_y correction: 0.0057073669713260085 deg
2026-04-22 19:11:32,001 - jwst.assign_wcs.nirspec - INFO - theta_x correction: 7.258633810078802e-05 deg
2026-04-22 19:11:32,180 - jwst.assign_wcs.nirspec - INFO - Removing slit 2 from the list of open slits because the WCS bounding_box is completely outside the detector.
2026-04-22 19:11:32,196 - jwst.assign_wcs.nirspec - INFO - Removing slit 5 from the list of open slits because the WCS bounding_box is completely outside the detector.
2026-04-22 19:11:32,211 - jwst.assign_wcs.nirspec - INFO - Removing slit 6 from the list of open slits because the WCS bounding_box is completely outside the detector.
2026-04-22 19:11:32,227 - jwst.assign_wcs.nirspec - INFO - Removing slit 8 from the list of open slits because the WCS bounding_box is completely outside the detector.
2026-04-22 19:11:32,242 - jwst.assign_wcs.nirspec - INFO - Removing slit 9 from the list of open slits because the WCS bounding_box is completely outside the detector.
2026-04-22 19:11:32,259 - jwst.assign_wcs.nirspec - INFO - Removing slit 13 from the list of open slits because the WCS bounding_box is completely outside the detector.
2026-04-22 19:11:32,274 - jwst.assign_wcs.nirspec - INFO - Removing slit 15 from the list of open slits because the WCS bounding_box is completely outside the detector.
2026-04-22 19:11:32,289 - jwst.assign_wcs.nirspec - INFO - Removing slit 18 from the list of open slits because the WCS bounding_box is completely outside the detector.
2026-04-22 19:11:32,305 - jwst.assign_wcs.nirspec - INFO - Removing slit 20 from the list of open slits because the WCS bounding_box is completely outside the detector.
2026-04-22 19:11:32,320 - jwst.assign_wcs.nirspec - INFO - Removing slit 23 from the list of open slits because the WCS bounding_box is completely outside the detector.
2026-04-22 19:11:32,335 - jwst.assign_wcs.nirspec - INFO - Removing slit 24 from the list of open slits because the WCS bounding_box is completely outside the detector.
2026-04-22 19:11:32,350 - jwst.assign_wcs.nirspec - INFO - Removing slit 28 from the list of open slits because the WCS bounding_box is completely outside the detector.
2026-04-22 19:11:32,452 - jwst.assign_wcs.nirspec - INFO - Removing slit 3 from the list of open slits because the WCS bounding_box is completely outside the detector.
2026-04-22 19:11:32,468 - jwst.assign_wcs.nirspec - INFO - Removing slit 4 from the list of open slits because the WCS bounding_box is completely outside the detector.
2026-04-22 19:11:32,483 - jwst.assign_wcs.nirspec - INFO - Removing slit 7 from the list of open slits because the WCS bounding_box is completely outside the detector.
2026-04-22 19:11:32,499 - jwst.assign_wcs.nirspec - INFO - Removing slit 10 from the list of open slits because the WCS bounding_box is completely outside the detector.
2026-04-22 19:11:32,516 - jwst.assign_wcs.nirspec - INFO - Removing slit 11 from the list of open slits because the WCS bounding_box is completely outside the detector.
2026-04-22 19:11:32,531 - jwst.assign_wcs.nirspec - INFO - Removing slit 12 from the list of open slits because the WCS bounding_box is completely outside the detector.
2026-04-22 19:11:32,547 - jwst.assign_wcs.nirspec - INFO - Removing slit 14 from the list of open slits because the WCS bounding_box is completely outside the detector.
2026-04-22 19:11:32,562 - jwst.assign_wcs.nirspec - INFO - Removing slit 16 from the list of open slits because the WCS bounding_box is completely outside the detector.
2026-04-22 19:11:32,578 - jwst.assign_wcs.nirspec - INFO - Removing slit 17 from the list of open slits because the WCS bounding_box is completely outside the detector.
2026-04-22 19:11:32,593 - jwst.assign_wcs.nirspec - INFO - Removing slit 19 from the list of open slits because the WCS bounding_box is completely outside the detector.
2026-04-22 19:11:32,608 - jwst.assign_wcs.nirspec - INFO - Removing slit 21 from the list of open slits because the WCS bounding_box is completely outside the detector.
2026-04-22 19:11:32,623 - jwst.assign_wcs.nirspec - INFO - Removing slit 22 from the list of open slits because the WCS bounding_box is completely outside the detector.
2026-04-22 19:11:32,638 - jwst.assign_wcs.nirspec - INFO - Removing slit 25 from the list of open slits because the WCS bounding_box is completely outside the detector.
2026-04-22 19:11:32,654 - jwst.assign_wcs.nirspec - INFO - Removing slit 26 from the list of open slits because the WCS bounding_box is completely outside the detector.
2026-04-22 19:11:32,669 - jwst.assign_wcs.nirspec - INFO - Removing slit 27 from the list of open slits because the WCS bounding_box is completely outside the detector.
2026-04-22 19:11:33,349 - jwst.assign_wcs.nirspec - INFO - Slits projected on detector NRS1: ['29', '30', '31', '32', '33', '34', '35', '36', '37', '38', '39', '40', '41', '42', '43', '44', '45', '46', '47', '48', '49', '50', '51', '52', '53', '54', '55', '56', '57', '58', '59', '60', '61', '62', '63', '64', '65', '66', '67', '68', '69', '70', '71', '72', '73', '74', '75', '76', '77', '78', '79', '80', '81']
2026-04-22 19:11:33,351 - jwst.assign_wcs.nirspec - INFO - Computing WCS for 53 open slitlets
2026-04-22 19:11:33,374 - jwst.assign_wcs.nirspec - INFO - gwa_ytilt is 0.177384809 deg
2026-04-22 19:11:33,374 - jwst.assign_wcs.nirspec - INFO - gwa_xtilt is 0.278486848 deg
2026-04-22 19:11:33,375 - jwst.assign_wcs.nirspec - INFO - theta_y correction: 0.0057073669713260085 deg
2026-04-22 19:11:33,376 - jwst.assign_wcs.nirspec - INFO - theta_x correction: 7.258633810078802e-05 deg
2026-04-22 19:11:33,386 - jwst.assign_wcs.nirspec - INFO - SPORDER= -1, wrange=[2.87e-06, 5.27e-06]
2026-04-22 19:11:33,476 - jwst.assign_wcs.nirspec - INFO - Applied Barycentric velocity correction : 1.000049924895689
2026-04-22 19:11:33,502 - jwst.assign_wcs.nirspec - INFO - There are 6 open slits in quadrant 1
2026-04-22 19:11:33,538 - jwst.assign_wcs.nirspec - INFO - There are 11 open slits in quadrant 2
2026-04-22 19:11:33,603 - jwst.assign_wcs.nirspec - INFO - There are 20 open slits in quadrant 3
2026-04-22 19:11:33,720 - jwst.assign_wcs.nirspec - INFO - There are 16 open slits in quadrant 4
2026-04-22 19:11:34,050 - jwst.assign_wcs.nirspec - INFO - There are 0 open slits in quadrant 5
2026-04-22 19:11:34,187 - jwst.assign_wcs.nirspec - INFO - Created a NIRSPEC nrs_msaspec pipeline with references {'distortion': None, 'filteroffset': None, 'specwcs': None, 'regions': None, 'wavelengthrange': '/home/runner/crds_cache/references/jwst/nirspec/jwst_nirspec_wavelengthrange_0006.asdf', 'camera': '/home/runner/crds_cache/references/jwst/nirspec/jwst_nirspec_camera_0008.asdf', 'collimator': '/home/runner/crds_cache/references/jwst/nirspec/jwst_nirspec_collimator_0008.asdf', 'disperser': '/home/runner/crds_cache/references/jwst/nirspec/jwst_nirspec_disperser_0068.asdf', 'fore': '/home/runner/crds_cache/references/jwst/nirspec/jwst_nirspec_fore_0051.asdf', 'fpa': '/home/runner/crds_cache/references/jwst/nirspec/jwst_nirspec_fpa_0009.asdf', 'msa': '/home/runner/crds_cache/references/jwst/nirspec/jwst_nirspec_msa_0009.asdf', 'ote': '/home/runner/crds_cache/references/jwst/nirspec/jwst_nirspec_ote_0011.asdf', 'ifupost': None, 'ifufore': None, 'ifuslicer': None, 'msametafile': './mast_products/jw01345061001_01_msa.fits'}
2026-04-22 19:11:36,886 - jwst.assign_wcs.assign_wcs - INFO - COMPLETED assign_wcs
2026-04-22 19:11:36,891 - stpipe.step - INFO - Step assign_wcs done
2026-04-22 19:11:37,179 - stpipe.step - INFO - Step badpix_selfcal running with args (<ImageModel(2048, 2048) from jw01345061001_07101_00003_nrs1_rate.fits>, [], []).
2026-04-22 19:11:37,180 - stpipe.step - INFO - Step skipped.
2026-04-22 19:11:37,431 - stpipe.step - INFO - Step msa_flagging running with args (<ImageModel(2048, 2048) from jw01345061001_07101_00003_nrs1_rate.fits>,).
2026-04-22 19:11:38,373 - jwst.msaflagopen.msaflagopen_step - INFO - Using reference file /home/runner/crds_cache/references/jwst/nirspec/jwst_nirspec_msaoper_0006.json
2026-04-22 19:11:38,444 - jwst.msaflagopen.msaflag_open - INFO - 24 failed open shutters
2026-04-22 19:11:43,457 - stpipe.step - INFO - Step msa_flagging done
2026-04-22 19:11:43,886 - stpipe.step - INFO - Step nsclean running with args (<ImageModel(2048, 2048) from jw01345061001_07101_00003_nrs1_rate.fits>,).
2026-04-22 19:11:43,887 - jwst.nsclean.nsclean_step - WARNING - The 'nsclean' step is a deprecated alias to 'clean_flicker_noise' and will be removed in future builds.
2026-04-22 19:11:43,893 - jwst.clean_flicker_noise.clean_flicker_noise - INFO - Input exposure type is NRS_MSASPEC, detector=NRS1
2026-04-22 19:11:45,033 - jwst.clean_flicker_noise.clean_flicker_noise - INFO - Cleaning image jw01345061001_07101_00003_nrs1_rate.fits
2026-04-22 19:11:47,226 - jwst.nsclean.nsclean_step - INFO - Saving mask file ./stage2_nsclean_modified/jw01345061001_07101_00003_nrs1_mask.fits
2026-04-22 19:11:48,878 - stpipe.step - INFO - Saved model in ./stage2_nsclean_modified/jw01345061001_07101_00003_nrs1_nsclean.fits
2026-04-22 19:11:48,879 - stpipe.step - INFO - Step nsclean done
2026-04-22 19:11:49,296 - stpipe.step - INFO - Step imprint_subtract running with args (<ImageModel(2048, 2048) from jw01345061001_07101_00003_nrs1_nsclean.fits>, []).
2026-04-22 19:11:49,298 - stpipe.step - INFO - Step skipped.
2026-04-22 19:11:49,614 - stpipe.step - INFO - Step bkg_subtract running with args (<ImageModel(2048, 2048) from jw01345061001_07101_00003_nrs1_nsclean.fits>, []).
2026-04-22 19:11:49,615 - stpipe.step - INFO - Step skipped.
2026-04-22 19:11:49,938 - stpipe.step - INFO - Step extract_2d running with args (<ImageModel(2048, 2048) from jw01345061001_07101_00003_nrs1_nsclean.fits>,).
2026-04-22 19:11:49,945 - jwst.extract_2d.extract_2d - INFO - EXP_TYPE is NRS_MSASPEC
2026-04-22 19:11:49,945 - jwst.extract_2d.nirspec - INFO - Slits selected:
2026-04-22 19:11:49,946 - jwst.extract_2d.nirspec - INFO - Name: 80, source_id: 1509
2026-04-22 19:11:50,008 - jwst.extract_2d.nirspec - INFO - Name of subarray extracted: 80
2026-04-22 19:11:50,009 - jwst.extract_2d.nirspec - INFO - Subarray x-extents are: 423 1777
2026-04-22 19:11:50,010 - jwst.extract_2d.nirspec - INFO - Subarray y-extents are: 262 295
2026-04-22 19:11:50,267 - jwst.extract_2d.nirspec - INFO - set slit_attributes completed
2026-04-22 19:11:50,276 - stcal.alignment.util - INFO - Update S_REGION to POLYGON ICRS 214.817179331 52.830822659 214.816253456 52.830818677 214.816255004 52.830763514 214.817180881 52.830767490
2026-04-22 19:11:50,277 - jwst.extract_2d.nirspec - INFO - Updated S_REGION to POLYGON ICRS 214.817179331 52.830822659 214.816253456 52.830818677 214.816255004 52.830763514 214.817180881 52.830767490
2026-04-22 19:11:50,343 - stpipe.step - INFO - Step extract_2d done
2026-04-22 19:11:50,675 - stpipe.step - INFO - Step srctype running with args (<MultiSlitModel from jw01345061001_07101_00003_nrs1_nsclean.fits>,).
2026-04-22 19:11:50,839 - jwst.srctype.srctype - INFO - Input EXP_TYPE is NRS_MSASPEC
2026-04-22 19:11:50,840 - jwst.srctype.srctype - INFO - source_id=1509, stellarity=1.0000, type=POINT
2026-04-22 19:11:50,842 - stpipe.step - INFO - Step srctype done
2026-04-22 19:11:51,353 - stpipe.step - INFO - Step master_background_mos running with args (<MultiSlitModel from jw01345061001_07101_00003_nrs1_nsclean.fits>,).
2026-04-22 19:11:51,359 - jwst.master_background.master_background_mos_step - WARNING - No background slits available for creating master background. Skipping
2026-04-22 19:11:51,531 - jwst.stpipe.core - INFO - Results used CRDS context: jwst_1464.pmap
2026-04-22 19:11:51,532 - stpipe.step - INFO - Step master_background_mos done
2026-04-22 19:11:51,870 - stpipe.step - INFO - Step wavecorr running with args (<MultiSlitModel from jw01345061001_07101_00003_nrs1_nsclean.fits>,).
2026-04-22 19:11:52,057 - jwst.wavecorr.wavecorr_step - INFO - Using WAVECORR reference file /home/runner/crds_cache/references/jwst/nirspec/jwst_nirspec_wavecorr_0004.asdf
2026-04-22 19:11:52,058 - jwst.wavecorr.wavecorr - INFO - Detected a POINT source type in slit 80
2026-04-22 19:11:52,138 - jwst.wavecorr.wavecorr - INFO - Using wavelength zero-point correction for aperture MOS
2026-04-22 19:11:52,181 - stpipe.step - INFO - Step wavecorr done
2026-04-22 19:11:52,535 - stpipe.step - INFO - Step flat_field running with args (<MultiSlitModel from jw01345061001_07101_00003_nrs1_nsclean.fits>,).
2026-04-22 19:11:52,562 - jwst.flatfield.flat_field_step - INFO - No reference found for type FLAT
2026-04-22 19:11:52,714 - jwst.flatfield.flat_field_step - INFO - Using FFLAT reference file: /home/runner/crds_cache/references/jwst/nirspec/jwst_nirspec_fflat_0167.fits
2026-04-22 19:11:53,188 - jwst.flatfield.flat_field_step - INFO - Using SFLAT reference file: /home/runner/crds_cache/references/jwst/nirspec/jwst_nirspec_sflat_0225.fits
2026-04-22 19:11:53,327 - jwst.flatfield.flat_field_step - INFO - Using DFLAT reference file: /home/runner/crds_cache/references/jwst/nirspec/jwst_nirspec_dflat_0001.fits
2026-04-22 19:11:53,484 - jwst.flatfield.flat_field - INFO - Working on slit 80
2026-04-22 19:11:53,866 - stpipe.step - INFO - Step flat_field done
2026-04-22 19:11:54,230 - stpipe.step - INFO - Step pathloss running with args (<MultiSlitModel from jw01345061001_07101_00003_nrs1_nsclean.fits>,).
2026-04-22 19:11:54,242 - jwst.pathloss.pathloss_step - INFO - Using PATHLOSS reference file /home/runner/crds_cache/references/jwst/nirspec/jwst_nirspec_pathloss_0010.fits
2026-04-22 19:11:54,302 - jwst.pathloss.pathloss - INFO - Input exposure type is NRS_MSASPEC
2026-04-22 19:11:54,466 - jwst.pathloss.pathloss - INFO - Working on slit 0
2026-04-22 19:11:54,466 - jwst.pathloss.pathloss - INFO - Shutter state = 11x, using MOS1x3 entry in ref file
2026-04-22 19:11:54,467 - jwst.pathloss.pathloss - INFO - Shutter above fiducial is closed, using upper region of pathloss array
2026-04-22 19:11:54,537 - stpipe.step - INFO - Step pathloss done
2026-04-22 19:11:54,893 - stpipe.step - INFO - Step barshadow running with args (<MultiSlitModel from jw01345061001_07101_00003_nrs1_nsclean.fits>,).
2026-04-22 19:11:54,906 - jwst.barshadow.barshadow_step - INFO - Using BARSHADOW reference file /home/runner/crds_cache/references/jwst/nirspec/jwst_nirspec_barshadow_0008.fits
2026-04-22 19:11:55,101 - jwst.barshadow.bar_shadow - INFO - Working on slitlet 80
2026-04-22 19:11:55,102 - jwst.barshadow.bar_shadow - INFO - Bar shadow correction skipped for slitlet 80 (source not uniform)
2026-04-22 19:11:55,110 - stpipe.step - INFO - Step barshadow done
2026-04-22 19:11:55,474 - stpipe.step - INFO - Step photom running with args (<MultiSlitModel from jw01345061001_07101_00003_nrs1_nsclean.fits>,).
2026-04-22 19:11:55,491 - jwst.photom.photom_step - INFO - Using photom reference file: /home/runner/crds_cache/references/jwst/nirspec/jwst_nirspec_photom_0015.fits
2026-04-22 19:11:55,492 - jwst.photom.photom_step - INFO - Using area reference file: /home/runner/crds_cache/references/jwst/nirspec/jwst_nirspec_area_0051.fits
2026-04-22 19:11:55,675 - jwst.photom.photom - INFO - Using instrument: NIRSPEC
2026-04-22 19:11:55,676 - jwst.photom.photom - INFO - detector: NRS1
2026-04-22 19:11:55,677 - jwst.photom.photom - INFO - exp_type: NRS_MSASPEC
2026-04-22 19:11:55,677 - jwst.photom.photom - INFO - filter: F290LP
2026-04-22 19:11:55,678 - jwst.photom.photom - INFO - grating: G395M
2026-04-22 19:11:55,722 - jwst.photom.photom - INFO - Working on slit 80
2026-04-22 19:11:55,723 - jwst.photom.photom - INFO - PHOTMJSR value: 1
2026-04-22 19:11:55,752 - stpipe.step - INFO - Step photom done
2026-04-22 19:11:56,324 - stpipe.step - INFO - Step pixel_replace running with args (<MultiSlitModel from ./stage2_nsclean_modified/jw01345061001_07101_00003_nrs1_cal.fits>,).
2026-04-22 19:11:56,326 - stpipe.step - INFO - Step skipped.
2026-04-22 19:11:56,635 - stpipe.step - INFO - Step resample_spec running with args (<MultiSlitModel from ./stage2_nsclean_modified/jw01345061001_07101_00003_nrs1_cal.fits>,).
2026-04-22 19:11:56,920 - jwst.exp_to_source.exp_to_source - INFO - Reorganizing data from exposure ./stage2_nsclean_modified/jw01345061001_07101_00003_nrs1_cal.fits
2026-04-22 19:11:57,306 - jwst.resample.resample_spec - INFO - Specified output pixel scale ratio: 1.0.
2026-04-22 19:11:57,316 - jwst.resample.resample_spec - INFO - Computed output pixel scale: 0.1036 arcsec.
2026-04-22 19:11:57,318 - stcal.resample.resample - INFO - Output pixel scale: 0.10360056695821028 arcsec.
2026-04-22 19:11:57,318 - stcal.resample.resample - INFO - Driz parameter kernel: square
2026-04-22 19:11:57,319 - stcal.resample.resample - INFO - Driz parameter pixfrac: 1.0
2026-04-22 19:11:57,319 - stcal.resample.resample - INFO - Driz parameter fillval: NaN
2026-04-22 19:11:57,320 - stcal.resample.resample - INFO - Driz parameter weight_type: exptime
2026-04-22 19:11:57,321 - jwst.resample.resample - INFO - Resampling science and variance data
2026-04-22 19:11:57,376 - stcal.resample.resample - INFO - Resampling science and variance data
2026-04-22 19:11:57,380 - stcal.resample.resample - INFO - Drizzling (33, 1354) --> (21, 1354)
2026-04-22 19:11:57,385 - stcal.resample.resample - INFO - Drizzling (33, 1354) --> (21, 1354)
2026-04-22 19:11:57,389 - stcal.resample.resample - INFO - Drizzling (33, 1354) --> (21, 1354)
2026-04-22 19:11:57,522 - stcal.alignment.util - INFO - Update S_REGION to POLYGON ICRS 214.816217049 52.830790936 214.817169667 52.830790936 214.817169667 52.830795030 214.816217049 52.830795030
2026-04-22 19:11:57,665 - stpipe.step - INFO - Saved model in ./stage2_nsclean_modified/jw01345061001_07101_00003_nrs1_s2d.fits
2026-04-22 19:11:57,666 - stpipe.step - INFO - Step resample_spec done
2026-04-22 19:11:57,755 - jwst.pipeline.calwebb_spec2 - INFO - Extracting 1 MSA slitlets
2026-04-22 19:11:58,060 - stpipe.step - INFO - Step extract_1d running with args (<MultiSlitModel from jw01345061001_07101_00003_nrs1_s2d.fits>,).
2026-04-22 19:11:58,216 - jwst.extract_1d.extract_1d_step - INFO - Using EXTRACT1D reference file /home/runner/crds_cache/references/jwst/nirspec/jwst_nirspec_extract1d_0009.json
2026-04-22 19:11:58,222 - jwst.extract_1d.extract_1d_step - INFO - Using APCORR file /home/runner/crds_cache/references/jwst/nirspec/jwst_nirspec_apcorr_0004.fits
2026-04-22 19:11:58,264 - jwst.extract_1d.extract - INFO - Working on slit 80
2026-04-22 19:11:58,265 - jwst.lib.pipe_utils - WARNING - Mismatched data shapes; skipping invalid data updates for extension 'dq'
2026-04-22 19:11:58,266 - jwst.extract_1d.extract - INFO - Turning on source position correction for exp_type = NRS_MSASPEC
2026-04-22 19:11:58,269 - jwst.extract_1d.source_location - INFO - Using source_xpos and source_ypos to center extraction.
2026-04-22 19:11:58,273 - jwst.extract_1d.extract - INFO - Computed source location is 4.78, at pixel 676, wavelength 4.07
2026-04-22 19:11:58,274 - jwst.extract_1d.extract - INFO - Nominal aperture start/stop: 7.50 -> 12.50 (inclusive)
2026-04-22 19:11:58,275 - jwst.extract_1d.extract - INFO - Nominal location is 10.00, so offset is -5.22 pixels
2026-04-22 19:11:58,276 - jwst.extract_1d.extract - INFO - Mean aperture start/stop from trace: 2.28 -> 7.28 (inclusive)
2026-04-22 19:11:58,279 - jwst.extract_1d.extract - INFO - Creating aperture correction.
2026-04-22 19:11:59,206 - stpipe.step - INFO - Step extract_1d done
2026-04-22 19:11:59,267 - stpipe.step - INFO - Saved model in ./stage2_nsclean_modified/jw01345061001_07101_00003_nrs1_x1d.fits
2026-04-22 19:11:59,268 - jwst.pipeline.calwebb_spec2 - INFO - Finished processing product mast_products/jw01345061001_07101_00003_nrs1
2026-04-22 19:11:59,269 - jwst.pipeline.calwebb_spec2 - INFO - Ending calwebb_spec2
2026-04-22 19:11:59,270 - jwst.stpipe.core - INFO - Results used CRDS context: jwst_1464.pmap
2026-04-22 19:11:59,500 - stpipe.step - INFO - Saved model in ./stage2_nsclean_modified/jw01345061001_07101_00003_nrs1_cal.fits
2026-04-22 19:11:59,501 - stpipe.step - INFO - Step Spec2Pipeline done
2026-04-22 19:11:59,501 - jwst.stpipe.core - INFO - Results used jwst version: 1.20.2
2026-04-22 19:11:59,529 - stpipe.step - INFO - PARS-RESAMPLESPECSTEP parameters found: /home/runner/crds_cache/references/jwst/nirspec/jwst_nirspec_pars-resamplespecstep_0001.asdf
2026-04-22 19:11:59,545 - stpipe.step - INFO - PARS-RESAMPLESPECSTEP parameters found: /home/runner/crds_cache/references/jwst/nirspec/jwst_nirspec_pars-resamplespecstep_0001.asdf
2026-04-22 19:11:59,566 - stpipe.step - INFO - Spec2Pipeline instance created.
2026-04-22 19:11:59,568 - stpipe.step - INFO - AssignWcsStep instance created.
2026-04-22 19:11:59,569 - stpipe.step - INFO - BadpixSelfcalStep instance created.
2026-04-22 19:11:59,570 - stpipe.step - INFO - MSAFlagOpenStep instance created.
2026-04-22 19:11:59,571 - stpipe.step - INFO - NSCleanStep instance created.
2026-04-22 19:11:59,572 - stpipe.step - INFO - BackgroundStep instance created.
2026-04-22 19:11:59,572 - stpipe.step - INFO - ImprintStep instance created.
2026-04-22 19:11:59,573 - stpipe.step - INFO - Extract2dStep instance created.
2026-04-22 19:11:59,577 - stpipe.step - INFO - MasterBackgroundMosStep instance created.
2026-04-22 19:11:59,578 - stpipe.step - INFO - FlatFieldStep instance created.
2026-04-22 19:11:59,579 - stpipe.step - INFO - PathLossStep instance created.
2026-04-22 19:11:59,580 - stpipe.step - INFO - BarShadowStep instance created.
2026-04-22 19:11:59,581 - stpipe.step - INFO - PhotomStep instance created.
2026-04-22 19:11:59,582 - stpipe.step - INFO - PixelReplaceStep instance created.
2026-04-22 19:11:59,583 - stpipe.step - INFO - ResampleSpecStep instance created.
2026-04-22 19:11:59,585 - stpipe.step - INFO - Extract1dStep instance created.
2026-04-22 19:11:59,586 - stpipe.step - INFO - WavecorrStep instance created.
2026-04-22 19:11:59,586 - stpipe.step - INFO - FlatFieldStep instance created.
2026-04-22 19:11:59,587 - stpipe.step - INFO - SourceTypeStep instance created.
2026-04-22 19:11:59,588 - stpipe.step - INFO - StraylightStep instance created.
2026-04-22 19:11:59,588 - stpipe.step - INFO - FringeStep instance created.
2026-04-22 19:11:59,590 - stpipe.step - INFO - ResidualFringeStep instance created.
2026-04-22 19:11:59,591 - stpipe.step - INFO - PathLossStep instance created.
2026-04-22 19:11:59,592 - stpipe.step - INFO - BarShadowStep instance created.
2026-04-22 19:11:59,593 - stpipe.step - INFO - WfssContamStep instance created.
2026-04-22 19:11:59,594 - stpipe.step - INFO - PhotomStep instance created.
2026-04-22 19:11:59,595 - stpipe.step - INFO - PixelReplaceStep instance created.
2026-04-22 19:11:59,596 - stpipe.step - INFO - ResampleSpecStep instance created.
2026-04-22 19:11:59,597 - stpipe.step - INFO - CubeBuildStep instance created.
2026-04-22 19:11:59,599 - stpipe.step - INFO - Extract1dStep instance created.
Saved jw01345061001_07101_00003_nrs1_mask.fits
Saved jw01345061001_07101_00003_nrs1_nsclean.fits
Saved jw01345061001_07101_00003_nrs1_cal.fits
Saved jw01345061001_07101_00003_nrs1_x1d.fits
Processing jw01345061001_07101_00003_nrs2_rate.fits...
2026-04-22 19:11:59,932 - stpipe.step - INFO - Step Spec2Pipeline running with args ('./mast_products/jw01345061001_07101_00003_nrs2_rate.fits',).
2026-04-22 19:11:59,960 - stpipe.step - INFO - Step Spec2Pipeline parameters are:
pre_hooks: []
post_hooks: []
output_file: None
output_dir: ./stage2_nsclean_modified/
output_ext: .fits
output_use_model: False
output_use_index: True
save_results: True
skip: False
suffix: None
search_output_file: True
input_dir: ''
save_bsub: False
fail_on_exception: True
save_wfss_esec: False
steps:
assign_wcs:
pre_hooks: []
post_hooks: []
output_file: None
output_dir: None
output_ext: .fits
output_use_model: False
output_use_index: True
save_results: False
skip: False
suffix: None
search_output_file: True
input_dir: ''
sip_approx: True
sip_max_pix_error: 0.01
sip_degree: None
sip_max_inv_pix_error: 0.01
sip_inv_degree: None
sip_npoints: 12
slit_y_low: -0.55
slit_y_high: 0.55
nrs_ifu_slice_wcs: False
badpix_selfcal:
pre_hooks: []
post_hooks: []
output_file: None
output_dir: None
output_ext: .fits
output_use_model: False
output_use_index: True
save_results: False
skip: True
suffix: None
search_output_file: True
input_dir: ''
flagfrac_lower: 0.001
flagfrac_upper: 0.001
kernel_size: 15
force_single: False
save_flagged_bkg: False
msa_flagging:
pre_hooks: []
post_hooks: []
output_file: None
output_dir: None
output_ext: .fits
output_use_model: False
output_use_index: True
save_results: False
skip: False
suffix: None
search_output_file: True
input_dir: ''
nsclean:
pre_hooks: []
post_hooks: []
output_file: None
output_dir: None
output_ext: .fits
output_use_model: False
output_use_index: True
save_results: True
skip: False
suffix: None
search_output_file: True
input_dir: ''
fit_method: fft
fit_by_channel: False
background_method: None
background_box_size: None
mask_spectral_regions: True
n_sigma: 5.0
fit_histogram: False
single_mask: False
user_mask: ./stage2_nsclean_modified/jw01345061001_07101_00003_nrs2_mask_modified.fits
save_mask: True
save_background: False
save_noise: False
bkg_subtract:
pre_hooks: []
post_hooks: []
output_file: None
output_dir: None
output_ext: .fits
output_use_model: False
output_use_index: True
save_results: False
skip: False
suffix: None
search_output_file: True
input_dir: ''
bkg_list: None
save_combined_background: False
sigma: 3.0
maxiters: None
soss_source_percentile: 35.0
soss_bkg_percentile: None
wfss_mmag_extract: None
wfss_maxiter: 5
wfss_rms_stop: 0.0
wfss_outlier_percent: 1.0
imprint_subtract:
pre_hooks: []
post_hooks: []
output_file: None
output_dir: None
output_ext: .fits
output_use_model: False
output_use_index: True
save_results: False
skip: False
suffix: None
search_output_file: True
input_dir: ''
extract_2d:
pre_hooks: []
post_hooks: []
output_file: None
output_dir: None
output_ext: .fits
output_use_model: False
output_use_index: True
save_results: False
skip: False
suffix: None
search_output_file: True
input_dir: ''
slit_names:
- '11'
source_ids: None
extract_orders: None
grism_objects: None
tsgrism_extract_height: None
wfss_extract_half_height: 5
wfss_mmag_extract: None
wfss_nbright: 1000
master_background_mos:
pre_hooks: []
post_hooks: []
output_file: None
output_dir: None
output_ext: .fits
output_use_model: True
output_use_index: True
save_results: False
skip: False
suffix: None
search_output_file: True
input_dir: ''
sigma_clip: 3.0
median_kernel: 1
force_subtract: False
save_background: False
user_background: None
inverse: False
steps:
flat_field:
pre_hooks: []
post_hooks: []
output_file: None
output_dir: None
output_ext: .fits
output_use_model: False
output_use_index: True
save_results: False
skip: False
suffix: None
search_output_file: True
input_dir: ''
save_interpolated_flat: False
user_supplied_flat: None
inverse: False
pathloss:
pre_hooks: []
post_hooks: []
output_file: None
output_dir: None
output_ext: .fits
output_use_model: False
output_use_index: True
save_results: False
skip: False
suffix: None
search_output_file: True
input_dir: ''
inverse: False
source_type: None
user_slit_loc: None
barshadow:
pre_hooks: []
post_hooks: []
output_file: None
output_dir: None
output_ext: .fits
output_use_model: False
output_use_index: True
save_results: False
skip: False
suffix: None
search_output_file: True
input_dir: ''
inverse: False
source_type: None
photom:
pre_hooks: []
post_hooks: []
output_file: None
output_dir: None
output_ext: .fits
output_use_model: False
output_use_index: True
save_results: False
skip: False
suffix: None
search_output_file: True
input_dir: ''
inverse: False
source_type: None
apply_time_correction: True
pixel_replace:
pre_hooks: []
post_hooks: []
output_file: None
output_dir: None
output_ext: .fits
output_use_model: True
output_use_index: True
save_results: False
skip: True
suffix: None
search_output_file: True
input_dir: ''
algorithm: fit_profile
n_adjacent_cols: 3
resample_spec:
pre_hooks: []
post_hooks: []
output_file: None
output_dir: None
output_ext: .fits
output_use_model: False
output_use_index: True
save_results: False
skip: False
suffix: None
search_output_file: True
input_dir: ''
pixfrac: 1.0
kernel: square
fillval: NaN
weight_type: exptime
output_shape: None
pixel_scale_ratio: 1.0
pixel_scale: None
output_wcs: ''
single: False
blendheaders: True
in_memory: True
extract_1d:
pre_hooks: []
post_hooks: []
output_file: None
output_dir: None
output_ext: .fits
output_use_model: False
output_use_index: True
save_results: False
skip: False
suffix: None
search_output_file: True
input_dir: ''
subtract_background: None
apply_apcorr: True
extraction_type: box
use_source_posn: None
position_offset: 0.0
model_nod_pair: True
optimize_psf_location: True
smoothing_length: None
bkg_fit: None
bkg_order: None
log_increment: 50
save_profile: False
save_scene_model: False
save_residual_image: False
center_xy: None
ifu_autocen: False
bkg_sigma_clip: 3.0
ifu_rfcorr: True
ifu_set_srctype: None
ifu_rscale: None
ifu_covar_scale: 1.0
soss_atoca: True
soss_threshold: 0.01
soss_n_os: 2
soss_wave_grid_in: None
soss_wave_grid_out: None
soss_estimate: None
soss_rtol: 0.0001
soss_max_grid_size: 20000
soss_tikfac: None
soss_width: 40.0
soss_bad_pix: masking
soss_modelname: None
soss_order_3: True
wavecorr:
pre_hooks: []
post_hooks: []
output_file: None
output_dir: None
output_ext: .fits
output_use_model: False
output_use_index: True
save_results: False
skip: False
suffix: None
search_output_file: True
input_dir: ''
flat_field:
pre_hooks: []
post_hooks: []
output_file: None
output_dir: None
output_ext: .fits
output_use_model: False
output_use_index: True
save_results: False
skip: False
suffix: None
search_output_file: True
input_dir: ''
save_interpolated_flat: False
user_supplied_flat: None
inverse: False
srctype:
pre_hooks: []
post_hooks: []
output_file: None
output_dir: None
output_ext: .fits
output_use_model: False
output_use_index: True
save_results: False
skip: False
suffix: None
search_output_file: True
input_dir: ''
source_type: None
straylight:
pre_hooks: []
post_hooks: []
output_file: None
output_dir: None
output_ext: .fits
output_use_model: False
output_use_index: True
save_results: False
skip: False
suffix: None
search_output_file: True
input_dir: ''
clean_showers: False
shower_plane: 3
shower_x_stddev: 18.0
shower_y_stddev: 5.0
shower_low_reject: 0.1
shower_high_reject: 99.9
save_shower_model: False
fringe:
pre_hooks: []
post_hooks: []
output_file: None
output_dir: None
output_ext: .fits
output_use_model: False
output_use_index: True
save_results: False
skip: False
suffix: None
search_output_file: True
input_dir: ''
residual_fringe:
pre_hooks: []
post_hooks: []
output_file: None
output_dir: None
output_ext: .fits
output_use_model: False
output_use_index: True
save_results: False
skip: True
suffix: residual_fringe
search_output_file: False
input_dir: ''
save_intermediate_results: False
ignore_region_min: None
ignore_region_max: None
pathloss:
pre_hooks: []
post_hooks: []
output_file: None
output_dir: None
output_ext: .fits
output_use_model: False
output_use_index: True
save_results: False
skip: False
suffix: None
search_output_file: True
input_dir: ''
inverse: False
source_type: None
user_slit_loc: None
barshadow:
pre_hooks: []
post_hooks: []
output_file: None
output_dir: None
output_ext: .fits
output_use_model: False
output_use_index: True
save_results: False
skip: False
suffix: None
search_output_file: True
input_dir: ''
inverse: False
source_type: None
wfss_contam:
pre_hooks: []
post_hooks: []
output_file: None
output_dir: None
output_ext: .fits
output_use_model: False
output_use_index: True
save_results: False
skip: True
suffix: None
search_output_file: True
input_dir: ''
save_simulated_image: False
save_contam_images: False
maximum_cores: none
orders: None
magnitude_limit: None
wl_oversample: 2
max_pixels_per_chunk: 50000
photom:
pre_hooks: []
post_hooks: []
output_file: None
output_dir: None
output_ext: .fits
output_use_model: False
output_use_index: True
save_results: False
skip: False
suffix: None
search_output_file: True
input_dir: ''
inverse: False
source_type: None
apply_time_correction: True
pixel_replace:
pre_hooks: []
post_hooks: []
output_file: None
output_dir: None
output_ext: .fits
output_use_model: True
output_use_index: True
save_results: False
skip: True
suffix: None
search_output_file: True
input_dir: ''
algorithm: fit_profile
n_adjacent_cols: 3
resample_spec:
pre_hooks: []
post_hooks: []
output_file: None
output_dir: None
output_ext: .fits
output_use_model: False
output_use_index: True
save_results: False
skip: False
suffix: None
search_output_file: True
input_dir: ''
pixfrac: 1.0
kernel: square
fillval: NaN
weight_type: exptime
output_shape: None
pixel_scale_ratio: 1.0
pixel_scale: None
output_wcs: ''
single: False
blendheaders: True
in_memory: True
cube_build:
pre_hooks: []
post_hooks: []
output_file: None
output_dir: None
output_ext: .fits
output_use_model: True
output_use_index: True
save_results: False
skip: False
suffix: s3d
search_output_file: False
input_dir: ''
pipeline: 3
channel: all
band: all
grating: all
filter: all
output_type: None
scalexy: 0.0
scalew: 0.0
weighting: drizzle
coord_system: skyalign
ra_center: None
dec_center: None
cube_pa: None
nspax_x: None
nspax_y: None
rois: 0.0
roiw: 0.0
weight_power: 2.0
wavemin: None
wavemax: None
single: False
skip_dqflagging: False
offset_file: None
debug_spaxel: -1 -1 -1
extract_1d:
pre_hooks: []
post_hooks: []
output_file: None
output_dir: None
output_ext: .fits
output_use_model: False
output_use_index: True
save_results: False
skip: False
suffix: None
search_output_file: True
input_dir: ''
subtract_background: None
apply_apcorr: True
extraction_type: box
use_source_posn: None
position_offset: 0.0
model_nod_pair: True
optimize_psf_location: True
smoothing_length: None
bkg_fit: None
bkg_order: None
log_increment: 50
save_profile: False
save_scene_model: False
save_residual_image: False
center_xy: None
ifu_autocen: False
bkg_sigma_clip: 3.0
ifu_rfcorr: True
ifu_set_srctype: None
ifu_rscale: None
ifu_covar_scale: 1.0
soss_atoca: True
soss_threshold: 0.01
soss_n_os: 2
soss_wave_grid_in: None
soss_wave_grid_out: None
soss_estimate: None
soss_rtol: 0.0001
soss_max_grid_size: 20000
soss_tikfac: None
soss_width: 40.0
soss_bad_pix: masking
soss_modelname: None
soss_order_3: True
2026-04-22 19:11:59,992 - stpipe.pipeline - INFO - Prefetching reference files for dataset: 'jw01345061001_07101_00003_nrs2_rate.fits' reftypes = ['apcorr', 'area', 'barshadow', 'bkg', 'camera', 'collimator', 'cubepar', 'dflat', 'disperser', 'distortion', 'extract1d', 'fflat', 'filteroffset', 'flat', 'fore', 'fpa', 'fringe', 'ifufore', 'ifupost', 'ifuslicer', 'mrsxartcorr', 'msa', 'msaoper', 'ote', 'pastasoss', 'pathloss', 'photom', 'psf', 'regions', 'sflat', 'speckernel', 'specprofile', 'specwcs', 'wavecorr', 'wavelengthrange']
2026-04-22 19:11:59,996 - stpipe.pipeline - INFO - Prefetch for APCORR reference file is '/home/runner/crds_cache/references/jwst/nirspec/jwst_nirspec_apcorr_0004.fits'.
2026-04-22 19:11:59,997 - stpipe.pipeline - INFO - Prefetch for AREA reference file is '/home/runner/crds_cache/references/jwst/nirspec/jwst_nirspec_area_0051.fits'.
2026-04-22 19:11:59,997 - stpipe.pipeline - INFO - Prefetch for BARSHADOW reference file is '/home/runner/crds_cache/references/jwst/nirspec/jwst_nirspec_barshadow_0008.fits'.
2026-04-22 19:11:59,998 - stpipe.pipeline - INFO - Prefetch for BKG reference file is 'N/A'.
2026-04-22 19:11:59,999 - stpipe.pipeline - INFO - Prefetch for CAMERA reference file is '/home/runner/crds_cache/references/jwst/nirspec/jwst_nirspec_camera_0008.asdf'.
2026-04-22 19:11:59,999 - stpipe.pipeline - INFO - Prefetch for COLLIMATOR reference file is '/home/runner/crds_cache/references/jwst/nirspec/jwst_nirspec_collimator_0008.asdf'.
2026-04-22 19:12:00,000 - stpipe.pipeline - INFO - Prefetch for CUBEPAR reference file is 'N/A'.
2026-04-22 19:12:00,000 - stpipe.pipeline - INFO - Prefetch for DFLAT reference file is '/home/runner/crds_cache/references/jwst/nirspec/jwst_nirspec_dflat_0002.fits'.
2026-04-22 19:12:00,001 - stpipe.pipeline - INFO - Prefetch for DISPERSER reference file is '/home/runner/crds_cache/references/jwst/nirspec/jwst_nirspec_disperser_0068.asdf'.
2026-04-22 19:12:00,002 - stpipe.pipeline - INFO - Prefetch for DISTORTION reference file is 'N/A'.
2026-04-22 19:12:00,002 - stpipe.pipeline - INFO - Prefetch for EXTRACT1D reference file is '/home/runner/crds_cache/references/jwst/nirspec/jwst_nirspec_extract1d_0009.json'.
2026-04-22 19:12:00,003 - stpipe.pipeline - INFO - Prefetch for FFLAT reference file is '/home/runner/crds_cache/references/jwst/nirspec/jwst_nirspec_fflat_0167.fits'.
2026-04-22 19:12:00,004 - stpipe.pipeline - INFO - Prefetch for FILTEROFFSET reference file is 'N/A'.
2026-04-22 19:12:00,004 - stpipe.pipeline - INFO - Prefetch for FLAT reference file is 'N/A'.
2026-04-22 19:12:00,005 - stpipe.pipeline - INFO - Prefetch for FORE reference file is '/home/runner/crds_cache/references/jwst/nirspec/jwst_nirspec_fore_0051.asdf'.
2026-04-22 19:12:00,005 - stpipe.pipeline - INFO - Prefetch for FPA reference file is '/home/runner/crds_cache/references/jwst/nirspec/jwst_nirspec_fpa_0009.asdf'.
2026-04-22 19:12:00,006 - stpipe.pipeline - INFO - Prefetch for FRINGE reference file is 'N/A'.
2026-04-22 19:12:00,006 - stpipe.pipeline - INFO - Prefetch for IFUFORE reference file is 'N/A'.
2026-04-22 19:12:00,007 - stpipe.pipeline - INFO - Prefetch for IFUPOST reference file is 'N/A'.
2026-04-22 19:12:00,007 - stpipe.pipeline - INFO - Prefetch for IFUSLICER reference file is 'N/A'.
2026-04-22 19:12:00,008 - stpipe.pipeline - INFO - Prefetch for MRSXARTCORR reference file is 'N/A'.
2026-04-22 19:12:00,008 - stpipe.pipeline - INFO - Prefetch for MSA reference file is '/home/runner/crds_cache/references/jwst/nirspec/jwst_nirspec_msa_0009.asdf'.
2026-04-22 19:12:00,009 - stpipe.pipeline - INFO - Prefetch for MSAOPER reference file is '/home/runner/crds_cache/references/jwst/nirspec/jwst_nirspec_msaoper_0006.json'.
2026-04-22 19:12:00,009 - stpipe.pipeline - INFO - Prefetch for OTE reference file is '/home/runner/crds_cache/references/jwst/nirspec/jwst_nirspec_ote_0011.asdf'.
2026-04-22 19:12:00,010 - stpipe.pipeline - INFO - Prefetch for PASTASOSS reference file is 'N/A'.
2026-04-22 19:12:00,010 - stpipe.pipeline - INFO - Prefetch for PATHLOSS reference file is '/home/runner/crds_cache/references/jwst/nirspec/jwst_nirspec_pathloss_0010.fits'.
2026-04-22 19:12:00,011 - stpipe.pipeline - INFO - Prefetch for PHOTOM reference file is '/home/runner/crds_cache/references/jwst/nirspec/jwst_nirspec_photom_0015.fits'.
2026-04-22 19:12:00,011 - stpipe.pipeline - INFO - Prefetch for PSF reference file is 'N/A'.
2026-04-22 19:12:00,012 - stpipe.pipeline - INFO - Prefetch for REGIONS reference file is 'N/A'.
2026-04-22 19:12:00,012 - stpipe.pipeline - INFO - Prefetch for SFLAT reference file is '/home/runner/crds_cache/references/jwst/nirspec/jwst_nirspec_sflat_0232.fits'.
2026-04-22 19:12:00,014 - stpipe.pipeline - INFO - Prefetch for SPECKERNEL reference file is 'N/A'.
2026-04-22 19:12:00,015 - stpipe.pipeline - INFO - Prefetch for SPECPROFILE reference file is 'N/A'.
2026-04-22 19:12:00,015 - stpipe.pipeline - INFO - Prefetch for SPECWCS reference file is 'N/A'.
2026-04-22 19:12:00,016 - stpipe.pipeline - INFO - Prefetch for WAVECORR reference file is '/home/runner/crds_cache/references/jwst/nirspec/jwst_nirspec_wavecorr_0004.asdf'.
2026-04-22 19:12:00,016 - stpipe.pipeline - INFO - Prefetch for WAVELENGTHRANGE reference file is '/home/runner/crds_cache/references/jwst/nirspec/jwst_nirspec_wavelengthrange_0006.asdf'.
2026-04-22 19:12:00,017 - jwst.pipeline.calwebb_spec2 - INFO - Starting calwebb_spec2 ...
2026-04-22 19:12:00,018 - jwst.pipeline.calwebb_spec2 - INFO - Processing product mast_products/jw01345061001_07101_00003_nrs2
2026-04-22 19:12:00,018 - jwst.pipeline.calwebb_spec2 - INFO - Working on input ./mast_products/jw01345061001_07101_00003_nrs2_rate.fits ...
2026-04-22 19:12:00,235 - stpipe.step - INFO - Step assign_wcs running with args (<ImageModel(2048, 2048) from jw01345061001_07101_00003_nrs2_rate.fits>,).
2026-04-22 19:12:00,329 - jwst.assign_wcs.nirspec - INFO - Retrieving open MSA slitlets for msa_metadata_id = 83 and dither_index = 3
2026-04-22 19:12:00,338 - jwst.assign_wcs.nirspec - INFO - Slitlet 3 is background only; assigned source_id=3
2026-04-22 19:12:00,339 - jwst.assign_wcs.nirspec - INFO - Slitlet 4 is background only; assigned source_id=4
2026-04-22 19:12:00,340 - jwst.assign_wcs.nirspec - INFO - Slitlet 5 is background only; assigned source_id=5
2026-04-22 19:12:00,347 - jwst.assign_wcs.nirspec - INFO - Slitlet 9 is background only; assigned source_id=9
2026-04-22 19:12:00,350 - jwst.assign_wcs.nirspec - INFO - Slitlet 10 contains virtual source, with source_id=-59
2026-04-22 19:12:00,353 - jwst.assign_wcs.nirspec - INFO - Slitlet 12 is background only; assigned source_id=12
2026-04-22 19:12:00,354 - jwst.assign_wcs.nirspec - INFO - Slitlet 13 is background only; assigned source_id=13
2026-04-22 19:12:00,355 - jwst.assign_wcs.nirspec - INFO - Slitlet 14 is background only; assigned source_id=14
2026-04-22 19:12:00,358 - jwst.assign_wcs.nirspec - INFO - Slitlet 15 contains virtual source, with source_id=-63
2026-04-22 19:12:00,363 - jwst.assign_wcs.nirspec - INFO - Slitlet 18 is background only; assigned source_id=18
2026-04-22 19:12:00,364 - jwst.assign_wcs.nirspec - INFO - Slitlet 19 is background only; assigned source_id=19
2026-04-22 19:12:00,371 - jwst.assign_wcs.nirspec - INFO - Slitlet 23 is background only; assigned source_id=23
2026-04-22 19:12:00,378 - jwst.assign_wcs.nirspec - INFO - Slitlet 27 is background only; assigned source_id=27
2026-04-22 19:12:00,379 - jwst.assign_wcs.nirspec - INFO - Slitlet 28 is background only; assigned source_id=28
2026-04-22 19:12:00,390 - jwst.assign_wcs.nirspec - INFO - Slitlet 34 is background only; assigned source_id=34
2026-04-22 19:12:00,418 - jwst.assign_wcs.nirspec - INFO - Slitlet 48 is background only; assigned source_id=48
2026-04-22 19:12:00,432 - jwst.assign_wcs.nirspec - INFO - Slitlet 55 is background only; assigned source_id=55
2026-04-22 19:12:00,437 - jwst.assign_wcs.nirspec - INFO - Slitlet 57 contains virtual source, with source_id=-72
2026-04-22 19:12:00,446 - jwst.assign_wcs.nirspec - INFO - Slitlet 62 is background only; assigned source_id=62
2026-04-22 19:12:00,451 - jwst.assign_wcs.nirspec - INFO - Slitlet 64 contains virtual source, with source_id=-74
2026-04-22 19:12:00,456 - jwst.assign_wcs.nirspec - INFO - Slitlet 67 is background only; assigned source_id=67
2026-04-22 19:12:00,457 - jwst.assign_wcs.nirspec - INFO - Slitlet 68 is background only; assigned source_id=68
2026-04-22 19:12:00,460 - jwst.assign_wcs.nirspec - INFO - Slitlet 69 contains virtual source, with source_id=-77
2026-04-22 19:12:00,461 - jwst.assign_wcs.nirspec - INFO - Slitlet 70 is background only; assigned source_id=70
2026-04-22 19:12:00,462 - jwst.assign_wcs.nirspec - INFO - Slitlet 71 is background only; assigned source_id=71
2026-04-22 19:12:00,467 - jwst.assign_wcs.nirspec - INFO - Slitlet 74 is background only; assigned source_id=74
2026-04-22 19:12:00,474 - jwst.assign_wcs.nirspec - INFO - Slitlet 78 is background only; assigned source_id=78
2026-04-22 19:12:00,506 - jwst.assign_wcs.nirspec - INFO - gwa_ytilt is 0.177384809 deg
2026-04-22 19:12:00,506 - jwst.assign_wcs.nirspec - INFO - gwa_xtilt is 0.278486848 deg
2026-04-22 19:12:00,507 - jwst.assign_wcs.nirspec - INFO - theta_y correction: 0.0057073669713260085 deg
2026-04-22 19:12:00,508 - jwst.assign_wcs.nirspec - INFO - theta_x correction: 7.258633810078802e-05 deg
2026-04-22 19:12:01,455 - jwst.assign_wcs.nirspec - INFO - Removing slit 58 from the list of open slits because the WCS bounding_box is completely outside the detector.
2026-04-22 19:12:01,471 - jwst.assign_wcs.nirspec - INFO - Removing slit 59 from the list of open slits because the WCS bounding_box is completely outside the detector.
2026-04-22 19:12:01,487 - jwst.assign_wcs.nirspec - INFO - Removing slit 60 from the list of open slits because the WCS bounding_box is completely outside the detector.
2026-04-22 19:12:01,503 - jwst.assign_wcs.nirspec - INFO - Removing slit 61 from the list of open slits because the WCS bounding_box is completely outside the detector.
2026-04-22 19:12:01,519 - jwst.assign_wcs.nirspec - INFO - Removing slit 62 from the list of open slits because the WCS bounding_box is completely outside the detector.
2026-04-22 19:12:01,536 - jwst.assign_wcs.nirspec - INFO - Removing slit 65 from the list of open slits because the WCS bounding_box is completely outside the detector.
2026-04-22 19:12:01,555 - jwst.assign_wcs.nirspec - INFO - Removing slit 66 from the list of open slits because the WCS bounding_box is completely outside the detector.
2026-04-22 19:12:01,572 - jwst.assign_wcs.nirspec - INFO - Removing slit 68 from the list of open slits because the WCS bounding_box is completely outside the detector.
2026-04-22 19:12:01,588 - jwst.assign_wcs.nirspec - INFO - Removing slit 69 from the list of open slits because the WCS bounding_box is completely outside the detector.
2026-04-22 19:12:01,604 - jwst.assign_wcs.nirspec - INFO - Removing slit 70 from the list of open slits because the WCS bounding_box is completely outside the detector.
2026-04-22 19:12:01,621 - jwst.assign_wcs.nirspec - INFO - Removing slit 76 from the list of open slits because the WCS bounding_box is completely outside the detector.
2026-04-22 19:12:01,638 - jwst.assign_wcs.nirspec - INFO - Removing slit 78 from the list of open slits because the WCS bounding_box is completely outside the detector.
2026-04-22 19:12:01,702 - jwst.assign_wcs.nirspec - INFO - Removing slit 57 from the list of open slits because the WCS bounding_box is completely outside the detector.
2026-04-22 19:12:01,718 - jwst.assign_wcs.nirspec - INFO - Removing slit 63 from the list of open slits because the WCS bounding_box is completely outside the detector.
2026-04-22 19:12:01,735 - jwst.assign_wcs.nirspec - INFO - Removing slit 64 from the list of open slits because the WCS bounding_box is completely outside the detector.
2026-04-22 19:12:01,751 - jwst.assign_wcs.nirspec - INFO - Removing slit 67 from the list of open slits because the WCS bounding_box is completely outside the detector.
2026-04-22 19:12:01,769 - jwst.assign_wcs.nirspec - INFO - Removing slit 71 from the list of open slits because the WCS bounding_box is completely outside the detector.
2026-04-22 19:12:01,789 - jwst.assign_wcs.nirspec - INFO - Removing slit 72 from the list of open slits because the WCS bounding_box is completely outside the detector.
2026-04-22 19:12:01,807 - jwst.assign_wcs.nirspec - INFO - Removing slit 73 from the list of open slits because the WCS bounding_box is completely outside the detector.
2026-04-22 19:12:01,830 - jwst.assign_wcs.nirspec - INFO - Removing slit 74 from the list of open slits because the WCS bounding_box is completely outside the detector.
2026-04-22 19:12:01,849 - jwst.assign_wcs.nirspec - INFO - Removing slit 75 from the list of open slits because the WCS bounding_box is completely outside the detector.
2026-04-22 19:12:01,865 - jwst.assign_wcs.nirspec - INFO - Removing slit 77 from the list of open slits because the WCS bounding_box is completely outside the detector.
2026-04-22 19:12:01,881 - jwst.assign_wcs.nirspec - INFO - Removing slit 79 from the list of open slits because the WCS bounding_box is completely outside the detector.
2026-04-22 19:12:01,897 - jwst.assign_wcs.nirspec - INFO - Removing slit 80 from the list of open slits because the WCS bounding_box is completely outside the detector.
2026-04-22 19:12:01,921 - jwst.assign_wcs.nirspec - INFO - Removing slit 81 from the list of open slits because the WCS bounding_box is completely outside the detector.
2026-04-22 19:12:01,923 - jwst.assign_wcs.nirspec - INFO - Slits projected on detector NRS2: ['2', '3', '4', '5', '6', '7', '8', '9', '10', '11', '12', '13', '14', '15', '16', '17', '18', '19', '20', '21', '22', '23', '24', '25', '26', '27', '28', '29', '30', '31', '32', '33', '34', '35', '36', '37', '38', '39', '40', '41', '42', '43', '44', '45', '46', '47', '48', '49', '50', '51', '52', '53', '54', '55', '56']
2026-04-22 19:12:01,924 - jwst.assign_wcs.nirspec - INFO - Computing WCS for 55 open slitlets
2026-04-22 19:12:01,950 - jwst.assign_wcs.nirspec - INFO - gwa_ytilt is 0.177384809 deg
2026-04-22 19:12:01,950 - jwst.assign_wcs.nirspec - INFO - gwa_xtilt is 0.278486848 deg
2026-04-22 19:12:01,951 - jwst.assign_wcs.nirspec - INFO - theta_y correction: 0.0057073669713260085 deg
2026-04-22 19:12:01,952 - jwst.assign_wcs.nirspec - INFO - theta_x correction: 7.258633810078802e-05 deg
2026-04-22 19:12:01,962 - jwst.assign_wcs.nirspec - INFO - SPORDER= -1, wrange=[2.87e-06, 5.27e-06]
2026-04-22 19:12:02,054 - jwst.assign_wcs.nirspec - INFO - Applied Barycentric velocity correction : 1.000049924895689
2026-04-22 19:12:02,081 - jwst.assign_wcs.nirspec - INFO - There are 18 open slits in quadrant 1
2026-04-22 19:12:02,189 - jwst.assign_wcs.nirspec - INFO - There are 26 open slits in quadrant 2
2026-04-22 19:12:02,579 - jwst.assign_wcs.nirspec - INFO - There are 8 open slits in quadrant 3
2026-04-22 19:12:02,627 - jwst.assign_wcs.nirspec - INFO - There are 3 open slits in quadrant 4
2026-04-22 19:12:02,645 - jwst.assign_wcs.nirspec - INFO - There are 0 open slits in quadrant 5
2026-04-22 19:12:02,782 - jwst.assign_wcs.nirspec - INFO - Created a NIRSPEC nrs_msaspec pipeline with references {'distortion': None, 'filteroffset': None, 'specwcs': None, 'regions': None, 'wavelengthrange': '/home/runner/crds_cache/references/jwst/nirspec/jwst_nirspec_wavelengthrange_0006.asdf', 'camera': '/home/runner/crds_cache/references/jwst/nirspec/jwst_nirspec_camera_0008.asdf', 'collimator': '/home/runner/crds_cache/references/jwst/nirspec/jwst_nirspec_collimator_0008.asdf', 'disperser': '/home/runner/crds_cache/references/jwst/nirspec/jwst_nirspec_disperser_0068.asdf', 'fore': '/home/runner/crds_cache/references/jwst/nirspec/jwst_nirspec_fore_0051.asdf', 'fpa': '/home/runner/crds_cache/references/jwst/nirspec/jwst_nirspec_fpa_0009.asdf', 'msa': '/home/runner/crds_cache/references/jwst/nirspec/jwst_nirspec_msa_0009.asdf', 'ote': '/home/runner/crds_cache/references/jwst/nirspec/jwst_nirspec_ote_0011.asdf', 'ifupost': None, 'ifufore': None, 'ifuslicer': None, 'msametafile': './mast_products/jw01345061001_01_msa.fits'}
2026-04-22 19:12:05,666 - jwst.assign_wcs.assign_wcs - INFO - COMPLETED assign_wcs
2026-04-22 19:12:05,672 - stpipe.step - INFO - Step assign_wcs done
2026-04-22 19:12:05,968 - stpipe.step - INFO - Step badpix_selfcal running with args (<ImageModel(2048, 2048) from jw01345061001_07101_00003_nrs2_rate.fits>, [], []).
2026-04-22 19:12:05,969 - stpipe.step - INFO - Step skipped.
2026-04-22 19:12:06,229 - stpipe.step - INFO - Step msa_flagging running with args (<ImageModel(2048, 2048) from jw01345061001_07101_00003_nrs2_rate.fits>,).
2026-04-22 19:12:07,215 - jwst.msaflagopen.msaflagopen_step - INFO - Using reference file /home/runner/crds_cache/references/jwst/nirspec/jwst_nirspec_msaoper_0006.json
2026-04-22 19:12:07,636 - jwst.msaflagopen.msaflag_open - INFO - 24 failed open shutters
2026-04-22 19:12:12,300 - stpipe.step - INFO - Step msa_flagging done
2026-04-22 19:12:12,724 - stpipe.step - INFO - Step nsclean running with args (<ImageModel(2048, 2048) from jw01345061001_07101_00003_nrs2_rate.fits>,).
2026-04-22 19:12:12,725 - jwst.nsclean.nsclean_step - WARNING - The 'nsclean' step is a deprecated alias to 'clean_flicker_noise' and will be removed in future builds.
2026-04-22 19:12:12,731 - jwst.clean_flicker_noise.clean_flicker_noise - INFO - Input exposure type is NRS_MSASPEC, detector=NRS2
2026-04-22 19:12:13,911 - jwst.clean_flicker_noise.clean_flicker_noise - INFO - Cleaning image jw01345061001_07101_00003_nrs2_rate.fits
2026-04-22 19:12:16,019 - jwst.nsclean.nsclean_step - INFO - Saving mask file ./stage2_nsclean_modified/jw01345061001_07101_00003_nrs2_mask.fits
2026-04-22 19:12:17,734 - stpipe.step - INFO - Saved model in ./stage2_nsclean_modified/jw01345061001_07101_00003_nrs2_nsclean.fits
2026-04-22 19:12:17,735 - stpipe.step - INFO - Step nsclean done
2026-04-22 19:12:18,156 - stpipe.step - INFO - Step imprint_subtract running with args (<ImageModel(2048, 2048) from jw01345061001_07101_00003_nrs2_nsclean.fits>, []).
2026-04-22 19:12:18,157 - stpipe.step - INFO - Step skipped.
2026-04-22 19:12:18,481 - stpipe.step - INFO - Step bkg_subtract running with args (<ImageModel(2048, 2048) from jw01345061001_07101_00003_nrs2_nsclean.fits>, []).
2026-04-22 19:12:18,482 - stpipe.step - INFO - Step skipped.
2026-04-22 19:12:18,808 - stpipe.step - INFO - Step extract_2d running with args (<ImageModel(2048, 2048) from jw01345061001_07101_00003_nrs2_nsclean.fits>,).
2026-04-22 19:12:18,815 - jwst.extract_2d.extract_2d - INFO - EXP_TYPE is NRS_MSASPEC
2026-04-22 19:12:18,816 - jwst.extract_2d.nirspec - INFO - Slits selected:
2026-04-22 19:12:18,817 - jwst.extract_2d.nirspec - INFO - Name: 11, source_id: 386
2026-04-22 19:12:18,881 - jwst.extract_2d.nirspec - INFO - Name of subarray extracted: 11
2026-04-22 19:12:18,882 - jwst.extract_2d.nirspec - INFO - Subarray x-extents are: 141 1507
2026-04-22 19:12:18,883 - jwst.extract_2d.nirspec - INFO - Subarray y-extents are: 616 648
2026-04-22 19:12:19,144 - jwst.extract_2d.nirspec - INFO - set slit_attributes completed
2026-04-22 19:12:19,152 - stcal.alignment.util - INFO - Update S_REGION to POLYGON ICRS 214.832940199 52.885103324 214.832013460 52.885093088 214.832014161 52.885038573 214.832940897 52.885048802
2026-04-22 19:12:19,154 - jwst.extract_2d.nirspec - INFO - Updated S_REGION to POLYGON ICRS 214.832940199 52.885103324 214.832013460 52.885093088 214.832014161 52.885038573 214.832940897 52.885048802
2026-04-22 19:12:19,222 - stpipe.step - INFO - Step extract_2d done
2026-04-22 19:12:19,552 - stpipe.step - INFO - Step srctype running with args (<MultiSlitModel from jw01345061001_07101_00003_nrs2_nsclean.fits>,).
2026-04-22 19:12:19,717 - jwst.srctype.srctype - INFO - Input EXP_TYPE is NRS_MSASPEC
2026-04-22 19:12:19,718 - jwst.srctype.srctype - INFO - source_id=386, stellarity=1.0000, type=POINT
2026-04-22 19:12:19,720 - stpipe.step - INFO - Step srctype done
2026-04-22 19:12:20,222 - stpipe.step - INFO - Step master_background_mos running with args (<MultiSlitModel from jw01345061001_07101_00003_nrs2_nsclean.fits>,).
2026-04-22 19:12:20,229 - jwst.master_background.master_background_mos_step - WARNING - No background slits available for creating master background. Skipping
2026-04-22 19:12:20,403 - jwst.stpipe.core - INFO - Results used CRDS context: jwst_1464.pmap
2026-04-22 19:12:20,405 - stpipe.step - INFO - Step master_background_mos done
2026-04-22 19:12:20,752 - stpipe.step - INFO - Step wavecorr running with args (<MultiSlitModel from jw01345061001_07101_00003_nrs2_nsclean.fits>,).
2026-04-22 19:12:20,942 - jwst.wavecorr.wavecorr_step - INFO - Using WAVECORR reference file /home/runner/crds_cache/references/jwst/nirspec/jwst_nirspec_wavecorr_0004.asdf
2026-04-22 19:12:20,943 - jwst.wavecorr.wavecorr - INFO - Detected a POINT source type in slit 11
2026-04-22 19:12:21,022 - jwst.wavecorr.wavecorr - INFO - Using wavelength zero-point correction for aperture MOS
2026-04-22 19:12:21,065 - stpipe.step - INFO - Step wavecorr done
2026-04-22 19:12:21,420 - stpipe.step - INFO - Step flat_field running with args (<MultiSlitModel from jw01345061001_07101_00003_nrs2_nsclean.fits>,).
2026-04-22 19:12:21,447 - jwst.flatfield.flat_field_step - INFO - No reference found for type FLAT
2026-04-22 19:12:21,601 - jwst.flatfield.flat_field_step - INFO - Using FFLAT reference file: /home/runner/crds_cache/references/jwst/nirspec/jwst_nirspec_fflat_0167.fits
2026-04-22 19:12:22,077 - jwst.flatfield.flat_field_step - INFO - Using SFLAT reference file: /home/runner/crds_cache/references/jwst/nirspec/jwst_nirspec_sflat_0232.fits
2026-04-22 19:12:22,217 - jwst.flatfield.flat_field_step - INFO - Using DFLAT reference file: /home/runner/crds_cache/references/jwst/nirspec/jwst_nirspec_dflat_0002.fits
2026-04-22 19:12:22,378 - jwst.flatfield.flat_field - INFO - Working on slit 11
2026-04-22 19:12:22,772 - stpipe.step - INFO - Step flat_field done
2026-04-22 19:12:23,141 - stpipe.step - INFO - Step pathloss running with args (<MultiSlitModel from jw01345061001_07101_00003_nrs2_nsclean.fits>,).
2026-04-22 19:12:23,153 - jwst.pathloss.pathloss_step - INFO - Using PATHLOSS reference file /home/runner/crds_cache/references/jwst/nirspec/jwst_nirspec_pathloss_0010.fits
2026-04-22 19:12:23,213 - jwst.pathloss.pathloss - INFO - Input exposure type is NRS_MSASPEC
2026-04-22 19:12:23,382 - jwst.pathloss.pathloss - INFO - Working on slit 0
2026-04-22 19:12:23,382 - jwst.pathloss.pathloss - INFO - Shutter state = 11x, using MOS1x3 entry in ref file
2026-04-22 19:12:23,383 - jwst.pathloss.pathloss - INFO - Shutter above fiducial is closed, using upper region of pathloss array
2026-04-22 19:12:23,452 - stpipe.step - INFO - Step pathloss done
2026-04-22 19:12:23,812 - stpipe.step - INFO - Step barshadow running with args (<MultiSlitModel from jw01345061001_07101_00003_nrs2_nsclean.fits>,).
2026-04-22 19:12:23,825 - jwst.barshadow.barshadow_step - INFO - Using BARSHADOW reference file /home/runner/crds_cache/references/jwst/nirspec/jwst_nirspec_barshadow_0008.fits
2026-04-22 19:12:24,024 - jwst.barshadow.bar_shadow - INFO - Working on slitlet 11
2026-04-22 19:12:24,025 - jwst.barshadow.bar_shadow - INFO - Bar shadow correction skipped for slitlet 11 (source not uniform)
2026-04-22 19:12:24,033 - stpipe.step - INFO - Step barshadow done
2026-04-22 19:12:24,399 - stpipe.step - INFO - Step photom running with args (<MultiSlitModel from jw01345061001_07101_00003_nrs2_nsclean.fits>,).
2026-04-22 19:12:24,416 - jwst.photom.photom_step - INFO - Using photom reference file: /home/runner/crds_cache/references/jwst/nirspec/jwst_nirspec_photom_0015.fits
2026-04-22 19:12:24,417 - jwst.photom.photom_step - INFO - Using area reference file: /home/runner/crds_cache/references/jwst/nirspec/jwst_nirspec_area_0051.fits
2026-04-22 19:12:24,603 - jwst.photom.photom - INFO - Using instrument: NIRSPEC
2026-04-22 19:12:24,604 - jwst.photom.photom - INFO - detector: NRS2
2026-04-22 19:12:24,604 - jwst.photom.photom - INFO - exp_type: NRS_MSASPEC
2026-04-22 19:12:24,605 - jwst.photom.photom - INFO - filter: F290LP
2026-04-22 19:12:24,605 - jwst.photom.photom - INFO - grating: G395M
2026-04-22 19:12:24,649 - jwst.photom.photom - INFO - Working on slit 11
2026-04-22 19:12:24,650 - jwst.photom.photom - INFO - PHOTMJSR value: 1
2026-04-22 19:12:24,679 - stpipe.step - INFO - Step photom done
2026-04-22 19:12:25,254 - stpipe.step - INFO - Step pixel_replace running with args (<MultiSlitModel from ./stage2_nsclean_modified/jw01345061001_07101_00003_nrs2_cal.fits>,).
2026-04-22 19:12:25,256 - stpipe.step - INFO - Step skipped.
2026-04-22 19:12:25,544 - stpipe.step - INFO - Step resample_spec running with args (<MultiSlitModel from ./stage2_nsclean_modified/jw01345061001_07101_00003_nrs2_cal.fits>,).
2026-04-22 19:12:25,830 - jwst.exp_to_source.exp_to_source - INFO - Reorganizing data from exposure ./stage2_nsclean_modified/jw01345061001_07101_00003_nrs2_cal.fits
2026-04-22 19:12:26,220 - jwst.resample.resample_spec - INFO - Specified output pixel scale ratio: 1.0.
2026-04-22 19:12:26,228 - jwst.resample.resample_spec - INFO - Computed output pixel scale: 0.10447 arcsec.
2026-04-22 19:12:26,230 - stcal.resample.resample - INFO - Output pixel scale: 0.10447274011512764 arcsec.
2026-04-22 19:12:26,230 - stcal.resample.resample - INFO - Driz parameter kernel: square
2026-04-22 19:12:26,231 - stcal.resample.resample - INFO - Driz parameter pixfrac: 1.0
2026-04-22 19:12:26,231 - stcal.resample.resample - INFO - Driz parameter fillval: NaN
2026-04-22 19:12:26,232 - stcal.resample.resample - INFO - Driz parameter weight_type: exptime
2026-04-22 19:12:26,233 - jwst.resample.resample - INFO - Resampling science and variance data
2026-04-22 19:12:26,287 - stcal.resample.resample - INFO - Resampling science and variance data
2026-04-22 19:12:26,292 - stcal.resample.resample - INFO - Drizzling (32, 1366) --> (21, 1366)
2026-04-22 19:12:26,296 - stcal.resample.resample - INFO - Drizzling (32, 1366) --> (21, 1366)
2026-04-22 19:12:26,300 - stcal.resample.resample - INFO - Drizzling (32, 1366) --> (21, 1366)
2026-04-22 19:12:26,434 - stcal.alignment.util - INFO - Update S_REGION to POLYGON ICRS 214.831972292 52.885065372 214.832933995 52.885065372 214.832933995 52.885075990 214.831972292 52.885075990
2026-04-22 19:12:26,578 - stpipe.step - INFO - Saved model in ./stage2_nsclean_modified/jw01345061001_07101_00003_nrs2_s2d.fits
2026-04-22 19:12:26,579 - stpipe.step - INFO - Step resample_spec done
2026-04-22 19:12:26,669 - jwst.pipeline.calwebb_spec2 - INFO - Extracting 1 MSA slitlets
2026-04-22 19:12:26,984 - stpipe.step - INFO - Step extract_1d running with args (<MultiSlitModel from jw01345061001_07101_00003_nrs2_s2d.fits>,).
2026-04-22 19:12:27,142 - jwst.extract_1d.extract_1d_step - INFO - Using EXTRACT1D reference file /home/runner/crds_cache/references/jwst/nirspec/jwst_nirspec_extract1d_0009.json
2026-04-22 19:12:27,149 - jwst.extract_1d.extract_1d_step - INFO - Using APCORR file /home/runner/crds_cache/references/jwst/nirspec/jwst_nirspec_apcorr_0004.fits
2026-04-22 19:12:27,191 - jwst.extract_1d.extract - INFO - Working on slit 11
2026-04-22 19:12:27,192 - jwst.lib.pipe_utils - WARNING - Mismatched data shapes; skipping invalid data updates for extension 'dq'
2026-04-22 19:12:27,193 - jwst.extract_1d.extract - INFO - Turning on source position correction for exp_type = NRS_MSASPEC
2026-04-22 19:12:27,196 - jwst.extract_1d.source_location - INFO - Using source_xpos and source_ypos to center extraction.
2026-04-22 19:12:27,201 - jwst.extract_1d.extract - INFO - Computed source location is 4.49, at pixel 682, wavelength 4.07
2026-04-22 19:12:27,202 - jwst.extract_1d.extract - INFO - Nominal aperture start/stop: 7.50 -> 12.50 (inclusive)
2026-04-22 19:12:27,203 - jwst.extract_1d.extract - INFO - Nominal location is 10.00, so offset is -5.51 pixels
2026-04-22 19:12:27,204 - jwst.extract_1d.extract - INFO - Mean aperture start/stop from trace: 1.99 -> 6.99 (inclusive)
2026-04-22 19:12:27,207 - jwst.extract_1d.extract - INFO - Creating aperture correction.
2026-04-22 19:12:28,147 - stpipe.step - INFO - Step extract_1d done
2026-04-22 19:12:28,209 - stpipe.step - INFO - Saved model in ./stage2_nsclean_modified/jw01345061001_07101_00003_nrs2_x1d.fits
2026-04-22 19:12:28,210 - jwst.pipeline.calwebb_spec2 - INFO - Finished processing product mast_products/jw01345061001_07101_00003_nrs2
2026-04-22 19:12:28,211 - jwst.pipeline.calwebb_spec2 - INFO - Ending calwebb_spec2
2026-04-22 19:12:28,212 - jwst.stpipe.core - INFO - Results used CRDS context: jwst_1464.pmap
2026-04-22 19:12:28,447 - stpipe.step - INFO - Saved model in ./stage2_nsclean_modified/jw01345061001_07101_00003_nrs2_cal.fits
2026-04-22 19:12:28,448 - stpipe.step - INFO - Step Spec2Pipeline done
2026-04-22 19:12:28,448 - jwst.stpipe.core - INFO - Results used jwst version: 1.20.2
Saved jw01345061001_07101_00003_nrs2_mask.fits
Saved jw01345061001_07101_00003_nrs2_nsclean.fits
Saved jw01345061001_07101_00003_nrs2_cal.fits
Saved jw01345061001_07101_00003_nrs2_x1d.fits
Run time: 0.955 min
7.2 Comparing Original vs. Cleaned Data (Hand-Modified Mask) #
# Plot the original and cleaned data, as well as a residual map.
cleaned_modified_masks = [
stage2_nsclean_modified_dir + "jw01345061001_07101_00003_nrs1_nsclean.fits",
stage2_nsclean_modified_dir + "jw01345061001_07101_00003_nrs2_nsclean.fits",
]
# Plot each associated set of rateint data and cleaned file.
for rate_file, cleaned_file in zip(rate_names, cleaned_modified_masks):
plot_cleaned_data(
mast_products_dir + rate_file, cleaned_file, layout="columns", scale=9
)
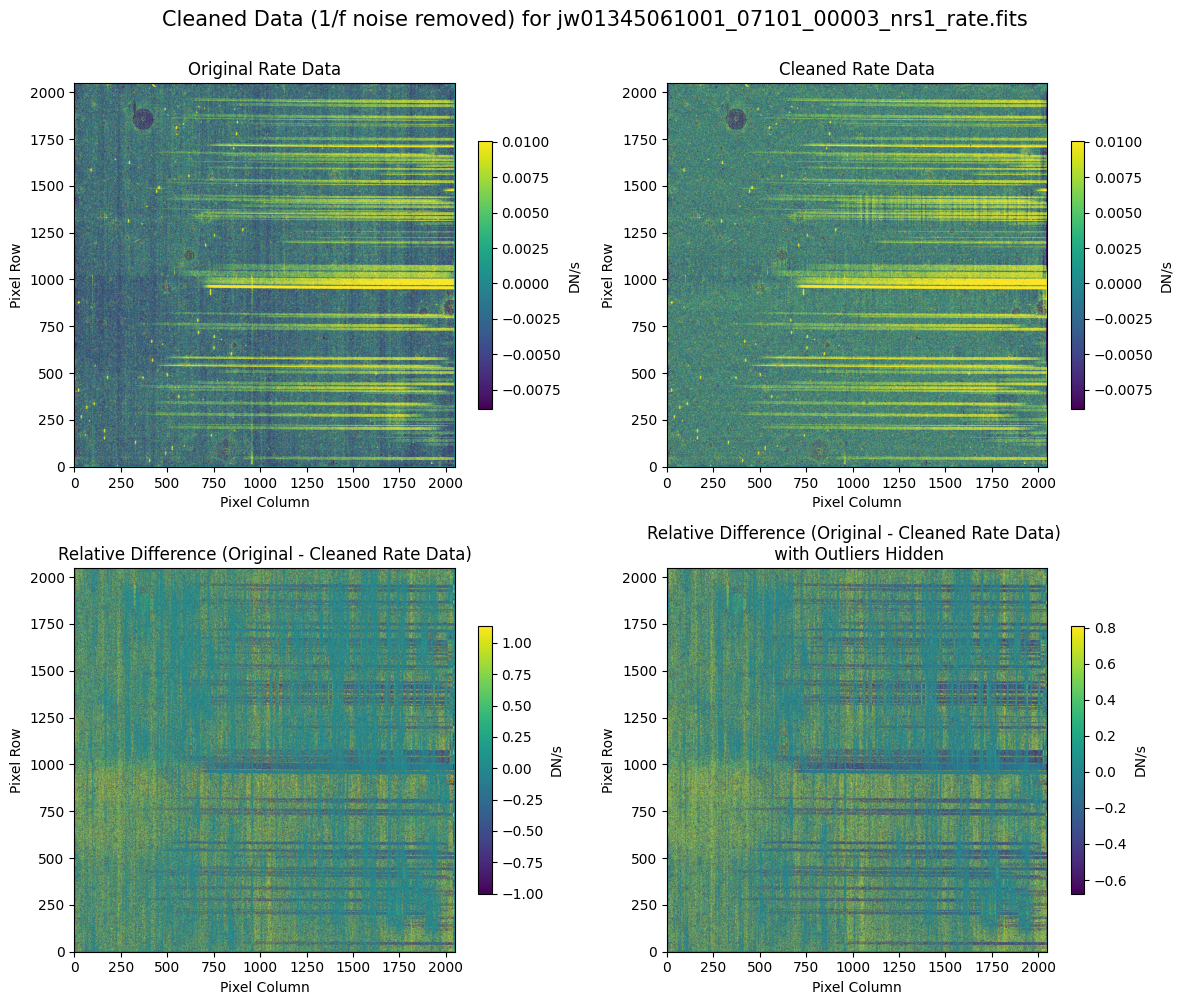
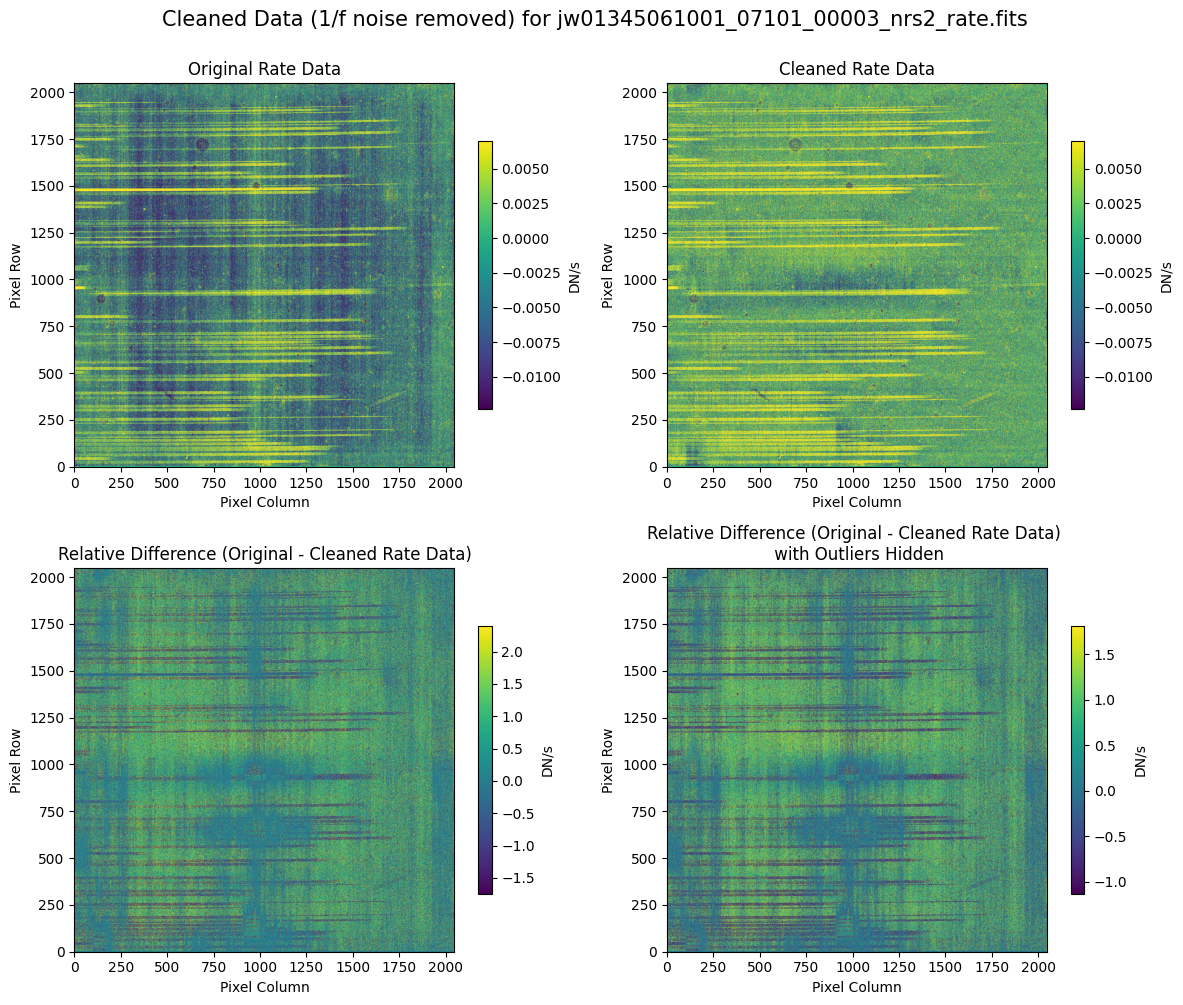
Compare the extracted spectrum from the cleaned data to the spectrum extracted from the original rate file.
x1d_nsclean_modified = [
stage2_nsclean_modified_dir + "jw01345061001_07101_00003_nrs1_x1d.fits",
stage2_nsclean_modified_dir + "jw01345061001_07101_00003_nrs2_x1d.fits",
]
# Wavelength Region of interest.
for original, cleaned in zip(x1d_nsclean_skipped, x1d_nsclean_modified):
plot_spectra([original, cleaned], scale_percent=9)
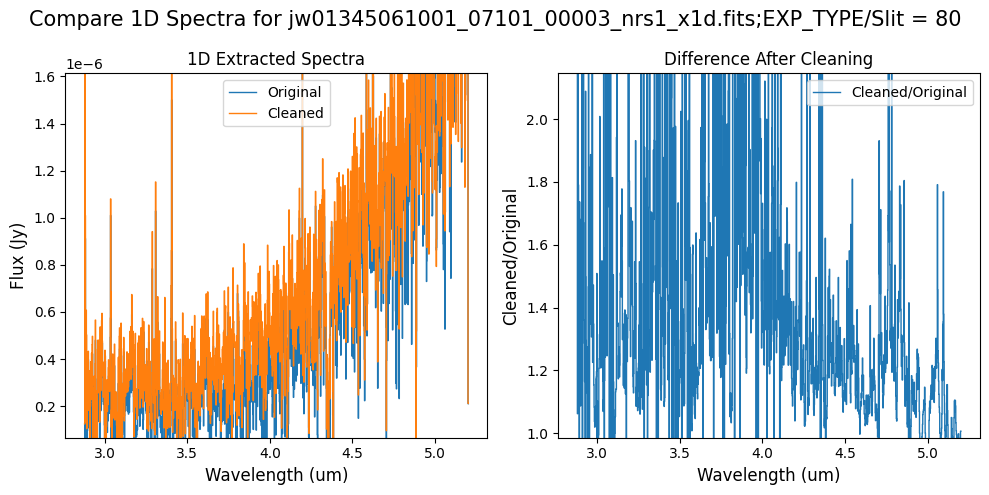
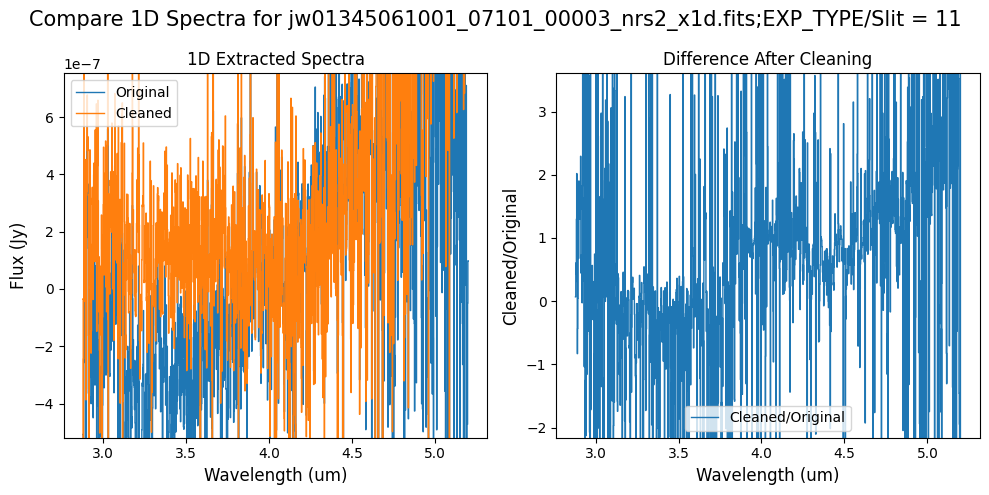
Notes:
In slit 80 on NRS1, the overall continuum level has been slightly altered by the cleaning process (similar to the default masking and alternate masking).
In slit 11 on NRS2, the flux between 4-4.55 um has decreased due to the cleaning process with the hand-modified mask. Some of the negative flux in the original spectrum (at shorter and longer wavelengths) has been corrected.
8. Conclusion #
The final plots below show the countrate images and the resulting 1D extracted spectra side-by-side to compare the different cleaning methods: the original (no NSClean applied), the cleaned countrate image (with the default pipeline mask), the cleaned countrate image (with an alternate pipeline mask), and finally, the cleaned countrate image (with the hand-modified mask).
Please note that the results presented in this notebook may vary for different datasets (e.g., targets of different brightness, spatial extent, etc.). Users are encouraged to explore NSClean using different masking methods to determine the optimal results.
The output from the cleaning algorithm is now ready for further processing. The (_cal.fits) files produced by the above Spec2Pipeline run may be used as input to the Spec3Pipeline, for generating final combined spectra.
# Not cleaned vs. cleaned (default mask) vs. cleaned (alternate mask) rate data
original_rate_data = [
fits.open(mast_products_dir + rate_name)[1].data for rate_name in rate_names
]
cleaned_rate_default_data = [
fits.open(cleaned_default_mask)[1].data
for cleaned_default_mask in cleaned_default_masks
]
cleaned_rate_alternate_data = [
fits.open(cleaned_alternate_mask)[1].data
for cleaned_alternate_mask in cleaned_alternate_masks
]
cleaned_rate_modified_data = [
fits.open(cleaned_modified_mask)[1].data
for cleaned_modified_mask in cleaned_modified_masks
]
# For plotting visualization
for data_list in [
original_rate_data,
cleaned_rate_default_data,
cleaned_rate_alternate_data,
cleaned_rate_modified_data,
]:
for data in data_list:
data[np.isnan(data)] = 0
# Original vs. cleaned data (with default mask)
fig, axs = plt.subplots(2, 4, figsize=(25, 12))
# Set y-axis titles and plot the data
titles = [
"Original Rate Data",
"Cleaned Rate Data (Default Mask)",
"Cleaned Rate Data (Alternate Mask)",
"Cleaned Rate Data (Hand-Modified Mask)",
]
for i, (data_list, title) in enumerate(
zip(
[
original_rate_data,
cleaned_rate_default_data,
cleaned_rate_alternate_data,
cleaned_rate_modified_data,
],
titles,
)
):
for j, data in enumerate(data_list):
ax = axs[j, i]
ax.set_title(f'{title} \n {"NRS1" if j == 0 else "NRS2"}', fontsize=12)
im = ax.imshow(data, origin="lower", clim=(-1e-2, 1e-2))
fig.colorbar(im, ax=ax, pad=0.05, shrink=0.7, label="DN/s")
ax.set_xlabel("Pixel Column", fontsize=10)
ax.set_ylabel("Pixel Row", fontsize=10)
plt.tight_layout()
plt.show()
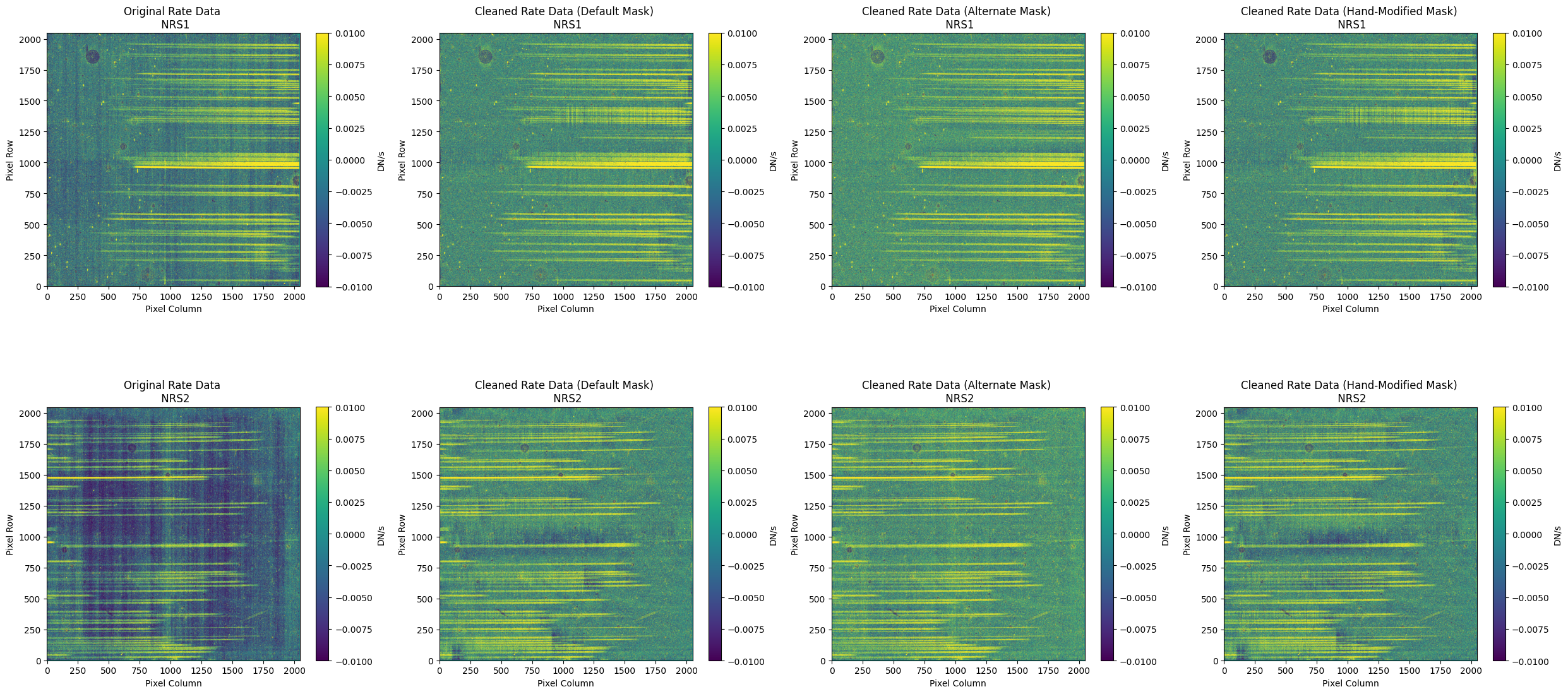
# Final Comparison
plot_spectra(
[
x1d_nsclean_skipped[0],
x1d_nsclean_default[0],
x1d_nsclean_alternate[0],
x1d_nsclean_modified[0],
],
scale_percent=4,
)
plot_spectra(
[
x1d_nsclean_skipped[1],
x1d_nsclean_default[1],
x1d_nsclean_alternate[1],
x1d_nsclean_modified[1],
],
scale_percent=4,
)
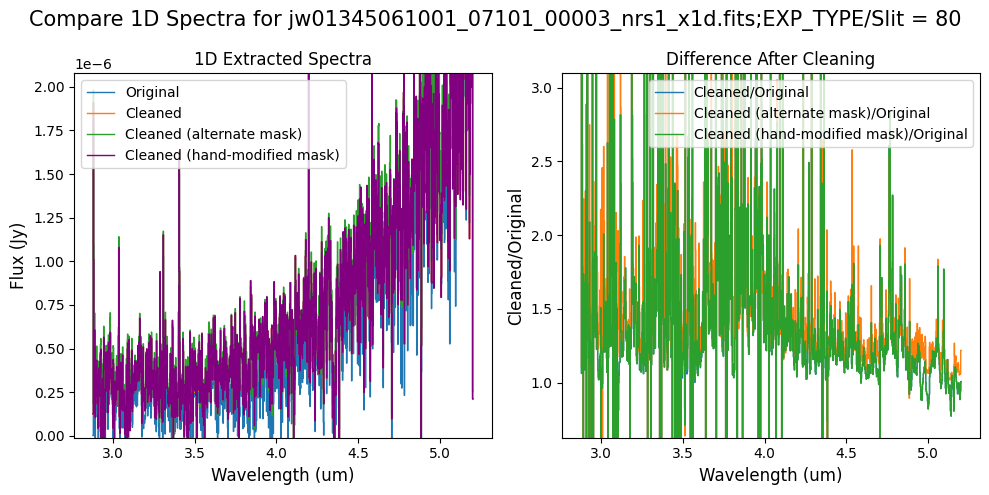
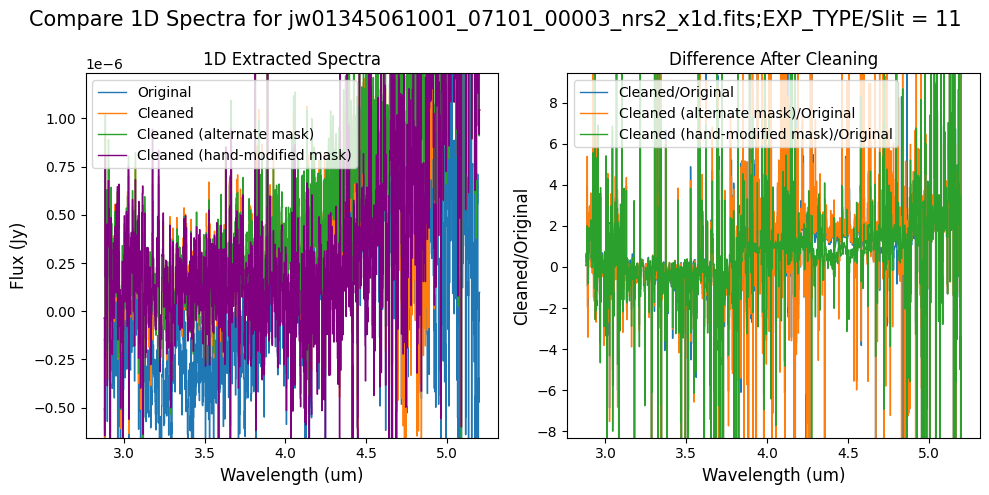
Final Notes:
The high-frequency noise in NRS2 introduced by the default masking, which was affecting the 1D extracted spectrum for slit 11 around 4.55um, no longer appears when using the alternate mask (slight improvement with the hand-modified mask), significantly improving the spectrum for slit 11.
Negative flux in slit 11 (at shorter and longer wavelengths) has been corrected with either of the masks. However, the hand-modified mask appears to decrease the continuum level for the spectrum of slit 11 between 4-4.55um. In this case, the alternate masking (clip-based) algorithm is preferable to blocking the entire science region for each MSA shutter.
About the Notebook #
Authors: Melanie Clarke, Kayli Glidic; NIRSpec Instrument Team
Updated On: Feburary 29, 2024.