
Hubble Source Catalog SWEEPS Proper Motion (API Version)#
2019 - 2022, Steve Lubow, Rick White, Trenton McKinney#
A new MAST interface supports queries to the current and previous versions of the Hubble Source Catalog. It allows searches of the summary table (with multi-filter mean photometry) and the detailed table (with all the multi-epoch measurements). It also has an associated API, which is used in this notebook.
The web-based user interface to the HSC does not currently include access to the new proper motions available for the SWEEPS field in version 3.1 of the Hubble Source Catalog. However those tables are accessible via the API. This notebook shows how to use them.
This notebook is similar to the previously released version that uses CasJobs rather than the new API. The Casjobs interface is definitely more powerful and flexible, but the API is simpler to use for users who are not already experienced Casjobs users. Currently the API does not include easy access to the colors and magnitudes of the SWEEPS objects, but they will be added soon.
Additional information is available on the SWEEPS Proper Motions help page.
A notebook that provides a quick introduction to the HSC API is also available. Another notebook generates a color-magnitude diagram for the Small Magellanic Cloud in only a couple of minutes.
Instructions:#
Complete the initialization steps described below.
Run the notebook to completion.
Modify and rerun any sections of the Table of Contents below.
Running the notebook from top to bottom takes about 4 minutes (depending on the speed of your computer).
Table of Contents#
Initialization #
Install Python modules#
This notebook requires the use of Python 3.
Modules can be installed with
conda, if using the Anaconda distribution of python, or withpip.If you are using
conda, do not install / update / remove a module withpip, that exists in acondachannel.If a module is not available with
conda, then it’s okay to install it withpip
import astropy
import time
import sys
import os
import requests
import json
import numpy as np
import matplotlib.pyplot as plt
from matplotlib.colors import LogNorm
from pathlib import Path
## For handling ordinary astropy Tables
from astropy.table import Table
from astropy.io import fits, ascii
from PIL import Image
from io import BytesIO
from fastkde import fastKDE
from scipy.interpolate import RectBivariateSpline
from astropy.modeling import models, fitting
# There are a number of relatively unimportant warnings that
# show up, so for now, suppress them:
import warnings
warnings.filterwarnings("ignore")
# set width for pprint
astropy.conf.max_width = 150
# set universal matplotlib parameters
plt.rcParams.update({'font.size': 16})
MAST API functions#
Execute HSC searches and resolve names using MAST query.
Here we define several interrelated functions for retrieving information from the MAST API.
The
hcvcone(ra, dec, radius [, keywords])function searches the HCV catalog near a position.The
hcvsearch()function performs general non-positional queries.The
hcvmetadata()function gives information about the columns available in a table.
hscapiurl = "https://catalogs.mast.stsci.edu/api/v0.1/hsc"
def hsccone(ra, dec, radius, table="summary", release="v3", format="csv", magtype="magaper2",
columns=None, baseurl=hscapiurl, verbose=False, **kw):
"""Do a cone search of the HSC catalog
Parameters
----------
ra (float): (degrees) J2000 Right Ascension
dec (float): (degrees) J2000 Declination
radius (float): (degrees) Search radius (<= 0.5 degrees)
table (string): summary, detailed, propermotions, or sourcepositions
release (string): v3 or v2
magtype (string): magaper2 or magauto (only applies to summary table)
format: csv, votable, json
columns: list of column names to include (None means use defaults)
baseurl: base URL for the request
verbose: print info about request
**kw: other parameters (e.g., 'numimages.gte':2)
"""
data = kw.copy()
data['ra'] = ra
data['dec'] = dec
data['radius'] = radius
return hscsearch(table=table, release=release, format=format, magtype=magtype,
columns=columns, baseurl=baseurl, verbose=verbose, **data)
def hscsearch(table="summary", release="v3", magtype="magaper2", format="csv",
columns=None, baseurl=hscapiurl, verbose=False, **kw):
"""Do a general search of the HSC catalog (possibly without ra/dec/radius)
Parameters
----------
table (string): summary, detailed, propermotions, or sourcepositions
release (string): v3 or v2
magtype (string): magaper2 or magauto (only applies to summary table)
format: csv, votable, json
columns: list of column names to include (None means use defaults)
baseurl: base URL for the request
verbose: print info about request
**kw: other parameters (e.g., 'numimages.gte':2). Note this is required!
"""
data = kw.copy()
if not data:
raise ValueError("You must specify some parameters for search")
if format not in ("csv", "votable", "json"):
raise ValueError("Bad value for format")
url = "{}.{}".format(cat2url(table, release, magtype, baseurl=baseurl), format)
if columns:
# check that column values are legal
# create a dictionary to speed this up
dcols = {}
for col in hscmetadata(table, release, magtype)['name']:
dcols[col.lower()] = 1
badcols = []
for col in columns:
if col.lower().strip() not in dcols:
badcols.append(col)
if badcols:
raise ValueError(f"Some columns not found in table: {', '.join(badcols)}")
# two different ways to specify a list of column values in the API
# data['columns'] = columns
data['columns'] = f"[{','.join(columns)}]"
# either get or post works
# r = requests.post(url, data=data)
r = requests.get(url, params=data)
if verbose:
print(r.url)
r.raise_for_status()
if format == "json":
return r.json()
else:
return r.text
def hscmetadata(table="summary", release="v3", magtype="magaper2", baseurl=hscapiurl):
"""Return metadata for the specified catalog and table
Parameters
----------
table (string): summary, detailed, propermotions, or sourcepositions
release (string): v3 or v2
magtype (string): magaper2 or magauto (only applies to summary table)
baseurl: base URL for the request
Returns an astropy table with columns name, type, description
"""
url = "{}/metadata".format(cat2url(table, release, magtype, baseurl=baseurl))
r = requests.get(url)
r.raise_for_status()
v = r.json()
# convert to astropy table
tab = Table(rows=[(x['name'], x['type'], x['description']) for x in v],
names=('name', 'type', 'description'))
return tab
def cat2url(table="summary", release="v3", magtype="magaper2", baseurl=hscapiurl):
"""Return URL for the specified catalog and table
Parameters
----------
table (string): summary, detailed, propermotions, or sourcepositions
release (string): v3 or v2
magtype (string): magaper2 or magauto (only applies to summary table)
baseurl: base URL for the request
Returns a string with the base URL for this request
"""
checklegal(table, release, magtype)
if table == "summary":
url = f"{baseurl}/{release}/{table}/{magtype}"
else:
url = f"{baseurl}/{release}/{table}"
return url
def checklegal(table, release, magtype):
"""Checks if this combination of table, release and magtype is acceptable
Raises a ValueError exception if there is problem
"""
releaselist = ("v2", "v3")
if release not in releaselist:
raise ValueError(f"Bad value for release (must be one of {', '.join(releaselist)})")
if release == "v2":
tablelist = ("summary", "detailed")
else:
tablelist = ("summary", "detailed", "propermotions", "sourcepositions")
if table not in tablelist:
raise ValueError(f"Bad value for table (for {release} must be one of {', '.join(tablelist)})")
if table == "summary":
magtypelist = ("magaper2", "magauto")
if magtype not in magtypelist:
raise ValueError(f"Bad value for magtype (must be one of {', '.join(magtypelist)})")
Use metadata query to get information on available columns#
This query works for any of the tables in the API (summary, detailed, propermotions, sourcepositions).
meta = hscmetadata("propermotions")
print(' '.join(meta['name']))
meta[:5]
objID numSources raMean decMean lonMean latMean raMeanErr decMeanErr lonMeanErr latMeanErr pmRA pmDec pmLon pmLat pmRAErr pmDecErr pmLonErr pmLatErr pmRADev pmDecDev pmLonDev pmLatDev epochStart epochEnd epochMean DSigma NumFilters NumVisits NumImages CI CI_Sigma KronRadius KronRadius_Sigma HTMID X Y Z
| name | type | description |
|---|---|---|
| str16 | str5 | str31 |
| objID | long | objID_descriptionTBD |
| numSources | int | numSources_descriptionTBD |
| raMean | float | raMean_descriptionTBD |
| decMean | float | decMean_descriptionTBD |
| lonMean | float | lonMean_descriptionTBD |
Retrieve data on selected SWEEPS objects#
This makes a single large request to the HSC search interface to the get the contents of the proper motions table. Despite its large size (460K rows), the query is relatively efficient: it takes about 25 seconds to retrieve the results from the server, and then another 20 seconds to convert it to an astropy table. The speed of the table conversion will depend on your computer.
Note that the query restricts the sample to objects with at least 20 images total spread over at least 10 different visits. These constraints can be modified depending on your science goals.
columns = """ObjID,raMean,decMean,raMeanErr,decMeanErr,NumFilters,NumVisits,
pmLat,pmLon,pmLatErr,pmLonErr,pmLatDev,pmLonDev,epochMean,epochStart,epochEnd""".split(",")
columns = [x.strip() for x in columns]
columns = [x for x in columns if x and not x.startswith('#')]
# missing -- impossible with current data I think
# MagMed, n, MagMAD
constraints = {'NumFilters.gt': 1, 'NumVisits.gt': 9, 'NumImages.gt': 19}
# note the pagesize parameter, which allows retrieving very large results
# the default pagesize is 50000 rows
t0 = time.time()
results = hscsearch(table="propermotions", release='v3', columns=columns, verbose=True, pagesize=500000, **constraints)
print("{:.1f} s: retrieved data".format(time.time()-t0))
tab = ascii.read(results)
print(f"{(time.time()-t0):.1f} s: converted to astropy table")
# change some column names for consistency with the Casjobs version of this notebook
tab.rename_column("raMean", "RA")
tab.rename_column("decMean", "Dec")
tab.rename_column("raMeanErr", "RAerr")
tab.rename_column("decMeanErr", "Decerr")
tab.rename_column("pmLat", "bpm")
tab.rename_column("pmLon", "lpm")
tab.rename_column("pmLatErr", "bpmerr")
tab.rename_column("pmLonErr", "lpmerr")
# compute some additional columns
tab['pmdev'] = np.sqrt(tab['pmLonDev']**2+tab['pmLatDev']**2)
tab['yr'] = (tab['epochMean'] - 47892)/365.25+1990
tab['dT'] = (tab['epochEnd']-tab['epochStart'])/365.25
tab['yrStart'] = (tab['epochStart'] - 47892)/365.25+1990
tab['yrEnd'] = (tab['epochEnd'] - 47892)/365.25+1990
# delete some columns that are not needed after the computations
del tab['pmLonDev'], tab['pmLatDev'], tab['epochEnd'], tab['epochStart'], tab['epochMean']
tab
https://catalogs.mast.stsci.edu/api/v0.1/hsc/v3/propermotions.csv?pagesize=500000&NumFilters.gt=1&NumVisits.gt=9&NumImages.gt=19&columns=%5BObjID%2CraMean%2CdecMean%2CraMeanErr%2CdecMeanErr%2CNumFilters%2CNumVisits%2CpmLat%2CpmLon%2CpmLatErr%2CpmLonErr%2CpmLatDev%2CpmLonDev%2CepochMean%2CepochStart%2CepochEnd%5D
8.9 s: retrieved data
10.7 s: converted to astropy table
| ObjID | RA | Dec | RAerr | Decerr | NumFilters | NumVisits | bpm | lpm | bpmerr | lpmerr | pmdev | yr | dT | yrStart | yrEnd |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| int64 | float64 | float64 | float64 | float64 | int64 | int64 | float64 | float64 | float64 | float64 | float64 | float64 | float64 | float64 | float64 |
| 4000709002286 | 269.7911379669984 | -29.206156187411423 | 0.6964818624528099 | 0.2730062330800141 | 2 | 47 | 2.087558644949346 | -7.738272329430371 | 0.38854582276386007 | 0.22115673368981237 | 2.887154518133692 | 2013.3007902147058 | 11.371914541371764 | 2003.4361796620085 | 2014.8080942033803 |
| 4000709002287 | 269.7955922590832 | -29.206151631494986 | 0.24020216760386343 | 0.18524811391217816 | 2 | 47 | -2.8930568503344967 | -0.7898583846555245 | 0.1316584790053578 | 0.12462185695877996 | 1.474676632663785 | 2013.3007902147058 | 11.371914541371764 | 2003.4361796620085 | 2014.8080942033803 |
| 4000709002288 | 269.81608933789283 | -29.206155196641195 | 0.3040684131020671 | 0.2850407586200256 | 2 | 47 | 4.65866649193795 | -3.2098804580343785 | 0.13931172183651183 | 0.20648097604781626 | 1.9570357322713463 | 2013.3007902147058 | 11.371914541371764 | 2003.4361796620085 | 2014.8080942033803 |
| 4000709002289 | 269.8259694163096 | -29.20615668840751 | 0.3564325426522067 | 0.39542200297333663 | 2 | 47 | -0.45662407290928664 | -2.0909050045433832 | 0.15758175952333653 | 0.2763881282194908 | 2.2415238499377685 | 2013.3007902147058 | 11.371914541371764 | 2003.4361796620085 | 2014.8080942033803 |
| 4000709002290 | 269.83486415728754 | -29.206155266983643 | 0.16299639839198538 | 0.14062839407811836 | 2 | 46 | 4.459275526783969 | -2.0433632344343886 | 0.17899727943855331 | 0.18503594468835396 | 1.0091970907052557 | 2013.5152382701992 | 3.0067822490178155 | 2011.8013119543625 | 2014.8080942033803 |
| 4000709002291 | 269.83512411344606 | -29.2061635244798 | 0.18282583105108072 | 0.2093503650681541 | 2 | 46 | 4.090870144734149 | -8.059473158394072 | 0.20446351152189052 | 0.26206212529696193 | 1.293050027027329 | 2013.5152382701992 | 3.0067822490178155 | 2011.8013119543625 | 2014.8080942033803 |
| 4000709002292 | 269.7964913295107 | -29.20618734483311 | 0.30491102397226527 | 0.26784496777851086 | 2 | 47 | -1.7001866534338244 | -5.963967462759159 | 0.14814161799844547 | 0.1920517681653374 | 1.9671761489287654 | 2013.3007902147058 | 11.371914541371764 | 2003.4361796620085 | 2014.8080942033803 |
| 4000709002293 | 269.7872745304419 | -29.206257828852337 | 1.351885504360048 | 1.0460614189471378 | 2 | 46 | -2.290436263458843 | -9.596838559623627 | 0.779373480816473 | 0.6485354032580087 | 8.518045574208871 | 2013.3206150152016 | 11.371914541371764 | 2003.4361796620085 | 2014.8080942033803 |
| 4000709002294 | 269.80888716219647 | -29.206189189626002 | 1.4134596118752103 | 1.2518047802862953 | 2 | 47 | 4.381302303073221 | -4.701855876394848 | 0.4784428793001857 | 1.0219363775325352 | 6.469654565147953 | 2013.3007902147058 | 11.371914541371764 | 2003.4361796620085 | 2014.8080942033803 |
| ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... |
| 4000812954616 | 269.70861806936244 | -29.22963925127374 | 0.4145350791035023 | 0.5646425139601212 | 2 | 22 | 6.446666882419759 | -3.264926033437659 | 0.6828436154370532 | 0.5815421760344301 | 2.575583819860359 | 2013.3781422207417 | 2.23068392031726 | 2012.2042105057922 | 2014.4348944261094 |
| 4000812954617 | 269.7095074514663 | -29.22960739481815 | 0.49938250039075976 | 1.8982129844394509 | 2 | 22 | 3.623866913363032 | -2.9658479339905663 | 1.5967167108154778 | 1.9408891618757047 | 6.437305561644422 | 2013.3781422207417 | 2.23068392031726 | 2012.2042105057922 | 2014.4348944261094 |
| 4000812954626 | 269.7091983596267 | -29.22958750839926 | 0.3611643080764414 | 0.47429286442575236 | 2 | 22 | -5.433170069101051 | -0.9841417338576105 | 0.5872691071338287 | 0.4876507397388473 | 1.7430015764136113 | 2013.3781422207417 | 2.23068392031726 | 2012.2042105057922 | 2014.4348944261094 |
| 4000812954627 | 269.71209922276853 | -29.22959324051154 | 0.5658959311125298 | 0.519501839292499 | 2 | 22 | 4.2551901040204285 | -5.316064882484524 | 0.7465186345159079 | 0.6405049366233309 | 2.632563947115044 | 2013.3781422207417 | 2.23068392031726 | 2012.2042105057922 | 2014.4348944261094 |
| 4000812954637 | 269.7036252387055 | -29.22962285608012 | 2.425143716284974 | 8.88123895829776 | 2 | 22 | 2.1216800196936427 | -5.961047115042334 | 8.107830471183322 | 8.557354457535954 | 31.969639239581014 | 2013.3781422207417 | 2.23068392031726 | 2012.2042105057922 | 2014.4348944261094 |
| 4000812954638 | 269.70516093446395 | -29.229602412104736 | 0.8032125874507969 | 4.19454587612144 | 2 | 22 | 2.2998593766281075 | -5.478248541486434 | 3.4483834125155632 | 4.244190586824991 | 16.085438853294303 | 2013.3781422207417 | 2.23068392031726 | 2012.2042105057922 | 2014.4348944261094 |
| 4000812954639 | 269.7093070217424 | -29.22959180754154 | 1.1921607534771352 | 1.7790305698670303 | 2 | 17 | -1.820561603619025 | -7.642848312464297 | 2.1090181120653155 | 2.082832995058273 | 6.165084911750225 | 2013.2228711226198 | 2.23068392031726 | 2012.2042105057922 | 2014.4348944261094 |
| 4000812954640 | 269.7093932337725 | -29.229607887328886 | 1.1740622179568994 | 1.5846576780771122 | 2 | 22 | -0.4509106887293366 | -9.522244792558286 | 1.117655690542412 | 2.2645107971462086 | 6.450944495248279 | 2013.3781422207417 | 2.23068392031726 | 2012.2042105057922 | 2014.4348944261094 |
| 4000812954644 | 269.7029865879542 | -29.229612168034777 | 1.642949267162042 | 9.35620041894705 | 2 | 14 | 3.5574461227433147 | -2.4326941838865883 | 7.242036606677296 | 9.522286534824058 | 23.979933473781877 | 2013.3627585429379 | 2.23068392031726 | 2012.2042105057922 | 2014.4348944261094 |
| 4000812954645 | 269.70419237331345 | -29.22962488614748 | 0.26508374005333074 | 0.7909562563588484 | 2 | 22 | 3.094705231697324 | -10.377113607275149 | 0.5699573253488941 | 0.9033750506085733 | 2.4453274575527577 | 2013.3781422207417 | 2.23068392031726 | 2012.2042105057922 | 2014.4348944261094 |
Properties of Full Catalog #
Sky Coverage #
fig, ax = plt.subplots(figsize=(12, 10))
ax.scatter('RA', 'Dec', data=tab, s=1, alpha=0.1)
ax.set(xlabel='RA', ylabel='Dec', title=f'{len(tab)} stars in SWEEPS')
ax.invert_xaxis()
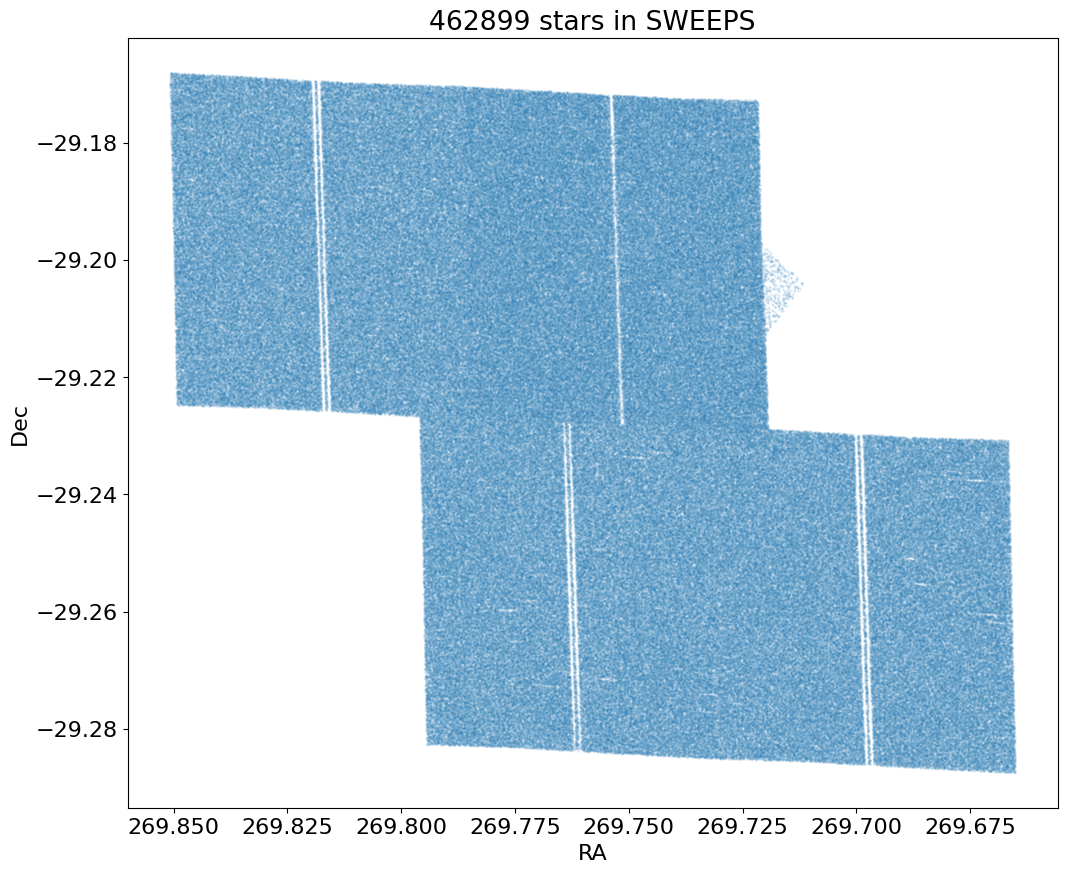
Proper Motion Histograms #
Proper motion histograms for lon and lat#
bins = 0.2
hrange = (-20, 20)
bincount = int((hrange[1]-hrange[0])/bins + 0.5) + 1
fig, ax = plt.subplots(figsize=(12, 10))
for col, label in zip(['lpm', 'bpm'], ['Longitude', 'Latitude']):
ax.hist(col, data=tab, range=hrange, bins=bincount, label=label, histtype='step', linewidth=2)
ax.set(xlabel='Proper motion [mas/yr]', ylabel=f'Number [in {bins:.2} mas bins]', title=f'{len(tab):,} stars in SWEEPS')
_ = ax.legend()
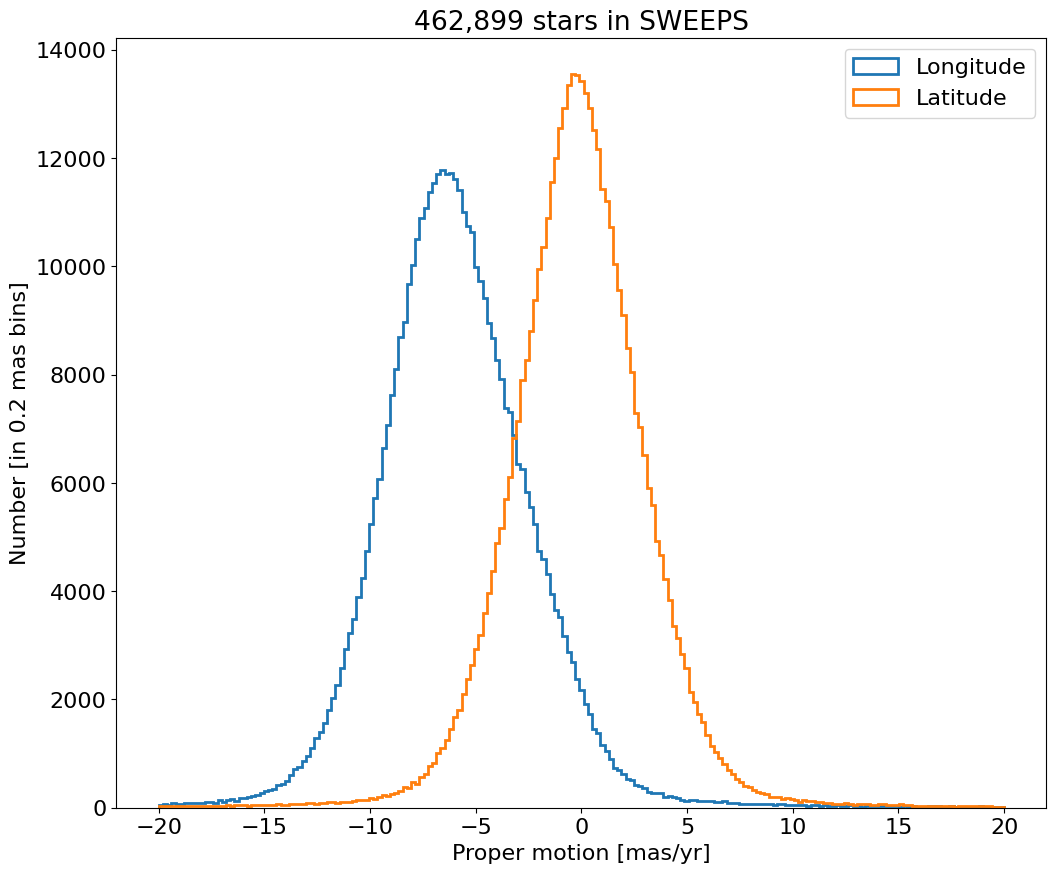
Proper motion error cumulative histogram for lon and lat#
bins = 0.01
hrange = (0, 2)
bincount = int((hrange[1]-hrange[0])/bins + 0.5) + 1
fig, ax = plt.subplots(figsize=(12, 10))
for col, label in zip(['lpmerr', 'bpmerr'], ['Longitude Error', 'Latitude Error']):
ax.hist(col, data=tab, range=hrange, bins=bincount, label=label, histtype='step', cumulative=1, linewidth=2)
ax.set(xlabel='Proper motion error [mas/yr]', ylabel=f'Cumulative number [in {bins:0.2} mas bins]', title=f'{len(tab):,} stars in SWEEPS')
_ = ax.legend(loc='upper left')
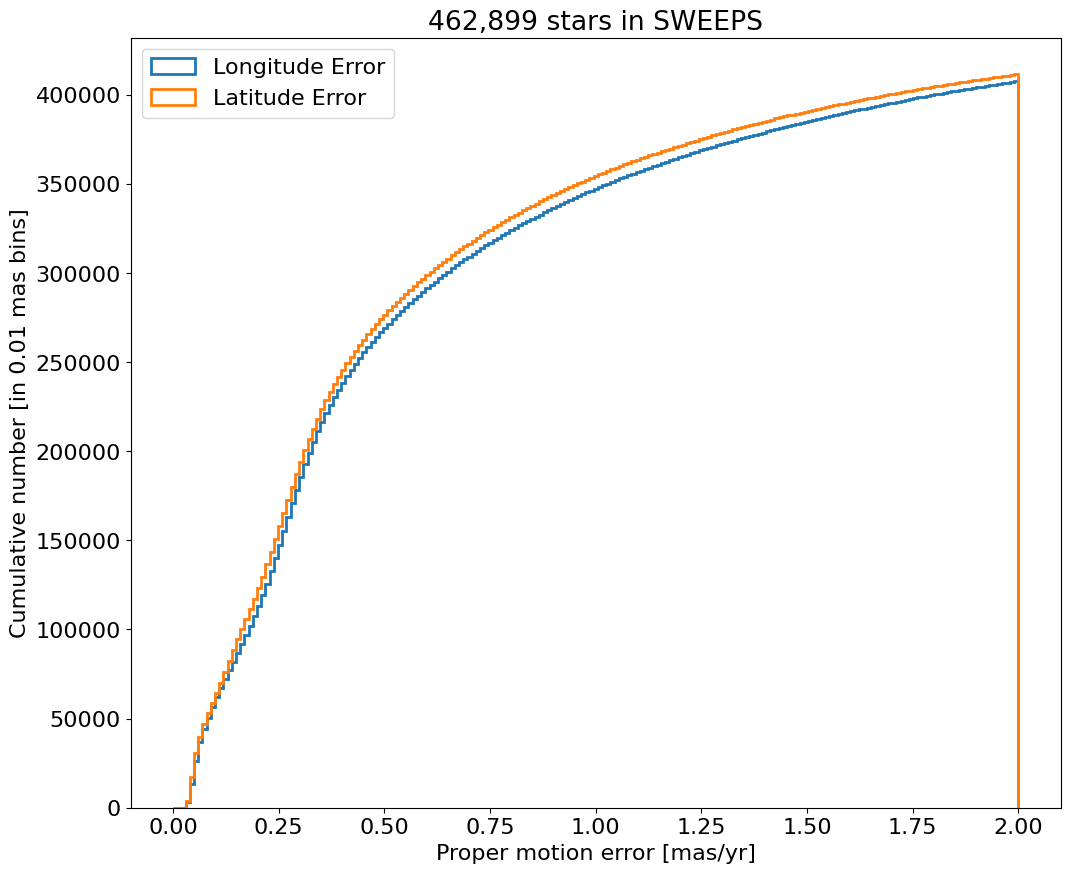
Proper motion error log histogram for lon and lat#
bins = 0.01
hrange = (0, 6)
bincount = int((hrange[1]-hrange[0])/bins + 0.5) + 1
fig, ax = plt.subplots(figsize=(12, 10))
for col, label in zip(['lpmerr', 'bpmerr'], ['Longitude Error', 'Latitude Error']):
ax.hist(col, data=tab, range=hrange, bins=bincount, label=label, histtype='step', linewidth=2)
ax.set(xlabel='Proper motion error [mas/yr]', ylabel=f'Number [in {bins:0.2} mas bins]', title=f'{len(tab):,} stars in SWEEPS', yscale='log')
_ = ax.legend(loc='upper right')
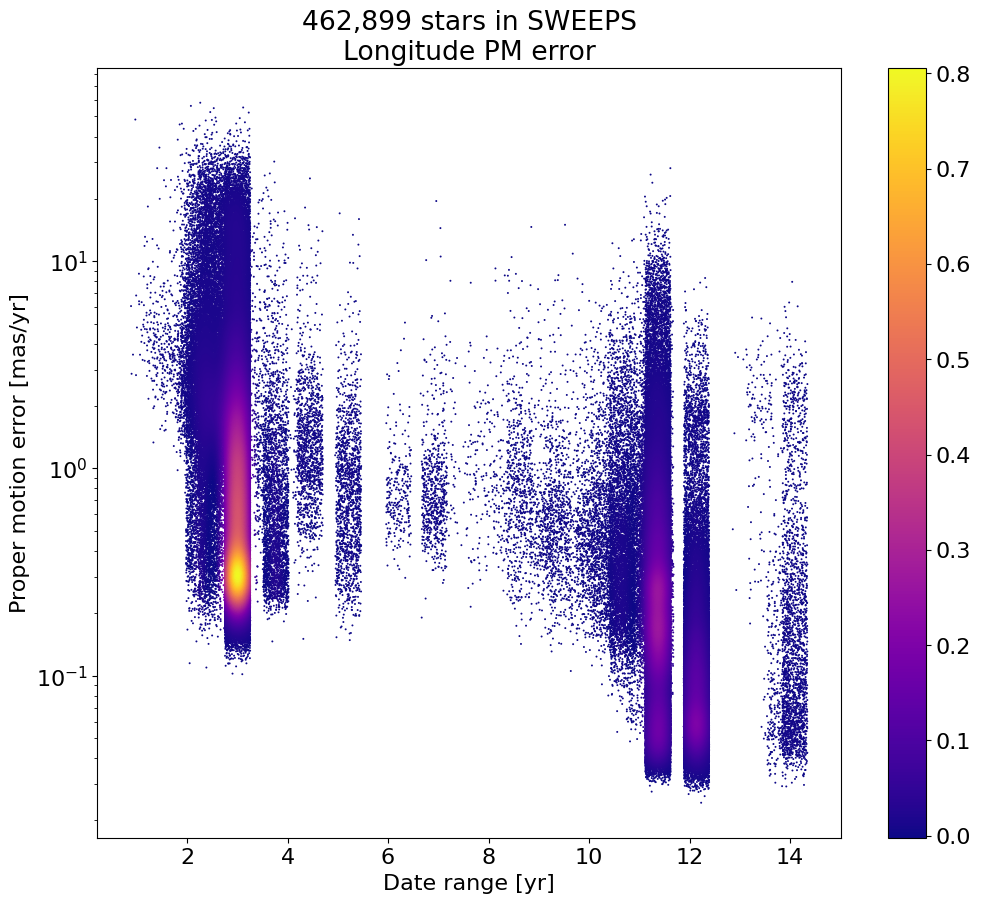
Proper motion error as a function of dT#
Exclude objects with dT near zero, and to improve the plotting add a bit of random noise to spread out the quanitized time values.
# restrict to sources with dT > 1 year
dtmin = 1.0
w = np.where(tab['dT'] > dtmin)[0]
if ('rw' not in locals()) or len(rw) != len(w):
rw = np.random.random(len(w))
x = np.array(tab['dT'][w]) + 0.5*(rw-0.5)
y = np.log(np.array(tab['lpmerr'][w]))
# Calculate the point density
t0 = time.time()
myPDF, axes = fastKDE.pdf(x, y, numPoints=2**9+1)
print(f"kde took {(time.time()-t0):.1f} sec")
# interpolate to get z values at points
finterp = RectBivariateSpline(axes[1], axes[0], myPDF)
z = finterp(y, x, grid=False)
# Sort the points by density, so that the densest points are plotted last
idx = z.argsort()
xs, ys, zs = x[idx], y[idx], z[idx]
# select a random subset of points in the most crowded regions to speed up plotting
wran = np.where(np.random.random(len(zs))*zs < 0.05)[0]
print(f"Plotting {len(wran)} of {len(zs)} points")
xs = xs[wran]
ys = ys[wran]
zs = zs[wran]
kde took 1.6 sec
Plotting 190233 of 461199 points
fig, ax = plt.subplots(figsize=(12, 10))
sc = ax.scatter(xs, np.exp(ys), c=zs, s=2, edgecolors='none', cmap='plasma')
ax.set(xlabel='Date range [yr]', ylabel='Proper motion error [mas/yr]',
title=f'{len(tab):,} stars in SWEEPS\nLongitude PM error', yscale='log')
_ = fig.colorbar(sc, ax=ax)
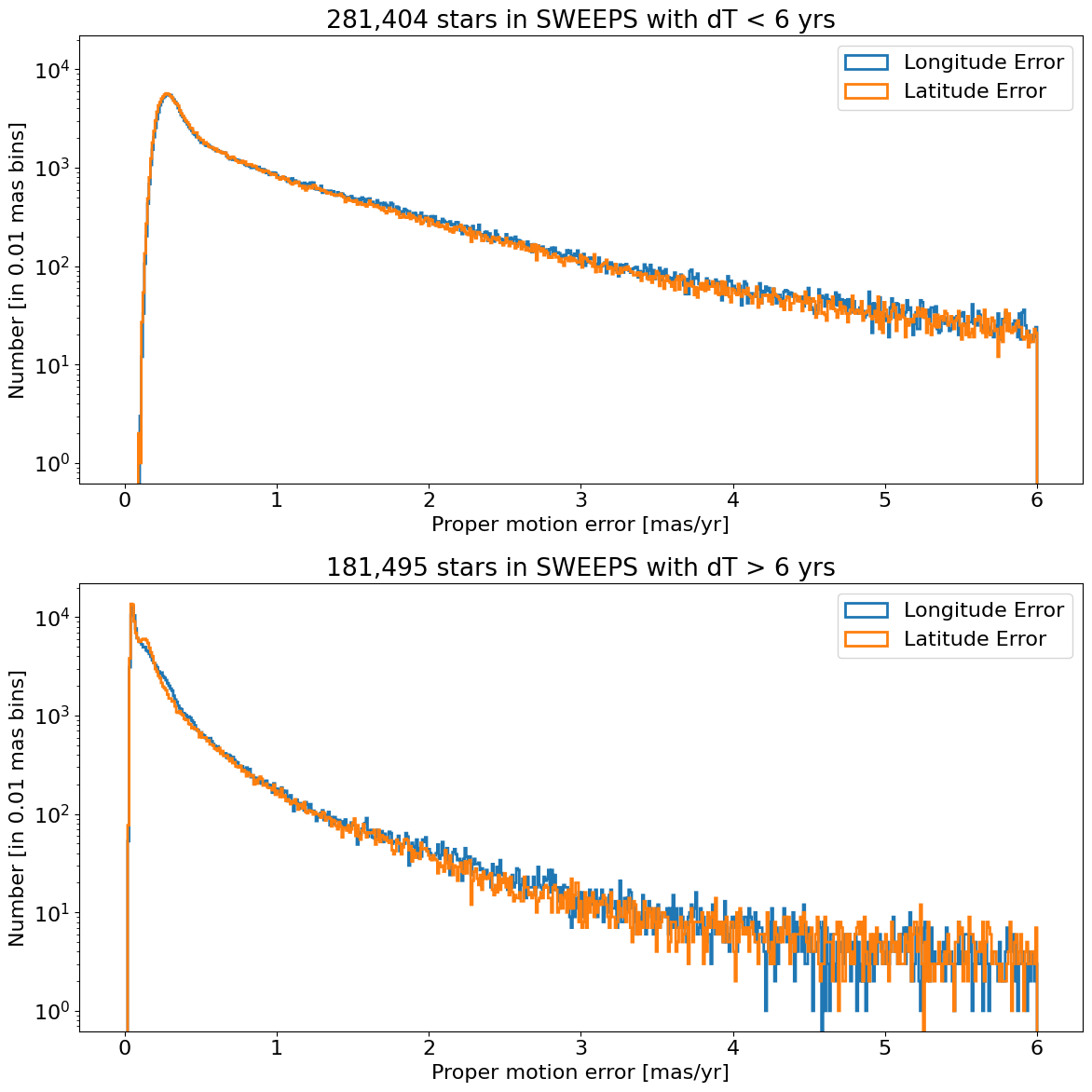
Proper motion error log histogram for lon and lat#
Divide sample into points with \(<6\) years of data and points with more than 6 years of data.
bins = 0.01
hrange = (0, 6)
bincount = int((hrange[1]-hrange[0])/bins + 0.5) + 1
tsplit = 6
# select the data to plot
mask = tab['dT'] <= tsplit
data1 = tab[mask]
data2 = tab[~mask]
fig, (ax1, ax2) = plt.subplots(nrows=2, ncols=1, figsize=(12, 12), sharey=True)
for ax, data in zip([ax1, ax2], [data1, data2]):
for col, label in zip(['lpmerr', 'bpmerr'], ['Longitude Error', 'Latitude Error']):
ax.hist(col, data=data, range=hrange, bins=bincount, label=label, histtype='step', linewidth=2)
ax1.set(xlabel='Proper motion error [mas/yr]', ylabel=f'Number [in {bins:0.2} mas bins]',
title=f'{len(data1):,} stars in SWEEPS with dT < {tsplit} yrs', yscale='log')
ax2.set(xlabel='Proper motion error [mas/yr]', ylabel=f'Number [in {bins:0.2} mas bins]',
title=f'{len(data2):,} stars in SWEEPS with dT > {tsplit} yrs', yscale='log')
ax1.legend()
ax2.legend()
_ = fig.tight_layout()
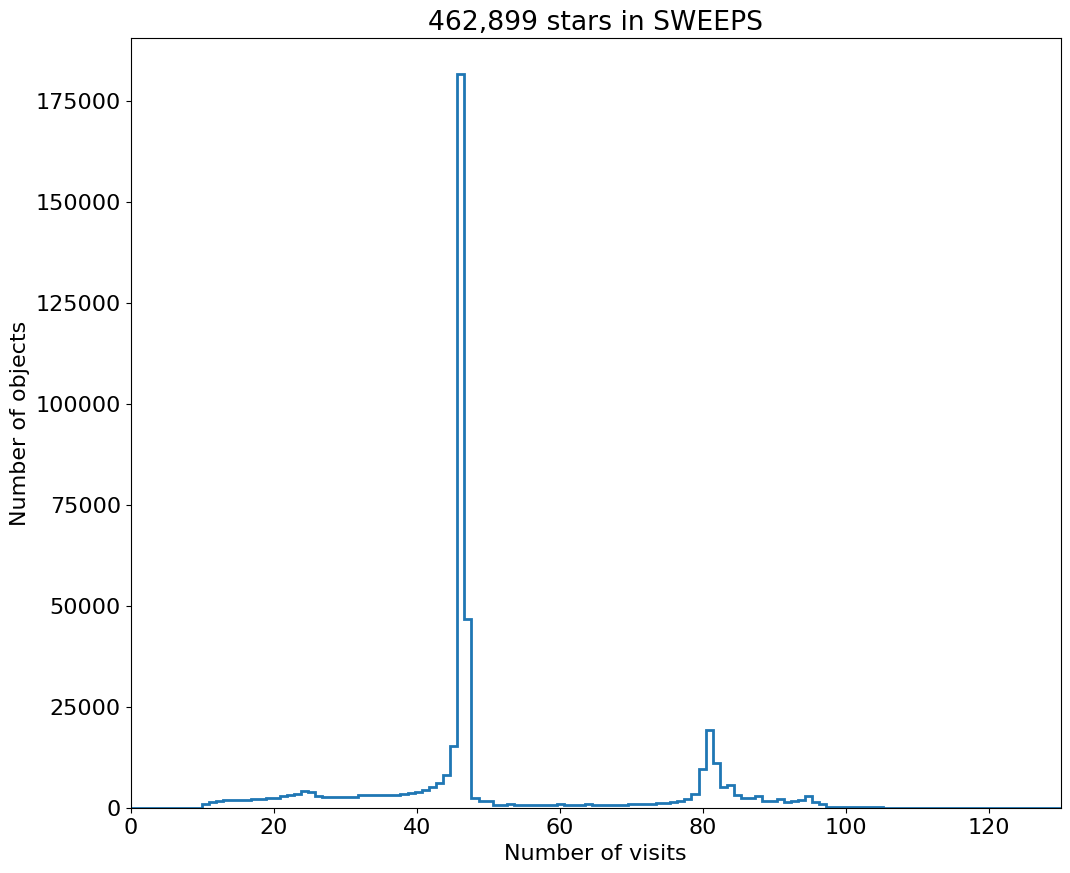
Number of Visits Histogram #
bins = 1
hrange = (0, 130)
bincount = int((hrange[1]-hrange[0])/bins + 0.5) + 1
fig, ax = plt.subplots(figsize=(12, 10))
ax.hist('NumVisits', data=tab, range=hrange, bins=bincount, label='Number of visits ', histtype='step', linewidth=2)
ax.set(xlabel='Number of visits', ylabel='Number of objects', title=f'{len(tab):,} stars in SWEEPS')
_ = ax.margins(x=0)
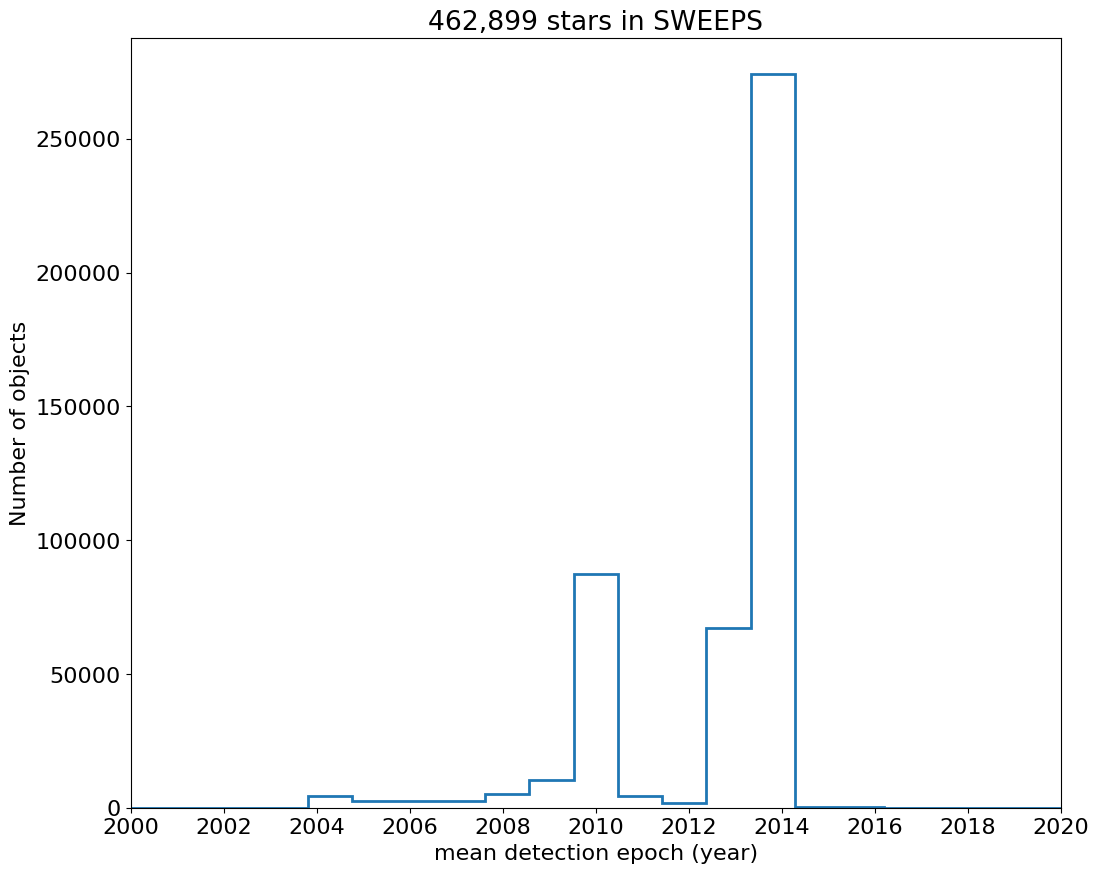
Time Histograms #
First plot histogram of observation dates.
bins = 1
hrange = (2000, 2020)
bincount = int((hrange[1]-hrange[0])/bins + 0.5) + 1
fig, ax = plt.subplots(figsize=(12, 10))
ax.hist('yr', data=tab, range=hrange, bins=bincount, label='year ', histtype='step', linewidth=2)
ax.set(xlabel='mean detection epoch (year)', ylabel='Number of objects', title=f'{len(tab):,} stars in SWEEPS')
ax.set_xticks(ticks=range(2000, 2021, 2))
_ = ax.margins(x=0)
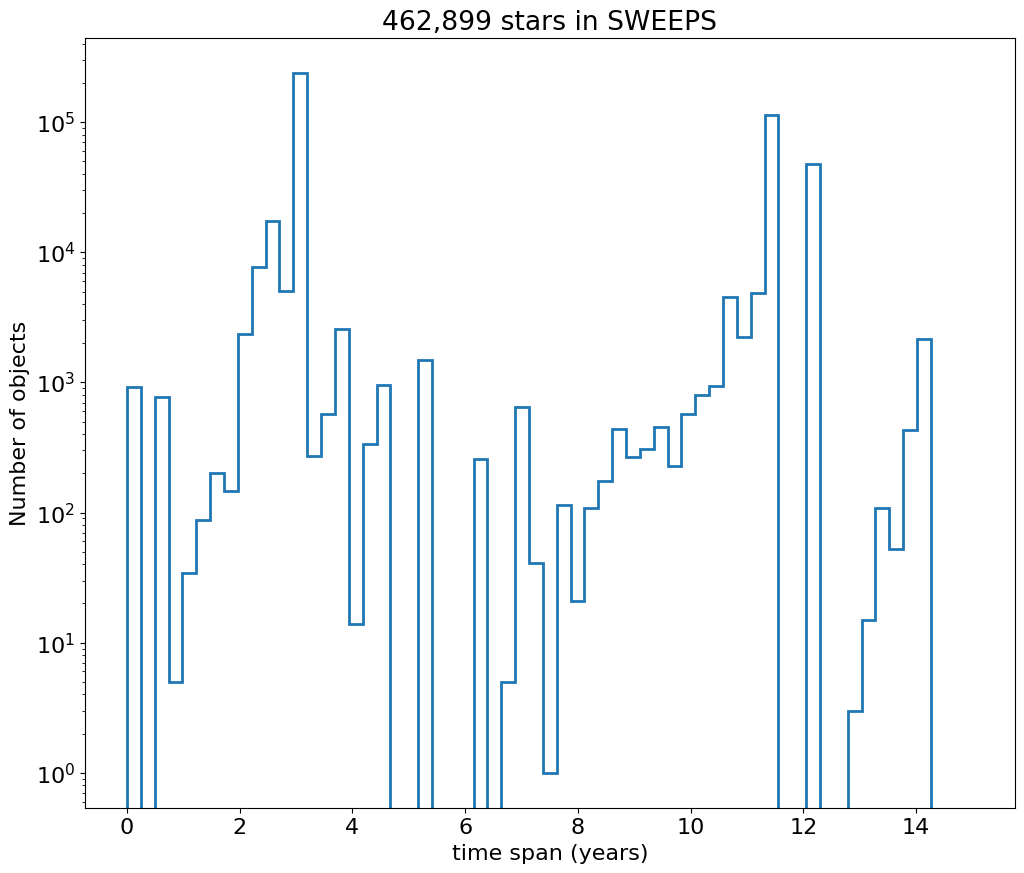
Then plot histogram of observation duration for the objects.
bins = 0.25
hrange = (0, 15)
bincount = int((hrange[1]-hrange[0])/bins + 0.5) + 1
fig, ax = plt.subplots(figsize=(12, 10))
ax.hist('dT', data=tab, range=hrange, bins=bincount, label='year ', histtype='step', linewidth=2)
_ = ax.set(xlabel='time span (years)', ylabel='Number of objects', title=f'{len(tab):,} stars in SWEEPS', yscale='log')
Detection Positions #
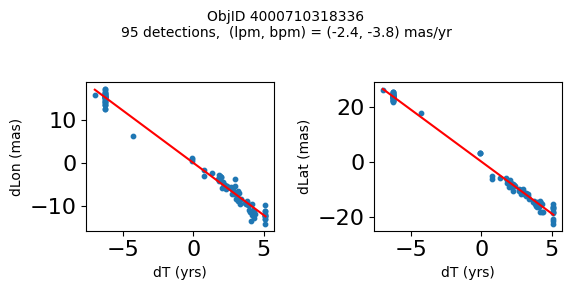
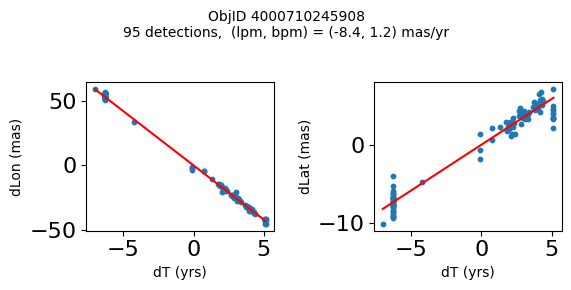
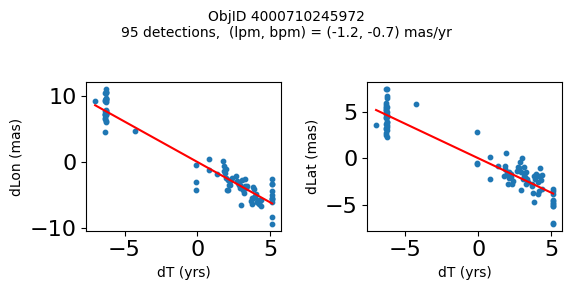
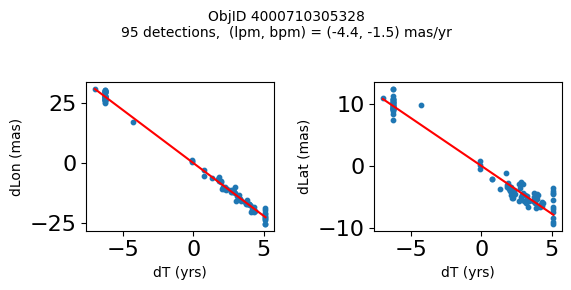
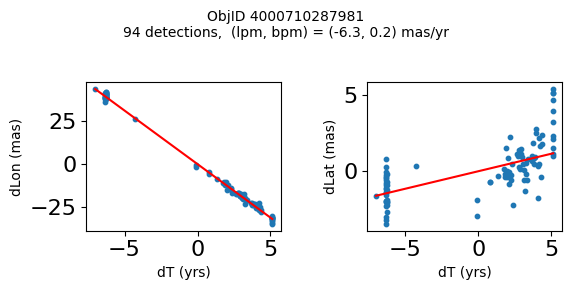
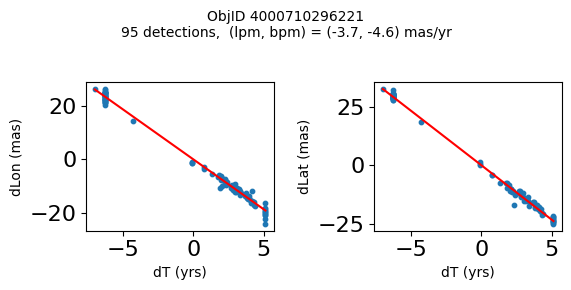
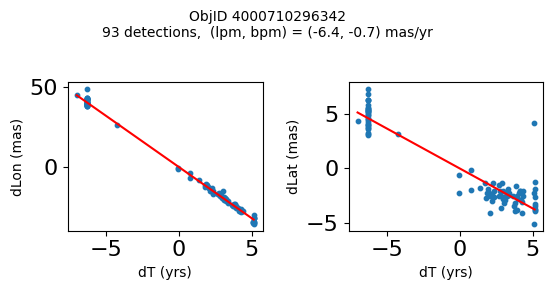
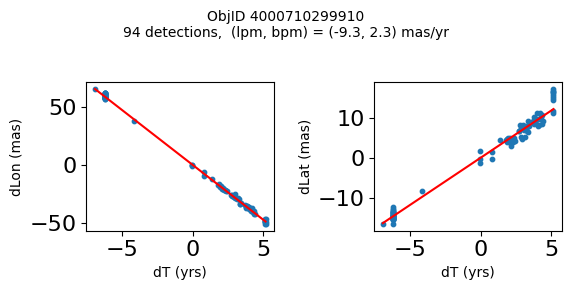
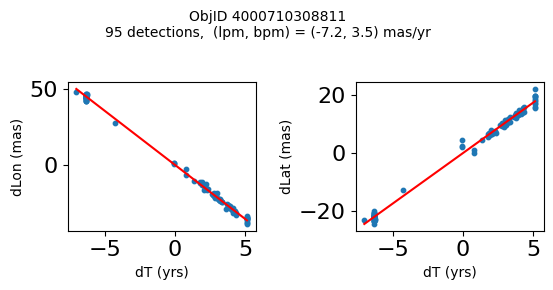
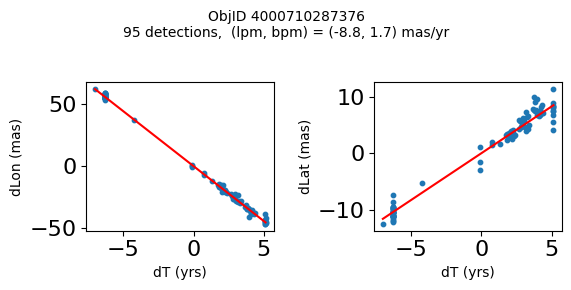
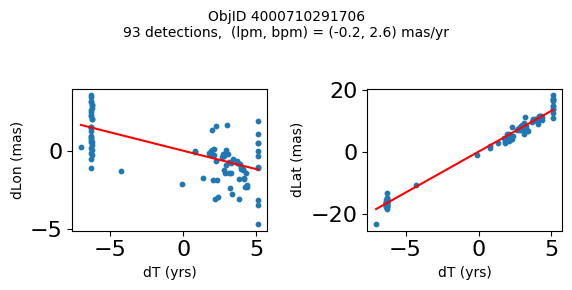
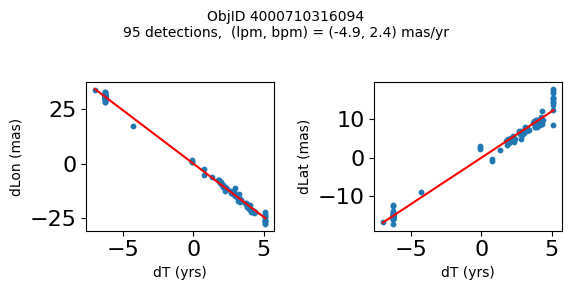
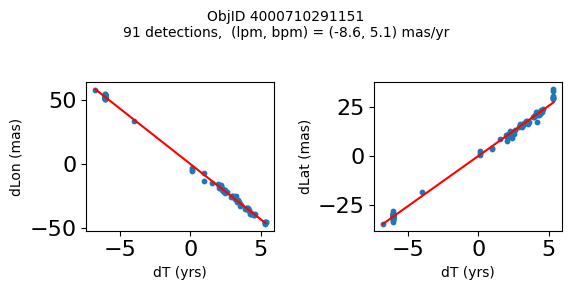
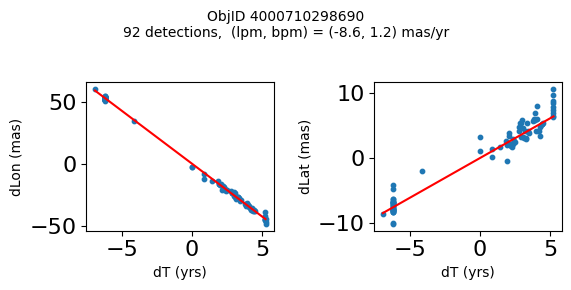
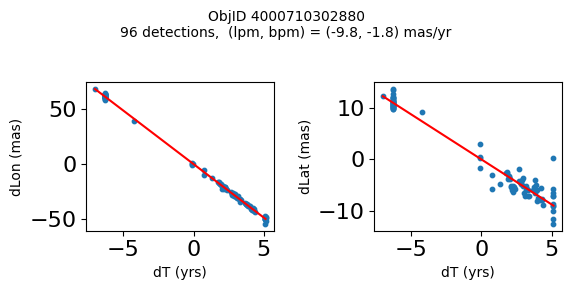
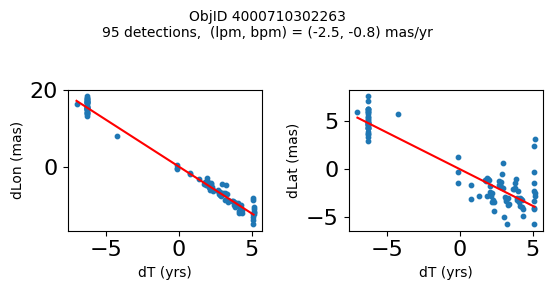
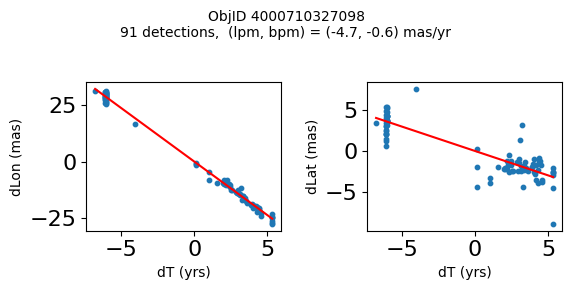
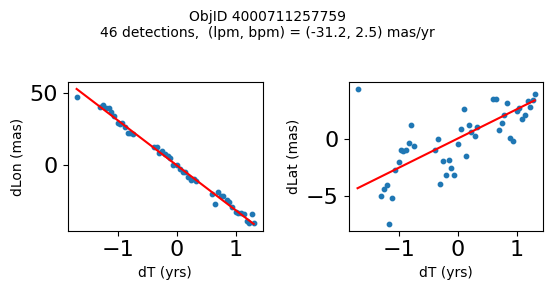
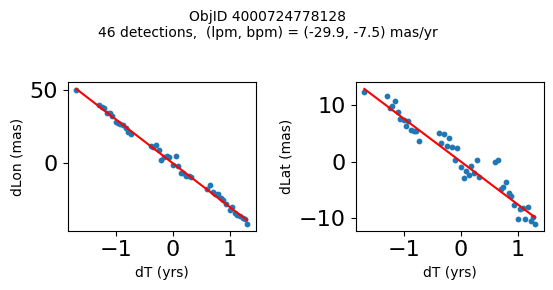
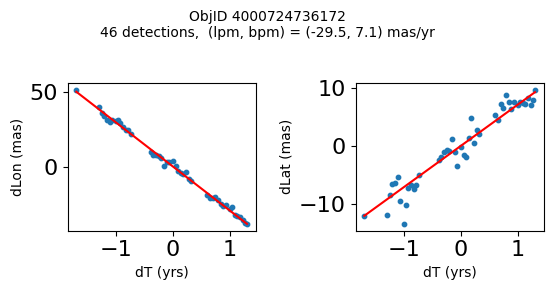
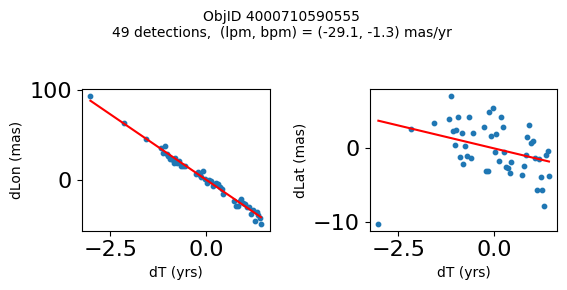
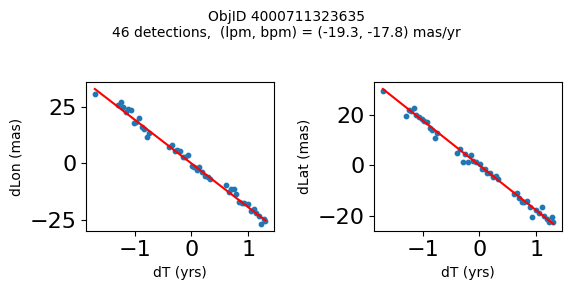
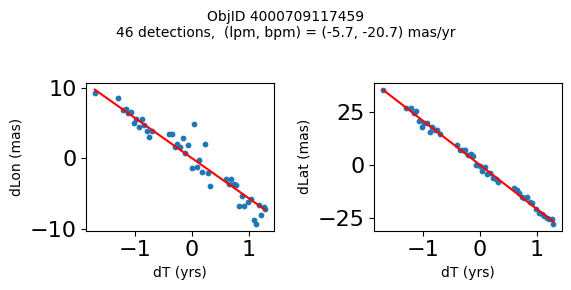
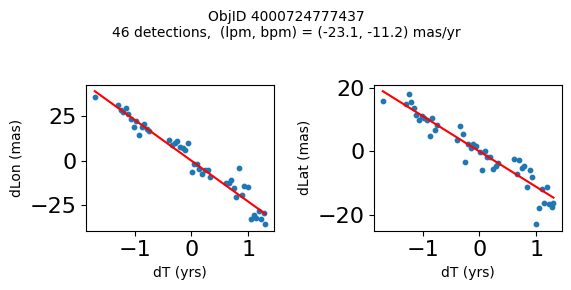
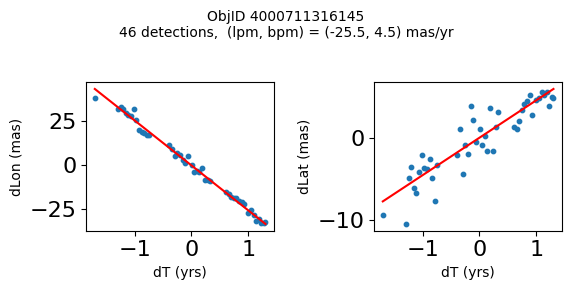
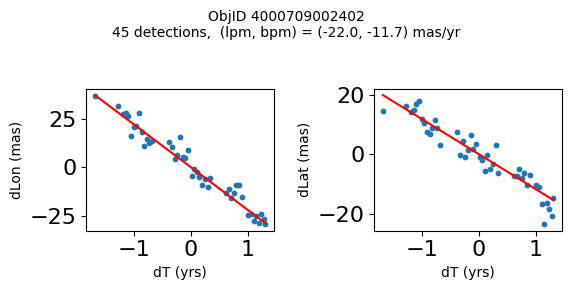
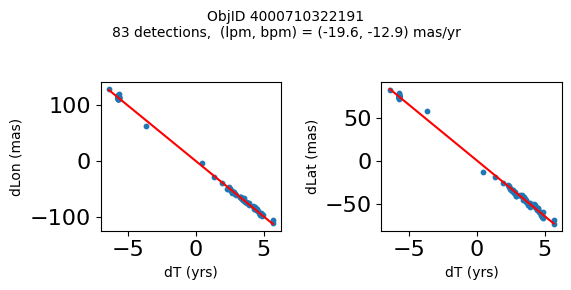
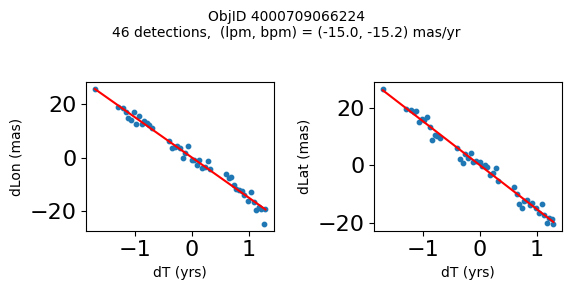
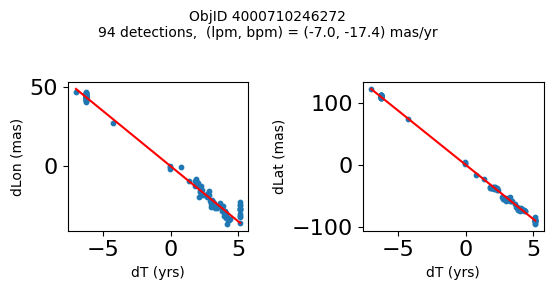
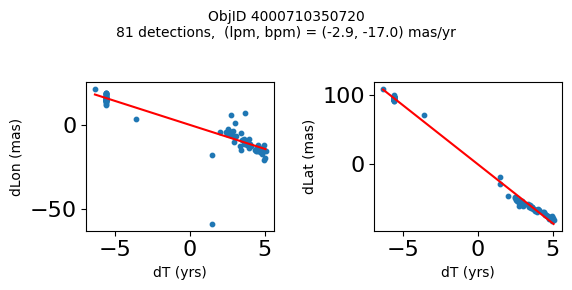
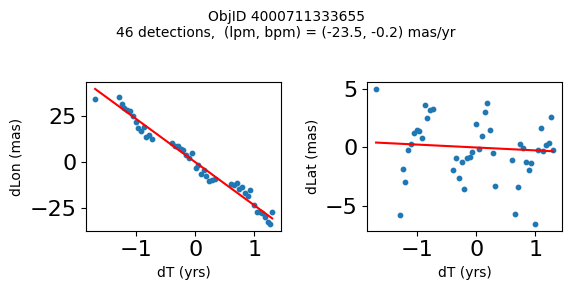
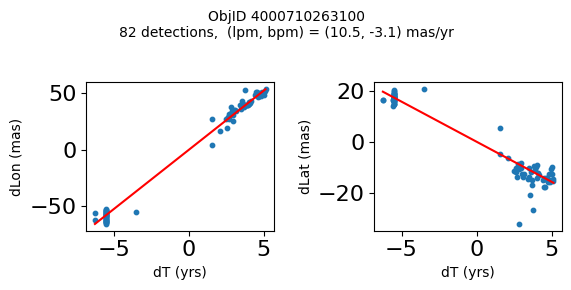
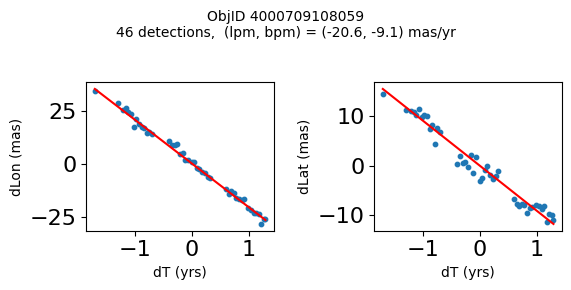
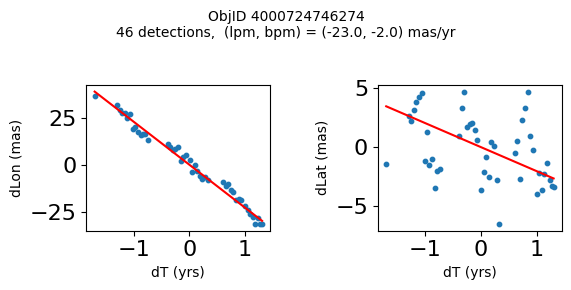
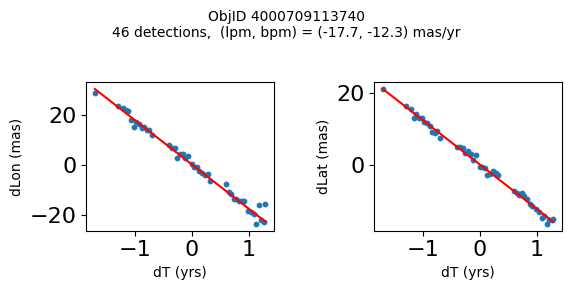
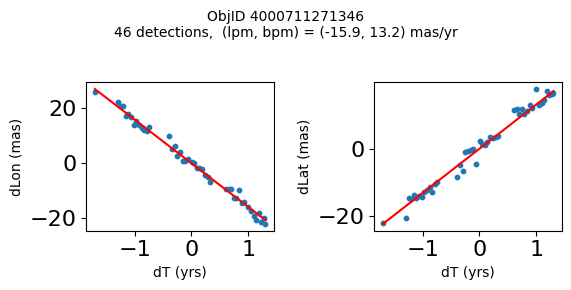
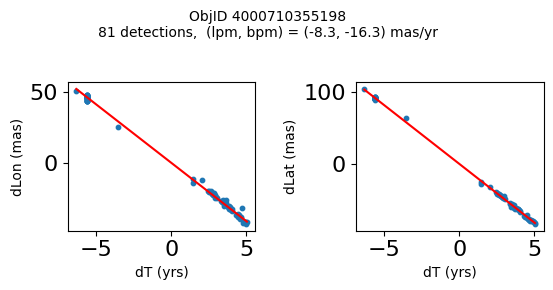
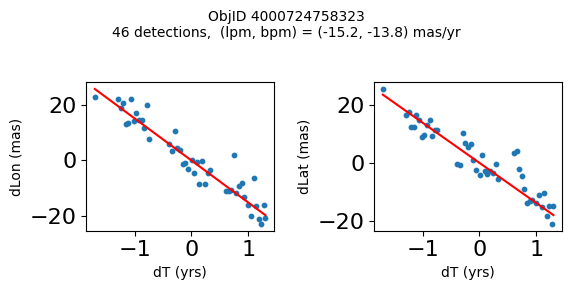
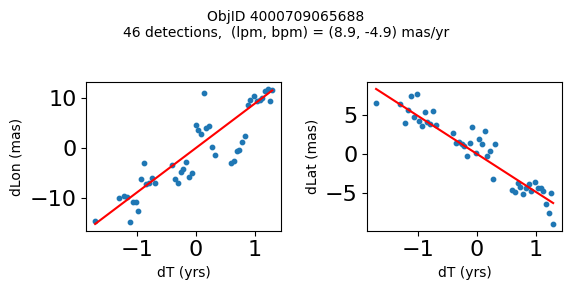
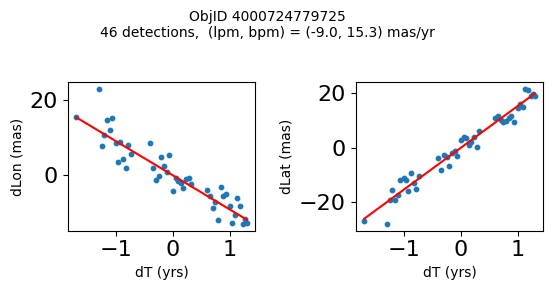
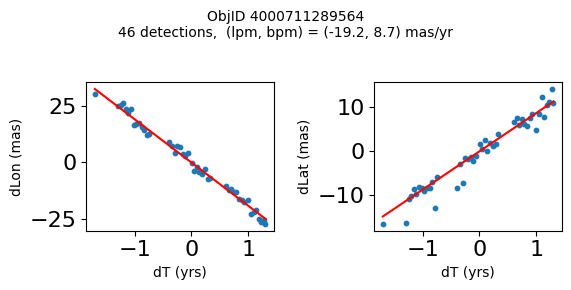
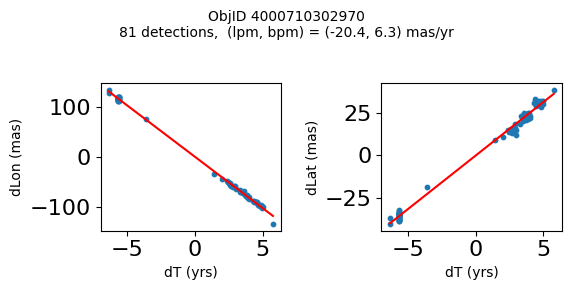
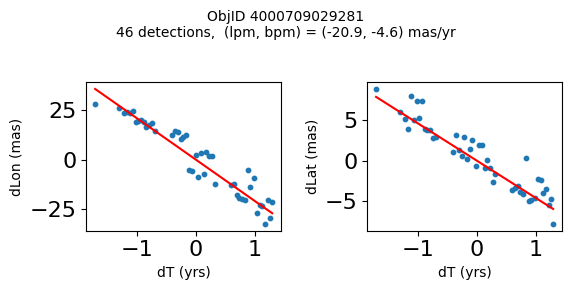
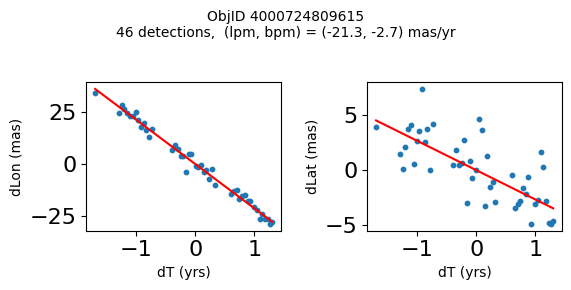
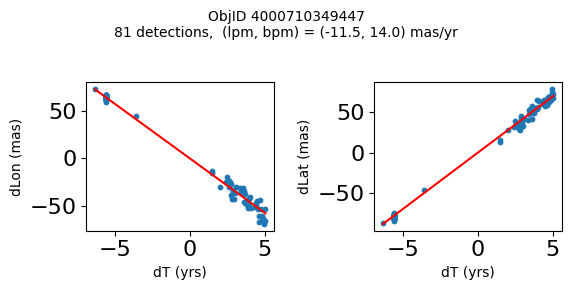
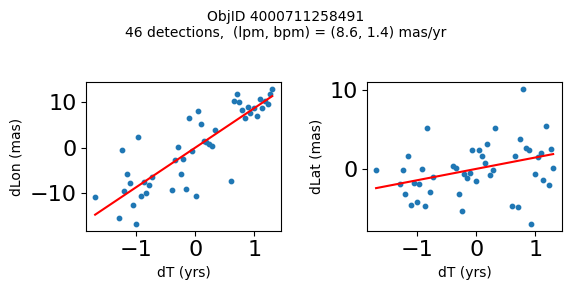
Define a function to plot the PM fit for an object.
# define function
def positions(Obj):
"""
input parameter Obj is the value of the ObjID
output plots change in (lon, lat) as a function of time
overplots proper motion fit
provides ObjID and proper motion information in labels
"""
# get the measured positions as a function of time
pos = ascii.read(hscsearch("sourcepositions", columns="dT,dLon,dLat".split(','), objid=Obj))
pos.sort('dT')
# get the PM fit parameters
pm = ascii.read(hscsearch("propermotions", columns="pmlon,pmlonerr,pmlat,pmlaterr".split(','), objid=Obj))
lpm = pm['pmlon'][0]
bpm = pm['pmlat'][0]
# get the intercept for the proper motion fit referenced to the start time
# time between mean epoch and zero (ref) epoch (years)
x = pos['dT']
# xpm = np.linspace(0, max(x), 10)
xpm = np.array([x.min(), x.max()])
y1 = pos['dLon']
ypm1 = lpm*xpm
y2 = pos['dLat']
ypm2 = bpm*xpm
# plot figure
fig, (ax1, ax2) = plt.subplots(nrows=1, ncols=2, figsize=(6, 3), tight_layout=True)
ax1.scatter(x, y1, s=10)
ax1.plot(xpm, ypm1, '-r')
ax2.scatter(x, y2, s=10)
ax2.plot(xpm, ypm2, '-r')
ax1.set_xlabel('dT (yrs)', fontsize=10)
ax1.set_ylabel('dLon (mas)', fontsize=10)
ax2.set_xlabel('dT (yrs)', fontsize=10)
ax2.set_ylabel('dLat (mas)', fontsize=10)
fig.suptitle(f'ObjID {Obj}'
f'\n{len(x)} detections, (lpm, bpm) = ({lpm:.1f}, {bpm:.1f}) mas/yr', fontsize=10)
plt.show()
plt.close()
Plot positions for a sample of objects with good proper motions #
This selects objects that are detected in more than 90 visits with a median absolute deviation from the fit of less than 1.5 mas and proper motion error less than 1.0 mas/yr.
n = tab['NumVisits']
dev = tab['pmdev']
objid = tab['ObjID']
lpmerr0 = np.array(tab['lpmerr'])
bpmerr0 = np.array(tab['bpmerr'])
wi = np.where((dev < 1.5) & (n > 90) & (np.sqrt(bpmerr0**2+lpmerr0**2) < 1.0))[0]
print(f"Plotting {len(wi)} objects")
for o in objid[wi]:
positions(o)
Plotting 21 objects
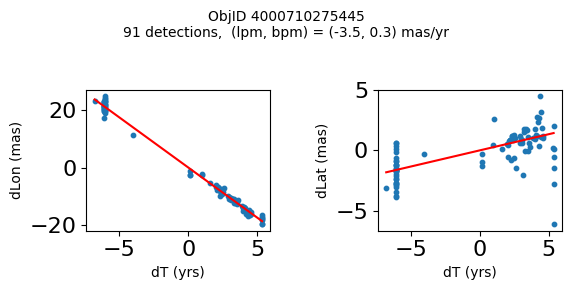
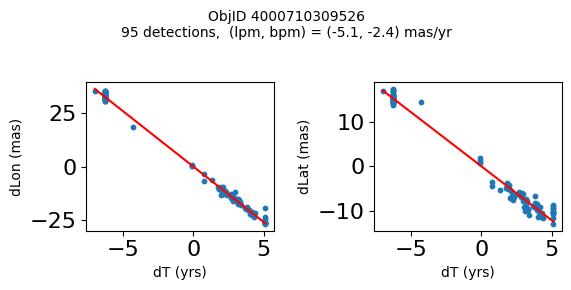
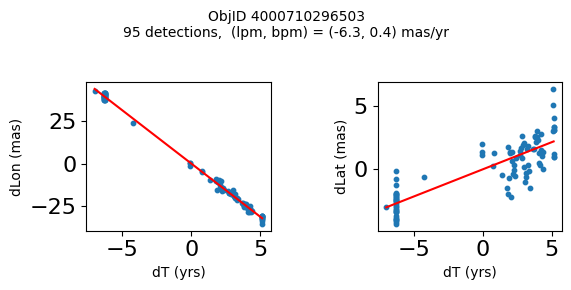
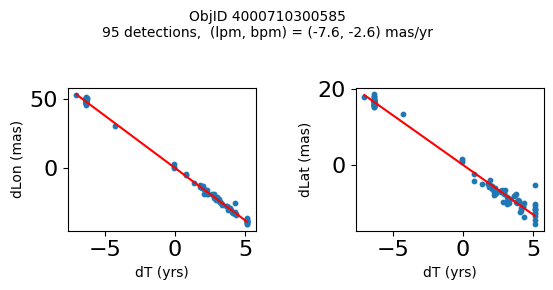
Science Applications #
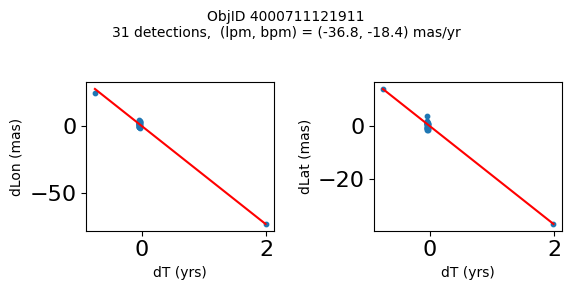
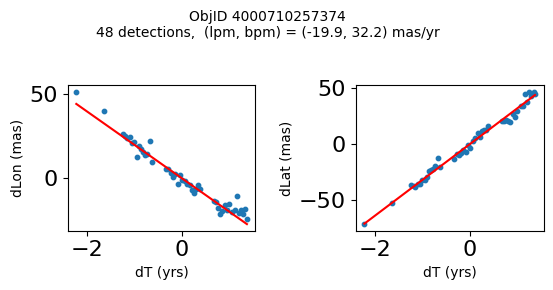
High Proper Motion Objects #
Get a list of objects with high, accurately measured proper motions. Proper motions are measured relative to the Galactic center.
lpm_sgra = -6.379 # +- 0.026
bpm_sgra = -0.202 # +- 0.019
lpm0 = np.array(tab['lpm'])
bpm0 = np.array(tab['bpm'])
lpmerr0 = np.array(tab['lpmerr'])
bpmerr0 = np.array(tab['bpmerr'])
pmtot0 = np.sqrt((bpm0-bpm_sgra)**2+(lpm0-lpm_sgra)**2)
pmerr0 = np.sqrt(bpmerr0**2+lpmerr0**2)
dev = tab['pmdev']
# sort samples by decreasing PM
wpmh = np.where((pmtot0 > 15) & (pmerr0 < 1.0) & (dev < 5))[0]
wpmh = wpmh[np.argsort(-pmtot0[wpmh])]
print(f"Plotting {len(wpmh)} objects")
for o in tab["ObjID"][wpmh]:
positions(o)
Plotting 31 objects
Get HLA cutout images for selected objects #
Get HLA color cutout images for the high-PM objects. The query_hla function gets a table of all the color images that are available at a given position using the f814w+f606w filters. The get_image function reads a single cutout image (as a JPEG color image) and returns a PIL image object.
See the documentation on HLA VO services and the fitscut image cutout service for more information on the web services being used.
def query_hla(ra, dec, size=0.0, imagetype="color", inst="ACS", format="image/jpeg",
spectral_elt=("f814w", "f606w"), autoscale=95.0, asinh=1, naxis=33):
# convert a list of filters to a comma-separated string
if not isinstance(spectral_elt, str):
spectral_elt = ",".join(spectral_elt)
siapurl = ("https://hla.stsci.edu/cgi-bin/hlaSIAP.cgi?"
f"pos={ra},{dec}&size={size}&imagetype={imagetype}&inst={inst}"
f"&format={format}&spectral_elt={spectral_elt}"
f"&autoscale={autoscale}&asinh={asinh}"
f"&naxis={naxis}")
votable = Table.read(siapurl, format="votable")
return votable
def get_image(url):
"""Get image from a URL"""
r = requests.get(url)
im = Image.open(BytesIO(r.content))
return im
# display earliest and latest images side-by-side
# top 10 highest PM objects
wsel = wpmh[:10]
nim = len(wsel)
icols = 1 # objects per row
ncols = 2*icols # two images for each object
nrows = (nim+icols-1)//icols
imsize = 33
xcross = np.array([-1, 1, 0, 0, 0])*2 + imsize/2
ycross = np.array([0, 0, 0, -1, 1])*2 + imsize/2
# selected data from tab
sd = tab[['RA', 'Dec', 'ObjID']][wsel]
# create the figure
fig, axes = plt.subplots(nrows=nrows, ncols=ncols, figsize=(12, (12/ncols)*nrows))
# iterate each observation, and each set of axes for the first and last image
for (ax1, ax2), obj in zip(axes, sd):
# get the image urls and observation datetime
hlatab = query_hla(obj["RA"], obj["Dec"], naxis=imsize)[['URL', 'StartTime']]
# sort the data by the observation datetime, and get the first and last observation url
(url1, time1), (url2, time2) = hlatab[np.argsort(hlatab['StartTime'])][[0, -1]]
# get the images
im1 = get_image(url1)
im2 = get_image(url2)
# plot the images
ax1.imshow(im1, origin="upper")
ax2.imshow(im2, origin="upper")
# plot the center
ax1.plot(xcross, ycross, 'g')
ax2.plot(xcross, ycross, 'g')
# labels and titles
ax1.set(ylabel=f'ObjID {obj["ObjID"]}', title=time1)
ax2.set_title(time2)

Look at the entire collection of images for the highest PM object#
i = wpmh[0]
# selected data
sd = tab['ObjID', 'RA', 'Dec', 'bpm', 'lpm', 'yr', 'dT'][i]
display(sd)
imsize = 33
# get the URL and StartTime data
hlatab = query_hla(sd['RA'], sd['Dec'], naxis=imsize)[['URL', 'StartTime']]
# sort the data
hlatab = hlatab[np.argsort(hlatab['StartTime'])]
nim = len(hlatab)
ncols = 8
nrows = (nim+ncols-1)//ncols
xcross = np.array([-1, 1, 0, 0, 0])*2 + imsize/2
ycross = np.array([0, 0, 0, -1, 1])*2 + imsize/2
| ObjID | RA | Dec | bpm | lpm | yr | dT |
|---|---|---|---|---|---|---|
| int64 | float64 | float64 | float64 | float64 | float64 | float64 |
| 4000711121911 | 269.7367256594695 | -29.209699919117618 | -18.43788346257518 | -36.80145933087569 | 2004.194238143401 | 2.749260607770275 |
# get the images: takes about 90 seconds for 77 images
images = [get_image(url) for url in hlatab['URL']]
# create the figure
fig, axes = plt.subplots(nrows=nrows, ncols=ncols, figsize=(20, (20/ncols)*nrows))
# flatten the axes for easy iteration and zipping
axes = axes.flat
plt.rcParams.update({"font.size": 11})
for ax, time1, img in zip(axes, hlatab['StartTime'], images):
# plot image
ax.imshow(img, origin="upper")
# plot the center
ax.plot(xcross, ycross, 'g')
# set the title
ax.set_title(time1)
# remove the last 3 unused axes
for ax in axes[nim:]:
ax.remove()
fig.suptitle(f"ObjectID: {sd['ObjID']}\nRA: {sd['RA']:0.2f} Dec: {sd['Dec']:0.2f}\nObservations: {nim}", y=1, fontsize=14)
fig.tight_layout()
